Paper: Machine Unlearning of Features and Labels
Authors: Alexander Warnecke, Lukas Pirch, Christian Wressnegger, Konrad Rieck
Venue: Network and Distributed System Security Symposium (NDSS) 2023
URL: https://www.ndss-symposium.org/wp-content/uploads/2023/02/ndss2023_s87_paper.pdf
Introduction
Removing sensitive information from machine learning models is a critical challenge for data privacy protection. As legal requirements such as GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act) have been strengthened, the need for unlearning techniques that can safely remove specific data points has grown. Unlearning refers to “a technique that not only removes specific data from a model but also effectively eliminates the information learned from that data.” This technique is particularly important when considering data sensitivity and is essential for meeting legal requirements related to personal information protection. Existing unlearning methods focused on removing entire data points, but this approach can be inefficient. “Machine Unlearning of Features and Labels” is a paper that proposes a faster and more efficient unlearning approach called ‘Machine Unlearning of Features and Labels.’ In this article, we examine the paper’s content and explore how this unlearning approach is applied to complex neural network models through actual experiments.
Preliminary
Influence Function
To understand the Machine Unlearning of Features and Labels approach, one must first understand the principles of the influence function. The influence function is useful for quantitatively evaluating the impact of a data point on a model. When you want to know how much a specific piece of data changes the model’s prediction results, you use the influence function, which is expressed as follows.
\[\begin{equation} \mathcal{I}(z,y) = -H_{\theta^*}^{-1} \nabla_\theta \ell(z,y;\theta^*) \label{eq:influence} \end{equation}\]This function represents the change in the model’s parameters, i.e., the prediction results, when the selected data point (z, y) is removed from the model. By comprehensively analyzing these changes, the importance and influence of data points to be removed during the unlearning process are accurately evaluated and adjusted.
Lambda-Strong Convexity
Lambda-Strong Convexity is an important property that guarantees the stability and convergence of optimization problems, ensuring that the model training process is stable and well-optimized. When a model trains, the shape of the loss function must be convex to find optimal values. Lambda-Strong Convexity is expressed as follows.
\[\begin{equation} H_{\theta^*} \succeq \lambda I \label{eq:strong_convexity_1} \end{equation}\]This condition ensures that the Hessian Matrix is always positive, which helps the model converge stably during the optimization process. Simply put, it can be understood as preventing the loss function from being too flat or too bumpy.
Closed-form Update
The most important step in the unlearning process is determining how to update the model’s parameters when specific data is removed, and the closed-form parameter is defined as $\theta’$.
\[\begin{equation} \theta' = \theta^* - \eta H^{-1}(\theta^*)\nabla_\theta\ell(z,y;\theta^*) \label{eq:closed_form_update} \end{equation}\]Through this formula, the model’s parameters are adjusted in the direction that cancels out the influence of the data point \((z,y)\) to be removed during the unlearning process. This method allows the effective removal of specific data’s influence without retraining the entire model.
Main Content
This paper starts from the question: “Is there a new unlearning approach that can overcome the limitations of unlearning methods that delete entire data and delete data more efficiently?”
Limitations of Existing Unlearning Methods and the Need for Feature and Label-Based Algorithms
Instance-Based Unlearning removes individual data points and is inefficient for distributed data or neural networks.
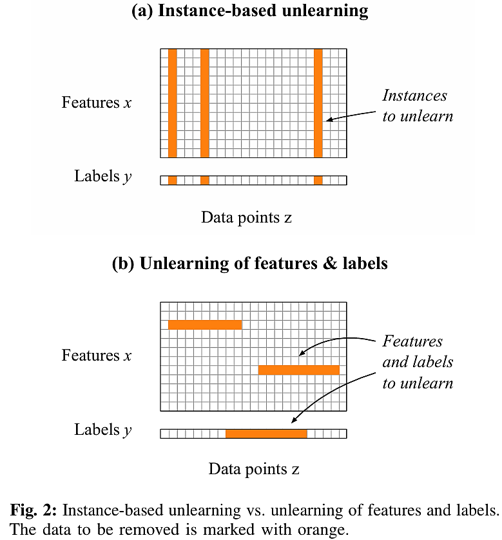
The figure above illustrates the limitations of Instance-based Unlearning compared to Machine Unlearning of Features and Labels.
Instance-based Unlearning shows diminishing performance benefits as the number of affected data points increases. Therefore, removing entire instances can unnecessarily degrade the model’s performance.
Next, Sharding divides the data and can speed things up by retraining some data, but as the amount of data to be removed increases, the probability of having to retrain all shards increases, causing efficiency to drop sharply.
The main challenges of Retraining can be summarized into three key points.
When small changes occur in large datasets, the entire model must be retrained, consuming significant time and computing resources. Additionally, compliance with privacy regulations and obtaining user consent are required, and data management becomes complex because original data cannot be stored indefinitely. Finally, in online learning systems where training data is continuously updated, outdated or inappropriate data must be quickly removed, requiring continuous data quality management.
So, what methods should be used to overcome these problems? This paper proposes an unlearning approach based on features and labels.
This approach can modify specific features and labels within training data through the model’s closed-form update based on feature values and labels rather than data instances.
Feature and label-based unlearning has two advantages.
First, in terms of efficiency, although privacy issues affect multiple data instances, directly modifying specific feature values or labels is more efficient.
Second, in terms of flexibility, there is the advantage of being able to modify specific feature values and labels of the original training data by utilizing influence functions.
Next, two update strategies are proposed for Machine Unlearning of Features and Labels.
First-order Update
The first-order update is a method that adjusts the model’s parameters using the gradient of the loss function. In this process, the influence of the original data \(Z\) is minimized, and the update is performed using substitute data \(\tilde{Z}\) to improve model performance.
The first-order update is expressed as follows.
\[\begin{equation} \Delta(Z, \tilde{Z}) = -\tau \left( \sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta) - \sum_{z \in Z} \nabla_\theta \ell(z, \theta) \right) \label{eq:first_order_update} \end{equation}\]\(\sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta)\) represents the gradient of the original data, and \(\sum_{z \in Z} \nabla_\theta \ell(z, \theta)\) represents the gradient of the substitute data. In the first-order update, specific data can be unlearned through this gradient difference.
This method is applicable to any model as long as the loss function is differentiable, enabling simple yet efficient information deletion. The unlearning rate $\tau$ must be appropriately adjusted for effective unlearning (Carlini et al.).
The first-order update operates in a manner similar to Gradient Descent (GD). Gradient Descent (GD) updates model parameters using the gradient of the substitute data \(\tilde{Z}\), and is expressed as follows. \(\begin{equation} GD(\tilde{Z}) = -\tau \sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta^*) \label{eq:gradient_descent} \end{equation}\)
Here, the Gradient Descent (GD) update corresponds to the substitute data gradient part \(\sum_{z \in Z} \nabla_\theta \ell(z, \theta))\) in the right-hand side of the first-order update.
Second-order Update
The second-order update precisely calculates the influence of single or multiple data points on the model and uses this to perform unlearning. In particular, the approach utilizing the Hessian Matrix contributes to increased accuracy, but the high computational cost remains a challenge to be addressed.
Using the inverse Hessian matrix enables precise calculation of the impact of data deletion. The influence of a single data point on model parameters (Single Data Point Influence) is expressed as follows.
\[\begin{equation} \frac{\partial \theta_{\epsilon, z \to \tilde{z}}}{\partial \epsilon} \bigg|_{\epsilon=0} = -H_{\theta^*}^{-1} \left( \nabla_\theta \ell(\tilde{z}, \theta^*) - \nabla_\theta \ell(z, \theta^*) \right) \label{eq:single_data_influence} \end{equation}\]This formula calculates the gradient difference between the original data and the substitute data, and adjusts it with the inverse Hessian matrix to approximate the influence on model parameters.
To extend the influence of a single data point to multiple data points, linear approximation is applied. The linear approximation is expressed as follows.
\[\begin{equation} \theta^*_{z \to \tilde{z}} \approx \theta^* - H_{\theta^*}^{-1} \left( \nabla_\theta \ell(\tilde{z}, \theta^*) - \nabla_\theta \ell(z, \theta^*) \right) \label{eq:linear_approximation} \end{equation}\]This formula provides a method to update model parameters by extending the influence of a single data point to multiple data points.
The Final Second-order Update formula considering multiple data points is expressed as follows.
\[\begin{equation} \Delta(Z, \tilde{Z}) = -H_{\theta^*}^{-1} \left( \sum_{\tilde{z} \in \tilde{Z}} \nabla_\theta \ell(\tilde{z}, \theta^*) - \sum_{z \in Z} \nabla_\theta \ell(z, \theta^*) \right) \label{eq:final_second_order_update} \end{equation}\]This formula calculates the gradient difference for all data points and adjusts it with the inverse Hessian matrix to perform the overall model update.
In this way, the second-order update precisely reflects the influence of data points to improve the model’s performance.
Unlearning Performance Evaluation Experiments
In this article, we concisely summarize the results of evaluating unlearning success for ‘Machine Unlearning of Features and Labels’ across three key scenarios: 1) Sensitive Features removal, 2) Unintended Memorization removal, and 3) Data Poisoning response.
Performance Evaluation Metrics
The success of unlearning is evaluated using the following three metrics.
First, Efficacy measures how completely the selected data has been removed from the model.
Second, Fidelity evaluates how well the model maintains its original performance after unlearning.
Third, Efficiency compares the time and resources required for unlearning relative to retraining.
Key Scenarios and Performance Evaluation Results
Scenario 1. Sensitive Features
The goal is to safely delete data while maintaining model performance by removing sensitive features in applications such as spam filtering and malware detection.
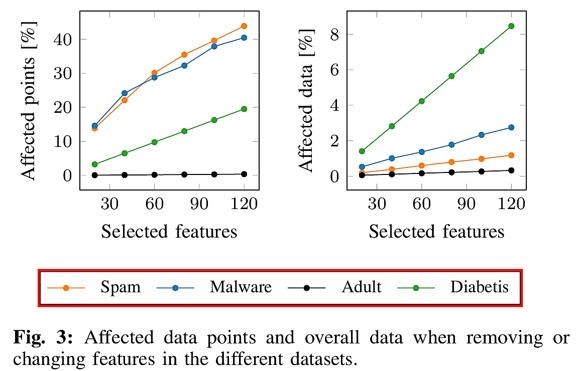
As shown on the left side of the figure above, removing specific features from the entire data affects a large number of data points, while replacing specific values of individual data points on the right side affects only a small number of data points.
In conclusion, the second-order update provides the best balance among efficacy, fidelity, and efficiency, while the first-order update records the fastest execution speed, achieving approximately 90x speed improvement over retraining.
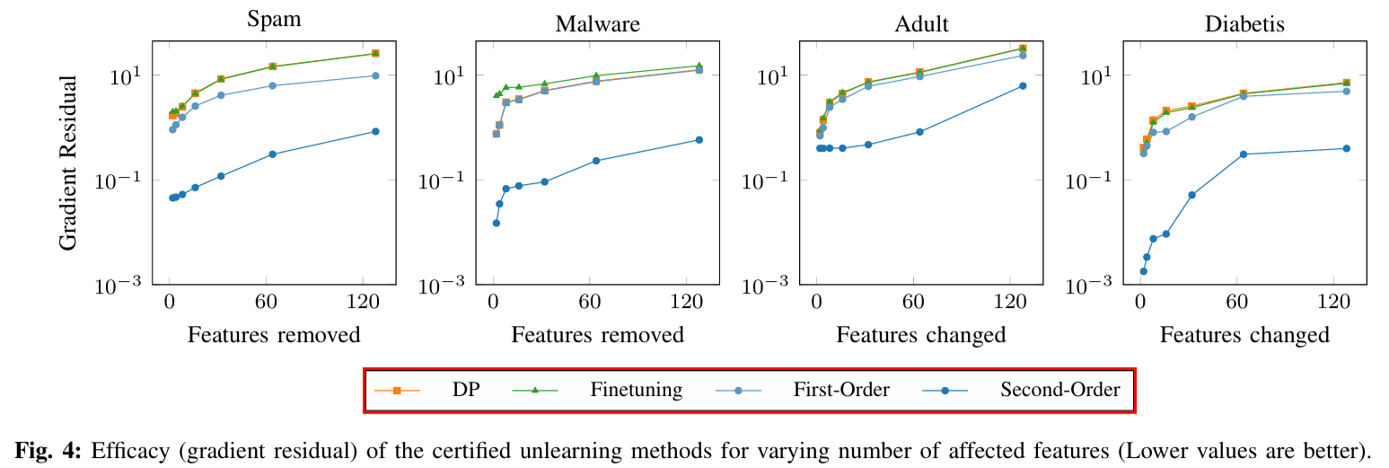
As the number of removed features increases, the gradient residual grows, indicating low efficacy because the difference between unlearning and retraining is large.
| Dataset | Differential Privacy (DP) | Fine-tuning | First-order Update | Second-order Update |
|---|---|---|---|---|
| Spam | High | Medium | Medium | Low |
| Malware | High | Medium | Medium | Low |
| Diabetes | High | Medium | Medium | Low |
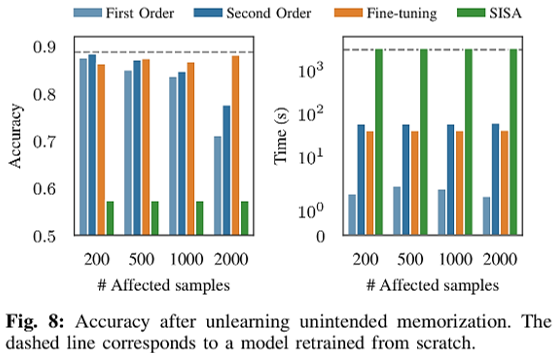
Scenario 2. Unintended Memorization
The goal is to prevent language models from unintentionally memorizing sensitive information such as credit card numbers.
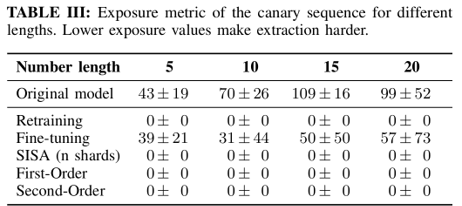
The first-order update and second-order update reduce the exposure metric to nearly “0,” making data extraction impossible and increasing efficacy.
Fine-Tuning maintains high accuracy but fails to delete sensitive data, resulting in low efficacy.
Scenario 3. Data Poisoning
The goal is to prevent performance degradation of object recognition systems caused by malicious data label manipulation.
The second-order update maintains high fidelity even when modifying large-scale data.
In contrast, SISA (Sharding) shows low performance due to the instability of majority voting.
Comparing the execution speed of unlearning methods, the first-order update demonstrated approximately 1000x faster execution speed compared to retraining. Additionally, the second-order update achieved approximately 28x speed improvement even without GPU acceleration.
Performance Evaluation Results Summary
After analyzing the three scenarios, in terms of Efficacy, the second-order update demonstrated the best performance.
In terms of Fidelity, both the first-order update and second-order update maintain high fidelity.
Finally, in terms of Efficiency, the first-order update is evaluated as the fastest and most practical method.
Considering the overall performance evaluation results, the two strategies of ‘Machine Unlearning of Features and Labels’ – the first-order update and second-order update – show the best results in performance evaluation compared to Retraining, Differential Privacy (DP), Fine-tuning, and SISA (Sharding).
Conclusion
This paper proposes a framework for unlearning features and labels using influence functions, and uses closed-form updates to enable rapid data deletion. Machine Unlearning of Features and Labels was verified both theoretically through mathematical formulas and through actual experiments, achieving Certified Unlearning in a Strong-Convexity Loss function environment. However, challenges remain, including efficiency degradation for large-scale data points, limitations of Certified Unlearning, and the complexity of detecting personal information leakage. We hope the findings of this research will contribute to developing optimization methods that improve the efficiency of unlearning approaches.