Paper: Neural Network Security: Hiding CNN Parameters with Guided Grad-CAM
Authors: Linda Guiga , Andrew William Roscoe
Venue: International Conference on Information Systems Security and Privacy (ICISSP) 2020
Introduction
CNN (Convolutional Neural Network) is one of the most widely used neural network architectures in deep learning, demonstrating excellent performance in pattern recognition and feature extraction across various data types such as images, video, audio, and text.
However, because CNNs are so widely used, they are a primary target for various attacks. There are two representative attack types.
First, adversarial attacks are attack methods that intentionally alter the model’s output for a specific input while keeping outputs for other inputs unchanged.
Second, reverse engineering attacks aim to extract the core parameters of a victim model.
This study focuses particularly on reverse engineering attacks among these threats and proposes an effective defense method to prevent CNN parameter leakage by leveraging a visualization technique called Guided Grad-CAM.
Background Knowledge
Tramer proposed various reverse engineering attack techniques in the paper “Stealing Machine Learning Models via Prediction APIs (2016)”.
Among them, the representative attack types include equation solving attacks and retraining attacks.
The equation solving attack formulates input-output relationships as equations based on the probability values output by the model and solves them to directly infer internal parameters.
The retraining attack queries the model with various inputs to collect outputs, then trains a new model on this data to mimic the behavior of the victim model.
Retraining attacks require significantly more query budget compared to equation solving attacks.
Therefore, this study selects the equation solving attack as the attack technique, considering that the target CNN model has a very large number of parameters and the availability of confidence values, and proposes a corresponding defense technique.
Main Content
The defense technique presented in this paper for protecting CNN model parameters involves adding noise to input values.
This makes it difficult to extract internal parameter values while maintaining model performance.
Noise is added to specific pixel values of the image using a visualization technique called Guided Grad-CAM.
Guided Grad-CAM
Each neuron in a CNN contributes differently to the prediction. Some research (Mahendran & Vedaldi, 2016) found that the last layer of a CNN reflects more of the global characteristics of an image.
Therefore, by analyzing the neurons of the last convolutional layer, we can identify which parts the model considers most important during prediction. Based on this background, Selvaraju et al. (2016) proposed the Guided Grad-CAM technique.
Guided Grad-CAM generates visual explanation maps based on the gradients of the last convolutional layer, enhancing the explainability of CNN models by showing which regions of the input image the model focused on.
As the name suggests, Guided Grad-CAM is a method that combines Guided Backpropagation and Grad-CAM. Guided Backpropagation provides fine-grained pixel-level information, while Grad-CAM highlights semantically meaningful feature regions for each class.

The figure above shows the results of applying different visualization techniques to highlight meaningful feature regions for predictions of a dog and a cat in an image containing both animals.
Proposed Method
This study proposes a method that uses Guided Grad-CAM to select pixels in the input image where noise should be added when the model predicts the class of an image. This makes it difficult to extract the CNN model’s parameters (weights).
Given the attacker’s input query $ x $, noise $ n $ is added to the input value to yield the output $f(x’)$ where $ (x’ = x+n)$.
When selecting pixels for noise injection, Guided Grad-CAM is used to select pixels with low importance. This is because noise must be added in a way that does not change the model’s prediction while making weight extraction difficult. The threshold for selecting unimportant pixels is denoted by $ t $.
The noise $n$ we inject follows a normal distribution \(\mathcal{N}(\mu,\ \sigma^2)\) defined over the selected pixel set $S$. A large $ \mu $ (mean) causes outputs to skew overall through linear operations, making noise components strongly visible, while a large $ \sigma $ (standard deviation) increases noise variability and makes the model less dependent on original input values. Batch Normalization within the model helps maintain training stability and performance by limiting abrupt changes in the input distribution.
\[\tilde{x}_{i,j}=\frac{x_{i,j}-\mu_{\text{batch}}}{\sqrt{V_{\text{batch}}+\varepsilon}}\]Experiment
In the experiments of this study, it is assumed that the attacker can estimate the architecture of the target model and that there is no limit on the number of input queries.
First, the number of pixels receiving noise and the change in accuracy were measured according to the value of $ t $.
- Model architecture: VGG-19
- Dataset: IMAGENET
- $ p $ = pixel value in the Guided-Grad-CAM map
- $m$ = maximum value of the Guided-Grad-CAM map
- $t$ = threshold
The results of selecting pixels for noise injection according to $ t $ and inserting noise following a normal distribution with $ \mu$ = 125 and $\sigma$ = 25 are shown in the following image.
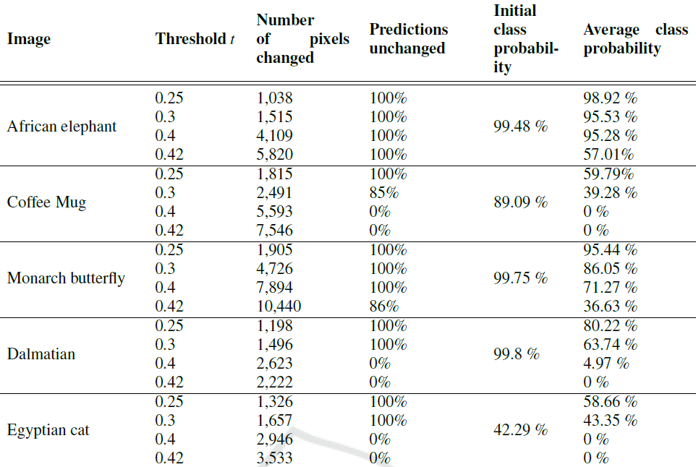
As the results show, as $t$ increases, the number of pixels with injected noise grows, and the degree to which the model’s predictions change varies across classes. The maximum value of $t$ at which all five class predictions remain unchanged was 0.25, so the threshold was set to 0.25 as the default for subsequent experiments.

Through the above experiment, it was confirmed that optimal defense is achieved at $ t = 0.25$, and this was applied to LeNet, the first CNN model.
The experimental settings were as follows:
- Model: LeNet (original version and version with batch normalization layer added)
- Dataset: CIFAR-10
- Mean and standard deviation of added noise: $\mu = 0.8, $ $\sigma = 0.1$
With these settings, first (a) the performance difference between the model with and without the defense technique was evaluated, second (b) the performance of the defense-applied model after adding batch normalization to the first convolution layer was evaluated, and then (c) the performance degradation when an attacker creates an extraction model from the defense-applied model was evaluated.
Results:
- In (a), 2% of total pixels were selected as unimportant and had noise added, with a prediction agreement rate of 82% compared to the original model.
- When noise was inserted across the entire image without pixel selection, the accuracy was 79.8%, confirming that using Guided Grad-CAM is more efficient.
- In (b), 1.8% of total pixels had noise added, with a prediction agreement rate of 89.5% compared to the original model.
To conduct (c), the attacker’s extraction model was created using Tramer’s Equation Solving Attack. The attack target was set to the last layer of the LeNet architecture. The attack performance evaluation metrics used the following formulas:
\[E(f,\tilde{f}) \;=\; \sum_{x \in D} \frac{ d\!\left(f(x),\, \tilde{f}(x)\right) }{|D|}\] \[E_{\mathrm{var}}(f,\tilde{f}) \;=\; \sum_{x \in D} \frac{ d_{\mathrm{var}}\!\left(f(x),\, \tilde{f}(x)\right) }{|D|}\] \[d_{\mathrm{var}}\!\big(f(x),\tilde f(x)\big) = \frac12 \sum_{i=1}^{c} \left|\, p_i - q_i \,\right|.\]$ f,\tilde{f} $ represent the victim model and the attacker’s extraction model respectively, and $D$ denotes the test dataset. $d$ is a distance metric that only checks whether the prediction labels of both models match, defined as 0 if they are the same and 1 if different. $d_{\mathrm{var}}$ is the total variation distance measuring the difference between the probability distributions of the two models.
When performing the attack on the last layer of the LeNet model, attacks were conducted on both the original LeNet model and a simplified LeNet model with the number of filters in the first convolution layer reduced from 16 to 6. The similarity to the original model was measured as $ 1-E, 1- E_{\mathrm{var}}$.
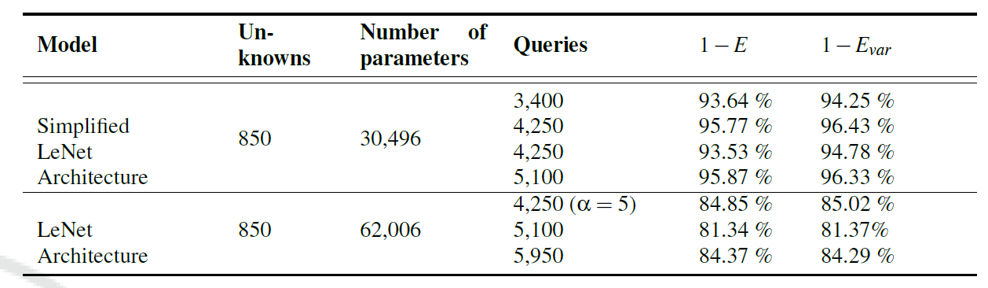
The simplification of LeNet was done for experimental efficiency such as reducing the number of parameters. The result of this experiment shows that simpler front-end representations make last-layer weight extraction significantly easier.
After applying the above attack method, experiment (c) was conducted. The results for models with and without batch normalization were also compared.
The accuracy on the CIFAR-10 test set for each original model was 64.6% and 62.7%, respectively.
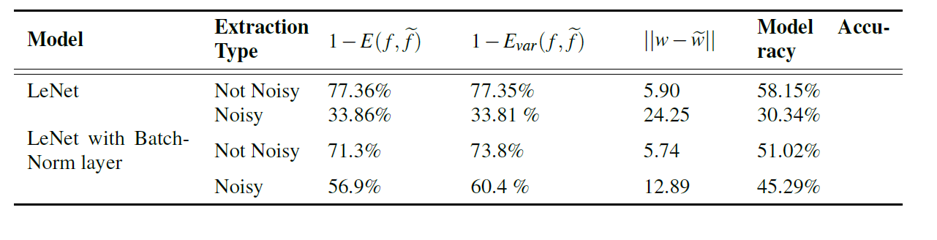
Interpreting the experimental results, in the case of the model without batch normalization, the performance of the extraction model significantly dropped when the defense method was applied, proving the effectiveness of this defense method.
When batch normalization was applied, the attacker’s extraction model performed lower without the defense technique compared to the case with batch normalization, but when comparing the cases with the defense technique applied, the defense performance was slightly reduced. However, the attacker’s extraction model still performed worse than before the defense technique was applied, so the defense technique can still be considered effective.
Conclusion
This study demonstrated the effectiveness of a noise injection technique using the Graded-Guided CAM visualization method as a defense against weight extraction attacks (Tramer’s Equation Solving attack).
However, since the experiments were limited to LeNet/CIFAR-10 and last-layer extraction, additional generalization validation for other architectures, datasets, multi-layer extraction, and adaptive attacks is expected to be needed in the future.