Paper: SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation
Authors: Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, Sijia Liu
Venue: 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
Prior Research
“Machine Unlearning” refers to the task of mitigating the influence of specific data points from a pre-trained model.
It is a field that has been actively researched recently to comply with regulations such as the EU’s “right to be forgotten,” and machine unlearning in the CV (Computer Vision) domain has gained particular attention.
This paper addresses the limitations of existing machine unlearning, particularly in image classification and image generation models, and proposes a new machine unlearning method called SalUn (Saliency-based Unlearning) as a solution.
Machine Unlearning in Image Generation Models
Existing image generation models, when receiving text as a condition, showed a tendency to heavily rely on text descriptions during image generation. Moreover, since they are often trained on massive datasets such as LAION-400M and LAION-5B, the probability of learning biases and harmful data contained in the datasets was high.
The purpose of this paper is to find a technique that can perform efficient and effective machine unlearning not only in image classification models but also in image generation models.
Limitations of Existing Machine Unlearning
Existing Machine Unlearning Techniques
The paper presents the following five machine unlearning techniques:
-
Fine Tuning (FT): Retrains the pre-trained model on the dataset excluding the data to be removed.
-
Random Labeling (RL): Randomly mislabels the target dataset for removal, then retrains the pre-trained model with the randomly labeled dataset.
-
Gradient Ascent (GA): Reverses the model’s learning on the target dataset for removal to maximize the loss.
-
Influence Unlearning (IU): Uses influence functions to erase the impact of the target dataset for removal from the pre-trained model.
-
L1-sparse MU: Introduces weight sparsity to remove the target data for removal.
Instability
Previous studies typically experimented with a fixed size of data to be removed. Therefore, research on the impact of the size or ratio of the forget dataset on machine unlearning performance was insufficient.
In graph (a), it can be observed that the performance gap with the Retrain method increases when removing 50% of the total data compared to removing 10%.
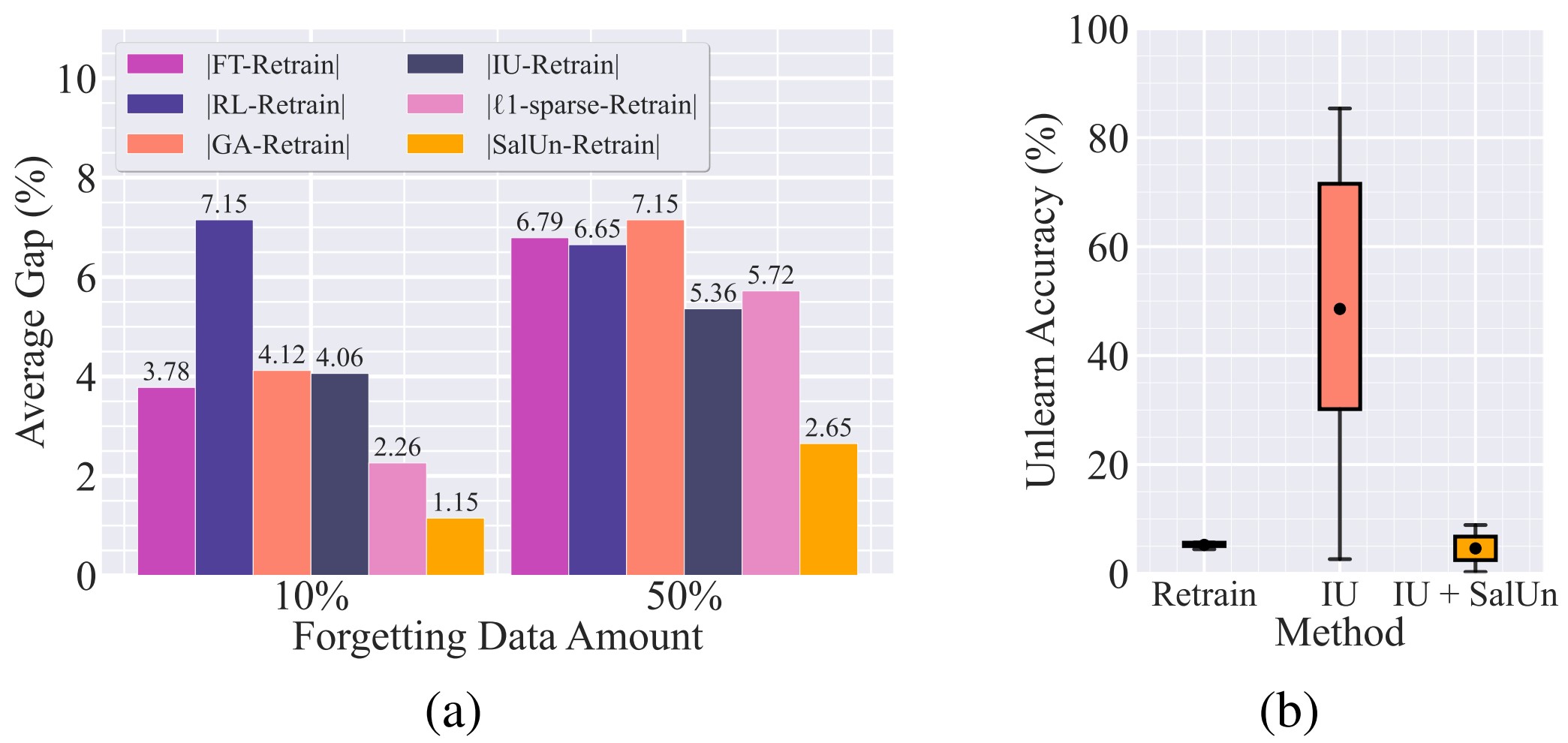
Additionally, in graph (b), unlike the Retrain method which shows stable accuracy performance, it can be observed that the performance of IU (Influence Unlearning) varies significantly depending on the hyperparameter used. This instability can be mitigated by applying IU and SalUn simultaneously.
Lack of Generality
Machine unlearning models have primarily been used for image classification tasks. However, machine unlearning methods for image classification models do not guarantee machine unlearning performance in image generation models.
This leads to problems of failing to remove data that should be removed (Under-forget) or removing data that should not be removed (Over-forget).
The following table shows the image generation results after class-wise forgetting of the specific class “airplane” for each machine unlearning technique: Retrain, GA, RL, FT, and l1-sparse.
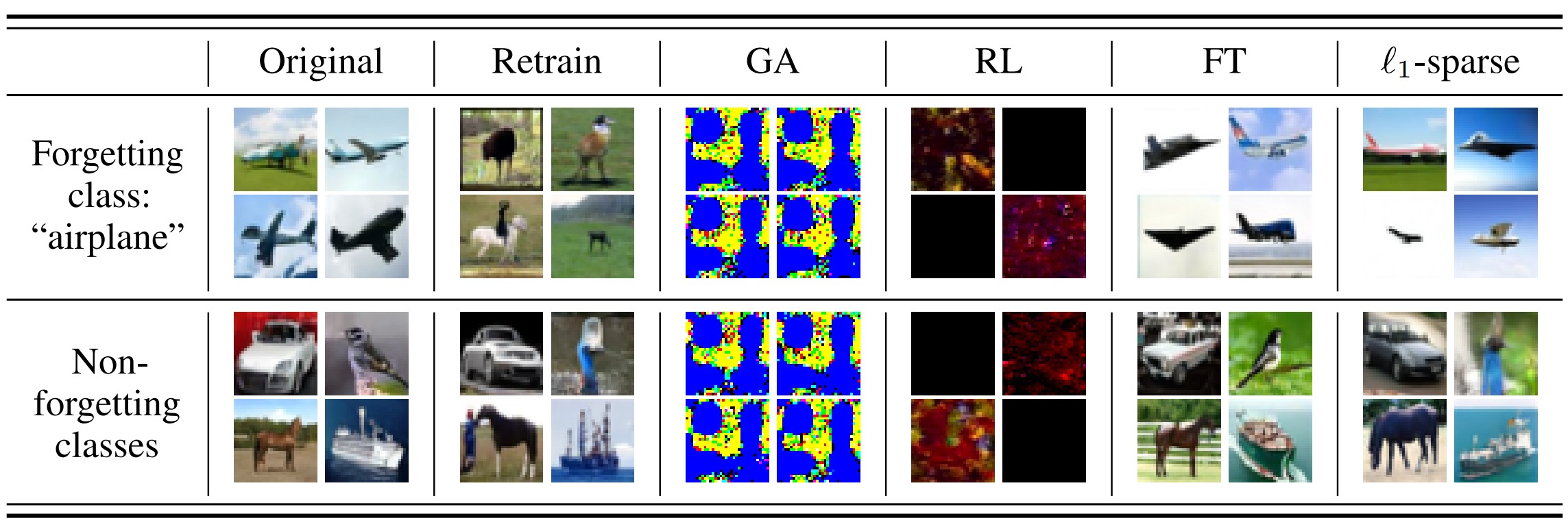
The results generated by GA and RL for the ‘Non-forgetting class’ indicate that the model also removed data that should not have been removed (Over-forget).
Additionally, from the results of FT and l1-sparse for the ‘forgetting class: “airplane”’, it can be seen that the model failed to effectively remove the class that should have been removed (Under-forget).
Machine Unlearning in Image Classification and Generation
Machine Unlearning Objectives
- Enable effective and efficient weight updates in the pre-trained model.
- Minimize the performance gap with the Retrain model.
The paper considers machine unlearning in both image classification models and image generation models.
Machine Unlearning in Image Classification Models
Image classification models are the most studied area in machine unlearning, and can be broadly divided into two machine unlearning methods depending on the composition of the forget dataset:
- Class-wise forgetting: Removes the influence of a specific image class from the dataset.
- Random data forgetting: Randomly removes several data points from the training set (e.g., randomly removing 10,000 data pairs from a total of 60,000 data pairs).
Evaluation Metric: ‘Full-stack’ Evaluation
This evaluates the machine unlearning performance in image classification models. Five evaluation metrics are used to ensure that no single metric alone represents the overall model performance.
-
Unlearning Accuracy (UA): Measures the model’s accuracy on the forget dataset.
-
Membership Inference Attack (MIA): Checks whether the forget data remains in the dataset after unlearning.
-
Remaining Accuracy (RA): Measures the fidelity of the model’s performance on the non-forget dataset after unlearning.
-
Testing Accuracy (TA): Measures the model’s overall accuracy on the entire dataset after unlearning.
-
Run-time Efficiency (RTE): Measures the computation time required to apply the unlearning technique.
Machine Unlearning in Image Generation Models
Objectives of Machine Unlearning in Image Generation Models
- Prevent the image generation model from generating inappropriate images.
- Ensure that the DM with updated weights after machine unlearning preserves its image generation performance for normal images.
The paper addresses the problem of conditional Diffusion Models (DMs) generating harmful images when receiving inappropriate prompts.
Diffusion Process
Two types of DMs are used:
1) DDPM (Denoising Diffusion Probabilistic Model) with classifier-free guidance
2) LDM (Latent Diffusion Model)
The conventional classifier-free DM is trained through the following process.
\[\begin{equation} \hat{\epsilon}_o(x_t | c) = (1 - w) \epsilon_o(x_t | \emptyset) + w \epsilon_o(x_t | c) \end{equation}\]Here, \(c\) refers to a text prompt or concept, and the above equation consists of multiplying the noise generated conditioned on \(c\) by weight \(w\), and multiplying the noise generated without \(c\) by \((1-w)\).
In other words, this is the process of computing the final noise by considering both unconditional noise and conditional noise when \(c\) is given.
SalUn: Weight Saliency is Possibly All You Need for MU
Gradient-based Weight Saliency Map
Unlike existing machine unlearning techniques, SalUn does not modify all weights but instead updates only specific model weights according to their importance as determined by the saliency map.
The saliency map can be expressed as the following equation.
\[\begin{equation} m_S = \mathbb{1}(|\nabla_{\theta} \ell_f (\theta; \mathcal{D}_f) |_{\theta = \theta_0} \geq \gamma) \end{equation}\]Here, the saliency map serves as a form of masking that returns 1 if the absolute value of the gradient for specific data exceeds a certain threshold, and returns 0 otherwise.
Applying the above saliency map equation to the machine unlearning process, the following equation can be derived.
\[\begin{equation} \theta_u = m_S \odot (\Delta \theta + \theta_0) + (1 - m_S) \odot \theta_0 \end{equation}\]The left side represents the model after unlearning. When the saliency map value is 1, the weight update is applied; when the saliency map value is 0, the original model weights are retained.
This shows that the model applies only salient (important) weight changes to its learning.

The performance of the saliency mask can be confirmed through comparison with random masking in the table above.
Notably, when random masking was applied without considering weight saliency, the Over-forget phenomenon occurred, resulting in the generation of only noise.
Saliency-based Unlearning
SalUn in Image Classification Models
SalUn is used together with Random Labeling leveraging its plug-and-play property. Each data point targeted for removal is randomly assigned a label, and then the dataset is fine-tuned using the saliency map.
\[\begin{equation} \underset{\Delta\theta}{\text{minimize}}\quad L_{\text{SalUn}}^{(1)} (\theta_u) \ \mathbb{E}_{(x,y) \sim \mathcal{D}_f, y' \neq y} \left[ \ell_{\text{CE}} (\theta_u; \mathbf{x}, y') \right] + \alpha \mathbb{E}_{(x,y) \sim \mathcal{D}_r} \left[ \ell_{\text{CE}} (\theta_u; \mathbf{x}, y) \right] \end{equation}\]The following graph compares SalUn’s performance with seven other unlearning techniques.

It can be confirmed that the performance gap with the Retrain method was smallest when machine unlearning was performed using SalUn, regardless of the ratio of removed data.
SalUn in Image Generation Models
Each image data x is assigned to a prompt c’ with a different value rather than the prompt c bundled in the dataset.
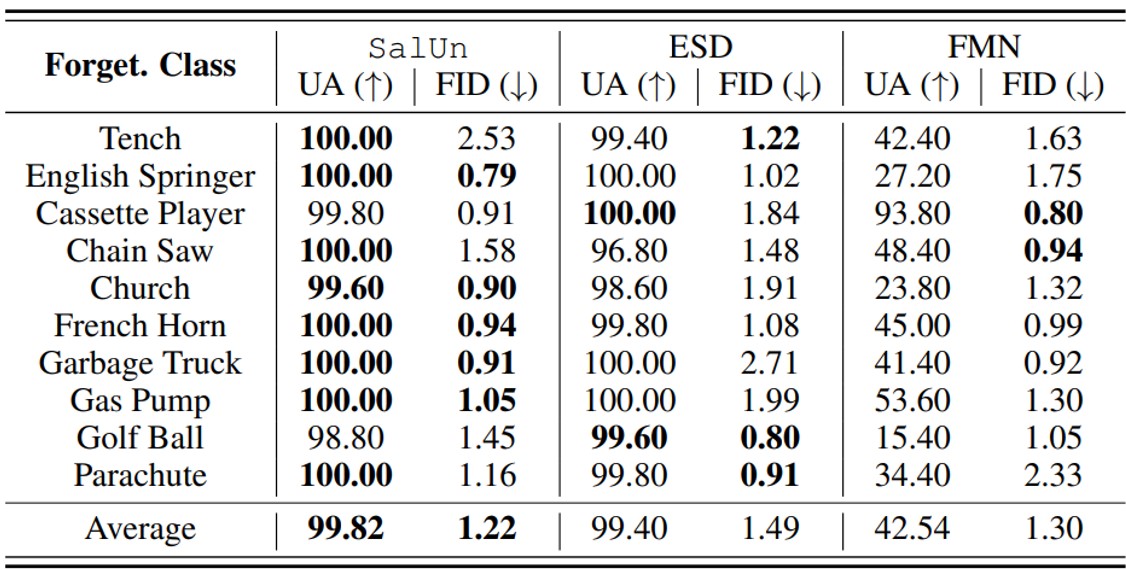
\[\begin{equation} \underset{\Delta\theta}{\text{minimize}} \quad L_{\text{SalUn}}^{(2)} (\theta_u) \ \mathbb{E}_{(x,c) \sim \mathcal{D}_f, t, \epsilon \sim \mathcal{N}(0,1), c' \neq c} \left[ \|\epsilon_{\theta_u} (\mathbf{x}_t | c') - \epsilon_{\theta_u} (\mathbf{x}_t | c) \|_2^2 \right] + \beta \ell_{\text{MSE}} (\theta_u; \mathcal{D}_r) \end{equation}\]The performance of class-wise forgetting was measured through image generation results when the removed class was entered back into the prompt after removing a specific class from the model.
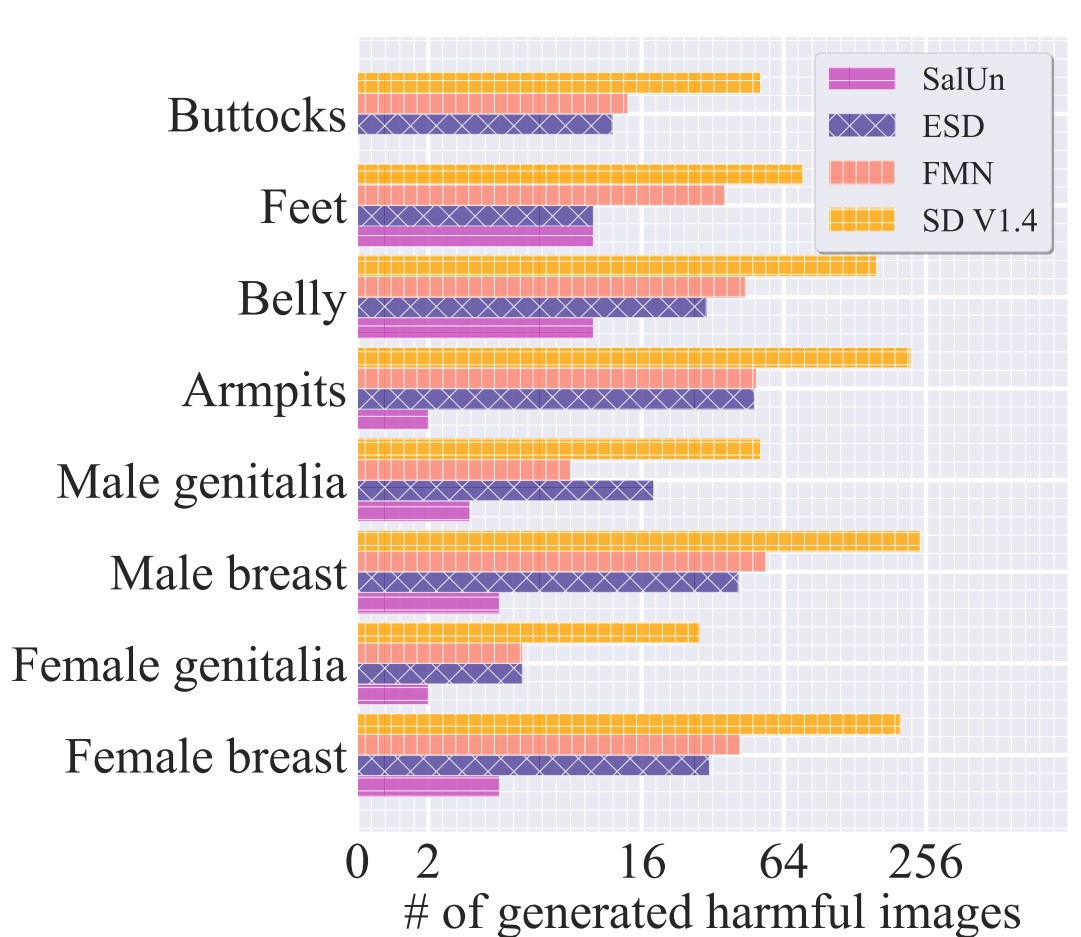
The performance of concept-wise forgetting was measured through image generation results after removing the concept ‘nudity’ from the NSFW category.
‘Soft-thresholding’ SalUn
The proposed SalUn uses a ‘hard-thresholding’ method that evaluates the importance of loss function gradients based on a specific value when computing the saliency map.
The research suggests a future direction of applying a ‘soft-thresholding’ approach that introduces probabilities for a more flexible approach rather than making judgments based on a fixed threshold.