논문명: Machine Unlearning of Features and Labels
저자: Alexander Warnecke, Lukas Pirch, Christian Wressnegger, Konrad Rieck
게재지: Network and Distributed System Security Symposium (NDSS) 2023
URL: https://www.ndss-symposium.org/wp-content/uploads/2023/02/ndss2023_s87_paper.pdf
서론
기계 학습 모델(Machine Learning Model)에서 민감한 정보를 삭제하는 것은 데이터 프라이버시 보호 측면에서 매우 중요한 과제입니다. 특히 GDPR(General Data Protection Regulation)과 CCPA(California Consumer Privacy Act)와 같은 법적 요구 사항이 강화됨에 따라, 특정 데이터 포인트를 안전하게 제거할 수 있는 언러닝(Unlearning) 기술의 필요성이 커지고 있습니다. 언러닝(Unlearning)은 “모델에서 특정 데이터를 제거하는 것과 더불어, 해당 데이터를 기반으로 학습한 정보를 효과적으로 없애는 기법”를 의미합니다. 이 기법은 데이터의 민감도를 고려할 때 특히 중요하며, 개인정보 보호와 관련된 법적 요구 사항을 충족하는 데 필수적입니다. 기존의 언러닝 방법은 전체 데이터 포인트를 제거하는 데 집중했으나, 이 방식은 비효율적일 수 있습니다. “Machine Unlearning of Features and Labels” 은 더 빠르고 효율적인 언러닝 방식인 ‘특징 및 라벨 기반 언러닝(Machine Unlearning of Features and Labels)’을 제안하는 논문이며, 본 글에서는 논문 내용과 함께 실제 실험을 통해 해당 언러닝 방식이 복잡한 신경망 모델에 어떻게 적용되는지를 알아보고자 합니다.
사전 지식
영향 함수(Influence funciton)
특징 및 라벨 기반 언러닝(Machine Unlearning of Features and Labels) 방식을 이해하기 위해서는, 우선 영향 함수의 원리를 파악해야 합니다. 영향 함수는 데이터 포인트가 모델에 미치는 영향을 정략적으로 평가하는 데 유용합니다. 특정 데이터가 모델의 예측 결과를 얼마나 바꾸는지 알고 싶을 때 영향 함수를 사용하고, 영향 함수는 다음과 같이 표현됩니다.
\[\begin{equation} \mathcal{I}(z,y) = -H_{\theta^*}^{-1} \nabla_\theta \ell(z,y;\theta^*) \label{eq:influence} \end{equation}\]이 함수는 선택한 데이터 포인트 (𝑧,𝑦)를 모델에서 제거했을 때 모델의 매개변수(parameters) 즉, 예측 결과의 변화를 나타냅니다. 이러한 변화를 종합적으로 분석하여 언러닝(unlearning) 과정에서 제거할 데이터 포인트의 중요성과 영향을 정확히 평가하고 조정합니다.
강한 볼록성(λ-Strong Convexity)
강한 볼록성(λ-Strong Convexity)은 최적화 문제의 안정성과 수렴성을 보장하는 중요한 속성으로, 모델 학습 과정이 안정적이고 최적화가 잘 되도록 보장합니다. 모델이 학습할 때 최적의 값을 찾기 위해 손실 함수의 모양이 볼록(convex)해야 합니다. 강한 볼록성(λ-Strong Convexity)은 아래와 같이 표현됩니다.
\[\begin{equation} H_{\theta^*} \succeq \lambda I \label{eq:strong_convexity_1} \end{equation}\]이 조건은 헤시안 행렬(Hessian Matrix)이 항상 양수임을 보장하며, 이는 모델이 최적화 과정에서 안정적으로 수렴하도록 돕습니다. 쉽게 말해, 손실 함수(Loss function)가 너무 평평하거나 울퉁불퉁하지 않게 만들어 준다고 생각하면 됩니다.
폐쇄형 매개변수 업데이트(Closed-form update)
언러닝 과정에서 가장 중요한 단계는 특정 데이터를 제거했을 때 모델의 매개변수(parameters)를 어떻게 업데이트할지 결정하는 것이고, 폐쇄형 매개변수는 $\theta’$라고 정의합니다.
\[\begin{equation} \theta' = \theta^* - \eta H^{-1}(\theta^*)\nabla_\theta\ell(z,y;\theta^*) \label{eq:closed_form_update} \end{equation}\]이 식을 통해 언러닝 과정에서 제거하고자 하는 데이터 포인트 \((z,y)\)의 영향을 상쇄하는 방향으로 모델의 매개변수(parameters)를 조정합니다. 이 방법은 전체 모델을 재학습하지 않고도 특정 데이터의 영향을 효과적으로 제거할 수 있게 해줍니다.
본론
본 논문은 “데이터를 삭제할 때 전체 데이터(entire data)를 삭제하는 언러닝 방식의 한계를 극복하고 효율적으로 데이터를 삭제할 수 있는 새로운 언러닝 방식이 있을까?”라는 질문에서 시작합니다.
기존 언러닝 방식의 한계와 특징 및 라벨 기반 알고리즘의 필요성
인스턴스 기반 언러닝(Instance-Based Unlearning)은 개별 데이터 포인트를 제거하는 방식으로, 분산 데이터나 신경망에서는 비효율적입니다.
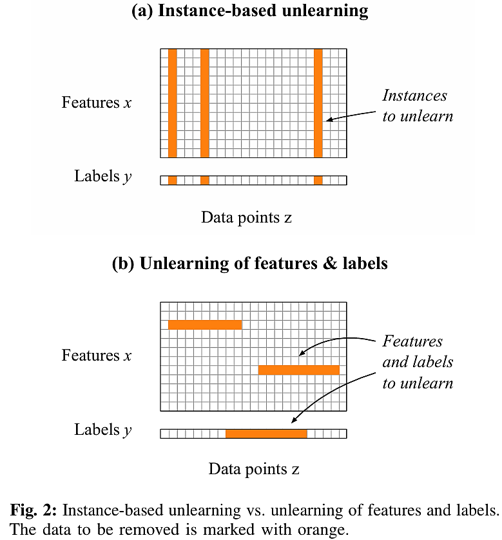
위 그림은 특징 및 라벨 언러닝(Machine Unlearning of Features and Labels)과 비교했을 때 인스턴스 기반 언러닝(Instance-based Unlearning)이 가지는 한계를 나타냅니다.
인스턴스 기반 언러닝(Instance-based Unlearning)은 영향을 받는 데이터 포인트 수가 증가할수록 성능 이점이 감소합니다. 따라서 전체 인스턴스를 제거하는 것은 모델의 성능을 불필요하게 저하시킬 수 있습니다.
댜음으로, 샤딩(Sharding)은 데이터를 나누고 일부 데이터를 재훈련(retraining)하여 속도를 높일 수 있지만, 제거해야 할 데이터가 많아질수록 모든 샤드(Shard)를 재훈련해야 할 확률이 높아져 효율성이 급격히 떨어집니다.
여기서 재훈련(Retraining)의 주요 도전 과제는 크게 세 가지로 요약할 수 있습니다.
대규모 데이터셋에서 작은 변화가 발생할 경우, 전체 모델을 재훈련해야 하므로 많은 시간과 컴퓨팅 자원이 소모됩니다. 또한, 개인정보 관련 법규를 준수하고 사용자 동의를 받아야 하며, 원본 데이터를 무기한 저장할 수 없기 때문에 데이터 관리가 복잡해집니다. 마지막으로, 온라인 학습 시스템에서는 학습 데이터가 계속해서 업데이트 해서 학습할 수 있기 때문에 오래되거나 부적절한 데이터를 신속하게 제거해야 하므로 지속적인 데이터 품질 관리가 필요합니다.
그렇다면, 이러한 문제를 극복하기 위해서는 어떤 방법이 사용되어야 하는가. 본 논문에서는 특징(features) 및 라벨(labels) 기반으로 언러닝하는 방식을 제시하고 있습니다.
이 접근법은 데이터 인스턴스가 아닌 특징 값(feature values)과 라벨(labels)을 기반으로 모델의 폐쇄형 업데이트(Closed-form Update)를 통해 훈련 데이터 내에서 특정 특징(feature)과 라벨(label)을 수정할 수 있습니다.
이러한 특징 및 라벨 기반 언러닝은 두 가지 장점을 가집니다.
먼저 효율성 측면에서 개인 정보 문제로 여러 데이터 인스턴스에 영향을 미치지만, 특정 특징 값(feature values)이나 레이블(labels)을 직접 수정하는 것이 더 효율적입니다.
다음으로, 유연성 측면에서 영향 함수(influence functions)를 활용하여 원래 훈련 데이터의 특정 특징 값(feature values)과 라벨(labels)을 수정할 수 있다는 장점이 존재합니다.
다음으로, 특징 및 라벨 기반 언러닝(Machine Unlearning of Features and Labels)을 위해서 두 가지 업데이트 전략을 제안합니다.
1차 업데이트 (First-order update)
먼저 1차 업데이트는 손실 함수의 기울기(gradient)를 활용하여 모델의 매개변수(parameter)를 조정하는 방법입니다. 이 과정에서 원본 데이터 \(Z\)의 영향을 최소화하고, 대체 데이터 \(\tilde{Z}\)를 사용하여 업데이트를 진행하여 모델 성능을 개선합니다.
1차 업데이트는 다음과 같이 표현됩니다.
\[\begin{equation} \Delta(Z, \tilde{Z}) = -\tau \left( \sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta) - \sum_{z \in Z} \nabla_\theta \ell(z, \theta) \right) \label{eq:first_order_update} \end{equation}\]\(\sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta)\)은 원본 데이터의 기울기를, \(\sum_{z \in Z} \nabla_\theta \ell(z, \theta)\)은 대체 데이터의 기울기를 나타냅니다. 1차 업데이트에서는 이 기울기 차이를 통해 특정 데이터를 제거(unlearning)할 수 있습니다.
손실 함수가 미분 가능하다면 어떤 모델에도 적용 가능하며, 간단하면서도 효율적으로 정보를 삭제할 수 있습니다. 이때 언러닝 속도 𝜏는 효과적인 언러닝을 위해 적절히 조정되어야 합니다(Carlini et al.).
1차 업데이트(First-order update)는 경사하강법(Gradient Descent, GD)과 유사한 방식으로 작동합니다. 경사하강법(Gradient Descent, GD)은 대체 데이터 \(\tilde{Z}\)의 기울기(gradient)를 사용하여 모델 매개변수(parameters)를 업데이트하며, 아래과 같이 표현됩니다. \(\begin{equation} GD(\tilde{Z}) = -\tau \sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta^*) \label{eq:gradient_descent} \end{equation}\)
여기서 경사하강법(Gardient Descent, GD)의 업데이트는 1차 업데이트의 우항에서 대체 데이터의 기울기 부분인 \(\sum_{z \in Z} \nabla_\theta \ell(z, \theta))\)와 일치합니다.
2차 업데이트 (Second-order update)
2차 업데이트는 단일 또는 다중 데이터 포인트가 모델에 미치는 영향을 정교하게 계산하고 이를 활용하여 언러닝을 수행합니다. 특히 헤시안 역행렬(Hessian Matrix)을 활용한 접근법은 정확성을 높이는 데 기여하지만, 계산 비용이 크다는 점은 해결해야 할 과제로 남아 있습니다.
헤시안 역행렬을 활용하면 데이터 삭제의 영향을 정교하게 계산할 수 있습니다. 단일 데이터 포인트가 모델 파라미터에 미치는 영향(Single Data Point Influence)은 아래와 같이 표현됩니다.
\[\begin{equation} \frac{\partial \theta_{\epsilon, z \to \tilde{z}}}{\partial \epsilon} \bigg|_{\epsilon=0} = -H_{\theta^*}^{-1} \left( \nabla_\theta \ell(\tilde{z}, \theta^*) - \nabla_\theta \ell(z, \theta^*) \right) \label{eq:single_data_influence} \end{equation}\]이 수식은 원본 데이터와 대체 데이터 간의 그래디언트 차이를 계산하고, 이를 헤시안 역행렬로 조정하여 모델 파라미터에 미치는 영향을 근사합니다.
단일 데이터 포인트의 영향을 다수의 데이터 포인트로 확장하기 위해 선형 근사(Linear Approximation)를 적용합니다. 선형 근사는 아래와 같이 표현됩니다.
\[\begin{equation} \theta^*_{z \to \tilde{z}} \approx \theta^* - H_{\theta^*}^{-1} \left( \nabla_\theta \ell(\tilde{z}, \theta^*) - \nabla_\theta \ell(z, \theta^*) \right) \label{eq:linear_approximation} \end{equation}\]이 수식은 단일 데이터 포인트의 영향을 다수의 데이터 포인트로 확장하여 모델 파라미터를 업데이트하는 방법을 제공합니다.
다중 데이터 포인트를 고려한 최종 업데이트 공식(Final Second-order update)은 아래와 같이 표현됩니다.
\[\begin{equation} \Delta(Z, \tilde{Z}) = -H_{\theta^*}^{-1} \left( \sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta^*) - \sum_{z \in Z} \nabla_\theta \ell(z, \theta^*) \right) \label{eq:final_second_order_update} \end{equation}\]이 수식은 모든 데이터 포인트에 대해 기울기(gradient) 차이를 계산하고 이를 헤시안 역행렬로 조정하여 전체 모델 업데이트를 수행합니다.
이와 같이, 2차 업데이트(Second-order update)는 데이터 포인트의 영향을 정교하게 반영하여 모델의 성능을 향상시킵니다.
언러닝(Unlearning) 성능 평가 실험
본 글에서는 1) 민감한 특징 제거(Sensitive Features), 2) 의도치 않은 기억 삭제(Unintended Memorization), 3) 데이터 포이즈닝 대응(Data Poisoning)이라는 세 가지 주요 시나리오를 중심으로 ‘특징 및 라벨 기반 언러닝(Machine Unlearning of Features and Labels)’의 언러닝 성공 여부를 평가한 결과를 간결하게 정리합니다.
성능 평가 지표
언러닝의 성공 여부는 다음 세 가지 지표로 평가됩니다.
첫 번째, 효과성(Efficacy)은 선택된 데이터가 모델에서 얼마나 완전히 제거되었는지 측정합니다.
두 번째, 충실도(Fidelity)는 언러닝 후 모델이 원래의 성능을 얼마나 유지하는지 평가합니다.
세 번째, 효율성(Efficiency)은 재학습(retraining) 대비 언러닝에 소요되는 시간과 자원을 비교합니다.
주요 시나리오와 성능 평가 결과
시나리오 1. 민감한 특징 제거(Sensitive Features)
스팸 필터링, 악성코드 탐지 등에서 민감한 특징을 제거하여 모델 성능을 유지하면서도 데이터를 안전하게 삭제하는 것을 목표로 합니다.
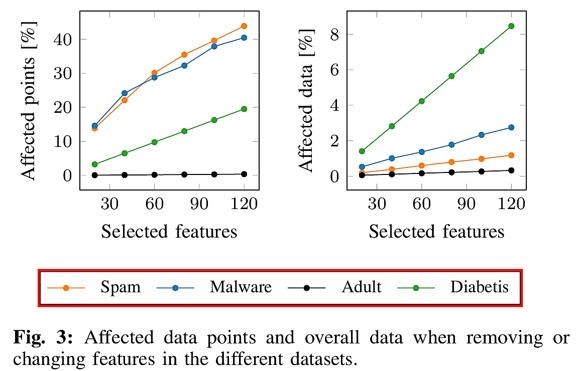
위 그림의 좌측에서와 같이 전체 데이터의 특정 특징을 제거하면 다수의 데이터 포인트에 영향을 미치는 반면, 우측에서와 같이 개별 데이터 포인트의 특정 값을 대체하면 소수의 데이터 포인트에만 영향을 미치는 것을 확인할 수 있습니다.
결론적으로, 2차 업데이트(Second-order update)는 효과성, 충실도, 효율성 간 최상의 균형을 제공하고, 1차 업데이트(First-order update)는 가장 빠른 실행 속도를 기록하며, 재학습 대비 약 90배의 속도를 향상시킨다.
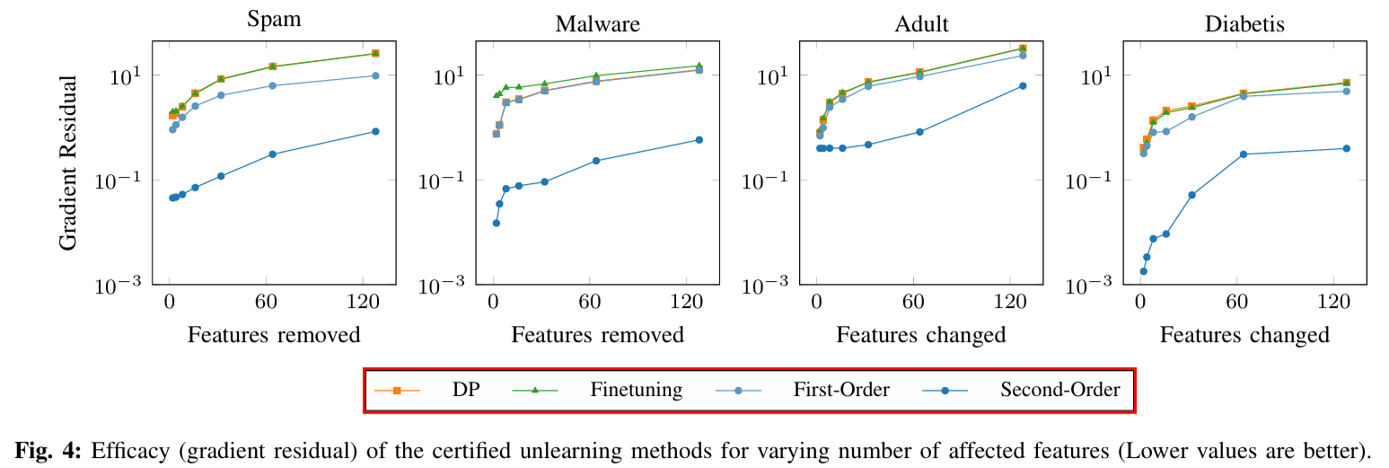
제거된 특징의 수가 증가할 수록 기울기 잔차(gradient residual)가 커지며, 이는 언러닝(Unlearning)과 재학습(retraining) 간의 차이가 크기 때문에 효과성(Efficacy)이 낮습니다.
| 데이터셋 | 차등 프라이버시(DP) | 미세 조정(Fine-tuning) | 1차 업데이트(First-order Update) | 2차 업데이트(Second-order Update) |
|---|---|---|---|---|
| 스팸(Spam) | 높음 | 중간 | 중간 | 낮음 |
| 악성코드(Malware) | 높음 | 중간 | 중간 | 낮음 |
| 당뇨병(Diabetes) | 높음 | 중간 | 중간 | 낮음 |
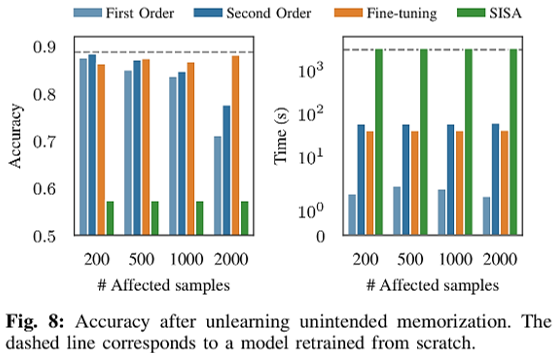
시나리오 2. 의도치 않은 정보 기억 제거(Unintended Memorization)
언어 모델이 신용카드 번호와 같은 민감 정보를 의도치 않게 기억하지 않도록 방지하는 것을 목표로 합니다.
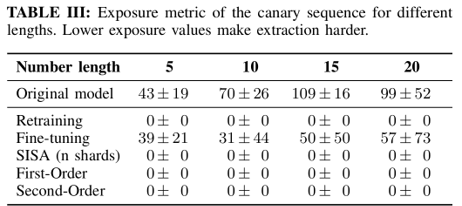
1차 업데이트(First-order update)와 2차 업데이트(Second-order update)는 노출 지표(Exposure Metric)를 거의 “0”으로 줄여 데이터 추출을 불가능하게 만들어서 효과성(Efficacy)를 높입니다.
미세 조정(Fine-Tuning)은 높은 정확도(accuracy)를 유지하지만, 민감 데이터 삭제에는 실패하여 효과성(Efficacy)이 낮습니다.
시나리오 3. 데이터 포이즈닝 대응(Data Poisoning)
악의적인 데이터 레이블 조작으로 인한 객체 인식 시스템의 성능 저하를 방지하는 것이 목표입니다.
2차 업데이트(Second-order update)는 대규모 데이터를 수정할 때에도 높은 충실도를 유지합니다.
반면, 샤딩(SISA)은 다수결 투표 방식의 불안정성으로 인해 성능이 낮습니다.
언러닝 방법의 실행 속도를 비교한 결과, 1차 업데이트(First-order update)는 재학습 대비 약 1000배 빠른 실행 속도를 보여주었습니다. 또한, 2차 업데이트(Second-order update)는 GPU 가속 없이도 약 28배 속도가 향상되었습니다.
성능 평가 결과 Summary
세 가지 시나리오를 분석한 결과, 효과성(Efficacy) 측면에서 2차 업데이트(Second-order update)가 가장 뛰어난 성과를 보였습니다.
충실도(Fidelity) 측면에서는 1차 업데이트(First-order update)와 2차 업데이트(Second-order update) 모두 높은 충실도를 유지하고 있습니다.
마지막으로, 효율성(Efficiency) 측면에서는 1차 업데이트(First-order update)가 가장 빠르고 실용적인 방법으로 평가됩니다.
종합적으로 성능 평가 결과를 고려할 때, ‘특징 및 라벨 기반 언러닝(Machine Unlearning of Features and Labels)’의 두 가지 전략인 1차 업데이트(First-order update)와 2차 업데이트(Second-order update)는 재학습(Retraining), 차등 프라이버시(Differential Privacy, DP), 미세 조정(Fine-tuning), 샤딩(SISA)와 비교했을 때 성능 평가에서 가장 우수한 결과를 나타냅니다.
결론
본 논문은 영향 함수(Influence function)를 활용하여 특징(features)과 라벨(labels)을 언러닝하는 프레임워크를 제안하며, 폐쇄형 업데이트(Closed-form update)를 사용하여 신속하게 데이터를 삭제할 수 있도록 합니다. 특징 및 레이블 기반 언러닝(Machine Unlearning of Features and Labels)을 수학 공식을 통해 이론적으로 그리고 실제 실험을 통해서 검증하였고, 강한 볼록 손실 함수(Strong-Covexity Loss function) 환경에서 인증된 언러닝(Certified Unlearning)을 달성했습니다. 그러나 여전히 대규모 데이터 포인트(data points)에 대한 효율성 저하, 인증된 언러닝(Certified Unlearning)의 제한, 개인 정보 유출 탐지의 복잡성 등 해결해야 할 과제가 남아 있습니다. 본 연구의 발견이 언러닝 방식의 효율성을 높이는 최적화 방법 개발에 기여하길 바랍니다.