Paper: Extracting Robust Models with Uncertain Examples
Authors: Guanlin Li, Guowen Xu, Shangwei Guo, Han Qiu, Jiwei Li, Tianwei Zhang
Venue: ICLR 2023
Introduction
With the growing awareness that DNNs are vulnerable to adversarial attacks, there has been an increasing trend of deploying robust models that are resilient to adversarial attacks. However, how to extract such robust models has not been previously studied. Therefore, this paper proposes a new attack technique called robustness extraction.
First, it points out that existing attacks fail to simultaneously extract both accuracy and robustness, or cause robust overfitting. It then proposes a new model extraction attack called Boundary Entropy Searching Thief (BEST) for extracting both accuracy and robustness under limited attack budgets.
BEST generates uncertain examples (UEs) for querying the original model. These samples have uniform confidence scores across multiple classes, allowing them to perfectly balance model accuracy and robustness.
Through experiments, this study demonstrates that BEST outperforms existing attack methods across various settings. It also reveals that BEST can circumvent existing extraction defense techniques.
Main Content
Threat Model
-
Victim model \(M_V\): Built through adversarial training, it is robust against adversarial examples (AE). It returns either logits vectors or hard labels.
-
Attacker \(A\): Creates a substitute model based on the victim model’s outputs. The attacker does not know the victim model’s architecture, training algorithm, or hyperparameters. The attacker does not even know whether the victim model has undergone adversarial training. The attacker only needs to collect data samples \(D_A\) from the same domain as the victim model, and this data does not need to follow the same distribution as the victim model’s training set. The attacker must consider the reduction of two attack budgets:
-
\(B_Q\): The query budget is defined as the number of queries the attacker sends to the victim model.
-
\(B_S\): The synthesis budget is defined as the computational cost of generating each query sample.
The attacker may use publicly available pre-trained models to reduce attack costs. The pre-trained model’s training set may be completely different from the victim model’s training set.
-
-
Substitute model \(M_A\): The model created by the attacker, which should have prediction performance similar to the victim model on both natural samples and adversarial examples.
Existing Attack Strategies and Limitations
Various attack strategies have been proposed to extract models with high accuracy and fidelity, and these can be classified into two categories.
Extraction with Clean Samples
The attacker samples query data from public datasets and trains a substitute model based on that data and the victim model’s predictions. The initial study Tramer used this strategy, and this paper refers to this attack as Vanilla.
Approaches combining active learning have also been proposed. In these approaches, the attacker constructs a large dataset of diverse natural images and actively selects optimal samples for the extraction attack. Representative examples include Knockoff Nets and ActiveThief.
Extraction with Adversarial Examples
The attacker generates adversarial examples (AE) using the substitute model to identify the victim model’s classification boundaries and uses them as query samples. A representative example is CloudLeak.
Some attacks also combine active learning to iteratively generate AEs. For example, JBDA generates AEs using FGSM and iteratively improves the substitute model based on the victim model’s predictions.
The above attack strategies may be effective for accuracy or fidelity extraction, but are ineffective for robustness extraction for the following reasons.
First, the substitute model cannot be trained to be robust using only clean samples. Therefore, strategies using clean samples cannot extract the victim model’s robustness.
Second, training the substitute model with AEs may decrease accuracy on natural samples. Additionally, it can easily overfit to training AEs, reducing robustness against test AEs.
To demonstrate this, the paper conducts the following experiment.
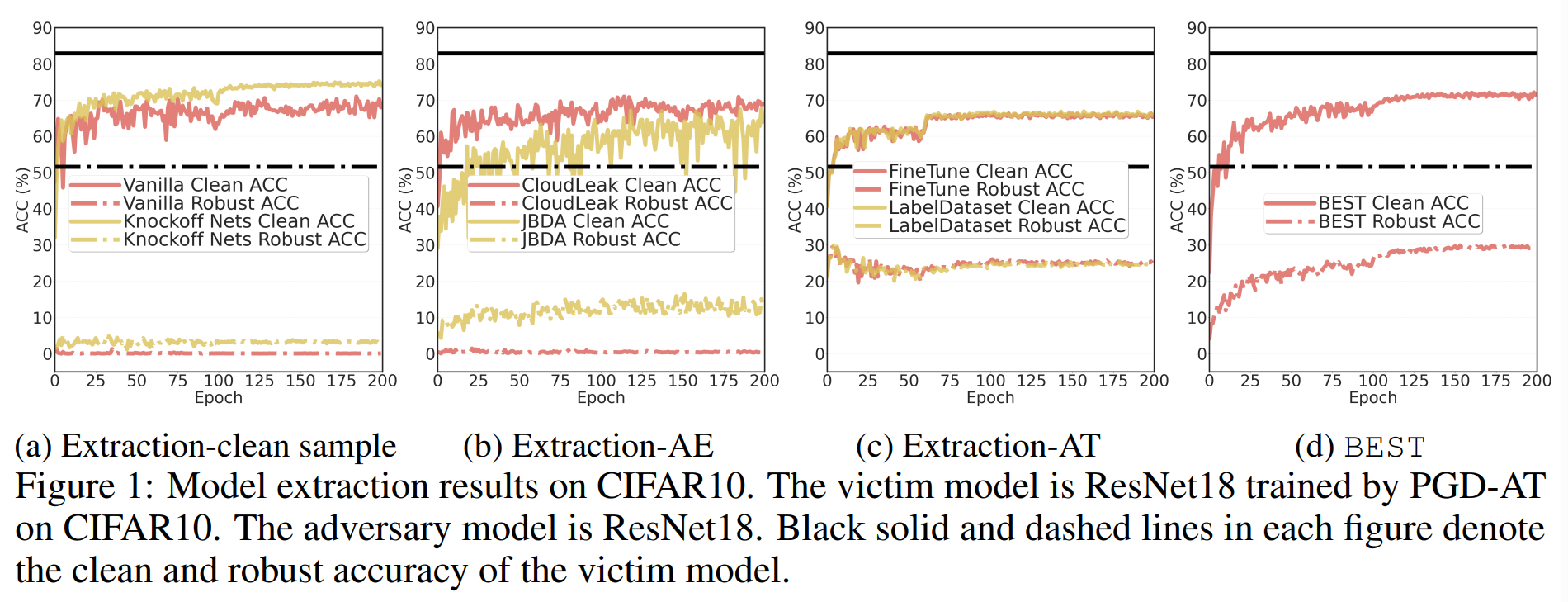
The above experiment compares extraction performance based on the substitute model’s training method, using CA and RA as performance evaluation metrics.
-
CA (Clean Accuracy): Accuracy on natural samples
-
RA (Robust Accuracy): Accuracy on adversarial examples
The solid and dashed black lines represent the victim model’s CA and RA, respectively, serving as benchmarks for comparison with the substitute model’s extraction performance.
(a): Results from training the substitute model with only natural samples. CA is high but RA is very low. This indicates failure to extract the victim model’s robustness.
(b): Results from training the substitute model using AEs. Overall, CA is lower compared to (a). However, CloudLeak maintains high CA like (a). This is because the AEs generated by CloudLeak have low transferability to the victim model. Despite using AEs for training, RA remains low.
(c): Results from a strategy that sequentially performs accuracy extraction and adversarial training to obtain robustness.
-
LabelDataset first receives predictions from the victim model using Vanilla or CloudLeak to create a labeled dataset. Then, using this dataset as ground truth, it performs adversarial training from scratch on a separate substitute model.
-
FineTune first extracts a high-accuracy substitute model using CloudLeak, then fine-tunes the model with adversarial examples generated against the substitute model to add robustness.
The (c) strategies show RA decreasing at the beginning of training. This is the Robust Overfitting phenomenon, where the substitute model overfits to adversarial training AEs and fails to be robust against test AEs. The cause is that the limited attack budget in this experiment did not provide sufficient data for adversarial training.
As such, existing attack strategies either missed accuracy or robustness, or showed limitations in securing both.
Requirements for New Query Samples
A substitute model that has undergone adversarial training acquires useful robust features that defend against specific AEs with very high confidence. However, such features are equivalent to overfitting to specific attack patterns, actually causing side effects like robust overfitting and CA degradation on natural samples, as seen in the experiments above.
Therefore, new query samples to replace existing AEs must satisfy the following two conditions:
-
First, they must not induce robust overfitting.
-
Second, they must effectively reflect the victim model’s decision boundary to prevent CA degradation.
This paper proposes Uncertain Examples (UEs) as query samples that satisfy these conditions.
Uncertain Examples
UEs aim to confuse the substitute model.
Given a substitute model \(M: \mathbb{R}^N \to \mathbb{R}^n\) and input \(\quad x \in \mathbb{R}^N\), we define \(\quad x\) as a \(\delta-UE\) if it satisfies the following:
\[\text{softmax}(M(x))_{\max} - \text{softmax}(M(x))_{\min} \leq \delta\]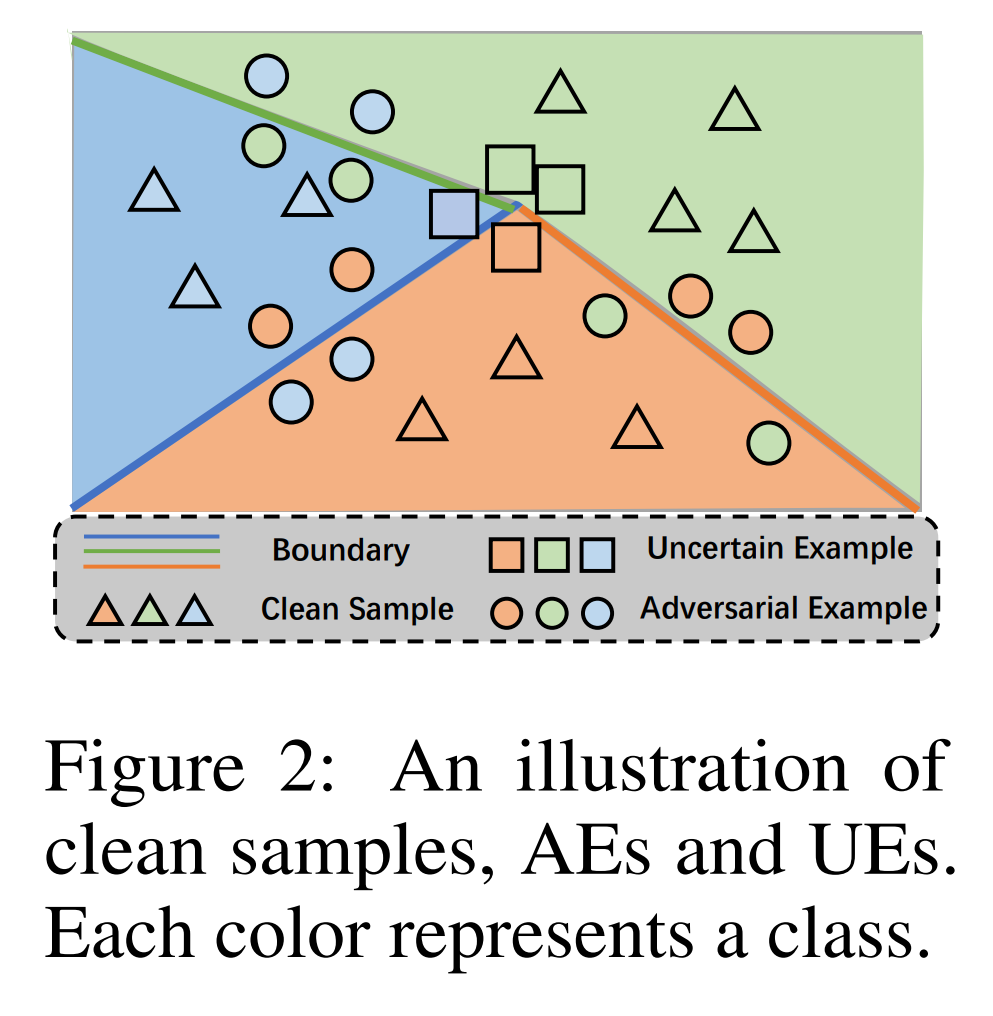
The figure above shows the positions of natural samples, AEs, and UEs relative to the substitute model’s decision boundary. Such UEs have the following characteristics:
-
Robust Overfitting Prevention: UEs can prevent the useful robust features possessed by AEs by lowering \(\delta\) to increase uncertainty. Therefore, using UEs as query samples fundamentally prevents the risk of robust overfitting.
-
CA Preservation: By definition, UEs are positioned closest to the substitute model’s decision boundary. This study assumes that once the substitute model has somewhat mimicked the victim model, the substitute model’s decision boundary will be near the victim model’s. Therefore, using UEs as query samples effectively reflects the victim model’s decision boundary and prevents CA degradation.
In conclusion, UEs satisfy both conditions required for robustness extraction, making them ideal query samples to replace existing ones.
BEST
This paper proposes a new extraction attack called Boundary Entropy Searching Thief (BEST) that leverages uncertain examples (UEs).
BEST is an attack that generates UEs at each iteration, queries the victim model with them, and improves the substitute model based on the predictions. The goal is to make the substitute model simultaneously achieve the victim model’s accuracy (CA) and robustness (RA).
BEST’s core strategy is to synthesize UEs rather than sample them. Since this paper limits the attacker’s dataset to \(D_A\), if sampling were used, the attacker would have to find UEs within this \(D_A\).
However, such a sampling approach is ineffective. As training continues with limited data, the model overfits to existing samples, and all training samples end up in safe regions far from the substitute model’s decision boundary. But UEs that can maximize attack efficiency must be located near that decision boundary, making sampling from within the existing dataset meaningless.
Therefore, BEST actively synthesizes the most useful UEs at each moment through a dual minimization problem.
\[\min_{M_A} L(x, y, M_A) \min_x \left( \text{softmax}(M_A(x))_{\text{max}} - \text{softmax}(M_A(x))_{\text{min}} \right)\]- Inner minimization: Based on existing dataset samples \(x\), it synthesizes new UE samples \(x\) that minimize the prediction confidence variance of the substitute model \(M_A\).
- Outer minimization: Queries the victim model \(M_V\) with UE \(x\) from the inner minimization to obtain the label \(y\). This is used to train the substitute model \(M_A\), minimizing its loss function \(L\). As a result, the optimal substitute model is computed.
The algorithm below describes this process in detail.

Looking at the algorithm above, first a uniform distribution \(\mathcal{Y}_p\) is generated as the target for UE synthesis. Then all samples in the attacker’s dataset \(D_A\) are used sequentially for UE synthesis.
Line 7 uses the following loss function:
\[\mathcal{L} = -KLD(softmax(M_A(X_i)), \mathcal{Y}_p)\]Here, \(softmax(M_A(X_i))\) is the current substitute model’s predicted probability distribution for sample \(X_i\). And \(\mathcal{Y}_p\) is the most uncertain state that UEs target, i.e., the uniform distribution.
The loss function \(\mathcal{L}\) is defined based on the difference between the two probability distributions measured by \(KLD\).
Line 8 uses the PGD method to iteratively modify sample \(X_i\) in the direction that maximizes the loss function \(\mathcal{L}\), i.e., in the direction that reduces the difference between the two probability distributions.
This process is repeated \(B_S\) times to synthesize the UE (\(X_{B_S}\)). The completed UE is queried to the victim model \(M_V\) to obtain the label \(Y\), and the substitute model \(M_A\) is trained using these (UE, label) pairs.
Experimental Setup
Dataset \(D_A\) uses CIFAR10 and CIFAR100. \(D_A\) with 5,000 samples for UE synthesis and \(D_T\) with 5,000 samples for performance evaluation are constructed separately.
Victim models use ResNet-18 (ResNet) or WideResNet-28-10 (WRN).
Substitute models can differ from the victim model, so MobileNetV2 (MobileNet) and VGG19BN (VGG) are additionally used.
For adversarial training the victim model, two methods are used: PGD-AT and TRADES. This produces ResNet-AT (WRN-AT) and ResNet-TRADES (WRN-TRADES), respectively.
Other attack techniques compared with BEST include Vanilla using natural samples, JBDA using AEs, and robust distillation techniques. The robust distillation techniques used are ARD, IAD, and RSLAD, which distill a robust teacher model to produce an even more robust student model. However, these distillation techniques assume white-box access to the teacher model, which does not match this paper’s threat model. Therefore, they are compared under the same black-box constraints as BEST.
The performance evaluation metrics for the substitute model in this experiment are:
- CA: Accuracy on natural samples in \(D_T\)
- rCA: Prediction agreement rate (fidelity) with the victim model on natural samples in \(D_T\)
- RA: Accuracy against various adversarial attacks (PGD20, PGD100, CW100, AA)
Experimental Results
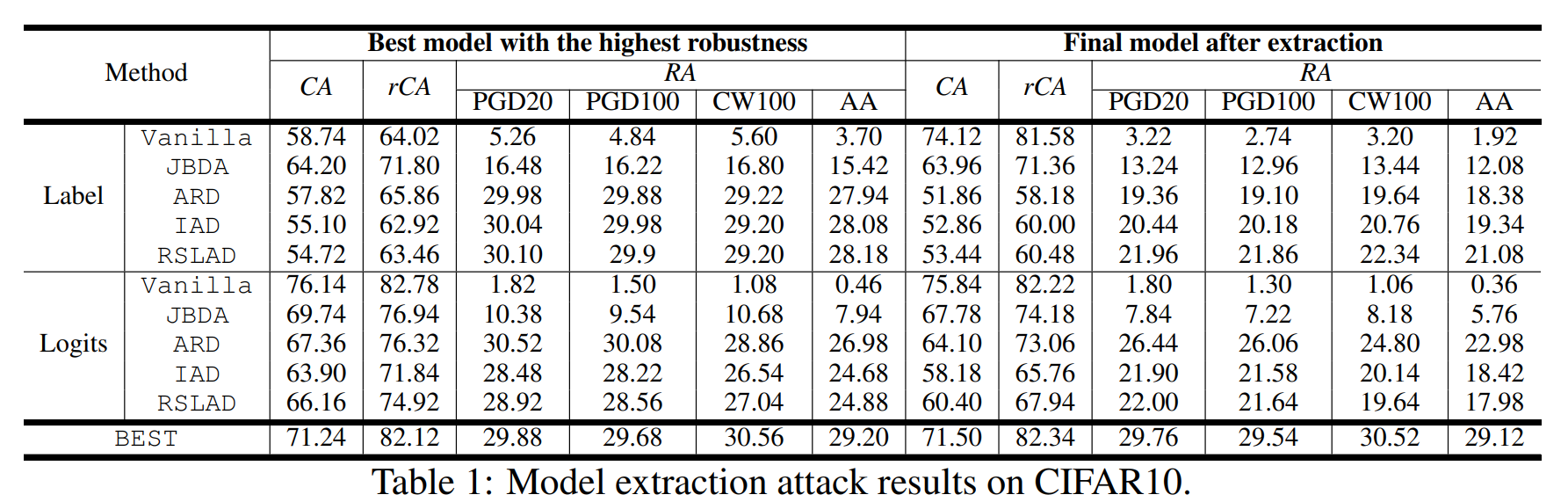
The table above compares the extraction performance of various attack techniques and BEST. The victim model is ResNet-AT, the substitute model is ResNet, and the dataset is CIFAR10.
Experiments also distinguish between cases where the victim model outputs only hard labels and cases where it outputs logit vectors. BEST is noted separately because even when receiving logit vectors, it only uses hard labels.
The results show that BEST had higher performance across all metrics than most attacks.
Most attacks show lower RA in the final model compared to the best model. This occurs due to robust overfitting. In contrast, BEST was able to reduce the RA gap between the final and best models thanks to using UEs.
Additionally, when the victim model returns logit vectors, most attacks increase (r)CA but decrease RA. Since logit vectors contain uncertain prediction information, using them for training reduces robustness.
When the victim model returns only hard labels, both CA and RA of robust distillation techniques decrease significantly. This is because the hard label constraint violates the white-box assumption required for robust distillation.

The above experiment shows performance when using architectures different from the victim model (ResNet-AT) as the substitute model. VGG and MobileNet performance is slightly lower than ResNet and WRN, which is due to inherent performance differences between architectures.
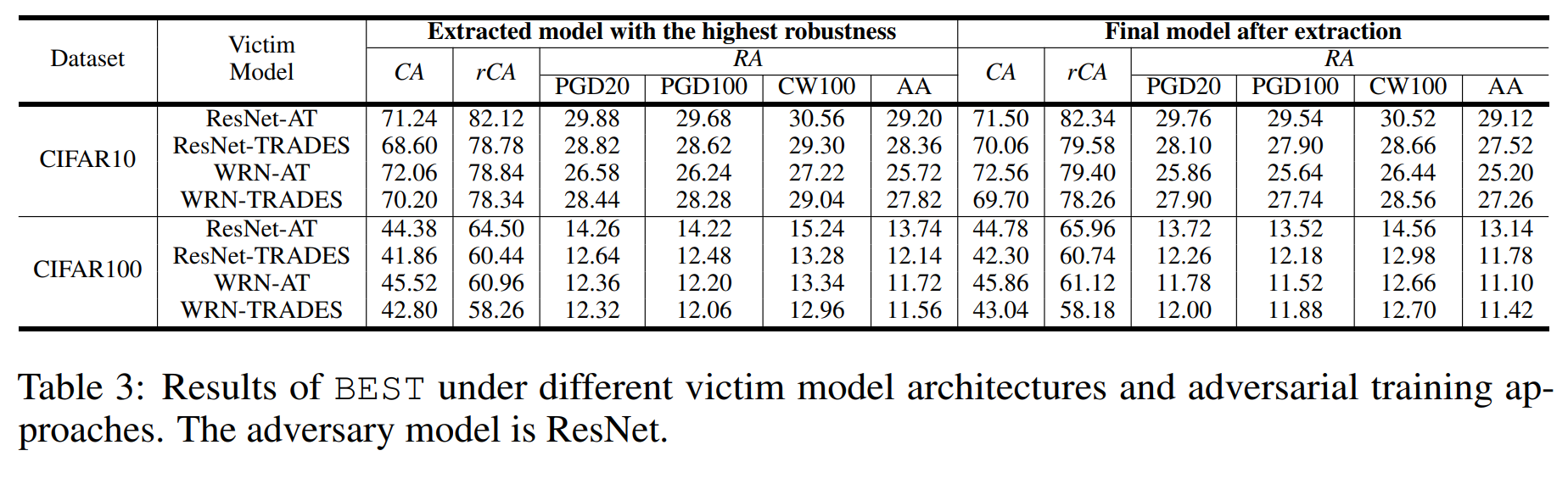
This study assumes the victim model has undergone adversarial training. The above experiment shows performance differences based on the adversarial training methods applied to the victim model. The results show no significant differences.
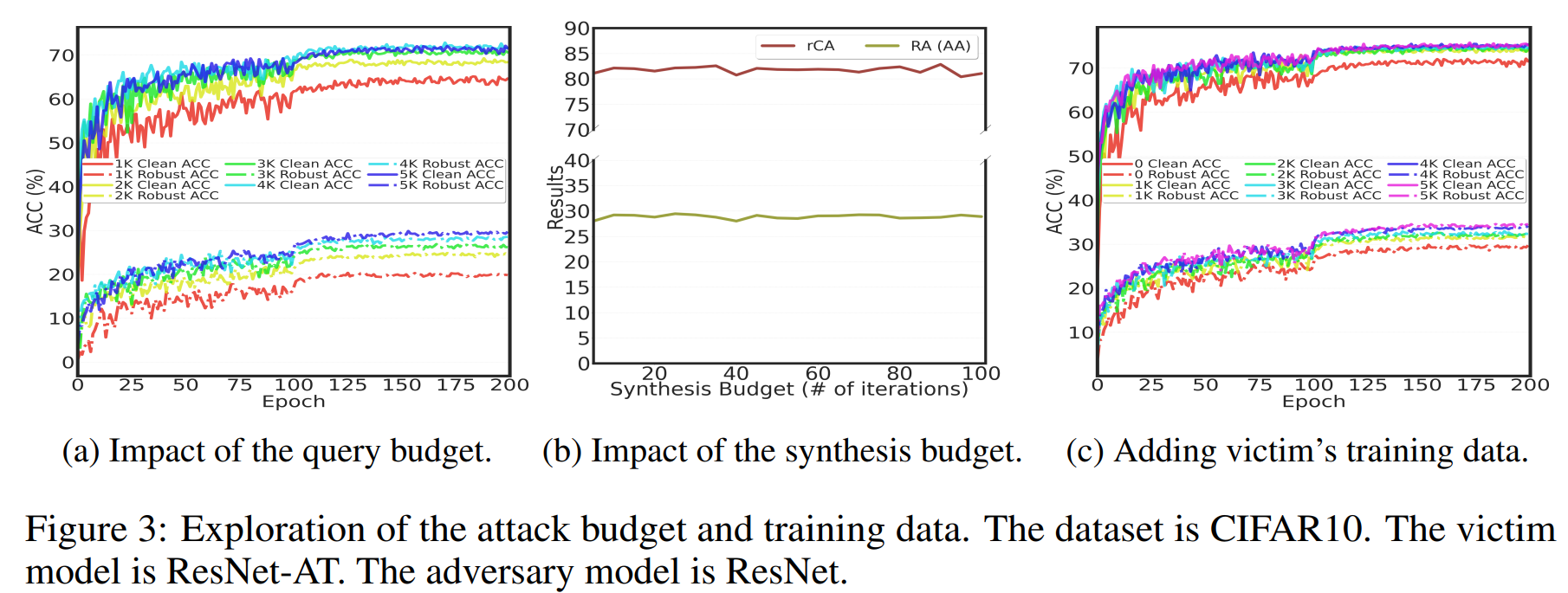
(a) shows the impact of query budget on BEST’s performance by adjusting the size of \(D_A\) used for UE generation.
As a result, both CA and RA improve with larger query budgets. And robust overfitting did not occur even with very small query budgets.
(b) shows the impact of synthesis budget on BEST’s performance. Very low synthesis budgets were sufficient to achieve high attack performance.
Even increasing the synthesis budget for more optimization steps barely improved performance, indicating that BEST’s UE generation method is so efficient that additional cost investment does not significantly help produce more UEs of higher quality (i.e., with smaller \(\delta\)).
(c) shows that adding the victim model’s training data to the UE generation \(D_A\) increases attack performance.
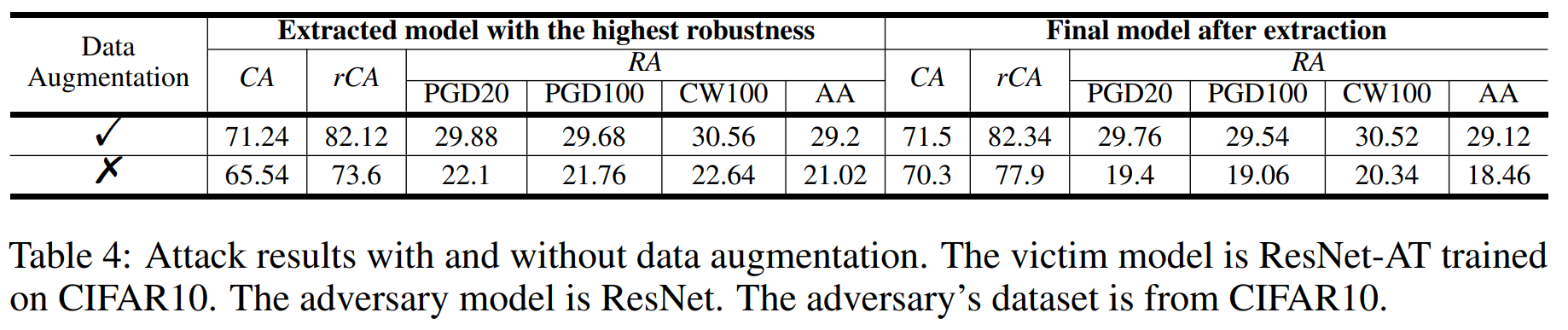
The above experiment shows the results of combining data augmentation with UE synthesis. The results confirm that augmenting \(D_A\) samples before synthesizing them into UEs improves both CA and RA.
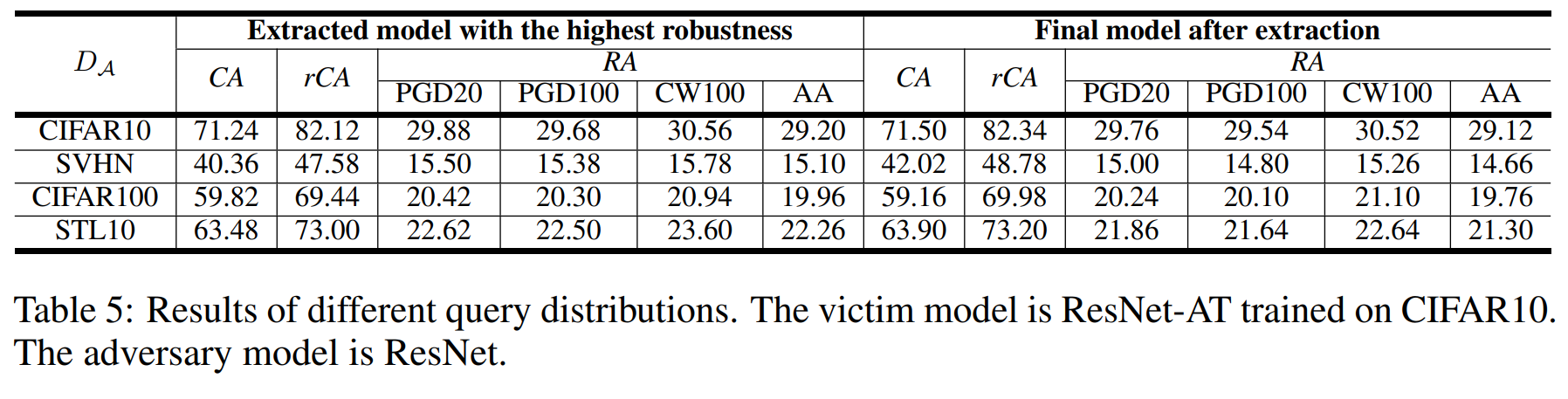
The above experiment shows extraction performance when using datasets (SVHN, CIFAR100, STL10) with different distributions from the victim model (trained on CIFAR10) as \(D_A\).
The results show that the larger the difference between the victim model’s training data distribution and the \(D_A\) distribution, the more both CA and RA dropped.
Therefore, to maximize attack performance, the attacker benefits from using data with distributions as similar as possible to what the victim model was trained on.
Bypassing Existing Defense Strategies
The BEST attack can bypass the following model extraction defense techniques:
-
Logit vector perturbation: A defense technique that adds noise to internal prediction values (logit vectors) without changing the model’s final prediction (hard label). However, since BEST learns using only hard labels rather than logit vectors, it is completely unaffected by this defense.
-
Malicious query detection
-
PRADA: A defense technique that detects attacks using statistical distribution of queries as an indicator. However, when BEST applies data augmentation before generating UEs, the statistical patterns of query distributions are modified. As a result, PRADA fails to detect the attack.
-
SEAT: A defense technique that blocks accounts that repeatedly submit similar queries. The attacker can easily bypass this by distributing queries across multiple accounts.
-
Conclusion
This paper presents the first study on robustness extraction of deep learning models, a topic that had never been previously investigated.
This study proposes a new attack technique called BEST that simultaneously extracts the victim model’s accuracy and robustness by synthesizing and querying uncertain examples (UEs).
Experimental results show that unlike existing attacks that targeted only accuracy or fidelity, BEST successfully extracted the model’s robustness as well.
These results suggest that a model’s robustness can also be a stealable intellectual asset and a target for attacks, highlighting the need for corresponding defense strategies.