서론
인공지능(Artificial Intelligence) 모델이 현실에 도입될 때에는 ‘대체로’ 잘 작동하는 것은 오히려 최소 조건이 됩니다. 오히려, 우리가 해당 모델을 신뢰할 수 있는지가 중요해집니다. 설명성(Explainability)이란 “인공지능이 자신이 내놓은 결과에 대해 사람에게 충분히 설명할 수 있는가?”를 의미합니다. 인공지능 기술의 투명성 등 인공지능 핵심 규제들을 달성하고 관리 감독하는 데에 달성되어야할 요소입니다.
“Are Self-Attentions Effective for Time Series Forecasting?” [Paper, Repo] 은 인공지능 최우수 학회인 NeurIPS 2024에서 발표된 본 연구실의 논문이며, 본 글에서는 기본적인 설명성에 대한 개념과 논문 내용을 알아보고자 합니다.
사전 지식
블랙박스(Black-box)
인공지능은 다양한 분야에서 높은 성능을 보여주지만, 한 가지 문제점이 존재합니다. 바로 블랙박스(Black-box) 성질입니다. 블랙박스란 인공지능 모델, 특히 딥러닝 모델의 내부 작동 방식을 이해하거나 설명하기 어려운 특성을 나타내는 용어입니다. 이는 인공지능의 많은 매개변수(Parameter) 및 구조적 복잡성으로 인해 발생합니다.

이러한 인공지능의 블랙박스를 극복하고자하는 연구 분야를 설명 가능한 AI (Explainable AI, XAI)라고 합니다. 설명 가능한 AI는 인공지능의 설명성(Explainability)를 높여, 인공지능이 결정을 내리는 과정을 보다 투명하게 만들어 사람들에게 신뢰를 줄 수 있는 것을 목표로 합니다. XAI 관련 연구는 크게 두 접근 방법으로 나눌 수 있습니다.
사후 설명법 vs. 내재 설명법
사후 설명법(Post-hoc method)은 모델이 훈련된 후에 그 결과를 해석하기 위해 별도의 설명 기법을 적용하는 방식입니다. 예를 들어, 복잡한 딥러닝 모델을 우선 학습시킨 후, 예측 결과를 설명하기 위해 해석 기술(LIME, SHAP)을 적용합니다.
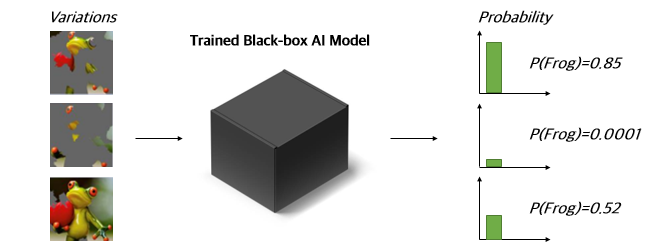
사후 설명법을 가능케하는 해석 기술 중 대표 예시로는 LIME(Local Interpretable Model-agnostic Explanations)이 존재합니다. LIME은 원본 개구리(Frog) 이미지가 있고, 학습된 블랙박스 모델(Trained black-box AI Model)이 있을 때, LIME은 “원본 개구리 중 어느 부분이 가장 핵심적이었는가?” 찾아내는 방법입니다. 학습된 블랙박스 모델에 특정 부분을 가린(Masking)한 사진들을 넣은 후, 대응되는 확률값을 바탕으로 가장 유의미한 부분을 찾아냅니다.
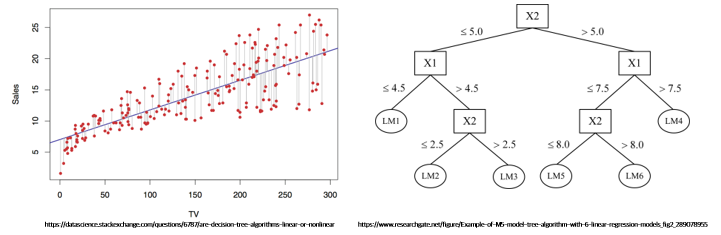
그에 반해 내재 설명법(Intrinsic method)은 모델 자체를 본질적으로 설명 가능하게 구현한 방법입니다. 해당 모델들은 별도의 해석 기술을 필요로 하지 않고 학습된 상태 그대로 예측 결과를 쉽게 해석할 수 있습니다. 인공지능 모델 중 선형 회귀(Linear regression), 결정 나무(Decision tree) 등이 이에 해당되며, 이들 모델은 산점도와 함께 그리거나 모델 자체를 시각화하여 해석할 수 있습니다.
높은 성능을 달성하는 딥러닝 모델들은 선형 회귀나 결정 나무와는 다르게 복잡한 구조를 가지고 있어 내재 설명법보다는 사후 설명법이 주로 사용되어 왔습니다. 그러나, 최근 연구들은 딥러닝 모델에 사후 설명법을 적용하는 것이 부정확할 수 있다는 것을 확인했습니다.

이에 일련의 연구들은 딥러닝 모델의 구조(Architecture)를 바꿈으로써 설명성을 높이는 방법들을 제안했습니다. 관련 연구들은 Generalized Additive Model (GAM)을 활용하거나 트랜스포머(Transformer)의 어텐션(Attention)을 활용하여 딥러닝의 설명력을 높였습니다. 아래 논문은 트랜스포머(Transformer)의 구조적 변경이 해석력을 크게 증대시킬 수 있음을 발견하기도 했습니다.

본론
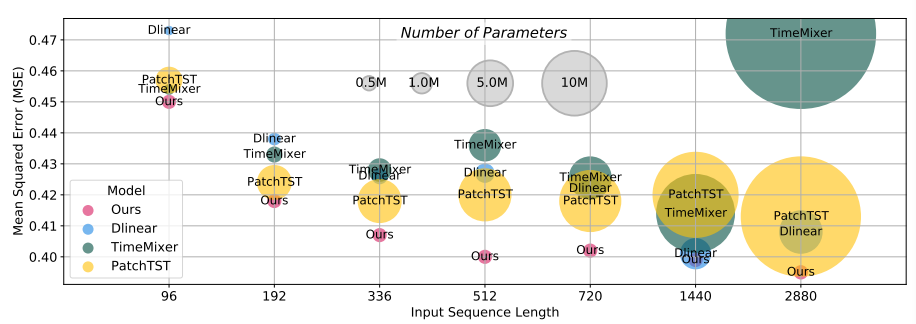
본 논문은 선행 연구에 이어 시계열 예측(Time-series Forecasting) 분야에서 어텐션(Attetion), 특히 셀프 어텐션(Self-attention)이 가지는 해석적/성능적 의의에 대해 분석하고자 했습니다. 이를 위해 널리 사용되는 시계열 모델, PatchTST의 셀프 어텐션 부분을 분석하였습니다.
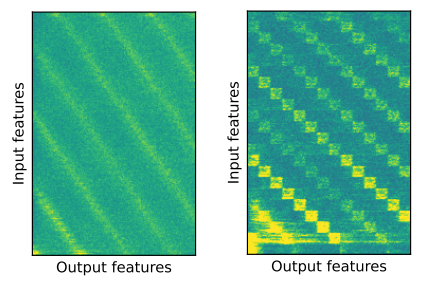
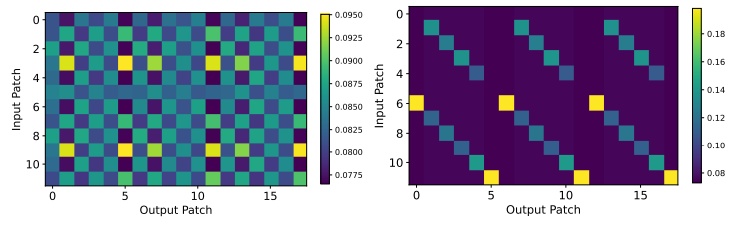
위 결과는 기존 셀프 어텐션을 사용했을 때에는 흐리게(Blur) 나오던 입력값과 출력값의 관계가 오히려 셀프 어텐션을 단순 선형 네트워크(Linear network)로 대체하였을 때 더 뚜렷해지는 현상을 보여줍니다. 즉, 시간적 정보(Temporal information)를 해석하는 데에 있어 셀프 어텐션이 단순 선형 네트워크보다 좋지 않을 수 있다는 것입니다. 성능적인 측면에서도 셀프 어텐션은 단순 선형 네트워크를 사용했을 때보다 유의미한 성능 차이를 보이지 못했으며, 오히려 감소한 성능을 보이기도 했습니다.
이러한 관찰 결과와 단순 선형 네트워크 기반의 선행 연구를 기반으로, 셀프 어텐션이 아닌 크로스 어텐션(Cross-attention)이 시간적 정보 분석 등 시계열 예측에서 여러 장점을 가질 수 있음을 결론지었습니다.
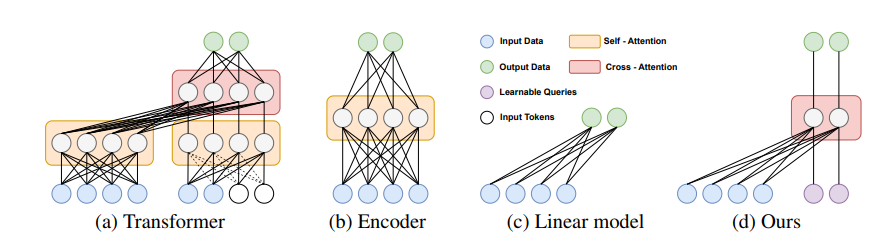
제안된 크로스 어텐션 기반의 모델(CATS)를 바탕으로 본 연구진은 적은 매개변수만으로도 높은 성능을 달성할 수 있었으며, 이는 기존 SOTA(State of the art) 모델 대비 뛰어난 성능을 보여주었습니다. 나아가, 제안된 크로스 어텐션 기반의 모델(CATS)은 해석하기 쉬운 결과를 제공하였습니다. 아래 그림처럼 입력 시계열의 주기적 패턴(Periodic Pattern)을 정확히 잡아내었으며, 추가적으로 충격(Shock)까지도 포착하는 모습을 보여주었습니다.
결론
설명성은 인공지능의 신뢰성 부문에서 핵심 개념 중 하나입니다. 모델의 설명성을 높이는 것은 인공지능이 사람이 의도한 대로 작동하고 있는지, 편향은 없는지 확인하는 데 필수적입니다. 설명성은 인공지능 모델이 내린 결정이 어떻게 도출되었는지 이해하고 분석하는 능력을 제공함으로써, 시스템의 투명성을 높이고 신뢰성을 강화합니다. 셀프 어텐션과 크로스 어텐션에 대한 본 논문의 발견이 모델의 설명 가능성 분야 발전에 기여하길 바랍니다.