Paper: Towards Unbounded Machine Unlearning
Authors: Meghdad Kuramanji, Peter Triantafillou, Jamie Hayes, Eleni Triantafillou
Venue: 37th Conference on Neural Information Processing Systems (NeurIPS 2023)
Introduction
Machine unlearning is a technique designed to protect privacy and remove data with various characteristics. As deep learning technology has recently been applied across diverse domains such as computer vision, healthcare, and natural language processing, the scope of GDPR’s “right to be forgotten” has been expanding. Unlearning is also used to remove data whose retention period has expired under data protection laws, outdated data to maintain model freshness, as well as critically biased data and noisy data that are detrimental to the model.
Before this paper was published, many studies did not consider various scenarios and the purpose of unlearning. Unlearning for privacy protection or for removing biased data prioritizes data removal, so achieving high forget quality is important even at the cost of sacrificing some model performance. In contrast, when deleting outdated data to maintain model freshness, preserving model utility is more important. Therefore, this paper argues that an unlearning algorithm capable of delivering consistent performance across all situations, considering various scenarios and purposes of unlearning, is needed.
Main Content
About SCRUB
SCRUB fundamentally takes the form of a teacher-student framework. The purpose of SCRUB is to perform unlearning effectively while maintaining model performance. SCRUB can be broadly divided into two processes.
The first process maximizes the forget-error, and the second process is the rewind stage that mitigates excessively high forget-error. Therefore, depending on the purpose of unlearning, users can decide whether to apply only the first process or both processes. For removing biased data or data with incorrectly assigned labels, SCRUB is trained through only the first process, while for privacy-protection unlearning, SCRUB is trained through both processes.
The reason why forget-error should not be too high for privacy protection is that it can become vulnerable to membership inference attacks. Similar to model overfitting, from an attacker’s perspective, an extremely high forget-error can make it possible to distinguish whether certain data is new data or data that previously existed in the model but was deleted.
SCRUB & Teacher-Student Model
The core idea of the teacher-student model in SCRUB is that the student model follows the teacher model for retain data, while the student model diverges from the teacher model for forget data.
\[\begin{equation} d(x; w_u) = D_{KL} \big( p(f(x; w_o)) \parallel p(f(x; w_u)) \big) \end{equation}\]The distance between the student model and the teacher model can be expressed through KL-Divergence as shown in the above equation. This equation measures the KL-Divergence between the output probability distributions of the teacher model and the student model, where the KL-Divergence value changes according to the student model’s weights while the teacher model’s weights remain constant. Therefore, for forget data, the student model’s weights are updated to maximize the KL-Divergence with the teacher model, and for retain data, the weights are updated to minimize the KL-Divergence with the teacher model.
SCRUB Training Process
Initially, the student model’s weights are initialized with the teacher model’s weights.
\[\begin{equation} \min_{w^u} -\frac{1}{N_f} \sum_{x_f \in D_f} d(x_f; w^u) \end{equation}\]Then, as shown in the above equation, the student model’s weights are updated to maximize the KL-Divergence between the student and teacher models for forget data. However, with only this equation, performance on retain data may decrease, so an additional process is needed to maintain model performance as follows.
\[\begin{equation} \min_{w_u} \frac{1}{N_r} \sum_{x_r \in D_r} d(x_r; w_u) + \lambda \frac{1}{N_r} \sum_{(x_r, y_r) \in D_r} l(f(x_r; w_u), y_r) - \alpha \frac{1}{N_f} \sum_{x_f \in D_f} d(x_f; w_u) \end{equation}\]This process adds the minimization of KL-Divergence between the teacher and student models for retain data and the minimization of the cross-entropy loss for retain data from the previous process, in order to maintain model performance.
However, this stage encounters a problem where the loss value oscillates significantly during training due to the conflicting nature of two different objectives. To solve this problem, this paper introduces an iterative alternative training approach. By alternately repeating a total of 3 steps, the previously encountered problem is resolved while maintaining model performance. The first step is expressed as max-step, performing updates on forget data; the second step is expressed as min-step, performing updates on retain data. Since the repetition of min-step and max-step may risk degrading performance on retain data, a third additional min-step is performed to recover performance on retain data.
SCRUB + Rewind
The reason an additional process called Rewind is needed is that excessively high unlearning performance on forget data can become vulnerable to membership inference attacks. Therefore, to achieve the goal of privacy protection, the forget error needs to be weakened through the rewind process. The core concept of Rewind is to maintain an appropriate level of unlearning performance.
Rewind refers to the method of setting a specific checkpoint that contains the error value for forget data, and when an error higher than the set error occurs, reverting to the previously set checkpoint. The process of Rewind is as follows.
First, validation data with the same distribution as the forget data is generated. For example, if all forget data belongs to class 0, the validation data must also all belong to class 0. After generating the validation data, training is conducted through SCRUB, and checkpoints containing the forget data error values are saved at each epoch. Then, the user sets an acceptable error value, and the error value is measured by inputting the validation data into the model at the checkpoint corresponding to that stage, setting this error value as the reference point, i.e., the threshold. If an error value higher than the reference point is measured during training, the final step is to rewind to the checkpoint closest to the reference point.
Experiment
Scenario & Setting
This paper evaluates SCRUB’s performance based on three scenarios. The first scenario targets the removal of biased data. This scenario aims to achieve the highest possible error on forget data. The second scenario targets the removal of data with incorrectly assigned labels. Like the first scenario, this also aims to achieve the highest possible error on forget data. The final scenario targets privacy protection, and unlike the previous two scenarios, aims to achieve a moderate level of error that is not vulnerable to membership inference attacks. In other words, the goal is to unlearn to the extent that an attacker cannot distinguish between examples belonging to forget data and entirely new data. Unlike previously published papers, this paper does not assume only small-scale settings but experiments with both small-scale and large-scale situations.
Results
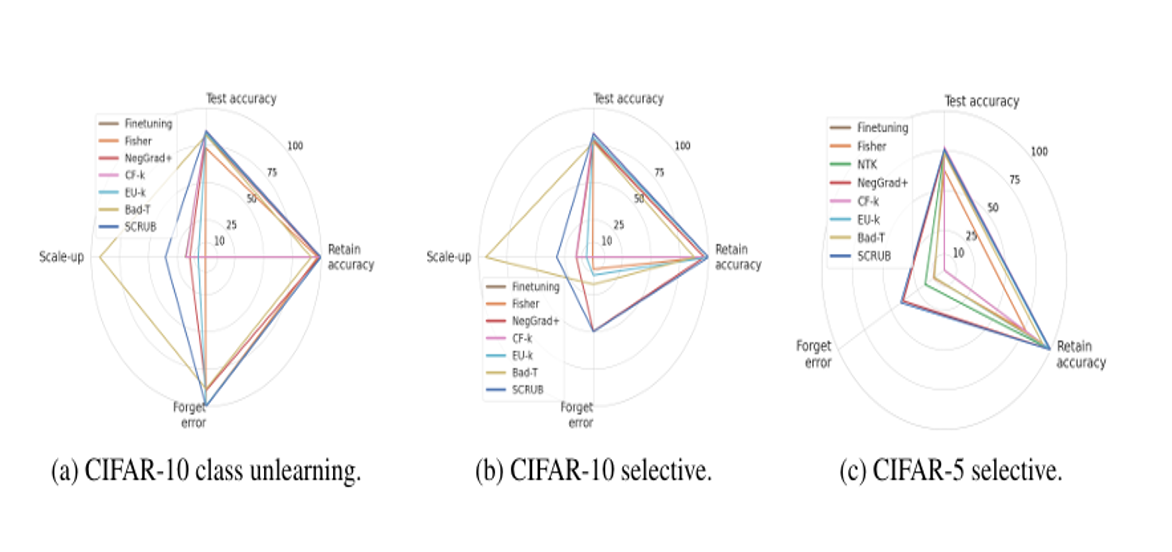
Through this graph, it can be confirmed that SCRUB best maintains model performance compared to other previously studied models in the scenario of removing biased data.
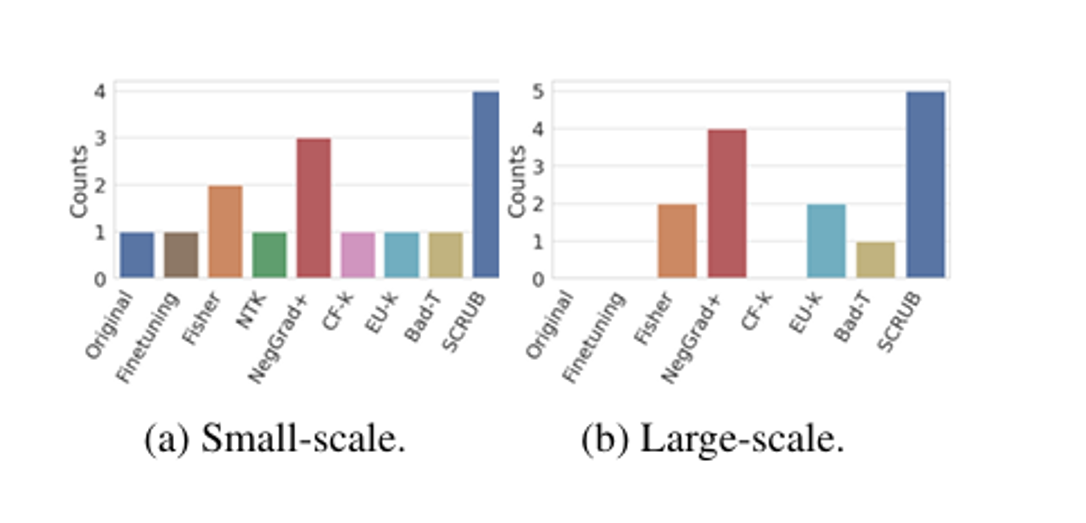
Additionally, through the following graph, SCRUB shows the highest forget quality across various situations and assumptions. Through both graphs, SCRUB demonstrates the best performance in terms of both model utility and unlearning. However, NegGrad+ also shows good performance, and since NegGrad+ requires less computational cost than SCRUB, a user decision on this matter would be necessary.
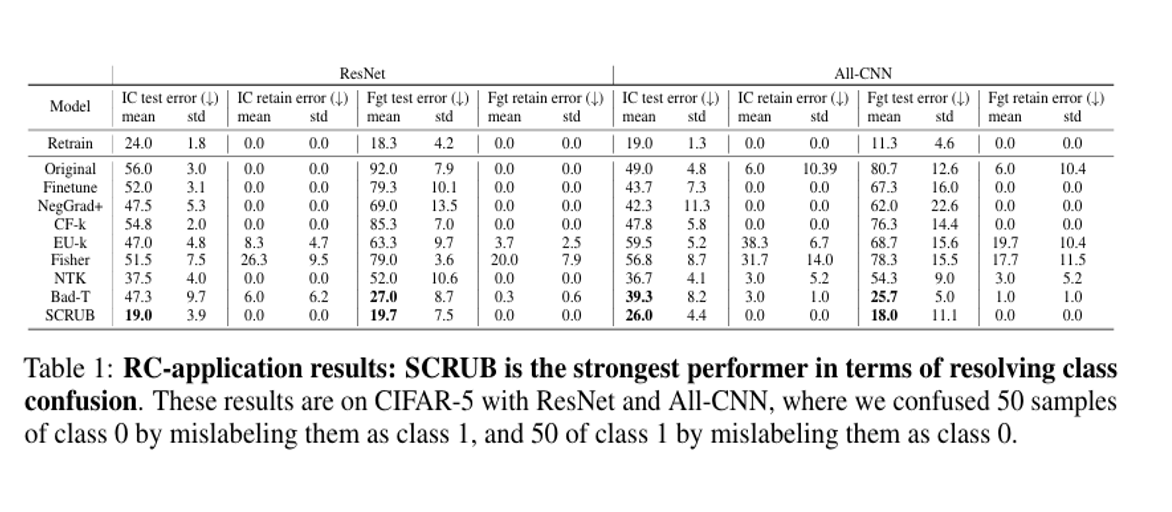
The following is an unlearning experiment by SCRUB on incorrect labels. The IC-ERR metric used in the experiment measures the number of times examples from two confused classes were misclassified as other classes, and the FGT-ERR metric measures the direct misclassification between two confused classes. Therefore, lower values for both indicate better model performance, and through this experiment, it can be seen that SCRUB best maintains model performance after unlearning data with incorrectly assigned labels.
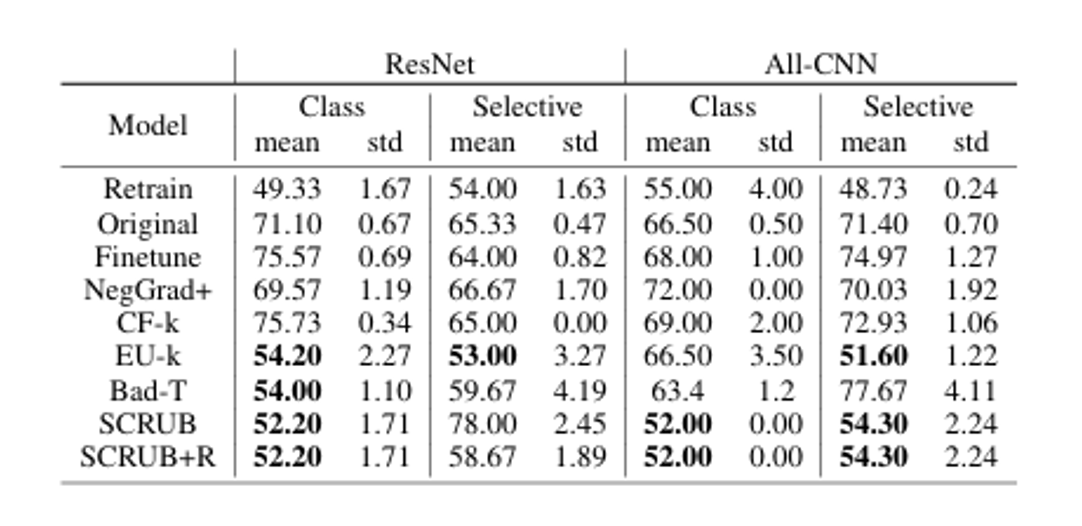
The following is an unlearning experiment by SCRUB for privacy protection. As shown in the table, SCRUB shows the most similar performance to retrain in terms of defense against membership inference attacks, and adding Rewind shows a significant difference in defense performance in selective unlearning. However, except for the selective unlearning case, Rewind does not show significant improvement in the remaining situations, so it is difficult to consider it advantageous in terms of computational cost.
Conclusion
This paper emphasizes that SCRUB can deliver consistent performance across various situations and unlearning purposes. Through the teacher-student framework, the difference between the two models is maximized for forget data and minimized for retain data, maintaining both model performance and forget quality at high levels. Additionally, since excessively high forget error becomes vulnerable to membership inference attacks from a privacy perspective, the rewind process is used to mitigate this. However, SCRUB has drawbacks in terms of high computational cost and many hyperparameters that must be determined by the user, and it should also be considered that NegGrad+, which shows similar performance with lower computational cost, may be more advantageous.