Introduction
When Artificial Intelligence (AI) models are deployed in the real world, working “most of the time” becomes merely the minimum requirement. What matters more is whether we can trust that model. Explainability refers to “Can the AI sufficiently explain its results to humans?” It is an element that must be achieved to fulfill and oversee core AI regulations such as the transparency of AI technology.
“Are Self-Attentions Effective for Time Series Forecasting?” [Paper, Repo] is a paper from our lab presented at NeurIPS 2024, one of the top AI conferences. In this article, we aim to explore the basic concepts of explainability and the contents of the paper.
Preliminary
Black-box
AI demonstrates high performance across various fields, but one problem persists: the black-box nature. Black-box is a term describing the characteristic of AI models, especially deep learning models, where the internal workings are difficult to understand or explain. This arises from the large number of parameters and the structural complexity of AI models.

The research field that seeks to overcome this black-box nature of AI is called Explainable AI (XAI). Explainable AI aims to enhance the explainability of AI, making the decision-making process of AI more transparent and building trust among people. XAI research can be broadly divided into two approaches.
Post-hoc Methods vs. Intrinsic Methods
Post-hoc methods apply separate explanation techniques to interpret results after the model has been trained. For example, a complex deep learning model is first trained, and then interpretation techniques (LIME, SHAP) are applied to explain the prediction results.
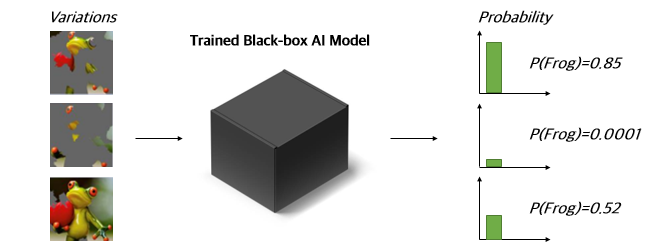
A representative example of interpretation techniques that enable post-hoc explanation is LIME (Local Interpretable Model-agnostic Explanations). Given an original frog image and a trained black-box AI model, LIME finds “which part of the original frog image was most critical.” It feeds images with specific regions masked into the trained black-box model, then identifies the most significant regions based on the corresponding probability values.
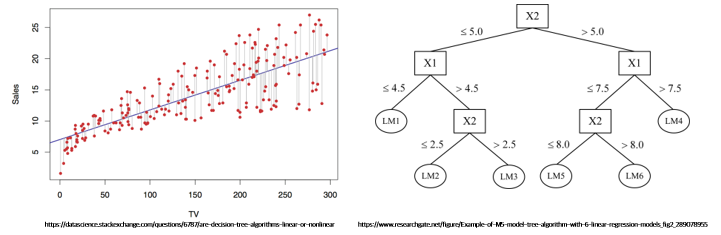
In contrast, intrinsic methods implement the model itself to be inherently explainable. These models do not require separate interpretation techniques and can easily interpret prediction results as-is in their trained state. Among AI models, linear regression and decision trees fall into this category, and these models can be interpreted by plotting them with scatter plots or visualizing the model itself.
Deep learning models that achieve high performance have complex structures unlike linear regression or decision trees, so post-hoc methods have been predominantly used over intrinsic methods. However, recent studies have confirmed that applying post-hoc methods to deep learning models can be inaccurate.

Accordingly, a line of research has proposed methods to improve explainability by modifying the architecture of deep learning models. Related studies have leveraged Generalized Additive Models (GAM) or the attention mechanism of Transformers to enhance the explanatory power of deep learning. The paper below also discovered that structural modifications to the Transformer can significantly enhance interpretability.

Main Results
Building on prior work, this paper aimed to analyze the interpretive and performance significance of attention, particularly self-attention, in time-series forecasting. To this end, the self-attention component of PatchTST, a widely used time-series model, was analyzed.
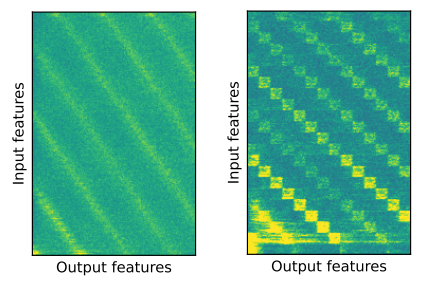
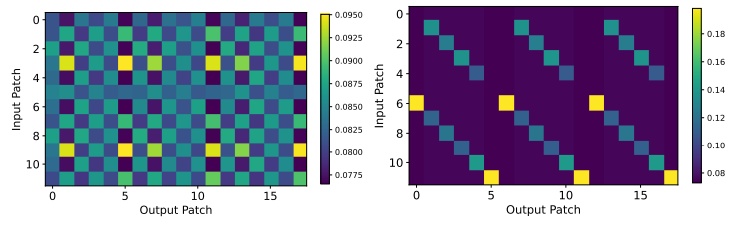
The above results show that the relationship between input and output values, which appeared blurry when using the original self-attention, actually became clearer when self-attention was replaced with a simple linear network. In other words, self-attention may not be better than a simple linear network for interpreting temporal information. In terms of performance as well, self-attention did not show a significant performance difference compared to using a simple linear network, and in some cases even showed decreased performance.
Based on these observations and prior work on simple linear networks, the paper concluded that cross-attention, rather than self-attention, can have several advantages for time-series forecasting, including temporal information analysis.
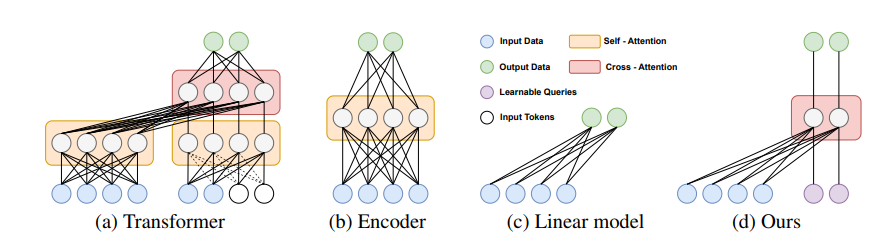
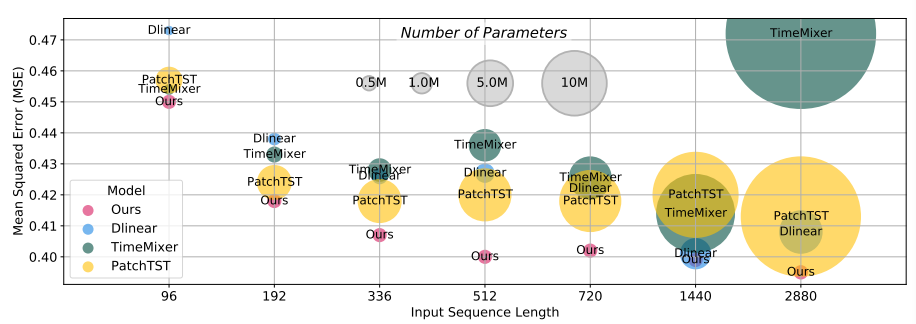
Based on the proposed cross-attention-based model (CATS), our research team achieved high performance with fewer parameters, outperforming existing state-of-the-art (SOTA) models. Furthermore, the proposed cross-attention-based model (CATS) provided easily interpretable results. As shown in the figure below, it accurately captured periodic patterns in the input time series, and additionally demonstrated the ability to detect shocks.
Conclusion
Explainability is one of the core concepts in AI trustworthiness. Improving model explainability is essential for verifying whether AI is operating as intended by humans and whether there is any bias. Explainability enhances system transparency and strengthens trustworthiness by providing the ability to understand and analyze how the decisions made by AI models were derived. We hope that the findings of this paper regarding self-attention and cross-attention contribute to advancing the field of model explainability.