Paper: Amnesiac Machine Learning
Authors: Laura Graves, Vineel Nagisetty, Vijay Ganesh (University of Waterloo)
Venue: 35th AAAI Conference on Artificial Intelligence
URL: https://cdn.aaai.org/ojs/17371/17371-13-20865-1-2-20210518.pdf
This paper proposes an unlearning model to comply with GDPR’s “Right to be Forgotten” in the context of deep learning. In particular, it introduces Amnesiac Unlearning as a method to safely and efficiently remove learned data from trained neural networks without degrading network performance, while ensuring the model is not vulnerable to state-of-the-art data leakage attacks such as model inversion attacks and membership inference attacks.
Amnesiac Unlearning
What is Amnesiac Unlearning?
“Amnesiac Unlearning” is one of the unlearning methods – a technique for selectively removing specific data from machine learning models. It is an algorithm that removes traces of data by recording and then removing updates from batches containing the data requested for deletion.
Amnesiac Unlearning can effectively defend against data leakage attacks compared to other existing unlearning methods. When deleting a small amount of data, it effectively forgets the deletion-requested data while preserving the model’s performance to the greatest extent possible.
However, this method has the disadvantage that the model’s performance degrades exponentially as the amount of deletion-requested data increases. Therefore, it is necessary to choose the appropriate unlearning algorithm depending on the data processing situation.
Random Labeling Unlearning
This paper uses a random labeling approach as an experimental group alongside Amnesiac Unlearning. The random labeling approach re-labels sensitive or deletion-requested data with randomly selected incorrect labels, then retrains the network for several iterations with the modified dataset.
For example, in image classification, if an image is classified as “cat,” it would be changed to an incorrect label such as “dog,” significantly reducing the classification performance for “cat.”
The following is the code implementation for the random labeling approach.
import torch
import copy
import random
target_index = [] # Deletion-requested data
nontarget_index = [] # Remained data excluding deletion-requested data
# Set 81 as the deletion-requested data
for i in range(0, len(testdata)):
if testdata[i][1] == 81:
target_index.append(i)
else:
nontarget_index.append(i)
# Deep copy all elements of traindata to create unlearning_data
unlearning_data = copy.deepcopy(traindata)
unlearning_labels = list(range(100))
unlearning_labels.remove(81)
# Randomly change the labels of deletion-requested data (81)
for i in range(len(unlearning_data)):
if unlearning_data.targets[i] == 81:
unlearning_data.targets[i] = random.choice(unlearning_labels)
# Create a new training data loader
unlearning_train_loader = torch.utils.data.DataLoader(unlearning_data, batch_size=64, shuffle=True)
In this code, assuming 81 is the deletion-requested data, it changes 81 to a random different class value to assign a new label, then separates the unlearning data and remain data.
About the Amnesiac Unlearning Algorithm
The formula describing the Amnesiac Unlearning algorithm is as follows:
\[\theta_{M'} = \theta_{initial} + \sum_{e=1}^{E} \sum_{b=1}^{B} \Delta \theta_{e,b} - \sum_{sb=1}^{SB} \Delta \theta_{sb} = \theta_M - \sum_{sb=1}^{SB} \Delta \theta_{sb}\]This formula expresses the approach of removing the batch updates containing the deletion-requested data from the existing model’s parameters.
The fewer batches that contain deletion-requested data, the smaller the difference between the original model and the model with unlearning applied, resulting in less impact on model efficiency.
This algorithm removes learned information of sensitive data with laser-like precision and can remove learned data for a single record from the model with minimal impact.
The following is a code implementation example of Amnesiac Unlearning.
def train(model, epoch, loader, returnable=False):
model.train()
delta={}
#Performs initialization on the weights and biases of the PyTorch model
for param_tensor in model.state_dict(): #Returns a dictionary containing all learnable parameters (weights and biases) of the PyTorch model
if "weight" in param_tensor or "bias" in param_tensor:
delta[param_tensor] = 0
if returnable:
thracc=[]
nacc=[]
for batch_idx, (data, target) in enumerate(loader):
#If target class is 81, save the model's weights and biases before training
if 81 in target:
before={}
for param_tensor in model.state_dict():
if "weight" in param_tensor or "bias" in param_tensor:
before[param_tensor] = model.state_dict()[param_tensor].clone()
optimizer.zero_grad()
output=model(data)
loss=criterion(output, target)
loss.backward()
optimizer.step()
#If target class is 81, save the model's weights and biases after training
if 81 in target:
after={}
for param_tensor in model.state_dict():
if "weight" in param_tensor or "bias" in param_tensor:
after[param_tensor] = model.state_dict()[param_tensor].clone()
#Update weight changes
for key in before:
delta[key]=delta[key] + after[key]-before[key]
if batch_idx % log_interval==0: #Print training status at intervals of 10
print("\rEpoch: {} [{:6d}]\tLoss: {:.6f}".format(
epoch, batch_idx*len(data), loss.item()
), end="")
if returnable and False:
#Save accuracy for target data
thracc.append(test(model, target_test_loader, dname="Threes only", printable=False))
#Save non-target data accuracy every 10th batch
if batch_idx % 10 ==0:
nacc.append(test(model, nontarget_test_loader, dname="nonthree only", printable=False))
model.train()
if returnable:
return thracc, nacc, delta
As shown in this code, when the deletion-requested data 81 is included, the model’s weights and biases are saved before and after training, and their difference (batch update) is recorded. Therefore, the core concept of Amnesiac Unlearning is to delete the parameter update delta for the deletion-requested data when a deletion request is received.
Data Leak Attack
Model Inversion Attack
A model inversion attack is a class information leakage attack that allows an attacker to acquire generalized information that should not be accessible in principle.
For example, if an attacker discovers that the class with a high risk of cancer is generalized as “mainly elderly males,” the attack is considered successful. In other words, through model inversion attacks, an attacker can learn what the target class represents.
Membership Inference Attack
A membership inference attack is an attack that infers whether a specific record or set of records is included in the training data. For example, if an attacker learns that a certain individual is included in the dataset used to train a model that predicts bankruptcy risk, the attack is considered successful.
In this case, the membership inference attack assumes that the attacker has data with a distribution similar to the data used to train the target model.
Performance Verification
To verify the performance of Amnesiac Unlearning, this paper proposes three methods.
The basic experiments are conducted using PyTorch on the MNIST handwritten digit dataset and CIFAR-100, with ResNet18 as the target model.
Retrain-Based & Accuracy-based
To verify the performance of Amnesiac Unlearning, this paper compares the performance of a model simply retrained after removing deletion-requested data from the original data, a model with random labeling unlearning applied, and a model with Amnesiac Unlearning applied.
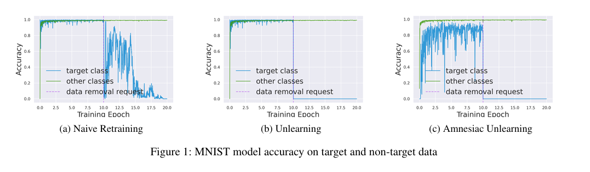
The graphs below show the results of training three models – retraining, random labeling, and Amnesiac Unlearning – on the MNIST handwritten digit dataset. All three methods confirm that the model’s accuracy on the remaining data (Remain Data) is maintained.
However, in the case of simple retraining, it takes a relatively long time for the model to forget the information contained in the deletion-requested data. In comparison, random labeling unlearning and Amnesiac Unlearning show a sharp drop in accuracy for deletion-requested data after the deletion request.
Among the three methods, Amnesiac Unlearning forgets data the fastest. The drop in accuracy for deletion-requested data means that the model is forgetting the data.

The graphs below show the results of training the three models on the CIFAR-100 dataset. We can see that the results for CIFAR-100 are similar to those for the MNIST handwritten digit dataset.
Attack-Based
To verify the performance of Amnesiac Unlearning, this paper performs model inversion attacks and membership inference attacks on the three models and compares the attack success rates on the deletion-requested data.
A lower success rate for model inversion attacks and membership inference attacks indicates that the deletion-requested data is being forgotten well, meaning the unlearning performance is high.

The original model is vulnerable to model inversion attacks, allowing the attacker to extract information about specific classes.
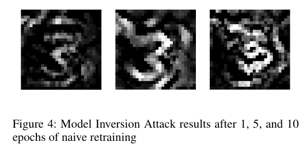
In the case of simple retraining, even after 10 epochs, the class characteristics remain recognizable. This confirms that there is virtually no effect in preventing sensitive class information leakage.

In contrast, the random labeling unlearning approach immediately blocks the acquisition of useful class information. From the first epoch, the original form becomes very difficult to recognize, and defense performance increases with each subsequent epoch.

Amnesiac Unlearning, like the random labeling approach, immediately blocks the acquisition of useful class information. In particular, since there is almost no gradient information available to the attacker, the inverted images fail to reproduce (reconstruct) the original form. In other words, both the random labeling approach and Amnesiac Unlearning effectively defend against model inversion attacks.
Next, this paper measures the defense performance against membership inference attacks for the three models. A lower membership inference attack success rate on unlearning target data indicates higher unlearning performance.
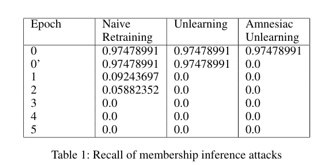
Here, epoch 0 in the table represents the membership inference attack results before data removal, and epoch 0’ represents the attack results after data modification but before retraining.
Simple retraining shows an inability to completely defend against membership inference attacks immediately. In contrast, both random labeling and Amnesiac Unlearning models can effectively defend against membership inference attacks with only retraining within 1 epoch. The reason random labeling shows no defense effect at epoch 0’ is that even though the label of specific data has been changed, the model’s internal weights remain intact, meaning traces of having learned that data still exist within the model.
Conclusion
Amnesiac Unlearning is highly effective at removing information learned from specific data samples, but using it too frequently can have a significant impact on model performance. That is, when there is a large amount of deletion-requested data, the model’s performance decreases sharply, creating a risk in terms of usability.
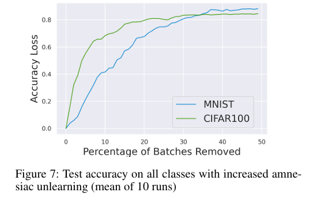
As shown in the graph above, when less than 1% of batches are removed, the model’s accuracy can be guaranteed, but as the number of removed batches increases, the model’s accuracy decreases sharply.
Therefore, when removing a small amount of data, Amnesiac Unlearning can be a good approach as it effectively forgets data while defending against data leakage attacks without significantly impacting the overall model. However, when removing a large amount of data, it is necessary to consider alternative unlearning approaches.