Paper: PRADA: Protecting Against DNN Model Stealing Attacks
Authors: Mika Juuti, Sebastian Szyller, Samuel Marchal, N. Asokan
Venue: Symposium on Security and Privacy (EuroS&P), Stockholm, Sweden, 2019. IEEE.
Introduction
Thanks to advances in deep learning, MLaaS (Machine-Learning-as-a-Service) has emerged to help leverage machine learning models for decision-making. MLaaS users can easily access prediction models running in the cloud through APIs. However, these prediction models are at risk of being stolen by malicious users.
Attackers attempt to acquire information to reproduce prediction models. To do this, attackers repeatedly send queries to the API, and the API repeatedly responds. In this process, the API inevitably leaks model information, and attackers can use this to extract the API’s prediction model. This paper conducts experiments that induce the API to leak more model information than existing attack techniques, further improving the performance of existing attack techniques.
As a defense technique, PRADA (Protecting Against DNN Model Stealing Attacks) is proposed. PRADA uses an attack detection approach that does not depend on the model structure or training data, providing versatile defense performance. This paper demonstrates through experiments that PRADA is effective in defending against model extraction.
Background
Assumptions
The attacker is assumed to know the shape of the original model’s input layer, hidden layers, and output layer, as well as the activation functions applied to each layer. However, the attacker cannot access the model’s internal parameters (weights or biases) and can only obtain the model’s output (labels or class probabilities) through the prediction API – a black-box environment is assumed.
Furthermore, the only data available to the attacker at the initial stage is seed samples.
Model Extraction Algorithm

| Symbol | Meaning |
|---|---|
| \(F\) | Original model under attack |
| \(X \in \mathbb{R}^n\) | Input data |
| \(Y \in \mathbb{R}^m\) | Output data |
| \(\hat{F}\) | Predicted class of the original model |
| \(F'\) | Substitute model reproduced by the attacker |
| \(U \ in \ row \ 6\) | Unlabeled seed samples |
| \(U \ in \ row \ 13\) | Unlabeled synthetic samples |
| \(L\) | Pairs of samples and labels returned by the prediction API |
| \(H\) | Hyperparameters for substitute model training |
| \(\rho\) | Number of retraining iterations |
Seed Samples
Seed samples are unlabeled data that the attacker uses for initial substitute model training in the early stages of a model extraction attack.
At the initial stage, the attacker possesses only seed samples and wants to use them as training data for the substitute model. However, since seed samples are unlabeled, they are not suitable for direct use as training data. To resolve this, the attacker inputs seed samples into the original model to obtain labels, and uses these labeled seed samples as training data for the substitute model.
Seed samples are classified into two types:
-
Natural Samples: Samples collected from real data distributions.
-
Random Samples: Samples randomly generated following a uniform distribution within the input space.
When training the substitute model with seed samples alone, it is difficult to precisely learn the original model’s decision boundary. To compensate for this, the attacker generates synthetic samples to use as additional training data.
Synthetic Samples
Synthetic samples are unlabeled samples intentionally created by the attacker to more effectively learn the original model’s decision boundary. The attacker inputs synthetic samples into the original model to obtain labels, then trains the substitute model with them multiple times. As these duplication rounds are repeated, the substitute model more accurately reflects the original model’s decision boundary.
This paper uses the following two synthetic sample generation methods:
-
JbDA (Jacobian-based Dataset Augmentation): Generates synthetic samples using the Jacobian matrix. (e.g., FGSM, I-FGSM, MI-FGSM)
-
Random generation: Generates synthetic samples by randomly transforming the color channels of input data. (e.g., COLOR)
FGSM Characteristics
\[\begin{align} x' \leftarrow x + \epsilon \cdot \operatorname{sign}\!\bigl(\nabla_{x}\,\mathcal{L}\bigl(F(x,c_{i})\bigr)\bigr) \end{align}\]As shown in the formula above, FGSM can simply generate adversarial examples. FGSM can be classified by the number of perturbation steps applied to the original data:
- FGSM: Perturbs the original data once by the maximum perturbation size ε in the gradient direction to generate adversarial examples.
- I-FGSM: Perturbs by ε/k iteratively k times. This generates more refined adversarial examples.
- MI-FGSM: Adds momentum optimization to I-FGSM.
It can also be classified by whether there is a target class:
- Non-targeted: Perturbs the original data so that it is not classified as the correct class.
- Targeted: Perturbs the original data so that it is classified as a specific class other than the correct class.

The black dots in the figure above are synthetic samples created through six rounds of retraining.
In (a), the synthetic samples generated by non-targeted FGSM overlap because they were created by alternating between the closest classes.
In contrast, (b) with the T-RND (Targeted Randomly) method shows significantly reduced overlap among synthetic samples because they were generated toward random target classes. Additionally, since (b) uses the I-FGSM method, the synthetic samples are generated close to the original model’s decision boundary.
Model Extraction Experiments
Objective
The goal of this experiment is to find the attack method that best reproduces the original model. The original model is an MLP model trained on MNIST and GTSRB.
Evaluation Metrics
The following metrics are used to evaluate which attack methods are effective for model extraction:
-
Agreement: Measures the fidelity of the substitute model.
- Test-agreement: Macro-averaged F1-score when inputting the actual test set to both the original model and the substitute model.
- RU-agreement: Ratio of identical predictions when inputting random points uniformly sampled from the input space to both the original and substitute models.
-
Transferability: Compares the decision boundaries of the original and substitute models to measure transferability.
- Non-targeted transferability: Attack success rate when adversarial samples generated in a non-targeted manner from the substitute model are input to the original model.
- Targeted transferability: Attack success rate when adversarial samples generated in a targeted manner from the substitute model are input to the original model.
Experimental Subjects
Existing attack techniques Papernot, Tramer, and variants of Papernot with modified hyperparameters – SAME and CV-search – were used as experimental subjects.
| Model Extraction Attack | Papernot | SAME | CV-search | Tramer |
|---|---|---|---|---|
| Seed sample type | Natural samples | Natural samples | Natural samples | Random samples |
| Hyperparameter selection | Attacker’s choice | Same as original model | CV-search | Attacker’s choice |
| Retraining iterations | 10+ | 10+ | 10+ | 1 |
| Synthetic sample generation | JbDA | JbDA | JbDA | Random generation, Line-search |
Attack Experimental Results
- Hyperparameter selection

Looking at CV-search in the results above, fidelity is similar to SAME, which uses the original hyperparameters. Moreover, transferability increases significantly with the number of retraining rounds compared to Papernot. Therefore, the CV-search method was effective for hyperparameter selection.
- Sample generation method for transferability evaluation

The results above show the misclassification success rate when adversarial examples generated by various methods from Papernot are input to the original model. The I-FGSM family shows the highest transferability, indicating that these methods generate adversarial examples very close to the decision boundary. Therefore, using I-FGSM family methods to generate transferability evaluation samples provides the best transferability assessment.
- Number of seed samples, class probabilities
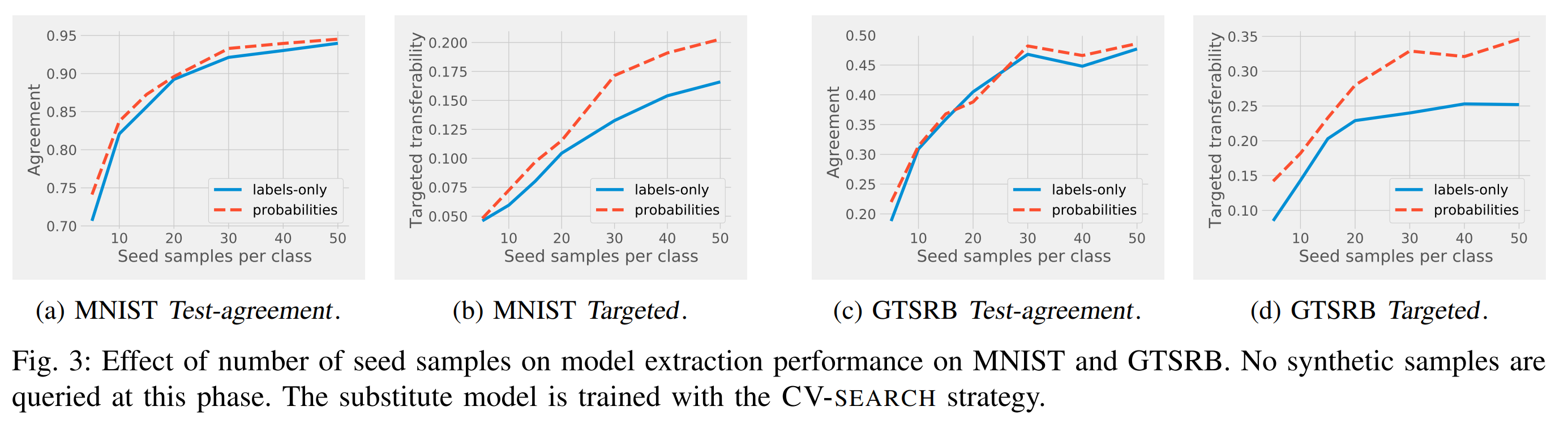
Looking at (a) and (c) in the results above, fidelity increases with the number of seed samples but is less affected by providing class probabilities. In contrast, looking at (b) and (d), transferability increases significantly when class probabilities are provided.
- Synthetic sample generation method
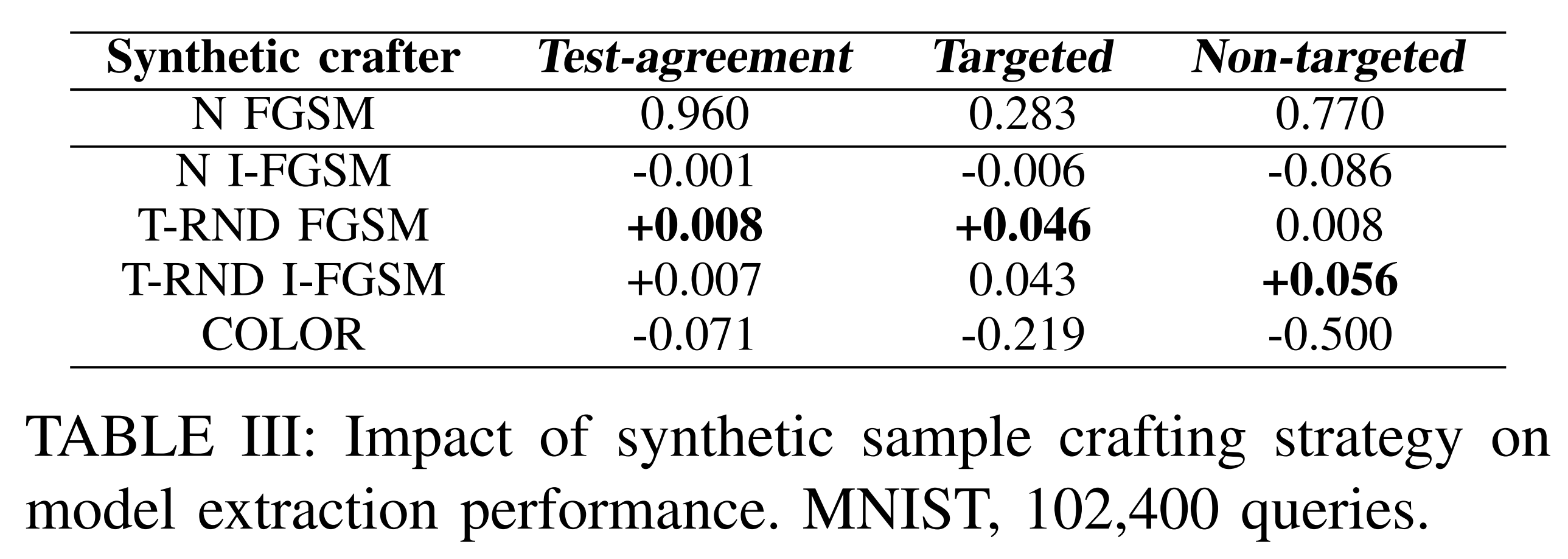
The results above show that fidelity and transferability are high when the substitute model is trained with T-RND synthetic samples.
- Model complexity mismatch
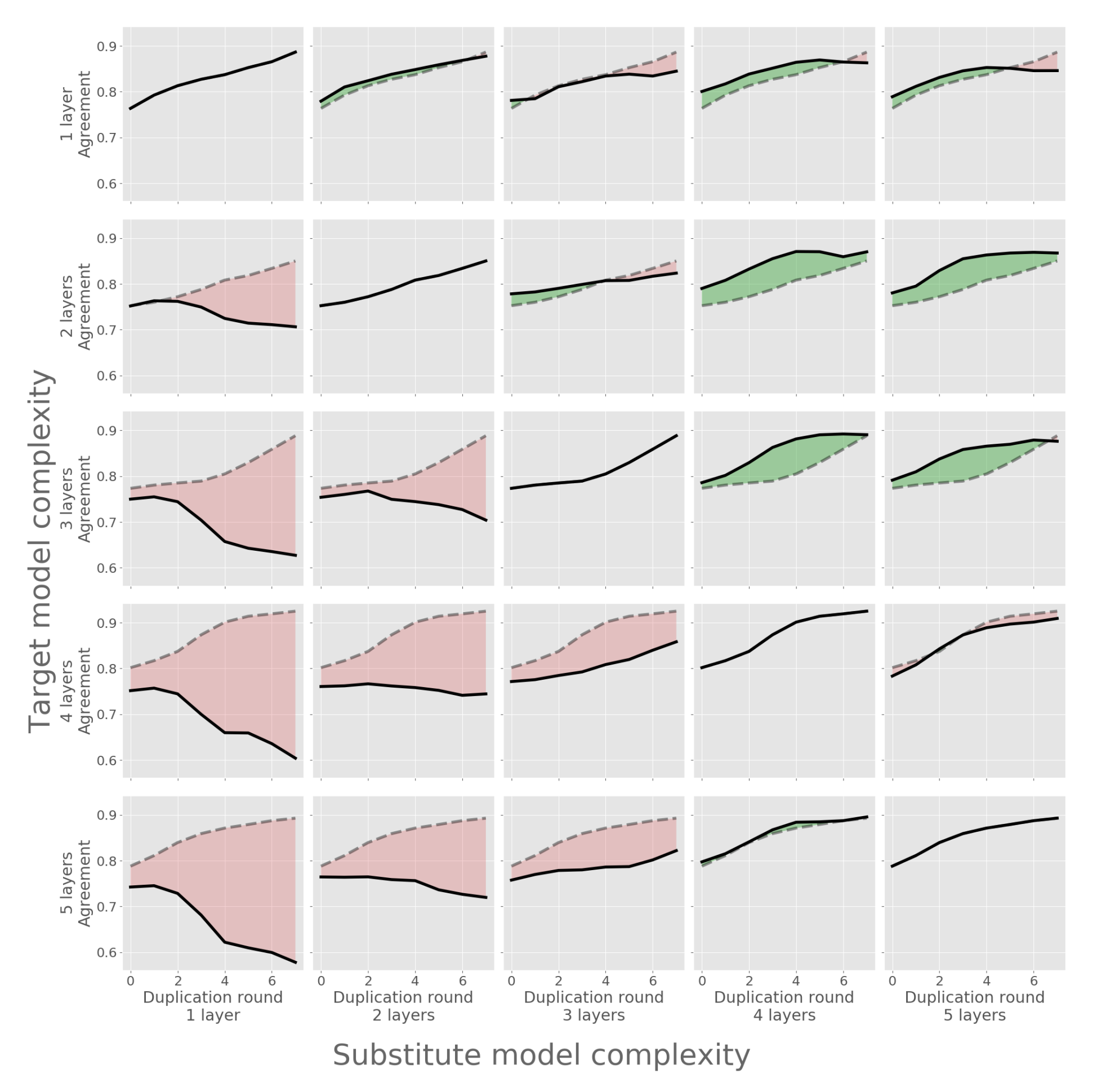
The figure above shows the Test-agreement based on the structural complexity difference between the original model and the substitute model. Diagonal elements represent cases where the complexity of both models matches. In each row, higher Test-agreement values relative to the diagonal element are shown in green, and lower values in red. As a result, fidelity improved when the substitute model’s complexity was equal to or higher than the original model’s.
Model Extraction Defense
PRADA
PRADA (Protecting Against DNN Model Stealing Attacks) is a defense technique that detects model extraction attacks through the attacker’s queries. PRADA does not judge individual queries as attacks, but rather determines whether an attack is occurring based on the distribution of consecutive queries.
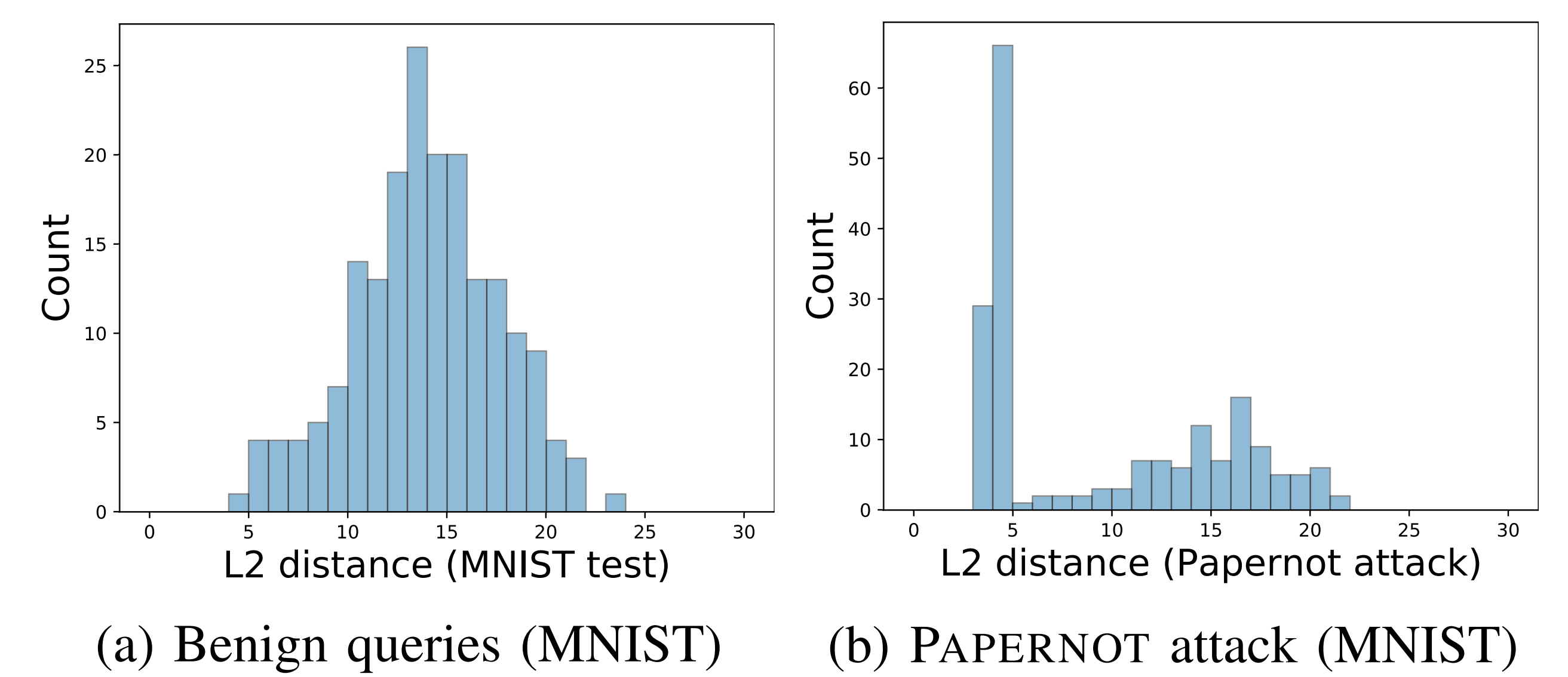
The distances between normal input samples are likely to approximate a normal distribution. Machine learning model inputs are generally defined within a finite space, and mathematically, the distances between two randomly selected points in a finite space approximate a normal distribution.
In contrast, the distances between attacker input samples are likely to deviate significantly from a normal distribution. This is because the attacker artificially adjusts distances between input samples to optimally explore the input space and leak information from the original model.
Therefore, PRADA determines whether an attack is occurring based on how much the distribution of distances between user input samples deviates from a normal distribution.
Defense Algorithm

Looking at the PRADA algorithm above, line 22 performs the Shapiro-Wilk normality test on the distance set D’ between input samples. The test statistic W(D’) is defined between 0 and 1.
As D’ deviates further from a normal distribution, W(D’) approaches 0. If W(D’) falls below the threshold δ, PRADA triggers an attack detection alert.
Evaluation Metrics
PRADA’s defense performance is evaluated through attack detection success, detection speed, and false positive (FP) rate. Detection speed is measured by the number of samples input before attack detection. The false positive rate is calculated as the ratio of false alarms for normal inputs.
Defense Performance
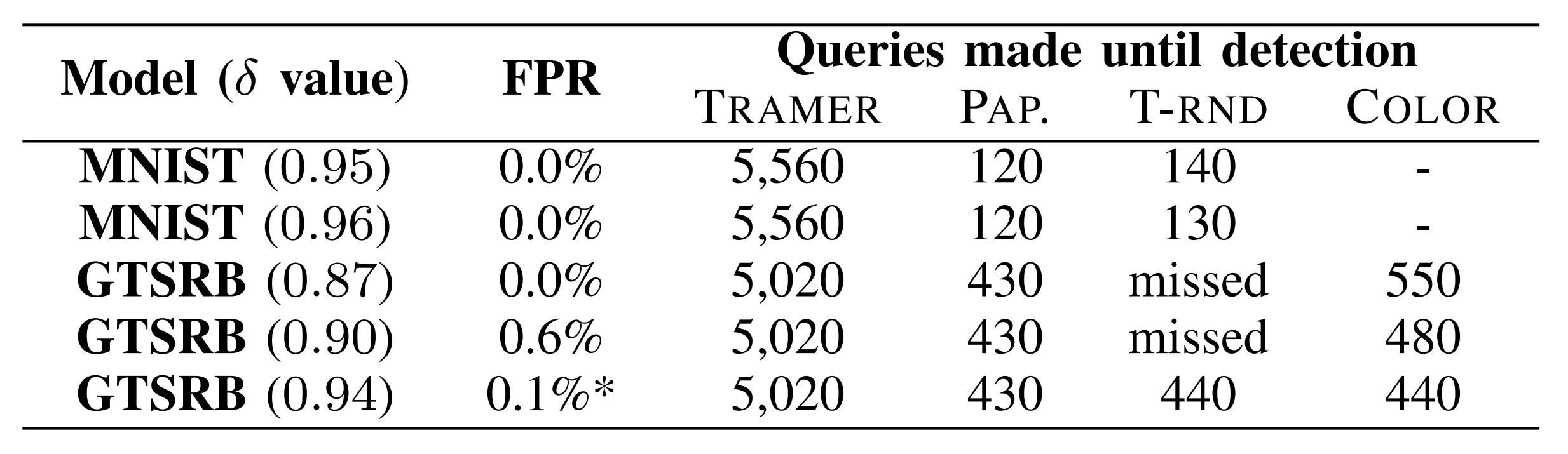
The results above show PRADA’s attack detection timing for the detection threshold δ.
The detection timing for Papernot, T-RND, and COLOR attacks was when transitioning from natural samples to synthetic samples, and for TRAMER attacks, it was when transitioning from random samples to line-search.
PRADA detected all attacks from the existing techniques Tramer and Papernot. However, the T-RND attack could not be detected for the GTSRB model when the detection threshold δ was too low, because the distances between synthetic samples generated by T-RND are large.
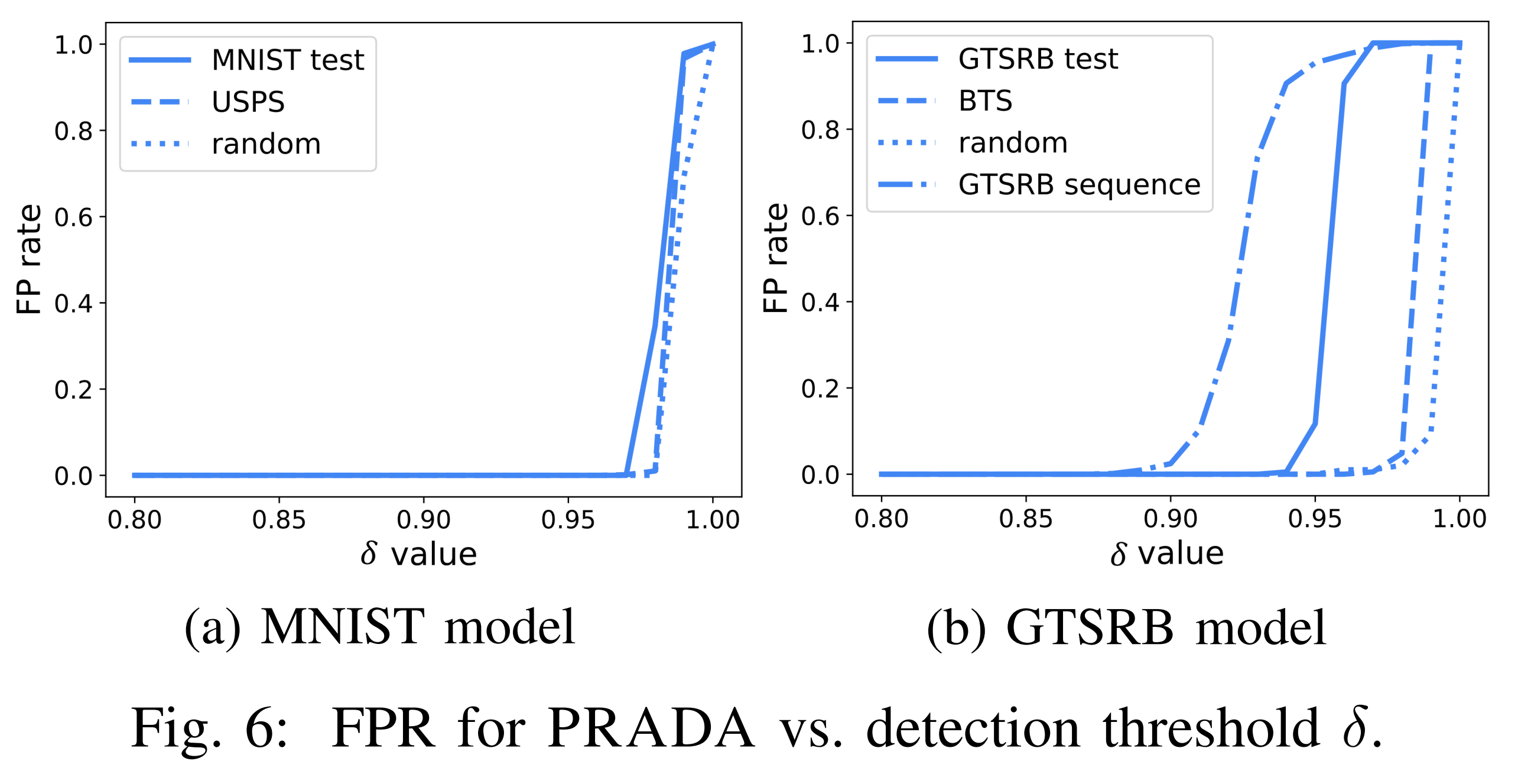
Looking at the graph above, for normal inputs, PRADA’s attack detection alert is only triggered when the W(D’) threshold is set at a relatively high level. This shows that PRADA has a low false positive rate across most threshold ranges.
Potential for Evasion
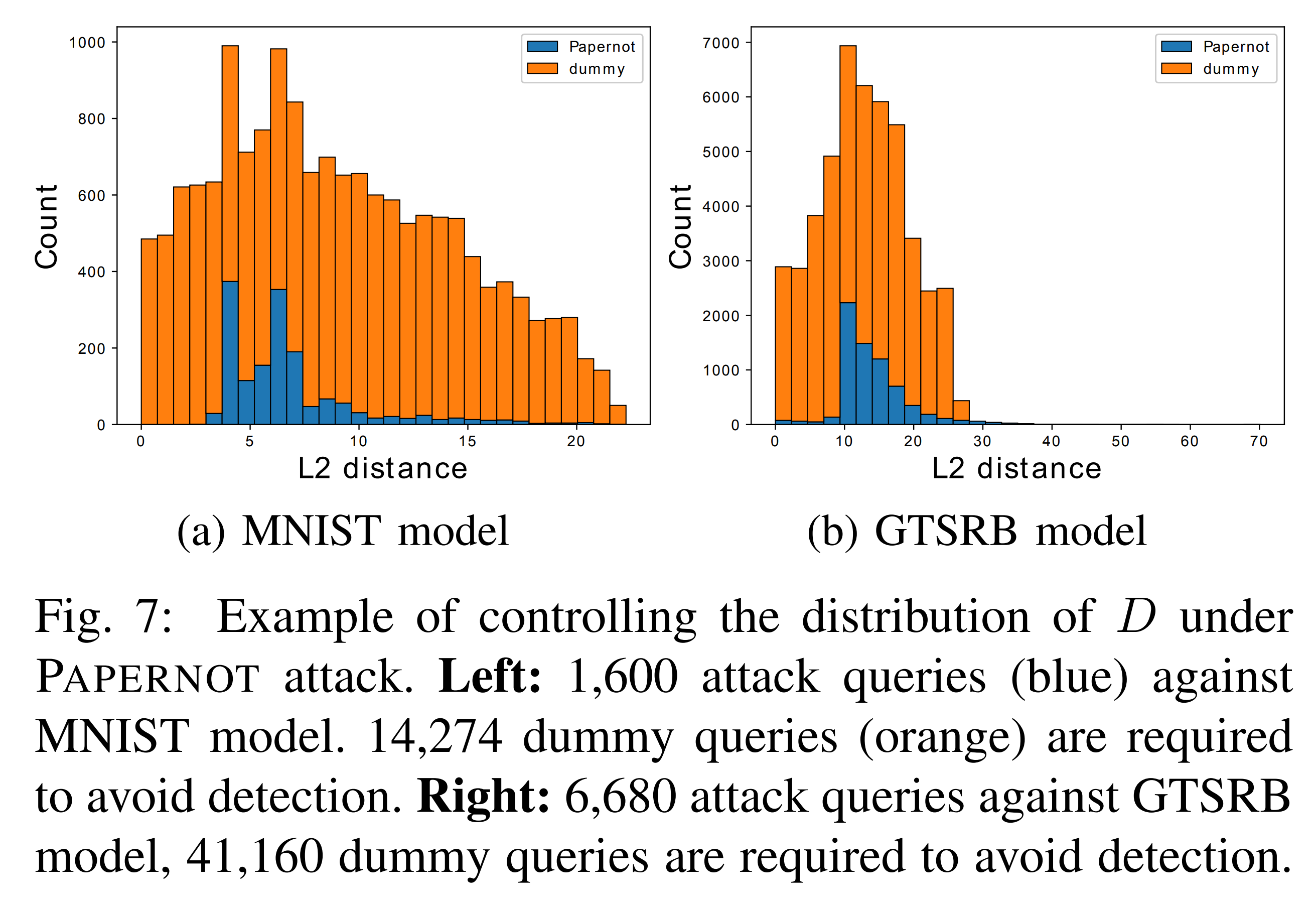
The graph above shows the attacker adding dummy queries to the input samples to make the distance distribution closer to a normal distribution in an attempt to evade PRADA.
However, the number of dummy queries needed to approximate a normal distribution was 3 to 10 times the number of actual queries. Therefore, PRADA demonstrates robustness against this evasion scenario.
Conclusion
This study improved the prediction accuracy and transferability of existing model extraction attacks and proposed the defense technique PRADA to detect them.
Through attack experiments, it was confirmed that hyperparameters, number of seed samples, and provision of probability vectors affect attack performance, with particularly excellent attack results when generating synthetic samples using the T-RND method.
PRADA detects attacks by analyzing how much the distribution of consecutive input samples deviates from a normal distribution, achieving a near-100% detection rate. Since it leverages patterns of consecutive samples rather than individual samples, it provides versatile defense performance that does not depend on model structure or training data.
Thanks to these advantages, PRADA can effectively defend against model extraction attacks even in black-box environments.