Paper: Evaluating Machine Unlearning via Epistemic Uncertainty
Authors: Alexander Becker, Thomas Liebig
Introduction
Machine Unlearning refers to training techniques that remove specific data from a trained model.
This paper proposes an efficient and quantitative metric for measuring the performance of machine unlearning models using the concept of Epistemic Uncertainty. To validate the metric, two hypotheses are established and verified by applying them to three machine unlearning models.
Preliminary
Retraining
Based on the concept of differential privacy, it guarantees the performance difference before and after data deletion (Certified Removal). Differential privacy is defined by the following formula.
\[e^{-\epsilon} \leq \frac{P(U(A(D), D, x) \in T)}{P(A(D \setminus \{x\}) \in T)} \leq e^{\epsilon}\]Amnesiac Unlearning
The parameters of the pre-trained model are reverted by the amount influenced by the data to be removed at a specific epoch e and batch b.
\[U_{AU}(\theta, D_f) = \theta - \sum_{e=1}^{E} \sum_{b=1}^{B} 1\left[D_f \cap D_{e,b} \neq \emptyset\right] \Delta_{\theta_{e,b}}\]Fisher Forgetting
Noise n following a normal distribution is added to the parameters to conceal the performance difference from the Retraining model. It is defined as the original parameters plus noise adjusted by hyperparameters.
\[U_{FF}(\theta, D_f) = \theta + \alpha^{\frac{1}{4}} F^{-\frac{1}{4}} n\]Adversarial Attack
Among adversarial attacks, the result of MIA (Membership Inference Attack) is used to verify whether specific data has been removed.
Main Content
This paper measures and evaluates the efficacy of each machine unlearning technique using evaluation metrics based on information theory and epistemic uncertainty.
Evaluation Metric Using Epistemic Uncertainty
“Epistemic Uncertainty” refers to the remaining influence of removed data in the model.
By calculating the information content of the removed data using the Fisher Information Matrix (FIM), the epistemic uncertainty of the model regarding that data can be measured. The paper reduces the computational complexity of the information content formula based on the Marquart-Levenberg approximation and presents it as follows.
\[\iota(\theta; D) = \operatorname{tr} \left( \mathcal{I}(\theta; D) \right) = \frac{1}{|D|} \sum_{i=1}^{|\theta|} \sum_{x, y \in D} \left( \frac{\partial \log p_{\theta}(y | x)}{\partial \theta_i} \right)^2\]This represents the total information that the model has about the dataset, indicating the degree to which the parameters are sensitive to the model’s performance. In other words, at specific parameters, the model’s total information represents the model’s uncertainty about the dataset.
Efficacy Score
To address side effects such as the Streisand effect that occur during data removal, this paper proposes the efficacy score. A lower efficacy score indicates that epistemic uncertainty about the data to be removed has increased.
\[\text{efficacy}(\theta; D) = \begin{cases} \frac{1}{\iota(\theta; D)}, & \text{if } \iota(\theta; D) > 0 \\ \infty, & \text{otherwise} \end{cases}\]As the dataset size or model size increases, the computational cost for each data point increases. To address this issue, the following theoretical upper bound is presented.
\[\text{efficacy}(\theta; D) \leq \frac{1}{\left\| \nabla \mathcal{L}(\theta, D) \right\|_2^2}\]Experiments and Results Analysis
This paper verifies the following two hypotheses.
- Hypothesis (1): When a pre-trained model is trained with a machine unlearning technique, the efficacy score for the removed data will always decrease.
- Hypothesis (2): A lower efficacy score always reduces the success rate of adversarial attacks.
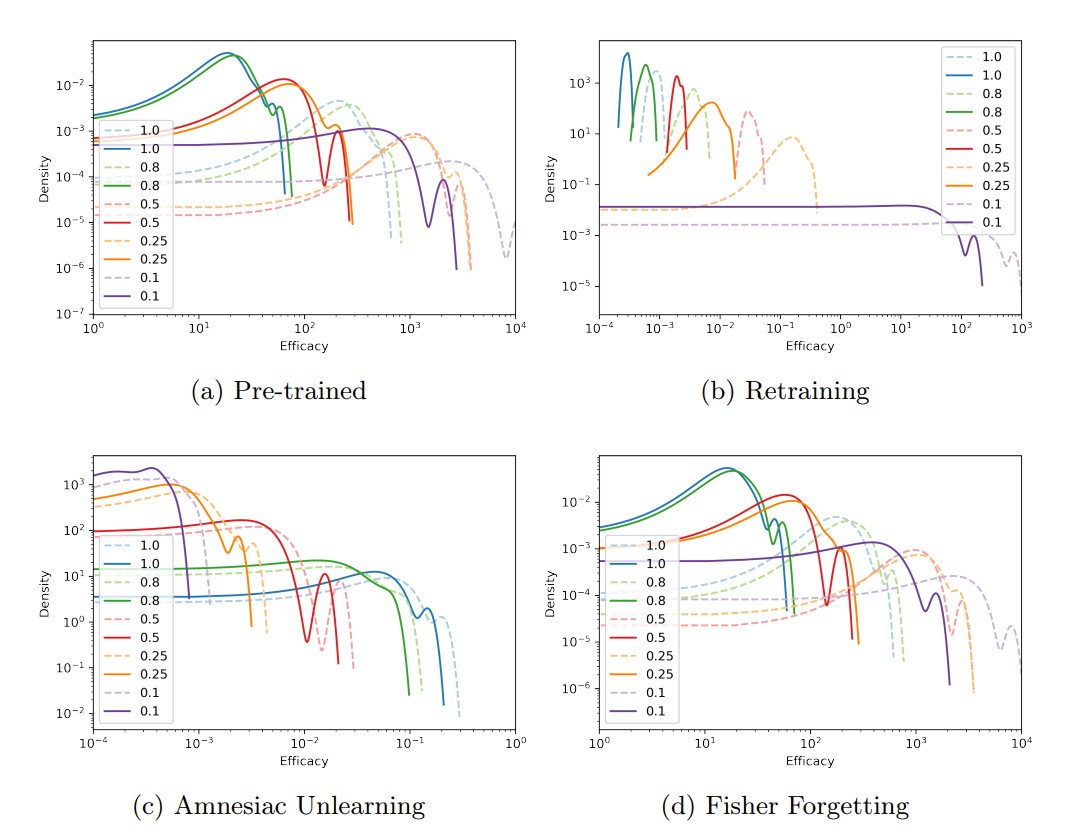
(b) Retraining and (d) Fisher Forgetting results show that the efficacy score decreases as the data removal ratio increases, satisfying Hypothesis (1).
However, (c) Amnesiac Unlearning results show that the efficacy score increases as the data removal ratio increases, rejecting Hypothesis (1). This is because the parameter adjustment methods of machine unlearning differ. In cases (b) and (d), the parameters change to narrow the performance gap with the Retraining result, whereas in case (c), the parameters narrow the performance gap with the model before pre-training.
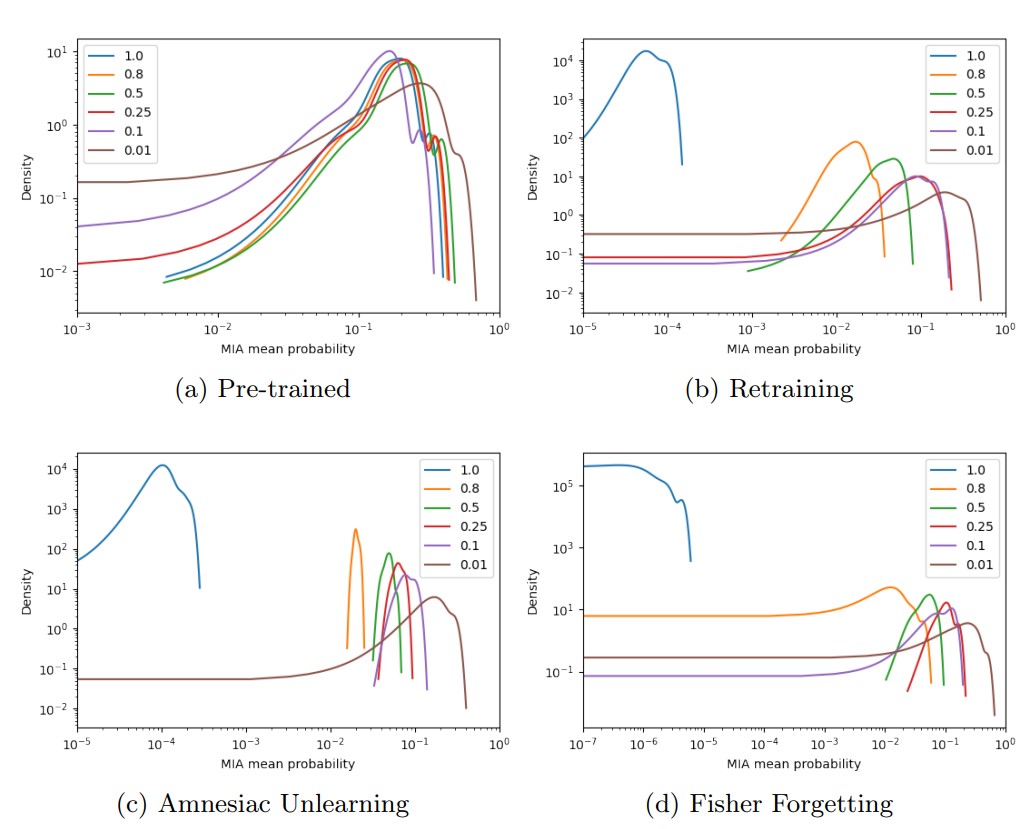
Results from (b), (c), and (d) show that the MIA attack success rate always decreases as the data removal ratio increases. This is used to examine the relationship between the efficacy score and the MIA success rate.
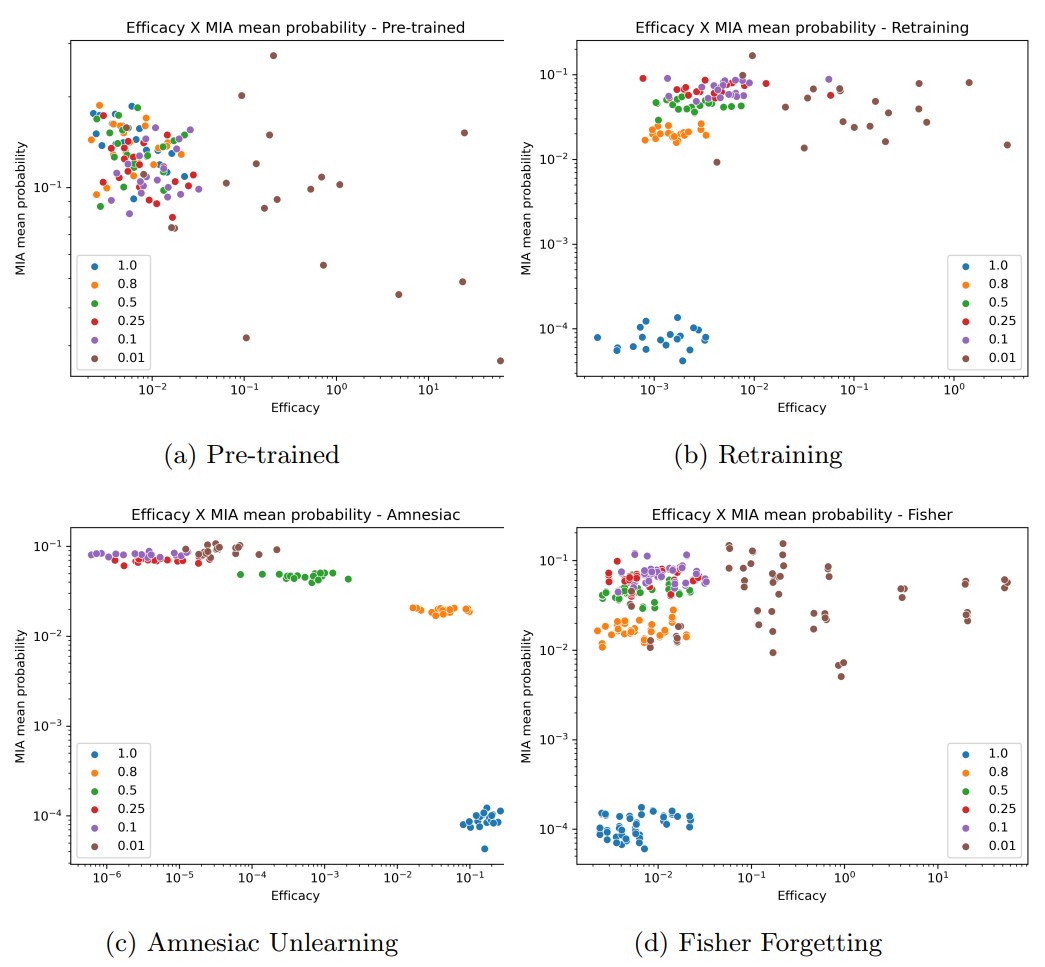
In (b) and (d), the MIA attack success rate decreases as the efficacy score decreases, but (c) shows the opposite result. Hypothesis (2) can also be explained by the same reason that Hypothesis (1) was rejected.
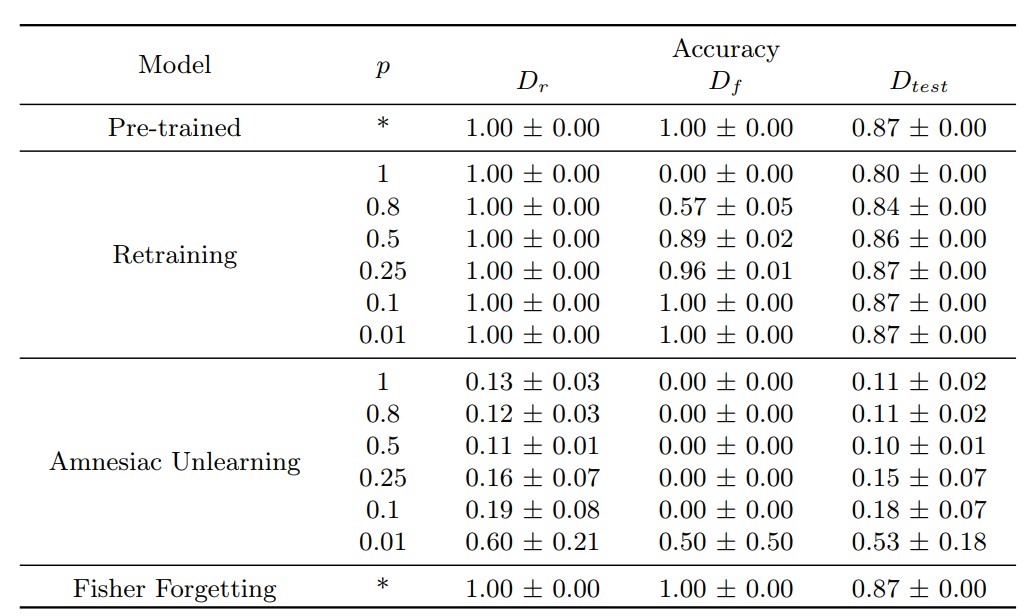
In the experiment measuring the accuracy of each machine unlearning technique using the efficacy score, the results shown in the table below were obtained. Overall, low accuracy is observed, and even in Retraining, which guarantees complete data removal, the accuracy is not high.
Conclusion
This paper proposes the efficacy score based on the concept of epistemic uncertainty as a metric for measuring information content, and verifies its utility by measuring three machine unlearning methods.
However, the fact that both hypotheses proposed in the paper were rejected, along with the accuracy measurement results of each machine unlearning technique shown below, raises questions about the utility of this evaluation metric. Nevertheless, the approximation of the information content calculation formula to reduce computational complexity, and the interpretation of information content from the perspective of epistemic uncertainty, will be useful for evaluating the accuracy of comprehensive unlearning techniques in the future.