Paper: Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
Authors: Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, Sifia Liu
Venue: 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
Advances in Diffusion Models and Unlearning
Diffusion models are trained on extensive online datasets to generate realistic images. However, because their training relies on content from diverse internet sources, safety concerns arise as inappropriate text inputs can lead the model to generate not-safe-for-work (NSFW) images.
To address this, the concept of unlearning has been introduced into diffusion models to prevent the generation of unwanted content even when faced with inappropriate prompts. Nevertheless, these models remain vulnerable to attacks such as UnlearnDiffAtk, which can restore concepts that were previously targeted for unlearning.
Background
LDMs and ESD
LDMs are models that achieve outstanding performance in text-to-image generation, operating by integrating text prompts into image embeddings to guide the generation process. They consider both the semantics and visual elements of the text to generate the image requested by the prompt. This process involves progressively removing noise from a noisy image representation to produce a clean image.
Subsequently, the ESD (Erasing Specific Concepts) approach was introduced to address vulnerabilities in LDMs while maintaining model performance. The following equation describes the ESD algorithm.
\[\begin{equation} \min_{\theta} \ell_{ESD} (\theta, c_e) := \mathbb{E} \left[ \left\| \epsilon_{\theta} (x_t \mid c_e) - \left( \epsilon_{\theta_o} (x_t \mid \emptyset) - \eta \left( \epsilon_{\theta_o} (x_t \mid c_e) - \epsilon_{\theta_o} (x_t \mid \emptyset) \right) \right) \right\|_2^2 \right] \end{equation}\]First, the influence of inappropriate content is calculated by subtracting the noise generated from a base image without inappropriate content from the noise of an image containing inappropriate content. Then, this influence is subtracted from the original image to remove the impact of the inappropriate content.
AT-ESD and AdvUnlearn
Even with the introduction of the ESD concept, the model remains vulnerable to adversarial attacks. Therefore, the concept of Adversarial Unlearning was introduced to defend against adversarial prompt attacks using adversarial examples. This concept is also referred to as AT-ESD.
This paper proposes a bi-level optimization method in which the defender and attacker are classified as the upper level and lower level respectively within the existing AT-ESD framework, and this is called AdvUnlearn.

The attacker generates optimal attack prompts through a process that minimizes loss during adversarial prompt generation, while the defender trains to eliminate the attack prompts optimized by the attacker. The two optimization problems are interconnected, with the upper level and lower level alternating.
Efficiency and Effectiveness of AdvUnlearning
If the ESD unlearning concept is simply applied at the upper level, there is a risk of significantly degrading the utility of the diffusion model. Therefore, it is necessary to maintain robustness against adversarial attacks while preserving the utility of the diffusion model.
Additionally, due to the modularity of diffusion models, the appropriate location for applying AT and the method for efficient implementation need to be determined.
Effectiveness
The following table and figure show the results of measuring the success rate of adversarial attacks and the degree of image quality degradation for a diffusion model without unlearning, and models with AT-ESD and ESD applied.

In the case of AT-ESD, ESD was used as the upper-level optimization problem and combined with adversarial prompt generation to reduce the adversarial attack success rate. However, this significantly decreased image generation quality. The reason for the image quality degradation in AT-ESD is that ESD focused on removing inappropriate concepts, and the additional adversarial training left insufficient capacity to maintain image quality.
Therefore, this paper devised AdvUnlearn by additionally utilizing retention data to encourage the model to maintain its general image generation capability on top of AT-ESD. The retention data uses an LLM as a discriminator to keep only text prompts unrelated to inappropriate content and generates additional prompts from external datasets such as COCO and ImageNet. The final set consists of 243 diverse prompts, with 5 prompts randomly sampled during training.
As shown in the table above, AdvUnlearn with retention data showed weakened robustness against adversarial attacks due to increased model utility, but demonstrated superior defense effectiveness compared to the standard ESD approach, relatively maintaining a balance between model utility and robustness.
Efficiency
Text Encoder
The conventional ESD unlearning was applied to the UNet module of the DM (Diffusion Model), but this approach has the drawback of not sufficiently improving the robustness of AdvUnlearn. Therefore, this paper addresses this drawback by applying unlearning to the text encoder instead of the UNet module. Using the text encoder provides three major advantages over the UNet module.
First, the text encoder has fewer parameters than the UNet module, allowing training to converge faster. Second, once the text encoder is unlearned, it can be applied to other DMs in a plug-in fashion. Third, the causal factors related to the visual image generation of the DM are concentrated in the text encoder, so modifying the text encoder can effectively control the image generation results of the entire model.
The last advantage is closely related to robustness improvement. The text encoder is the core module that determines what the model will generate. Since the UNet module is a post-processing stage, it cannot recover from text perturbations, and once an image is generated based on incorrect text conditions, there is no way to correct it. However, when the text encoder has learned a specific concept, directly modifying it can prevent that concept from being generated through text prompts. For example, if the concept of “nudity” is removed from the text encoder, prompts like “a nude woman” lose their meaning, preventing the model from generating such inappropriate images. In other words, the incorrect condition itself can be learned and removed.
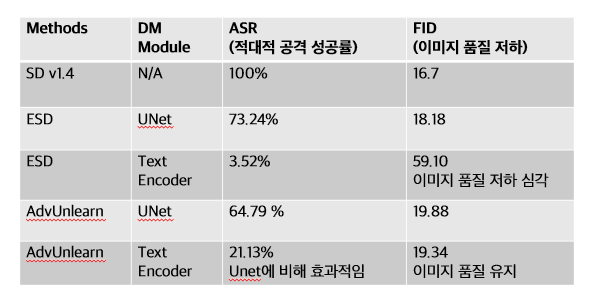
As shown in the following experimental results, applying the AT-ESD concept to the text encoder reduced the adversarial attack success rate compared to the UNet module, and was also advantageous for maintaining image quality.
Fast-AT
To improve the efficiency of AdvUnlearn, the lower-level optimization that generates adversarial prompts can be simplified. This concept is similar to the Fast AT technique used in image classification, utilizing FGSM (Fast Gradient Sign Method) to update weights with a single gradient computation (one-shot technique), which requires significantly less computation and enables faster training speed compared to the conventional approach.
The following equation represents the FGSM technique:
\[\begin{equation} \delta = \delta_0 - \alpha \cdot \text{sign} \left( \nabla_{\delta} \ell_{\text{atk}} (\theta, c + \delta_0) \right) \end{equation}\]This process generates a new adversarial prompt by adding a prefix vector to the original prompt, where the sign function outputs -1 for values less than 0, 0 for 0, and 1 for values greater than 0, playing the role of determining the direction of the gradient. Unlike standard gradient descent, this approach moves the weight update in the direction that maximizes the loss function.
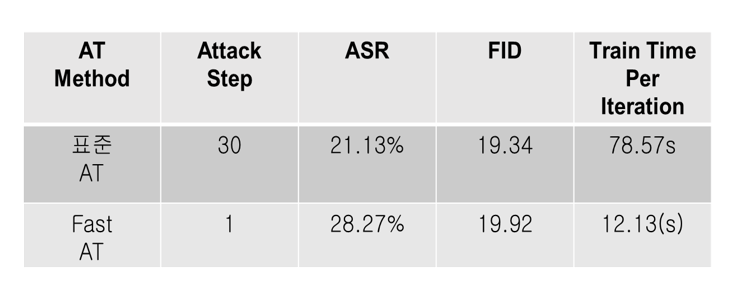
As shown in the results in the following table, using Fast-AT results in faster training speed. However, the adversarial attack success rate increased conversely, so it is necessary to select the algorithm considering the trade-off between computational cost and robustness during the AdvUnlearn process. In other words, Fast-AT is preferable when training efficiency is important, and Standard AT is advantageous when robustness is more critical.
Evaluation of Amnesiac Unlearning Performance
Experiments were conducted to verify the performance of the AdvUnlearn model, which applies adversarial training to the text encoder. Previously published unlearning algorithms such as SalUn, ESD, UCE, and FMN were used as baselines, and experiments on nudity unlearning to prevent the generation of harmful content from nude-related prompts were conducted. The goals to verify are robustness against adversarial prompts and image generation quality.
Robustness Against Adversarial Prompts and Image Quality Verification
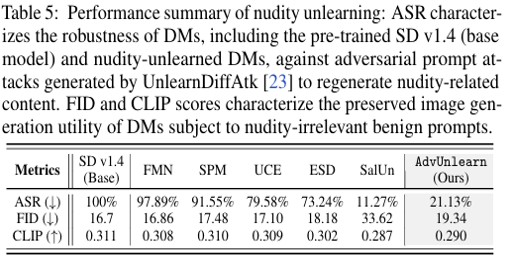
As shown in the results, AdvUnlearn significantly reduced the ASR (Adversarial Attack Success Rate) from 100% to 21.13%, improving robustness, while maintaining image quality metrics such as FID and CLIP Score at levels similar to the original SD v1.4 model. Unlike AdvUnlearn, SalUn achieved an ASR of 11.27%, showing the strongest robustness, but had a significant increase in FID, indicating it could not guarantee image quality.
Plug-and-Play Feasibility Verification
Next, the plug-in feasibility of AdvUnlearn is verified. The goal is to evaluate whether a text encoder trained with AdvUnlearn on the SD v1.4 model can be directly used in other DMs. This experiment verifies whether the text encoder trained on SD v1.4 can also be used in other models such as SD v1.5, DreamShaper, and Protogen.

As shown in the results, ASR decreased across all models compared to the original SD v1.4, and FID and CLIP Score also maintained similar levels of difference, confirming that AdvUnlearn’s text encoder can be directly used across multiple DMs.
Defense Performance Verification Against Adversarial Attacks
This experiment was conducted to verify AdvUnlearn’s defense performance against various adversarial attacks. Adversarial attacks can be broadly divided into text-based attacks and attacks that manipulate embedding vectors.
Text-based attacks restore concepts by modifying words or sentences (prompts). For example, “a nude woman” is transformed into “a beautiful lady with soft skin.”
There are also methods that circumvent concepts by reconstructing text prompts.
Attacks that manipulate embedding vectors transform words whose concepts have been removed into new embedding vectors with similar meanings. In other words, erased words are converted into “hidden vectors” to reactivate them.
For example, when the embedding vector for “nude” is [0.23, -1.45, 0.89, …0.76], the model is fooled by a fake word (vector) such as “icecream” = [0.22, -1.40, 0.91, …0.75] that is similar to “nude” but can express the concept.
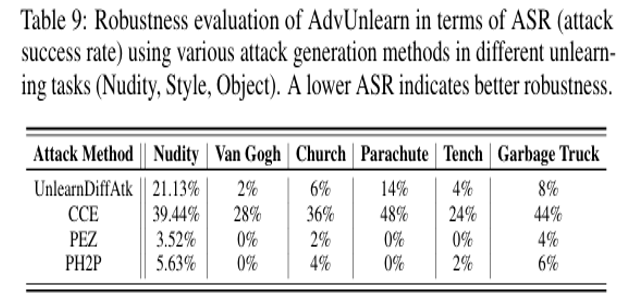
This experiment compared the robustness of AdvUnlearn against various types of adversarial attacks. As shown in the results, AdvUnlearn demonstrates excellent defense performance against general text-based attacks such as UnlearnDiffAtk, PEZ, and PH2P, but is relatively vulnerable to CCE, which manipulates embedding vectors. This is because attacks that manipulate the continuous embedding space possess stronger attack power than typical text-based attacks.
Conclusion
Currently, unlearned DMs remain vulnerable to adversarial prompt attacks. AdvUnlearn proposed in this paper presents a potential strategy that enhances robustness against such attacks while preserving image generation quality.
In particular, this paper introduces a regularization technique that maintains image quality to preserve model performance on a retained prompt set, and confirms that the text encoder is more effective than the UNet of DMs in securing robustness.
Through experiments across various scenarios, it was demonstrated that AdvUnlearn can maintain a balance between robust unlearning and image generation quality. While the Fast-AT technique can improve the speed of AdvUnlearn, continuously improving computational efficiency remains an important research challenge.