Paper: Knockoff nets: Stealing Functionality of Black-box Models
Authors: Tribhuvanesh Orekondy, Bernt Schiele, Mario Fritz
Venue: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
URL: Knockoff nets: Stealing Functionality of Black-box Models
Introduction
With the advancement of deep learning technology, various machine learning services such as image recognition are being provided as black-box APIs. For example, Google’s Cloud Vision service only provides prediction results to users, without revealing the internal structure or training data. Such commercial models are developed with enormous investments of time and resources, including data collection, model design, and hyperparameter tuning, and hold high economic value.
The high value and limited accessibility of black-box models have raised concerns about the potential for malicious exploitation. This concern has led to various inference attacks targeting black-box models, with active efforts to infer training data and model architectures.
This paper goes one step further and focuses on functionality stealing, which aims to steal the functionality itself of a model in a black-box setting.
It proposes attack techniques that can efficiently replicate the functionality of a target model using only simple prediction results, and experimentally analyzes their efficiency and effectiveness.
Background
Black-box vs. White-box
-
A black-box model does not expose its internal structure, parameters, or training data to the outside, and users can only observe the output for a given input. Most commercial machine learning APIs are provided in this form.
-
A white-box model is a form where the model’s structure and training process are fully disclosed, used in research and development or internal deployment environments. Users can directly access all information including the model’s parameters, architecture, and loss function.
This paper addresses attack scenarios in a black-box setting.
Model stealing
Recent studies have been making attempts to estimate the following internal information from black-box models:
- Parameters Fredrikson et al.,
- Hyperparameters Wang et al.,
- Architecture Oh et al.,
- Training data information Shokri et al.,
- Decision boundaries Papernot et al.
These studies aim for precise replication of the target model and typically assume some degree of prior knowledge or internal access to the target model.
In contrast, this paper focuses on whether the functionality itself of a black-box model can be stolen without prior knowledge.
Knowledge Distillation
Knowledge distillation is a technique that transfers knowledge from a complex teacher model to a lightweight student model.
Standard supervised learning trains on one-hot labels, but distillation uses the prediction probability distribution (soft labels) of the teacher model, enabling the student model to learn richer information. The teacher model’s prediction probability distribution reflects implicit knowledge such as inter-class similarities and confidence levels.
Active Learning
Active learning is a strategy that improves learning efficiency by preferentially selecting the most informative samples in situations where labeling costs are limited. Representative approaches include selecting samples with high model uncertainty or data that is difficult to predict.
The paper applies this concept to propose an adaptive querying technique.
Main Content
Objective
The attacker’s situation is as follows:
- The attacker has no prior knowledge of the target model’s hyperparameters such as learning rate, batch size, optimizer, or model architecture.
- The training data and semantic relationships across classes are also unknown.
- The target model returns only a probability vector for each input.
This paper seeks to replicate the functionality of the target model with minimal queries under these conditions.
This is represented by the following diagram:
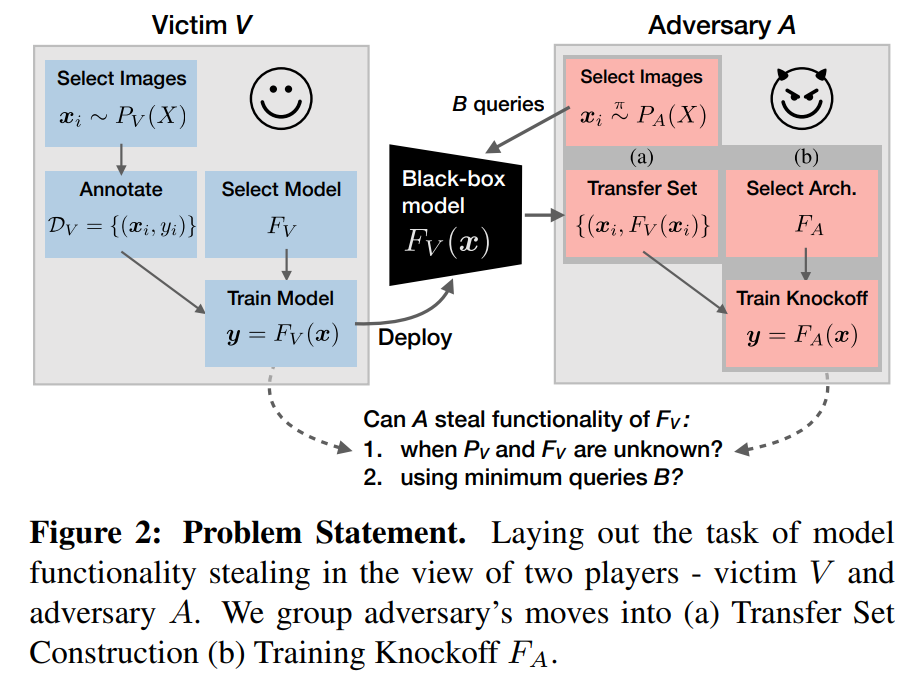
Knockoff Nets
Creating a knockoff model consists of two stages:
-
Transfer set construction
This is the process of querying the target model to obtain a transfer dataset for training the knockoff model. Two querying strategies are available:
-
Random Sampling Randomly selects inputs from an image distribution and queries the target model.
-
Adaptive Sampling A strategy that actively selects data to query, improving the quality of the transfer dataset. Adaptive sampling selects the class to use from a policy \(\pi_t(z)\) at each time step \(t\) and generates image samples.
-
The policy \(\pi_t\) is updated through the following process:
- The policy, expressed as \(\pi_t\), adjusts the query probability for each input.
-
A reward \(r_t\) is used to update the preference policy.
The reward \(r_t\) consists of three components:
-
\(R^{\mathcal{L}}\): The loss between the outputs of the target model and the knockoff model. This is expressed by the following formula: \(\begin{align} R^\mathcal{L}(y_t, \hat{y}_t) = \mathcal{L}(y_t, \hat{y}_t) \end{align}\)
- \(R^{cert}\): The certainty of the target model’s output. This is expressed by the following formula: \(\begin{align} R^{cert}(y_t) = P(y_{t,k_1}|x_t) - P(y_{t,k_2}|x_t) \end{align}\)
- \(R^{div}\): The diversity of the target model’s output. This is expressed by the following formula: \(\begin{align} R^{div}(y_{1:t}) = \sum_k \text{max}(0, {y}_{t,k}-\bar{y}_{t:t-\Delta, k}) \end{align}\)
-
The preference policy \(H_t\) is expressed by the following formula: \(\begin{align} H_{t+1}(z_t) = H_t(z_t) + \alpha(r_t - \bar{r}_t)(1-\pi_t(z_t)) \quad \text{and} \\ H_{t+1}(z') = H_t(z') + \alpha(r_t - \bar{r}_t)\pi_t(z') \quad\quad \forall z' \neq z_t \end{align}\)
The obtained reward \(r_t\) is used to update the preference \(H_t\) for each class \(z\).
-
-
Knockoff model training
The collected transfer dataset is used to train the knockoff model to produce outputs similar to the target model.
The knockoff model starts from a pretrained ImageNet model. (e.g., MobileNet, ResNet)
The training objective is to accurately mimic the victim model’s output, minimizing the following loss function:
This is a prediction probability distribution-based cross-entropy, equivalent to minimizing the KL-divergence between the target model and the knockoff model.
Experimental Setup
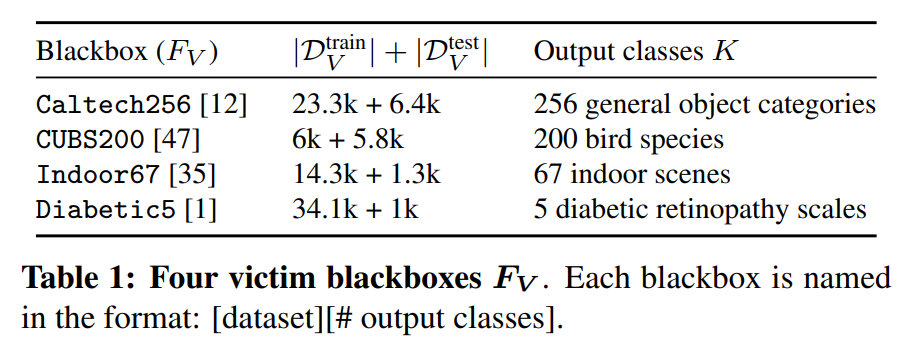
- Target Model
The target model is trained with the following datasets:
- Attack image set construction
Since the attacker does not know the dataset used to train the target model, arbitrary public image sets are used.
This paper samples images from various image distributions to construct the transfer dataset. The four main image distributions used in the experiments are:
- \(P_V\) (Identical data) Uses data identical to the target model’s training data. Used as a baseline for comparison with other image sets and can be considered a special form of knowledge distillation.
- ILSVRC (ImageNet) Uses 1.2M images from 1000 classes of the ILSVRC 2012 challenge.
- OpenImages Uses a subset of 550K images, with 2000 images extracted from each of 600 classes out of 9.2M images collected from Flickr.
- \(D^2\) (Dataset of Datasets) A combined set of all datasets used in the paper, totaling 2.2M images and 2129 classes.
The paper classifies the above image distributions as follows, based on the degree of label overlap between the target model’s training dataset and the attack image distribution:
- \(P_A=P_V\): Completely identical to the target model’s training data.
- Closed-World: \(P_A = D^2\), the target model’s training dataset is a subset of the attack image distribution.
- Open-World: ILSVRC, OpenImages, where any class overlap is coincidental.
Experimental Results
The results of experiments based on the above strategies and experimental settings are as follows:
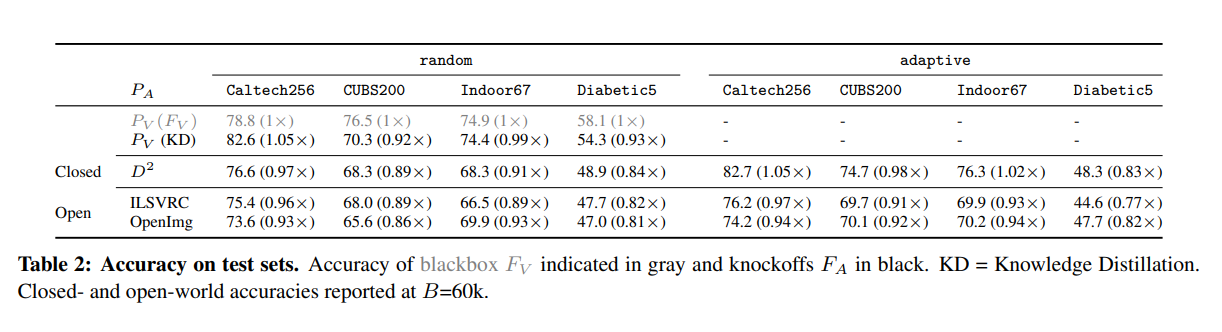
It was possible to replicate the model’s functionality to a certain degree simply by querying random images from image distributions independent of the target model’s training data.
The following are the qualitative analysis results:

When querying the target model with images of classes that did not exist in the training image set, the output labels were largely unrelated to the input images. (Fig. 6a)
However, when relevant images were presented during testing, strong prediction performance was observed. (Fig. 6b)
The following are the experimental results on model performance according to the budget:
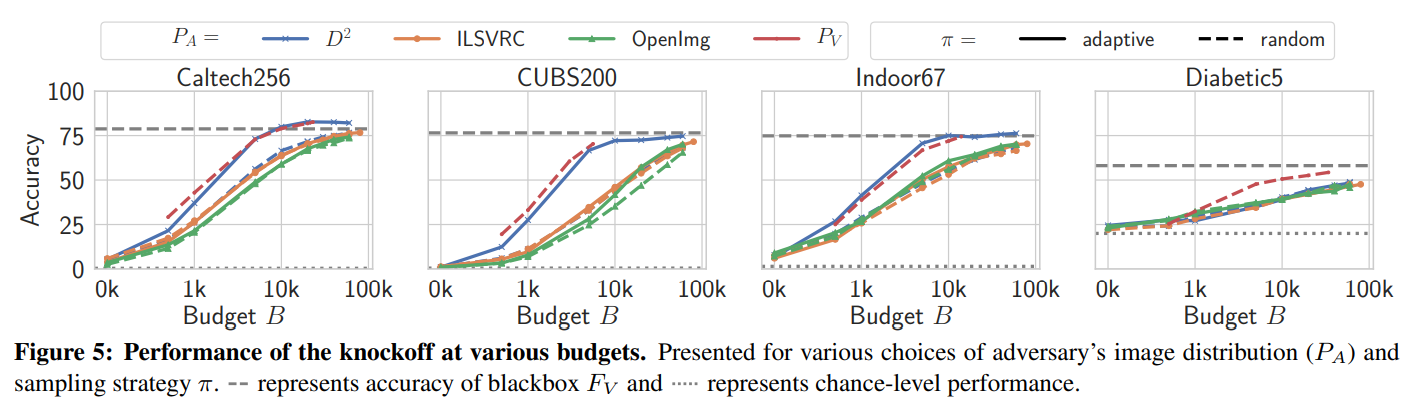
In the closed-world setting (\(D^2\)), the adaptive querying strategy generally showed the best performance.
Even though a much larger image distribution was used, the performance was comparable to knowledge distillation (\(P_V\)) using the same data as the target model.
In the open-world setting (ILSVRC, OpenImg), the adaptive querying strategy achieved modest performance improvements and sample efficiency gains.
The following are the visualization results of the adaptive querying policy:
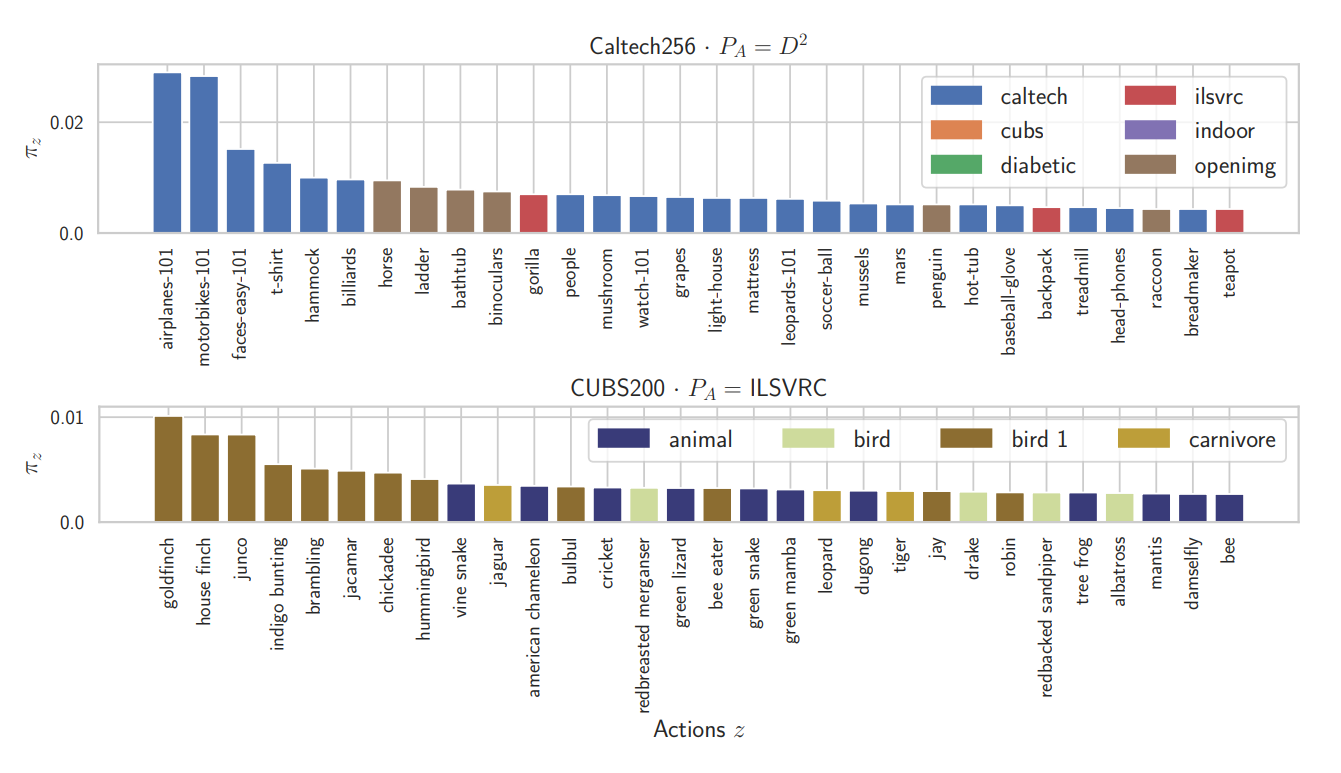
In the closed-world setting, images directly corresponding to the target model’s classes were used with high probability. Additionally, images from other datasets that represent those classes were also learned (e.g., Caltech256’s ladder).
In the open-world setting, there was no clear correspondence between the target model and query classes. However, higher-level concepts related to the target classes (birds, animals, etc.) were primarily selected.
The following are experimental results on model performance for each reward used in adaptive querying:
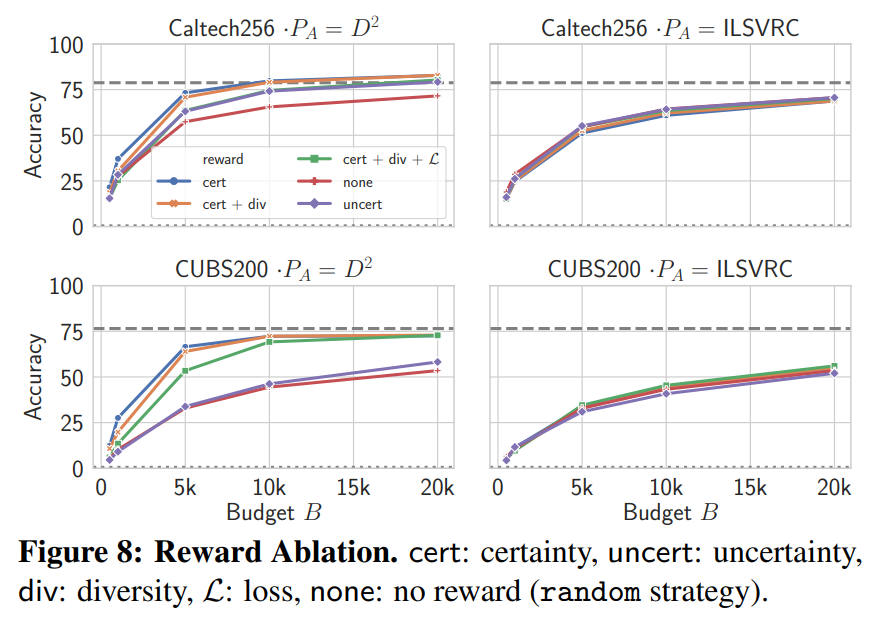
In the closed-world setting, the \(R^{cert}\) reward, which selects high-confidence samples, showed the best performance and was most effective at improving sample efficiency. The \(R^{uncert}\) reward, which selects uncertain samples, led to selection of completely irrelevant images, resulting in degraded performance.
In the open-world setting, all three rewards showed minimal or no performance improvement.
The following are performance experimental results by model architecture used for the knockoff model:
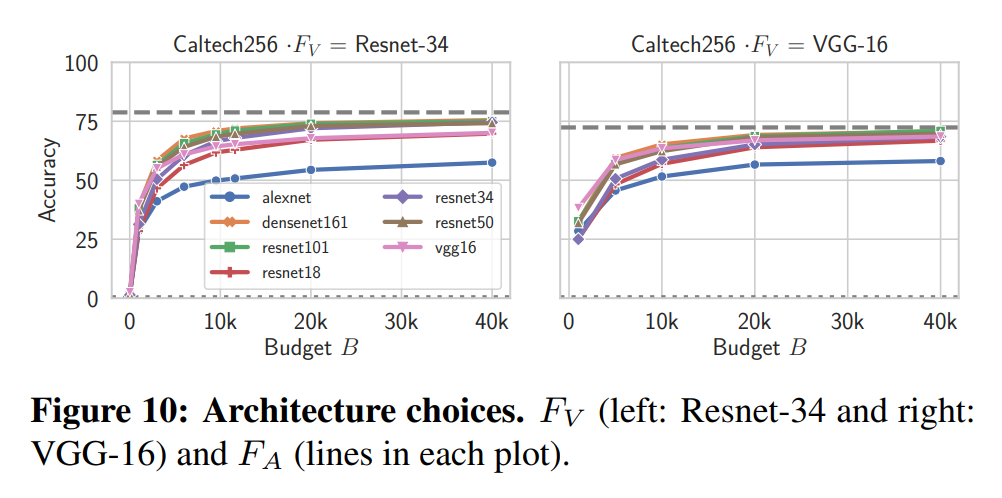
Performance was ordered by model complexity. The simplest AlexNet showed low performance, while the more complex ResNet-101 and DenseNet-161 showed high performance.
Cross-architecture replication was also possible. Both \(\text{VGG}\Rightarrow\text{ResNet}\) and \(\text{ResNet}\Rightarrow\text{VGG}\) maintained performance.
The following are experimental results targeting real-world commercial model APIs:
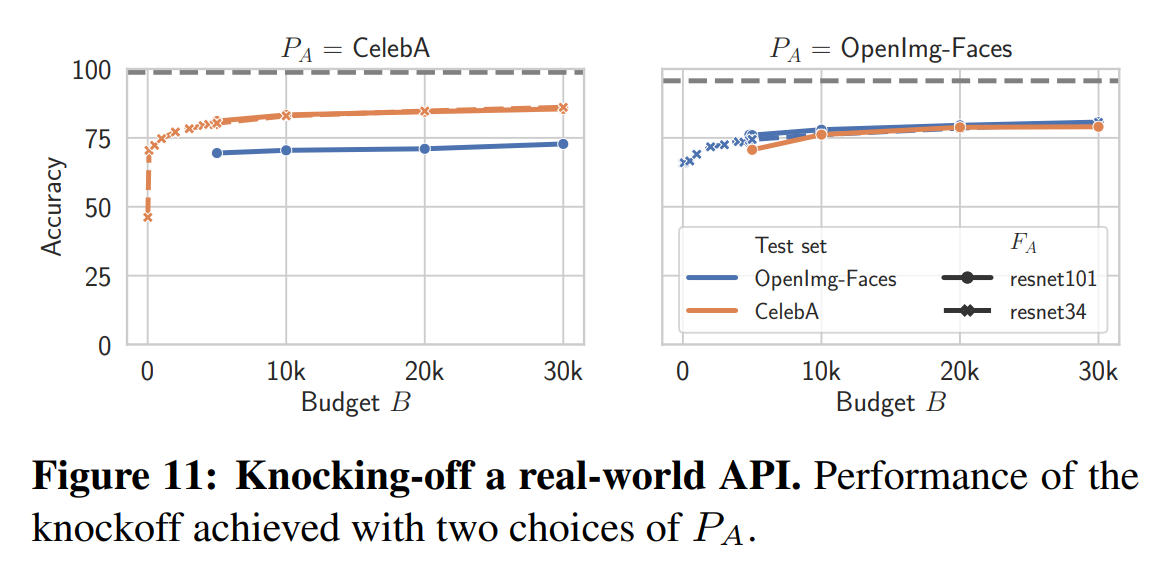
This experiment targeted a facial attribute prediction model API, using CelebA (220k images) and OpenImages-Faces (98k images) datasets. The query cost was $1-2 per 1000 queries.
Using the random sampling strategy, the knockoff model achieved 76-82% of the actual API’s performance. It was also confirmed that model complexity had little impact.
A knockoff model produced for around $30 demonstrated strong performance while saving enormous costs associated with image collection, expert labeling, and model tuning.
Conclusion
This study addressed the model functionality stealing problem and proposed the “Knockoff Nets” framework, which can effectively replicate the functionality of a target model using only black-box access. It experimentally demonstrated that high-performance knockoff models can be generated without prior information about the target model’s architecture or training data. Furthermore, experiments targeting real-world commercial image analysis APIs showed that knockoff models achieved high performance, demonstrating realistic threat potential.
These results suggest that functionality stealing is not just a theoretical concern but can be a direct threat in the real world. Therefore, new defense strategies for protecting machine learning models will be needed.