Paper: High Accuracy and High Fidelity Extraction of Neural Networks
Authors: Matthew Jagielski, Nicholas Carlini, David Berthelot, Alex Kurakin, and Nicolas Papernot
Venue: In USENIX Security Symposium. USENIX Association, 2020
URL: High Accuracy and High Fidelity Extraction of Neural Networks
Introduction
Model extraction attacks occur when an attacker has query access to a remotely deployed model and extracts a replica of the model through queries. This attack aims for high performance in the following two metrics:
- Accuracy: The prediction accuracy of the extraction model on the test distribution
- Fidelity: The degree to which the extraction model predicts identically to the original model for any given input
To extract a highly accurate model, this paper proposes a method of training the extraction model using the original model as a labeling oracle. The learning-based approach can achieve high accuracy. However, achieving high fidelity is difficult.
To overcome this limitation, this paper proposes a functionally equivalent approach that extracts the original model’s weights without training. Through experiments, it achieves fidelity close to 100%, demonstrating the performance of the functionally equivalent approach.
Background
Context
While prior research primarily focused on accuracy, this paper considers fidelity equally important. To successfully transfer adversarial examples generated from the extraction model to the original model, high fidelity between the two models is necessary. Membership inference also benefits from precisely replicating the victim model’s confidence scores. Furthermore, if functionally equivalent extraction becomes possible, analyzing the extraction model’s internals can reveal properties unrelated to the training objective, enabling exploitation of overlearning.
Attack Difficulty
Extracting a model whose internal parameters exactly match the original (Exact Extraction) from only input-output information is practically impossible. Therefore, the attacker’s goals are classified into the following three categories by difficulty:
-
Functionally Equivalent Extraction: Constructing a substitute model whose output matches the original model’s output for all inputs. Unlike Exact Extraction, the internal parameters may differ.
-
Fidelity Extraction: Maximizing the similarity of predictions between the two models over a performance measurement distribution. For example, this is performed over natural data distributions, distributions including adversarial examples, or distributions mixing training and non-training data. While functionally equivalent extraction requires matching on all inputs, fidelity extraction only needs to match within the given distribution, making it less difficult.
-
Task Accuracy Extraction: Maximizing prediction accuracy over the actual task distribution. Therefore, it does not need to reproduce the original model’s errors. This is considered the easiest goal.
Learning-based Model Extraction
Fully-supervised Model Extraction
It is assumed that the attacker only has unlabeled data. Instead, the attacker uses the original model as a labeling oracle, querying inputs of interest and training the extraction model in a supervised manner using the resulting (input, label/score) pairs.
The experiments below evaluate the performance of fully-supervised extraction attacks by comparing this learning approach with training on actual training data.
Fully-supervised Extraction Performance
This experiment assumes that the attacker queries the WSL oracle (trained on Instagram images) with unlabeled ImageNet data and receives labels and probabilities. The attacker trains ResNet-v2-50/200 extraction models in a supervised manner using unlabeled ImageNet data and labels received from the oracle.
For comparison, a baseline trained with the same amount of ImageNet data and ground truth labels is also prepared.
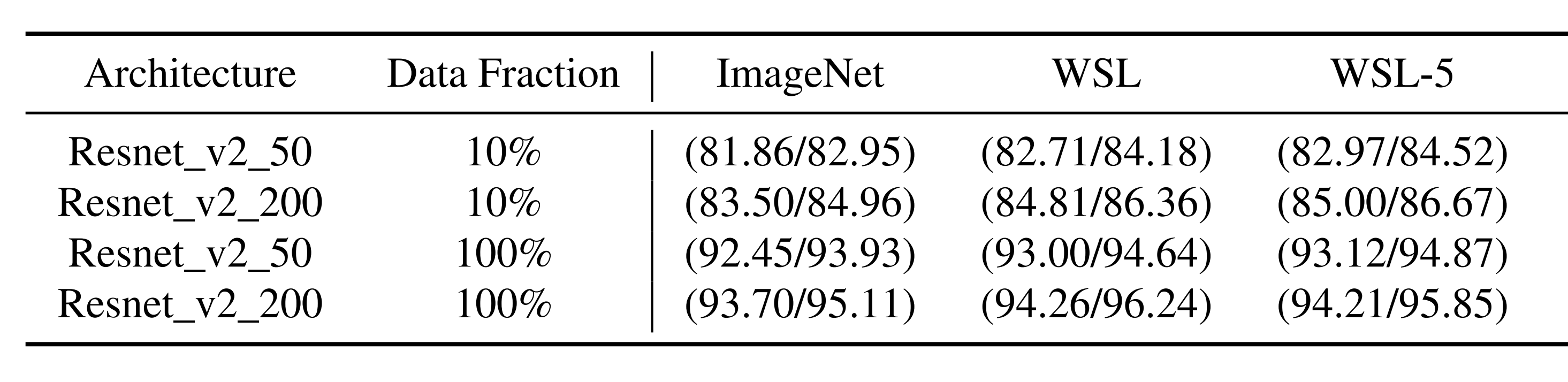
In the above experimental results, each value represents (Top-5 Accuracy / Top-5 Fidelity).
-
Top-5 Accuracy: The probability that at least one of the top 5 classes predicted by the extraction model on the ImageNet validation set matches the actual ground truth class
-
Top-5 Fidelity: The probability that the oracle’s Top-1 predicted class is included in the extraction model’s Top-5 predictions on the ImageNet validation set
ImageNet is the baseline, WSL is when the oracle outputs full class probabilities, and WSL-5 is when the oracle outputs top 5 class probabilities. The row Data Fraction indicates the proportion of ImageNet data used by the attacker.
Observation shows that even with the same proportion of data, WSL and WSL-5 using oracle outputs outperform the baseline. Additionally, WSL-5 shows performance similar to WSL, indicating that even with reduced oracle information, it remains superior to the baseline.
Oracle Query Count
Learning-based extraction attacks must acquire labels by querying the oracle. Attackers can reduce the number of oracle queries through the following methods:
-
Active Learning: A technique that selects only the most informative data from the entire dataset to query the oracle.
-
Semi-supervised Learning: A technique that leverages labeled data along with much more unlabeled data, compensating for limited query budgets and improving model performance.
- Rotation Loss: A semi-supervised learning technique that adds a rotation prediction classifier to the image classification model. It trains the model to predict the angle by rotating input images to 0, 90, 180, and 270 degrees, thereby guiding the model to understand object position, type, and pose. Rotation loss is applied to unlabeled data, while it is combined with the standard classification loss for labeled data, enabling the model to learn meaningful features even without labels.
- MixMatch: Each unlabeled image is augmented multiple times, and the class probability values predicted by the model for the augmented images are averaged to generate a single pseudo-label. These images with pseudo-labels are then combined with a small amount of real labeled data through MixUp and used as training samples.
Rotation Loss and MixMatch Performance

The above experimental results show that adding rotation loss to the existing extraction method improves performance. Since the primary goal is to reduce the number of oracle queries, rotation loss experiments were conducted only at a Data Fraction of 10%.
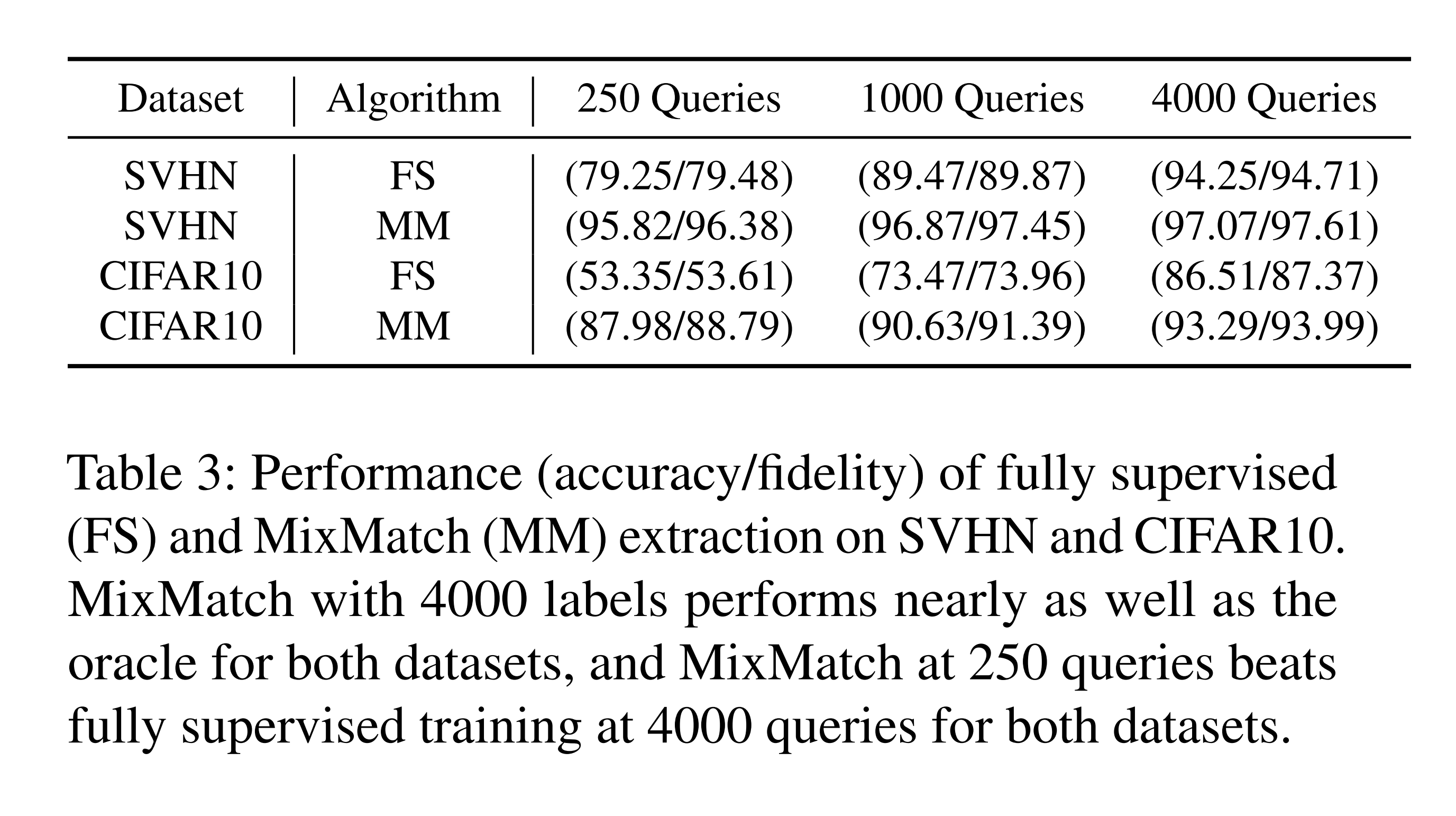
Additionally, the results above show that MixMatch with only 250 oracle queries outperforms the FS (fully-supervised) approach with 4,000 oracle queries.
Limitations of Learning-based Extraction Attacks
Learning-based extraction methods struggle to achieve functional equivalence due to non-determinism. This paper explains the reasons for this non-determinism through the following three factors:
1. Random initialization of model parameters 2. SGD mini-batch ordering 3. Non-determinism in GPU computation itself
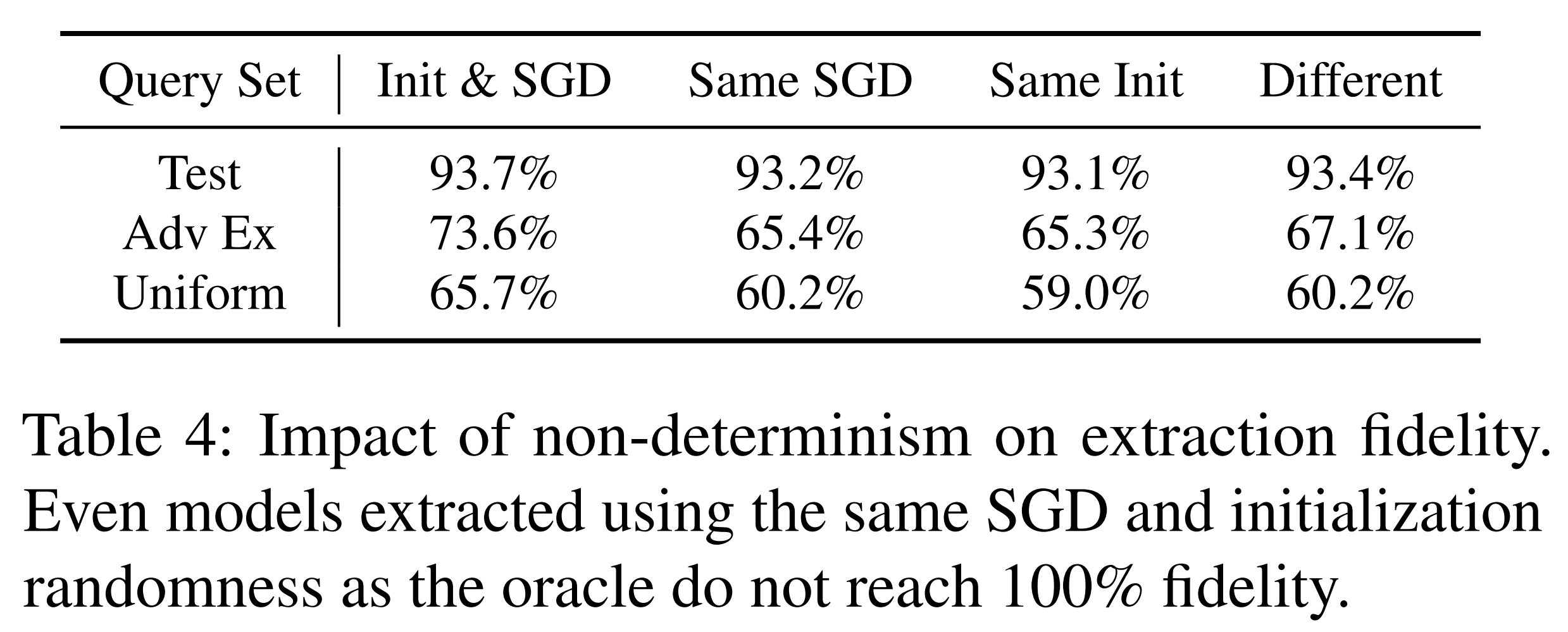
In the above experimental results, columns represent fixed variables and rows represent input distributions. The input distributions consist of the Fashion MNIST test set, FGSM adversarial examples generated from the oracle model, and randomly sampled data from the input space. Each value represents the agreement rate when the same input is applied twice to the extraction model, expressing the impact of non-determinism.
As a result, even when all controllable variables were fixed, the maximum agreement rate was 93.7%, failing to reach 100%. This demonstrates the fundamental limitation of learning-based approaches, leading to the conclusion that a different extraction method is needed to achieve functional equivalence.
Functionally Equivalent Extraction
Summary
Functionally equivalent extraction is an attack technique that achieves functional equivalence by directly recovering the original model’s weights. In this study, it was designed to operate on single-hidden-layer ReLU neural networks, tracking the weights of the layers immediately before and after the ReLU layer based on the activation boundary information of the ReLU layer. This process is explained in 5 steps below.
1. Critical Point Search
\(O_L(x)\) is the logit when inputting \(x(t) \in \mathbb{R}^d\) to the oracle model.
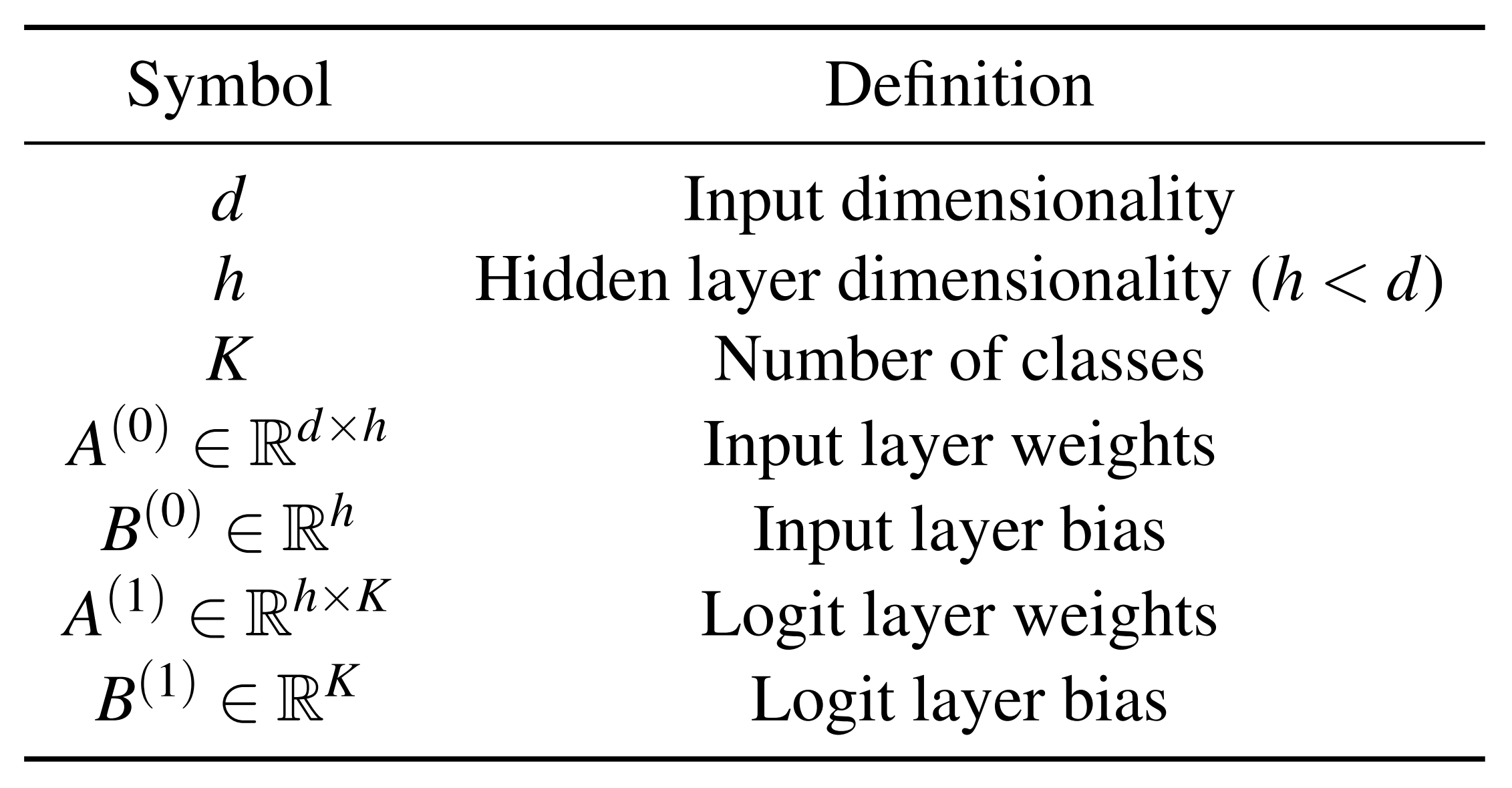
- \(A^{(0)}\): Weight matrix from input to the pre-ReLU hidden layer \(\in \mathbb{R}^{d\times h}\)
- \(A^{(1)}\): Weight matrix from the post-ReLU hidden layer to the logit layer \(\in \mathbb{R}^{h\times K}\)
Table 5 transposes the weight matrix dimensions to match the matrix multiplication form for input and output dimensions. Therefore, the actual row vector dimensions of \(A\) in the \(O_L\) formula are as follows:
- \(A^{(0)}_i\): The \(i\)-th weight row vector of \(A^{(0)}\) \(\in \mathbb{R}^{d}\)
- \(A^{(1)}_i\): The \(i\)-th weight row vector of \(A^{(1)}\) \(\in \mathbb{R}^{k}\)
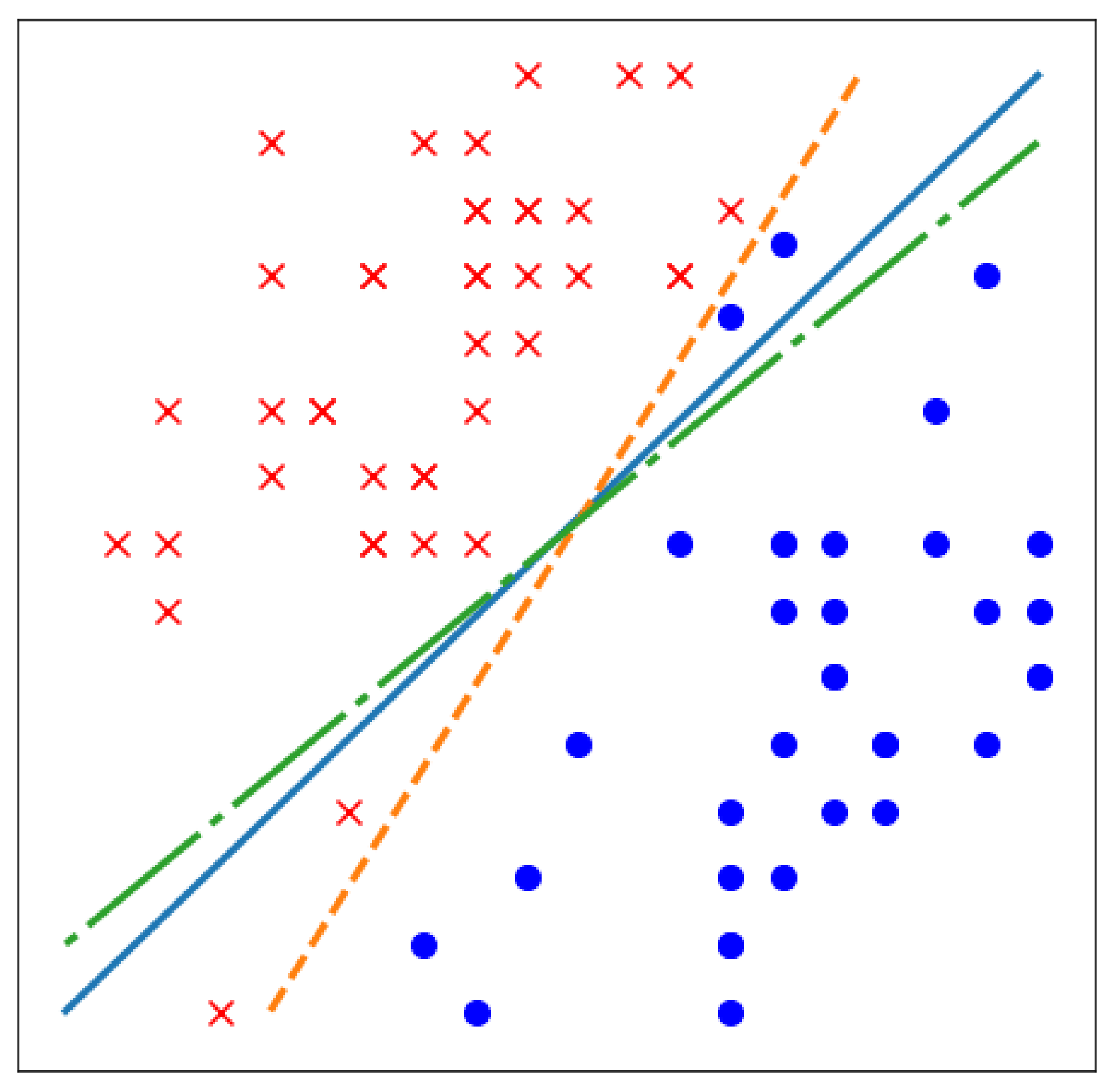
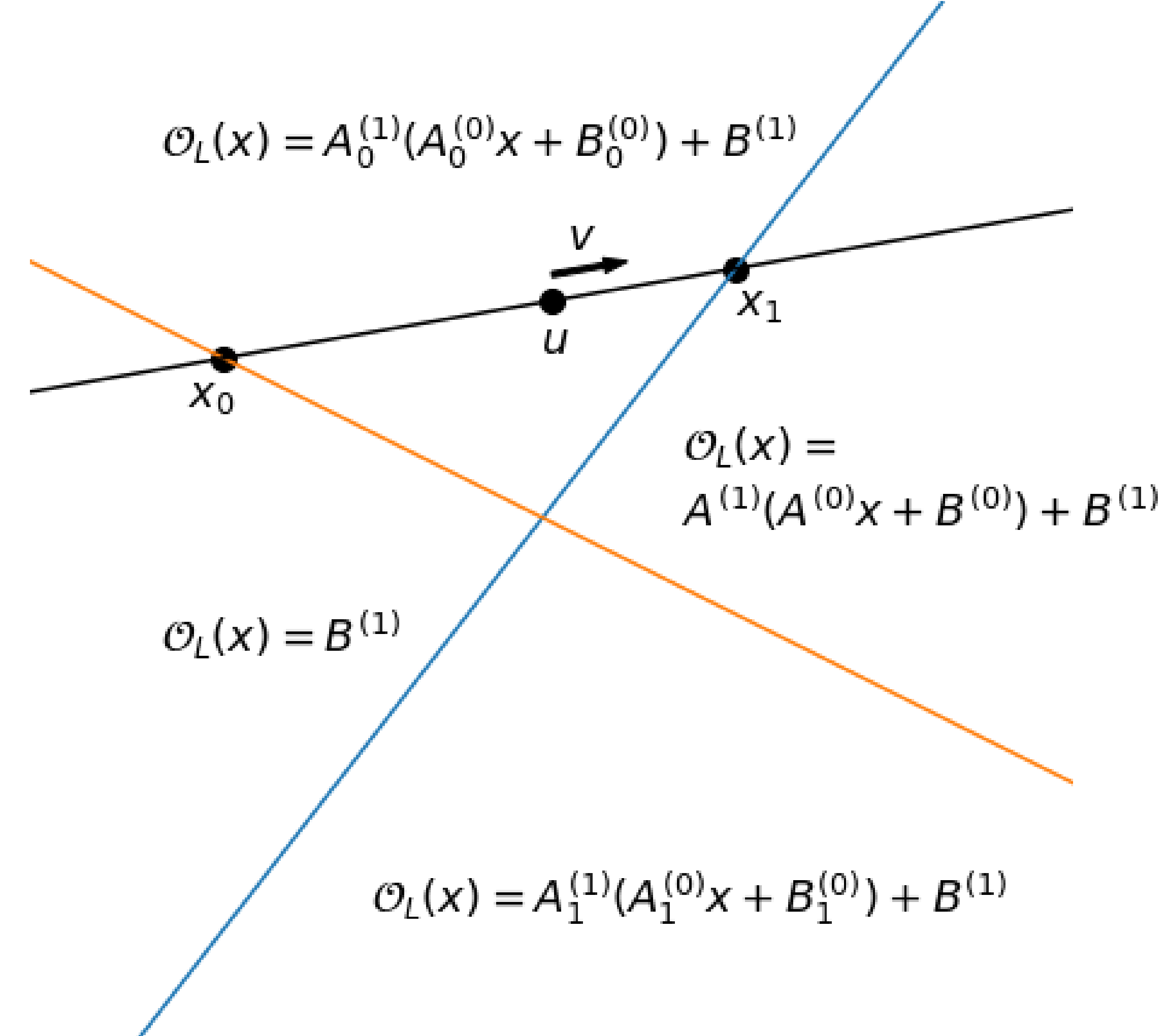
For the input \(x\) to the pre-ReLU hidden layer, the orange and blue lines in Figure 2 represent the boundaries where \(A^{(0)}_{0}x + B^{(0)}_{0}=0\) and \(A^{(0)}_{1}x + B^{(0)}_{1}=0\), respectively.
The attacker samples arbitrary vectors \(u, v \in \mathbb{R}^d\) to construct an arbitrary line \(x(t)=u+tv\). The \(x(t)\) value at point \(t\) is input to \(O_L(x)\), and the result is defined as \(L(t)=O_L(u+tv)\). Since \(L(t)\) is a logit through the ReLU layer, it is a piecewise linear function with different slopes separated by the orange and blue lines in Figure 2.
In Figure 2, above the orange line means \(A^{(0)}_{0}x + B^{(0)}_{0}>0\), and to the right of the blue line means \(A^{(0)}_{1}x + B^{(0)}_{1}>0\).
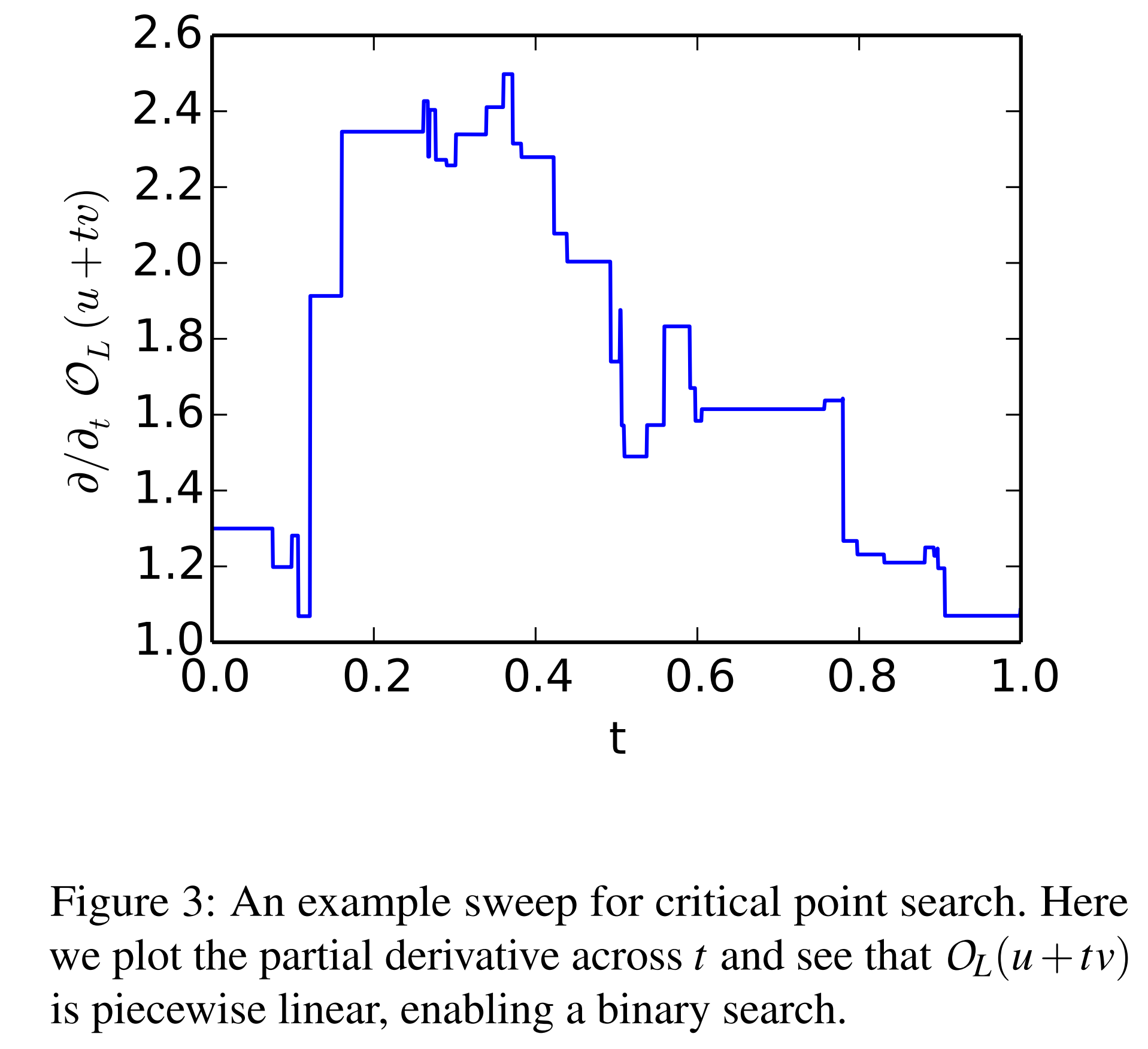
The attacker adjusts \(t\) to find points where \(L(t)\) is non-differentiable and considers those points as critical points.
2. Absolute Value Recovery
In the previous step, the attacker obtained critical points \(x_i\) lying on \(h\) boundaries \(A^{(0)}_{i}x + B^{(0)}_{i}=0\). Now, using these \(h\) critical points \(x_i\), we can access \(A^{(0)}\).
\[\frac{\partial^2 O_L}{\partial e_j^2} \Big|_{x_i} = \frac{\partial O_L}{\partial e_j} \Big|_{x_i + c e_j} - \frac{\partial O_L}{\partial e_j} \Big|_{x_i - c e_j} = \pm \left( A^{(0)}_{ji} A^{(1)}_i \right)\]As shown in the formula above, computing the second derivative near \(x_i\) via finite differences along an arbitrary direction \(e_j \in \mathbb{R}^d\) in the input space simplifies to the product of coordinates of \(A^{(0)}\) and rows of \(A^{(1)}\).
For each \(x_i\), by varying the direction \(e_j\) to compute \(\lvert A^{(0)}_{ji} A^{(1)}_i\rvert\) and dividing them, we can calculate ratios like \(\bigl\lvert \tfrac{A^{(0)}_{1i}}{A^{(0)}_{ki}} \bigr\rvert\) between coordinates within the same row \(i\).
This recovers each row vector \(A^{(0)}_i\) completely, except for the signs.
3. Weight Sign Recovery
Now we need to determine the signs of each row vector \(A^{(0)}_i\).
Computing the second derivative at critical point \(x_i\) via finite differences along the sum of two directions \((e_j+e_k)\) simplifies as follows:
\[\left.\frac{\partial^2 O_L}{\partial (e_j+e_k)^2}\right|_{x_i} \!=\ \pm\!\big(A^{(0)}_{ji}A^{(1)}_i \ \pm\ A^{(0)}_{ki}A^{(1)}_i\big)\]When the two terms on the right cancel out, \(A^{(0)}_{ji}\) and \(A^{(0)}_{ki}\) have opposite signs; when they amplify, they have the same sign. Computing this across all direction pairs determines the relative signs between all row vectors of \(A^{(0)}\), but the actual signs remain unknown.
4. Global Sign Recovery
If we can determine the actual signs of all row vectors of the recovered \(\hat A^{(0)}\), we can identify which direction relative to each of the \(h\) boundaries of \(A^{(0)}\) satisfies \(A^{(0)}_{i}x + B^{(0)}_{i}\ge0\).
To this end, we first set a null space vector \(z\) satisfying \(\hat A^{(0)} z=\mathbf{0}\). Then, for each \(i\), we find \(v_i\) satisfying \(v_i A^{(0)}=e_i\).
We then compare \(O_L(z), \ O_L(z\!+\!v_i), \ O_L(z\!-\!v_i)\) to determine the sign of each row vector. The same approach recovers \(B^{(0)}\) with signs as well.
| Comparison | Same? | \(A^{(0)}_i\!\cdot v_i\) |
|---|---|---|
| \(O_L(z+v_i), \ O_L(z)\) | Same | \(< 0\) |
| \(O_L(z-v_i), \ O_L(z)\) | Same | \(> 0\) |
5. Last Layer Extraction
\(A^{(0)}\) and \(B^{(0)}\) have been fully recovered. We also have \(h\) critical points \(x_i\).
Now, substituting each \(x_i\) into \(O_L(x)=A^{(1)}\,\mathrm{ReLU}(A^{(0)}x+B^{(0)})+B^{(1)}\), we can recover \(A^{(1)}\) and \(B^{(1)}\) using the least squares method.
Performance Experiments
The oracle’s \(A^{(0)}\) and \(A^{(1)}\) have 16 to 512 neurons each, trained on MNIST and CIFAR-10.
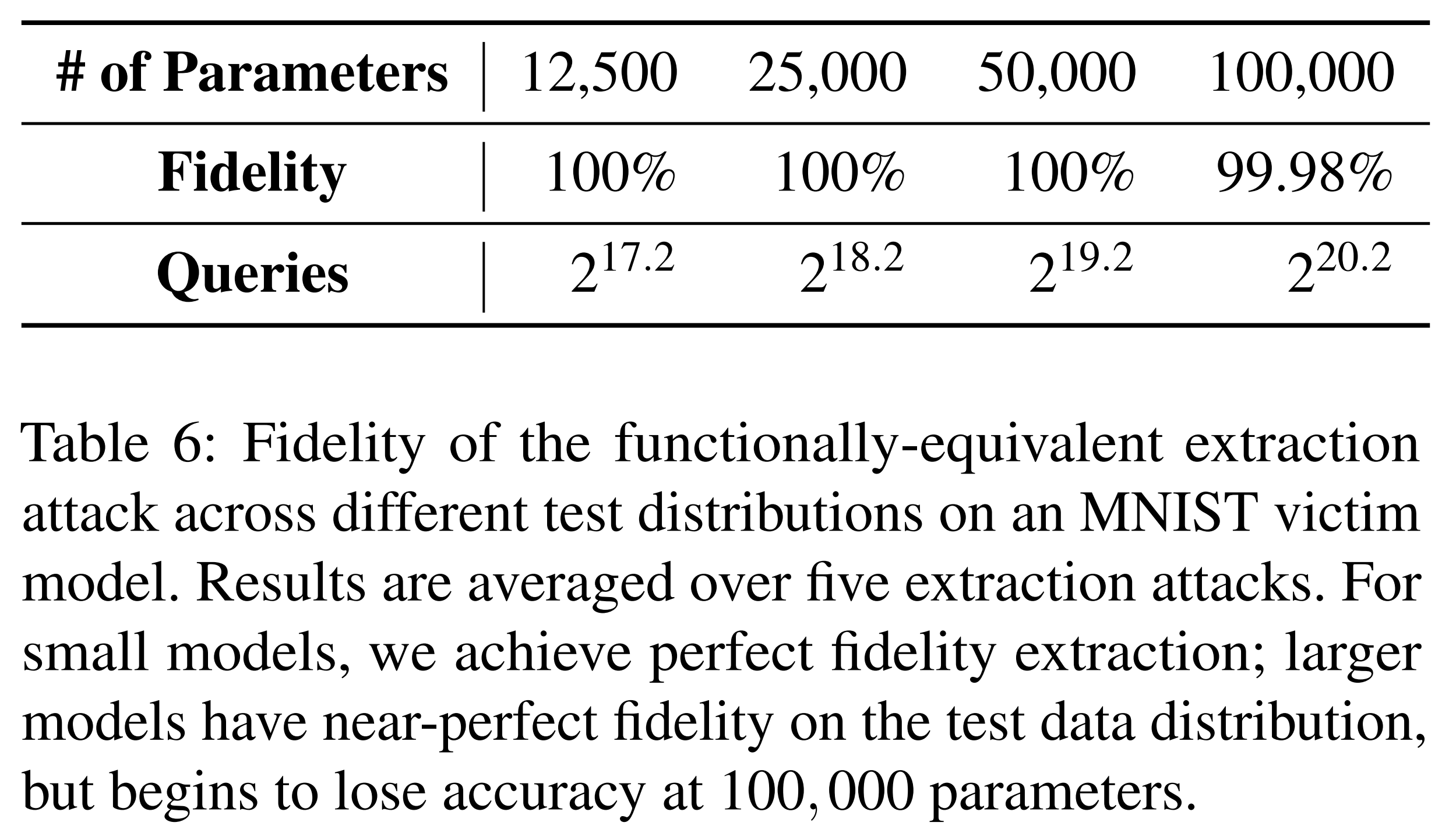
The above experimental results show the performance of the functionally equivalent extraction attack on an oracle trained on MNIST. Although the number of oracle queries is large, fidelity converges to 100%.
For CIFAR-10, 100% fidelity was achieved when the number of model parameters was 200,000 or fewer.
Limitations
The functionally equivalent extraction attack proposed in this study was conducted with only two hidden layers, making it difficult to apply to deeper models. In deeper models, even if a critical point is found, it is difficult to determine which layer it belongs to. Even if the layer is known, accessing neurons directly is difficult due to the model’s depth. Finally, if small extraction errors accumulate layer by layer, the total error amplifies, significantly degrading weight recovery accuracy.
Hybrid Strategy
Summary
A strategy that takes advantages from both sides by combining the query efficiency of learning-based extraction attacks with the high fidelity of functionally equivalent extraction attacks on a continuum.
Learning-based Extraction Attack and Gradient Matching
Conventional learning-based extraction focused only on matching outputs between the oracle and the extraction model \(f\). However, the Gradient Matching approach trains the model to match not only the output but also the gradients with respect to the input. That is, the attacker must be able to observe not only the output value when querying the oracle, but also the input gradient \(\nabla_x O(x)\). This strategy can improve fidelity by minimizing the following objective:
\[\sum_{i=1}^{n}\underbrace{H\!\big(O(x_i),\,f(x_i)\big)}_{\text{output (logit/prob) matching}} \;+\; \alpha\,\underbrace{\big\|\nabla_x O(x_i)-\nabla_x f(x_i)\big\|_2^2}_{\text{input gradient matching}}\]In the above formula, \(H\) is the cross-entropy. In experiments on Fashion-MNIST, fidelity improved slightly from 95% to 96.5%.
Error Recovery through Learning
Functionally equivalent extraction works perfectly in theory, but in practice, errors accumulate during computation. Especially when recovering \(A^{(0)}\) and \(B^{(0)}\), even tiny errors are amplified in the bias terms of subsequent layers, causing fidelity to drop significantly for larger models.
To address this, the study proposes using \(\hat A^{(0)}\) and \(\hat B^{(0)}\) as initial values and training other parameters via gradient descent to correct errors.
\[\mathbb{E}_{x \in \mathcal{D}} \left\| f_\theta(x) - W_1 \,\mathrm{ReLU}\!\big(\hat{A}^{(0)} x + \hat{B}^{(0)} + W_0\big) + W_2 \right\|\]- \(f_\theta(x)\): Oracle model output
- \(\hat{A}^{(0)}, \hat{B}^{(0)}\): Approximations obtained from functionally equivalent extraction
- \(W_0\): Correction term replacing \(B^{(0)}\)
- \(W_1\): Correction term for \(A^{(1)}\)
- \(W_2\): Correction term for \(B^{(1)}\)
Through this process, small errors from the initial extraction stage are corrected and the extraction model’s fidelity improves. The table below shows results from functionally equivalent extraction alone, already demonstrating high fidelity.
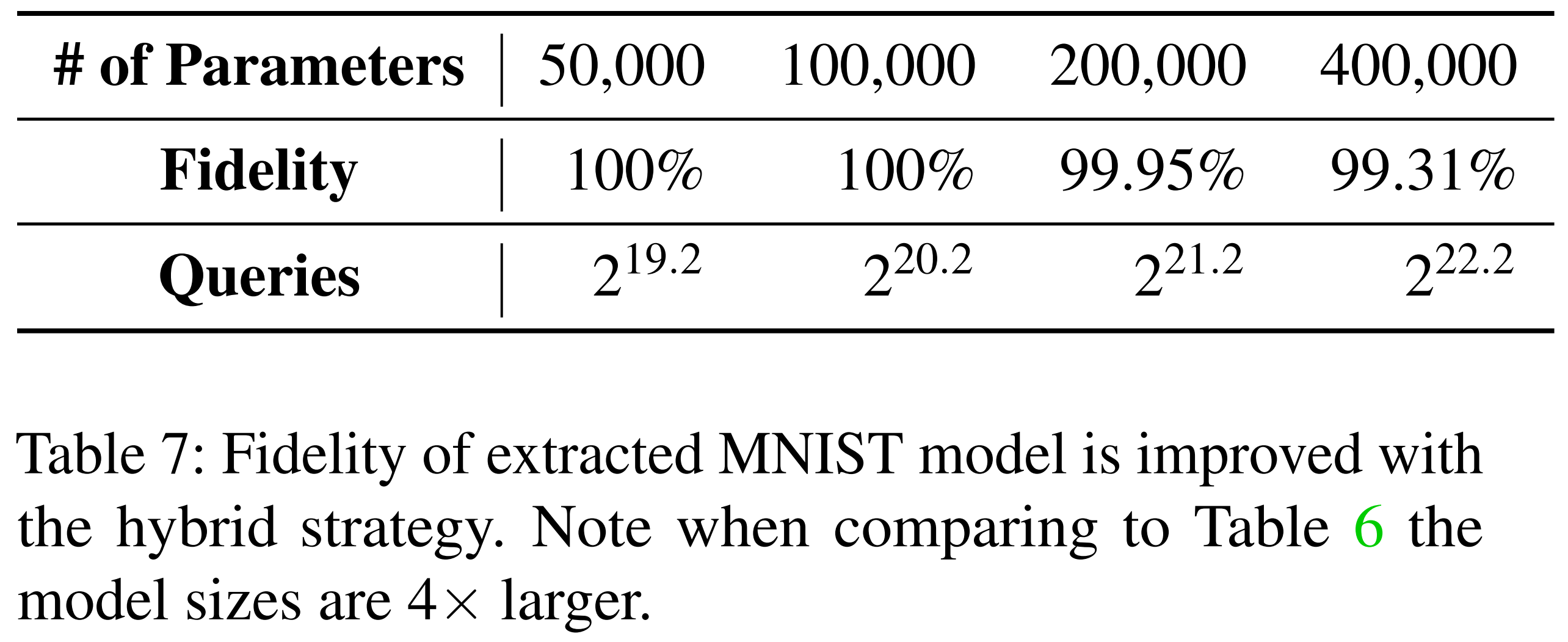
Subsequently, error recovery learning was additionally applied to the same extraction model. As shown in the table below, adversarial examples generated from the extraction model after error recovery learning transfer to the oracle at 100%.
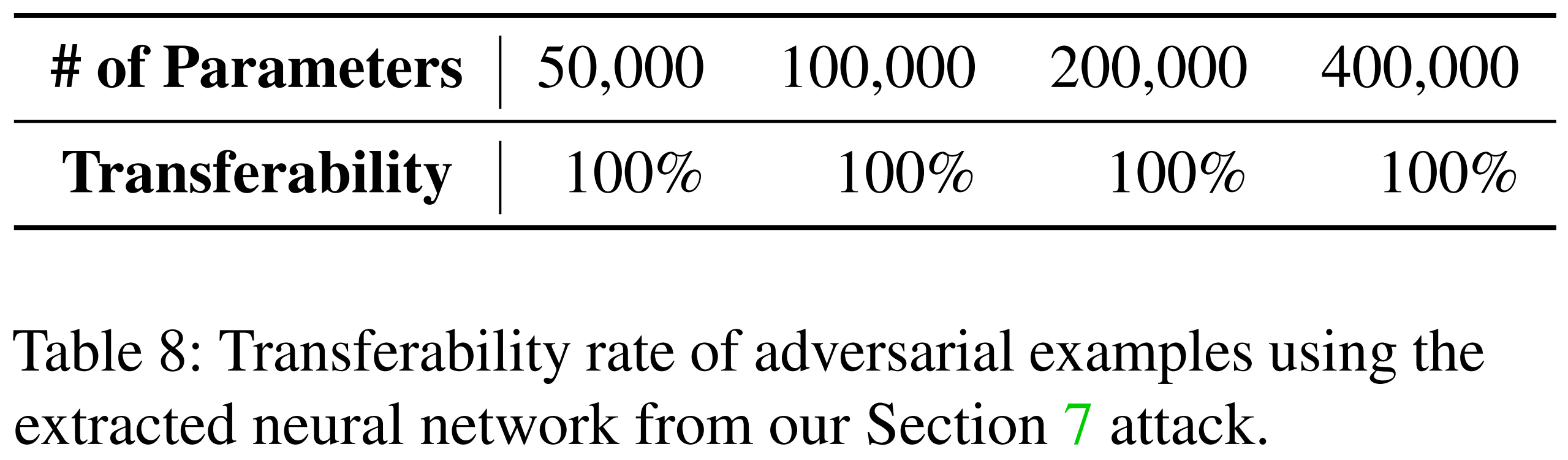
Conclusion
This paper proposes a novel extraction attack technique for single-hidden-layer ReLU neural networks that recovers internal weights and biases solely through oracle queries. This attack leverages the nonlinear boundary properties of ReLU to find critical points and directly reverse-engineers the model structure through them.
As a result, it achieved much higher fidelity than conventional learning-based extraction methods, and achieved near-perfect functional equivalence for small models. Furthermore, when combined with the hybrid strategy, experiments confirmed that fidelity degradation can be mitigated even as model size increases.
Although extension to multi-layer neural networks or more complex architectures has limitations, this study demonstrates that functionally equivalent model extraction is practically achievable.