Paper: Stealing Hyperparameters in Machine Learning
Authors: Binghui Wang, Neil Zhenqiang Gong
Venue: Symposium on Security and Privacy SP, San Francisco, CA, 2018. IEEE.
Introduction
MLaaS (Machine Learning as a Service) is a service that provides machine learning model development, training, deployment, and management through cloud platforms. Thanks to MLaaS, businesses and individuals can easily utilize high-performance machine learning models at low cost. However, MLaaS models may be exposed to the risk of hyperparameter stealing.
Hyperparameters are key elements that determine model performance and adjust the learning direction across various algorithms. The process of learning hyperparameters involves high costs, and they are therefore considered trade secrets. However, during the process of users sharing training data and model parameters with MLaaS, malicious users can extract hyperparameters. This can lead to attempts to train high-performance models at low cost by bypassing the cost structure of MLaaS. Such attempts can undermine the commercial value of MLaaS, necessitating countermeasures.
Against this backdrop, this paper analyzes hyperparameter stealing attacks and proposes defense techniques. It also experiments with hyperparameter stealing attacks on various algorithms in real MLaaS platforms such as Amazon Machine Learning, and demonstrates their effectiveness. Furthermore, it presents the performance and limitations of a defense technique based on rounding model parameters.
Background
Hyperparameters vs. Model Parameters
Hyperparameters are variables that adjust the training process of machine learning models and directly affect model performance. In the formula below, the hyperparameter λ balances the loss function and the regularization term in the objective function L(w) to prevent overfitting.
\[\begin{align} \mathcal{L}(\mathbf{w}) = \mathcal{L}_{\text{loss}}(\mathbf{w}) + \lambda \mathcal{R}(\mathbf{w}) \end{align}\]Model parameters are the parameters actually learned in the process of minimizing the objective function. The representation of model parameters varies depending on the type of objective function.
Non-Kernel Algorithms vs. Kernel Algorithms
A non-kernel algorithm uses linear combinations of weights and data. When the objective function is a non-kernel algorithm, the model parameters are expressed as w. \(\begin{align} \mathcal{L}(\mathbf{w})=\mathcal{L}(X,y,\mathbf{w})+\lambda\,\mathcal{R}(\mathbf{w}) \end{align}\)
A kernel algorithm maps data to a nonlinear high-dimensional space. The objective function in this case is as follows: \(\begin{align} \mathcal{L}(\mathbf{w})=\mathcal{L}\bigl(\phi(X),y,\mathbf{w}\bigr)+\lambda\,\mathcal{R}(\mathbf{w}) \end{align}\)
As shown in the formula above, if the objective function is a kernel algorithm and includes norm regularization, the Representer theorem can be applied. According to the Representer theorem, the optimized model parameter w is expressed as a linear combination of the mapping results. Therefore, for kernel algorithms, the actual optimization target changes from w to α, and α is used as a model parameter equivalent to w.
\[\begin{align} \mathbf{w} = \sum_i \alpha_i \phi(x_i) \end{align}\]| Objective Function | Model Parameters | Examples |
|---|---|---|
| Non-kernel algorithm | \(\mathbf{w}\) | RR (Ridge Regression), LR (Logistic Regression), LASSO, SVM (Support Vector Machine) |
| Kernel algorithm | \(\mathbf{w},\ \boldsymbol{\alpha}\) | KLR (Kernel Logistic Regression), KSVM (Kernel Support Vector Machine) |
Analytical Solution vs. Approximate Solution
An analytical solution is an exact solution obtained by solving mathematically.
An approximate solution is a solution estimated through iterative optimization such as gradient descent.
An analytical solution does not require iterative trial and error but may be difficult to apply when computations are complex, while an approximate solution is practical but may involve error.
Threat Model
The target algorithms include linear regression, kernel regression, linear classification, kernel classification, and neural networks.
The attacker is assumed to know the training dataset, the training algorithm, and the model parameters. If the model parameters are unknown, it is assumed that the attacker uses model parameter stealing techniques proposed in prior research.
Estimating Hyperparameter λ
The attacker sets up a linear equation based on the condition that the gradient of the objective function equals zero, and computes the hyperparameter λ that satisfies this condition.
Non-kernel algorithm objective function
\[\begin{align} \frac{\partial \mathcal{L}_{\text{loss}}(X,\,y,\,\mathbf{w})}{\partial \mathbf{w}} \;+\; \lambda\,\frac{\partial \mathcal{R}(\mathbf{w})}{\partial \mathbf{w}} \;=\; 0 \end{align}\] \[\begin{align} \mathbf{b} \;=\; \begin{bmatrix} \dfrac{\partial \mathcal{L}(X,y,\mathbf{w})}{\partial w_1} \\ \dfrac{\partial \mathcal{L}(X,y,\mathbf{w})}{\partial w_2} \\ \vdots \\[2pt] \dfrac{\partial \mathcal{L}(X,y,\mathbf{w})}{\partial w_m} \end{bmatrix}, \qquad \mathbf{a} \;=\; \begin{bmatrix} \dfrac{\partial \mathcal{R}(\mathbf{w})}{\partial w_1} \\ \dfrac{\partial \mathcal{R}(\mathbf{w})}{\partial w_2} \\ \vdots \\[2pt] \dfrac{\partial \mathcal{R}(\mathbf{w})}{\partial w_m} \end{bmatrix} \end{align}\] \[\begin{align} \frac{\partial \mathcal{L}(\mathbf{w})}{\partial \mathbf{w}} \;=\; \mathbf{b} \;+\; \lambda\,\mathbf{a} \;=\; 0 \end{align}\]Kernel algorithm objective function
\[\begin{align} \frac{\partial \mathcal{L}_{\text{loss}}\bigl(\phi(\mathbf{X}),\,y,\,\mathbf{w}\bigr)} {\partial \boldsymbol{\alpha}} \;+\; \lambda\, \frac{\partial \mathcal{R}(\mathbf{w})} {\partial \boldsymbol{\alpha}} \;=\; 0 \end{align}\] \[\mathbf{b} \;=\; \begin{bmatrix} \dfrac{\partial \mathcal{L}\bigl(\phi(X),y,\mathbf{w}\bigr)}{\partial \alpha_1} \\ \dfrac{\partial \mathcal{L}\bigl(\phi(X),y,\mathbf{w}\bigr)}{\partial \alpha_2} \\ \vdots \\[2pt] \dfrac{\partial \mathcal{L}\bigl(\phi(X),y,\mathbf{w}\bigr)}{\partial \alpha_n} \end{bmatrix}, \qquad \mathbf{a} \;=\; \begin{bmatrix} \dfrac{\partial \mathcal{R}(\mathbf{w})}{\partial \alpha_1} \\ \dfrac{\partial \mathcal{R}(\mathbf{w})}{\partial \alpha_2} \\ \vdots \\[2pt] \dfrac{\partial \mathcal{R}(\mathbf{w})}{\partial \alpha_n} \end{bmatrix}\] \[\begin{align} \frac{\partial \mathcal{L}(\boldsymbol{\alpha})}{\partial \boldsymbol{\alpha}} \;=\; \mathbf{b} \;+\; \lambda\,\mathbf{a} \;=\; 0 \end{align}\]If the number of linear equations exceeds the number of λ values (over-determined), it is difficult to compute the exact λ. In such cases, the least-squares solution is used to compute the estimate of the closest approximation: \(\begin{align} \hat{\lambda} \;=\; -\,(\mathbf{a}^\top \mathbf{a})^{-1}\,\mathbf{a}^\top \mathbf{b} \end{align}\) The relative estimation error is used as a metric to evaluate the attacker’s hyperparameter estimation performance. The smaller the relative estimation error, the closer it is to the actual model performance, meaning higher attack performance.
| Symbol | Meaning |
|---|---|
| \(\lambda\) | Actual hyperparameter |
| \(\hat{\lambda}\) | Attacker’s estimated hyperparameter |
| \(\Delta\hat{\lambda}\) | \(\hat{\lambda}-\lambda\) |
| \(\mathbf{w},\ \boldsymbol{\alpha}\) | Actually trained / stolen model parameters |
| \(\boldsymbol{\mathbf{w}}^{\star},\ \boldsymbol{\alpha}^{\star}\) | Parameters corresponding to the exact minimum when the objective function is theoretically minimized |
| \(\Delta\mathbf{w},\ \Delta\boldsymbol{\alpha}\) | \(\mathbf{w}-\mathbf{w}^{\star},\ \boldsymbol{\alpha}-\boldsymbol{\alpha}^{\star}\) |
| \(\epsilon\) | \(\frac{\lvert \hat{\lambda}-\lambda \rvert}{\lambda}\) |
\(\begin{align} Relative \ estimation \ error: \epsilon \;=\; \frac{\lvert \hat{\lambda}-\lambda \rvert}{\lambda} \end{align}\) When the trained model parameters are close to the actual minimum of the objective function, the following upper bound holds for the hyperparameter estimation error. This means the estimation error remains within a predictable range: \(\begin{align} \Delta\hat{\lambda} &= \hat{\lambda}-\lambda = \Delta\mathbf{w}^{\top}\, \nabla\hat{\lambda}\!\bigl(\mathbf{w}^{\star}\bigr) + O\!\bigl(\Delta\mathbf{w}\rVert_{2}^{2}\bigr) &\quad (\Delta\mathbf{w}\to 0) \\[4pt] \end{align}\)
\(\begin{align} \Delta\hat{\lambda} &= \hat{\lambda}-\lambda = \Delta\boldsymbol{\alpha}^{\top}\, \nabla\hat{\lambda}\!\bigl(\boldsymbol{\alpha}^{\star}\bigr) + O\!\bigl(\Delta\boldsymbol{\alpha}\rVert_{2}^{2}\bigr) &\quad (\Delta\boldsymbol{\alpha}\to 0) \end{align}\)
Hyperparameter Stealing in MLaaS
Machine learning fundamentally follows the process below.
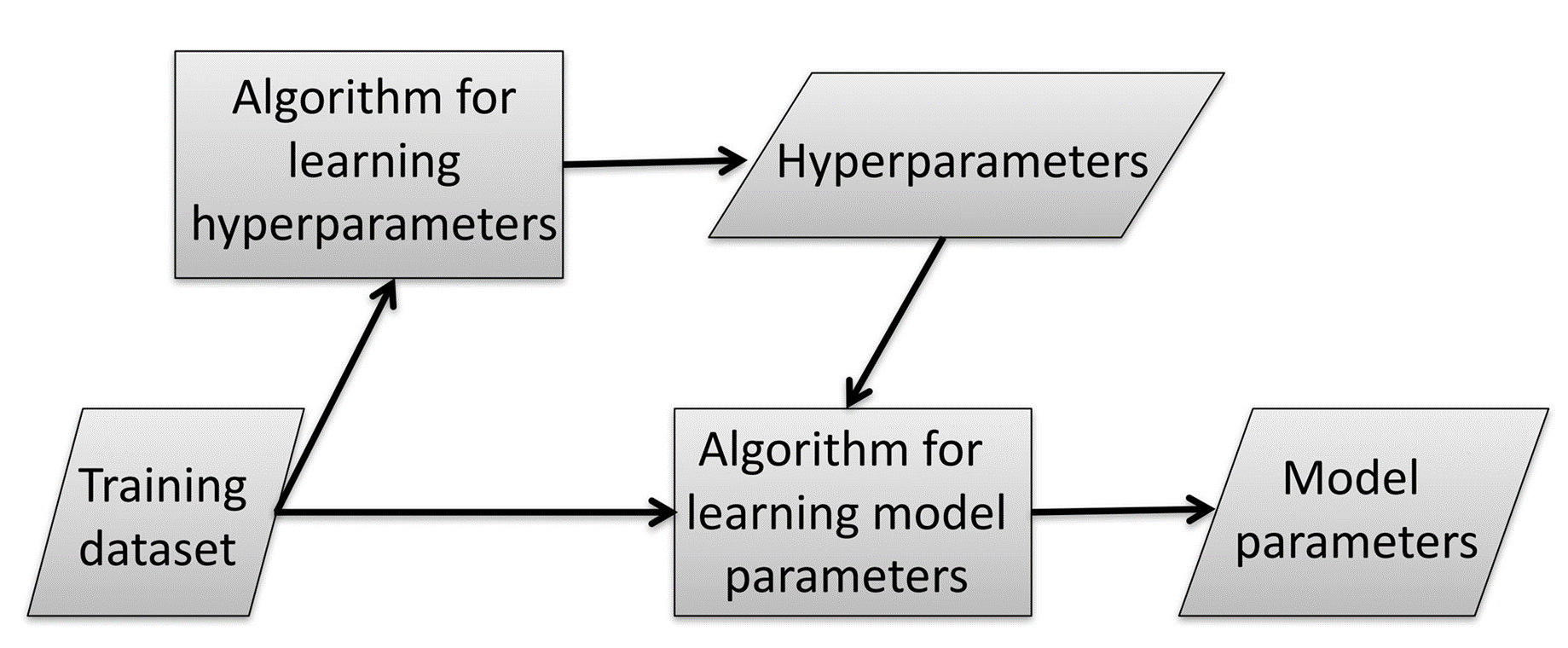
The attacker exploits two protocols within this process to steal hyperparameters.
Protocol 1: The user uploads the entire training dataset and training algorithm to the MLaaS platform, and MLaaS trains the hyperparameters and model parameters, then returns the model parameters.
Protocol 2: The user uploads the entire training dataset, training algorithm, and hyperparameters to the MLaaS platform, and MLaaS trains the model parameters.
The attacker exploits these protocols as follows. First, the attacker applies only a portion of the training dataset to Protocol 1 to obtain model parameters, then estimates the hyperparameters trained by MLaaS. Next, the attacker applies the full dataset and estimated hyperparameters to Protocol 2 to train a high-performance model at low cost. In this process, the attacker can bypass the expensive hyperparameter learning step.
This paper refers to this process as the Train-Steal-Retrain strategy, describing it as a method that exploits the cost structure of MLaaS platforms.
Defense Method
The defense technique against hyperparameter stealing in MLaaS proposed in this paper is as follows.
When MLaaS returns the model parameters trained in Protocol 1 to the user, it provides rounded values. This method effectively degrades the stealing performance by increasing the attacker’s hyperparameter estimation error.
Experiment
The following experiments estimate the hyperparameters of various objective functions and analyze the relative estimation error compared to the actual hyperparameters.
Additionally, the hyperparameter estimation performance is evaluated on real MLaaS platforms.
Finally, the performance and limitations of the rounding-based defense are examined.
Training Datasets
| Name | Samples | Dimensions | Type | Description |
|---|---|---|---|---|
| Diabetes | 442 | 10 | Regression | Disease progression prediction |
| GeoOrig | 1059 | 68 | Regression | Geographic variable prediction |
| UJIIndoor | 19937 | 529 | Regression | Indoor location prediction |
| Iris | 100 | 4 | Classification | Iris classification |
| Madelon | 4400 | 500 | Classification | Binary classification |
| Bank | 45210 | 16 | Classification | Term deposit subscription prediction |
Experimental Results
Regression
| Objective Function | Loss Function | Regularization |
|---|---|---|
| RR | Least square | L2 |
| LASSO | Least square | L1 |
| KRR | Least square | L2 |
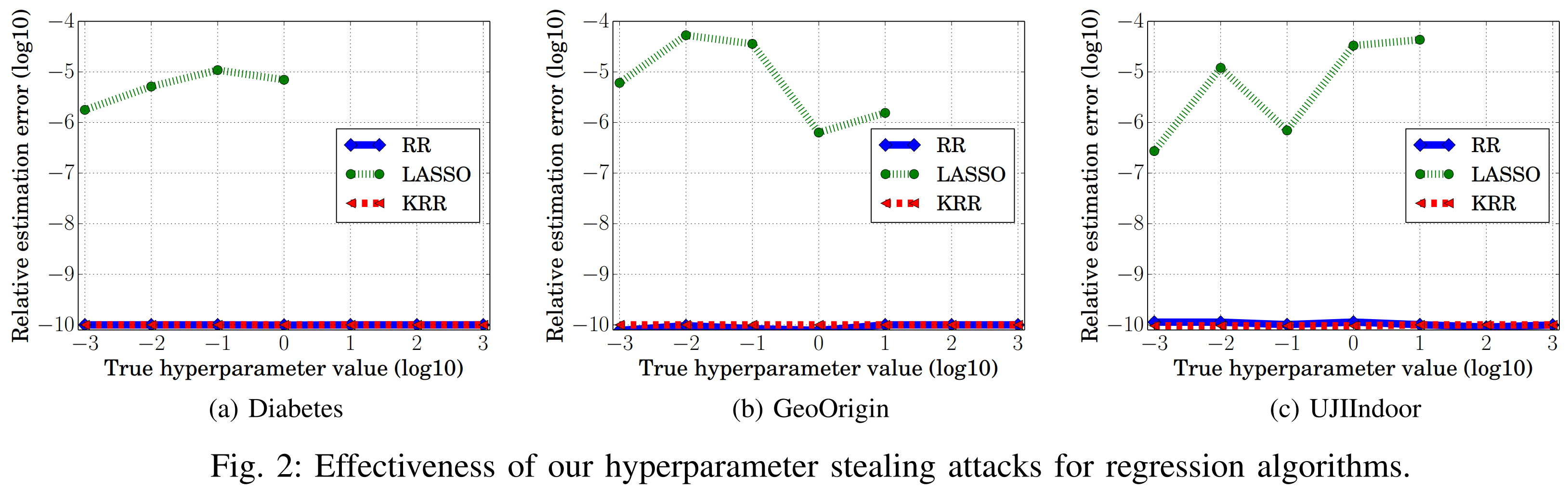
Looking at the graph above, the relative estimation error is very small when the objective function is RR or KRR. This is because the model parameters learned by these two objective functions follow analytical solutions. As a result, the model parameters w and α of RR and KRR match the exact minimum of the objective function. In other words, since ∆w, ∆α = 0, the hyperparameter estimation error becomes 0, achieving perfect hyperparameter stealing.
In contrast, other objective functions do not have analytical solutions for model parameters, so ∆w or ∆α are likely non-zero. These objective functions show relatively larger relative estimation errors.
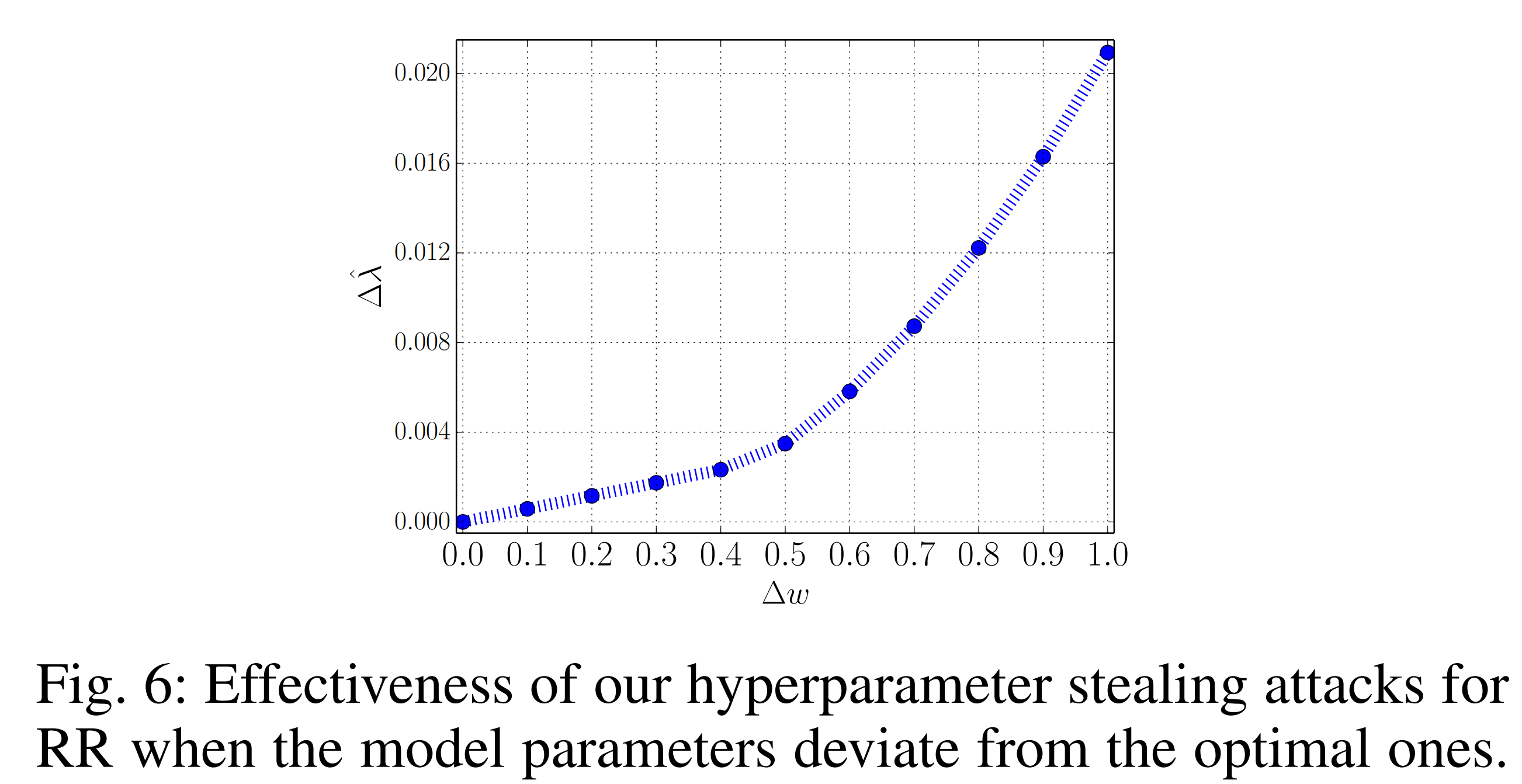
The graph below shows the results when RR’s model parameters follow approximate solutions. Analyzing the change in hyperparameter estimation error with respect to ∆w, when ∆w is small, a linear increase is observed, but beyond that, a nonlinear increase pattern appears. This is naturally explained by the fact that the hyperparameter estimation error consists of a sum of linear and nonlinear terms.
Logistic Regression
| Objective Function | Loss Function | Regularization |
|---|---|---|
| L2-LR | Cross Entropy | L2 |
| L1-LR | Cross Entropy | L1 |
| L2-KLR | Cross Entropy | L2 |
| L1-KLR | Cross Entropy | L1 |
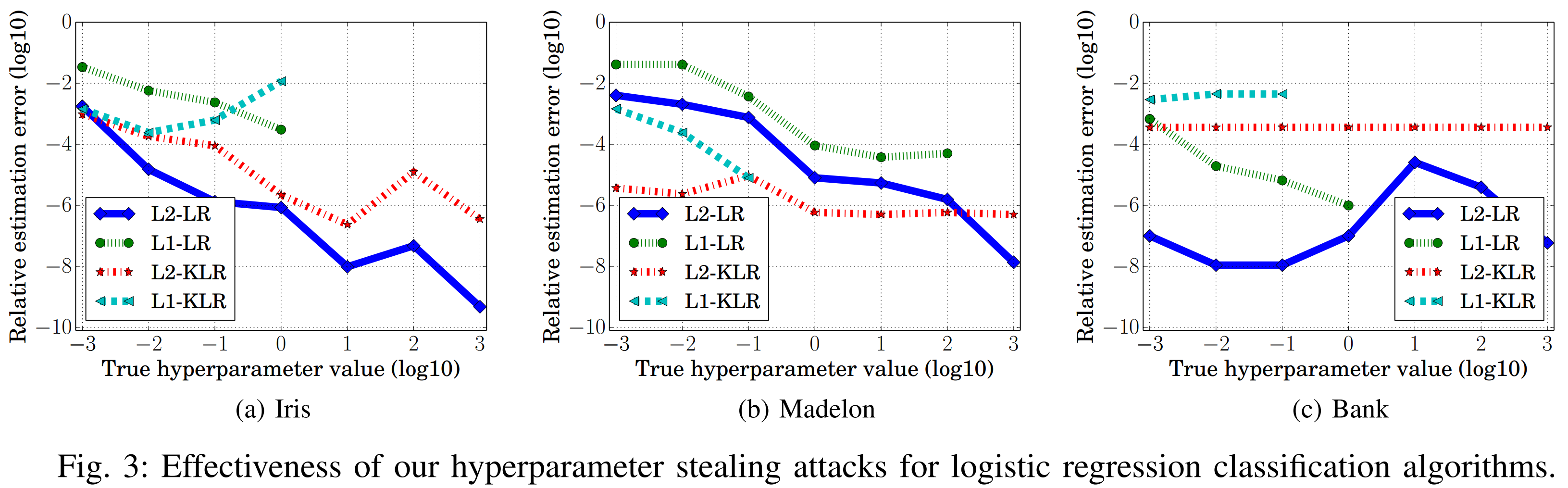
Looking at the graph above, when the objective function uses L2 regularization, the relative estimation error is comparatively smaller than with L1 regularization. The derivative of L2 regularization is 2w, which continuously adjusts learning so that the objective function stably approaches the minimum. This contributes to reducing the relative estimation error and consequently increases the performance of hyperparameter stealing attacks.
In contrast, the derivative of L1 regularization, sign(w), adjusts learning discontinuously, making the relative estimation error likely to be larger, and consequently lowering the attack performance.
MLaaS Experimental Results
This study sets up three methods (M1, M2, M3) targeting the MLaaS platform and compares the results of training with each method.
M1: Run Protocol 1
M2: Run Protocol 1 with only a portion of the training dataset
M3: Run Protocol 1 with only a portion of the training dataset → Estimate hyperparameters → Run Protocol 2
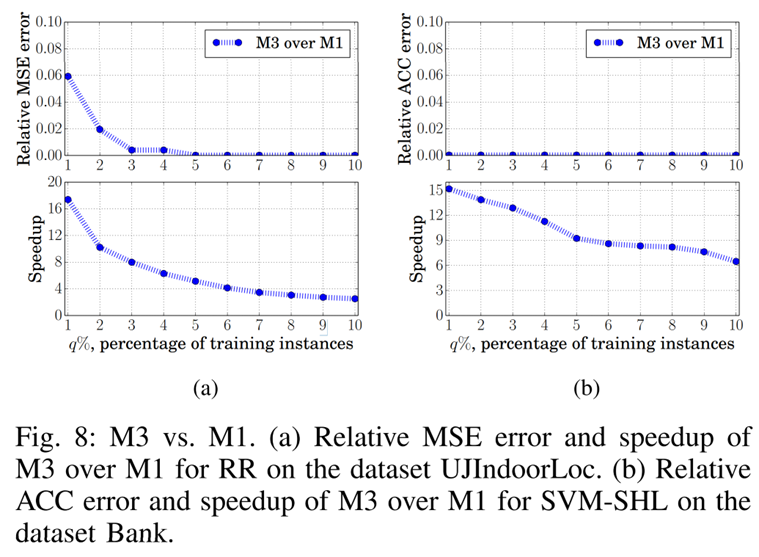
Looking at the graph above, the Relative MSE error and Relative ACC error between M3 and M1 are very small. This can be interpreted as M1’s performance being similar to M3’s performance with stolen hyperparameters.
In terms of speed, M3 even shows better performance than M1.
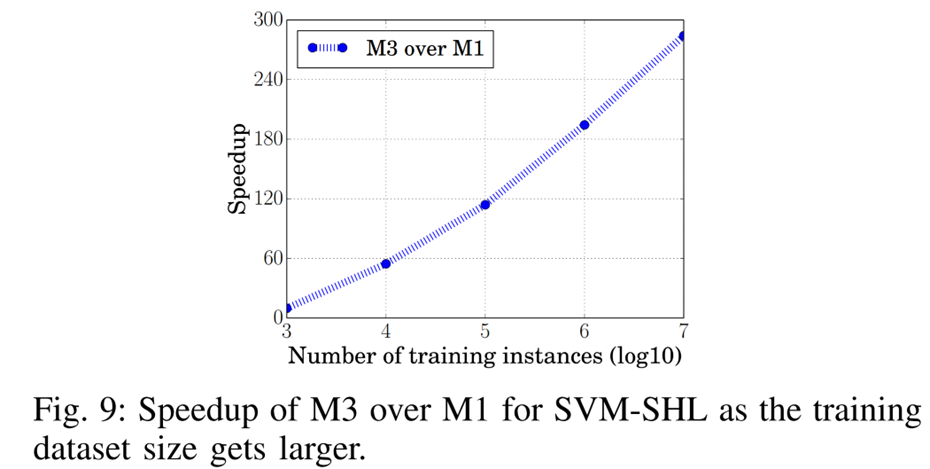
The graph above shows that M3’s training speed increases as the training dataset size grows.
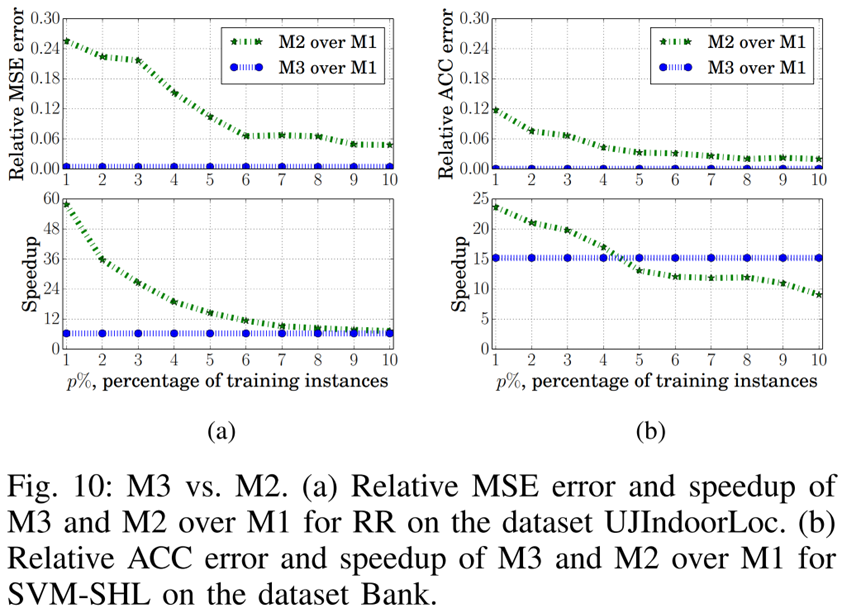
The graph above reveals the following. Both M3 and M2 use only a portion of the training dataset in Protocol 1, but M3 achieves higher performance than M2 even when the data ratio is reduced.
Defense Experiments Against Hyperparameter Stealing Attacks
Evaluation Metrics
If the following metrics are high, the rounding-based defense can be considered effective. \(\begin{align} Relative \ estimation \ error: \dfrac{|\hat{\lambda}_{\text{after Rounding}} -\lambda_{\text{before Rounding}}|}{\lambda_{\text{before Rounding}}} \end{align}\)
\[\begin{align} Relative \ MSE \ error: \dfrac{|\text{MSE}_{\text{after Rounding}} -\text{MSE}_{\text{before Rounding}}|}{\text{MSE}_{\text{before Rounding}}} \end{align}\] \[\begin{align} Relative \ ACC \ error: \dfrac{|\text{ACC}_{\text{after Rounding}} -\text{ACC}_{\text{before Rounding}}|}{\text{ACC}_{\text{before Rounding}}} \end{align}\]Experimental Results
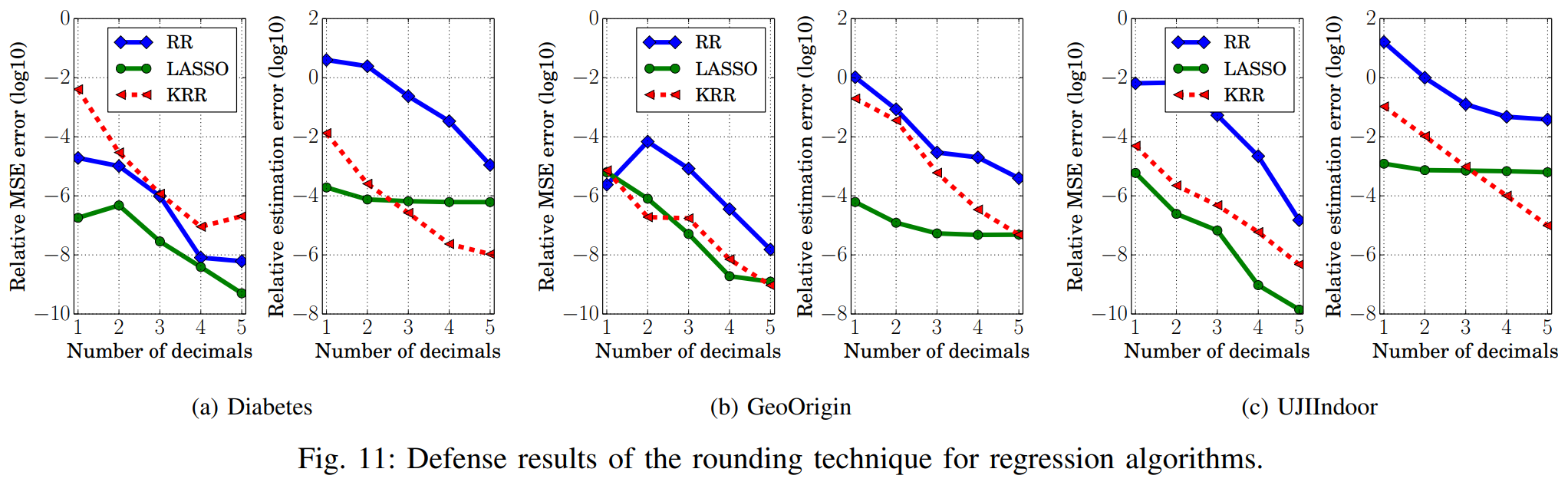
Looking at the graph above, most objective functions show high relative estimation error after rounding, but LASSO still shows low relative estimation error even after rounding is applied. This shows that the rounding defense cannot protect against hyperparameter stealing attacks on LASSO.
Furthermore, as the number of decimals in the rounded model parameters increases, the rounding defense performance tends to weaken. Therefore, results at low decimal places can be considered meaningful for analysis.
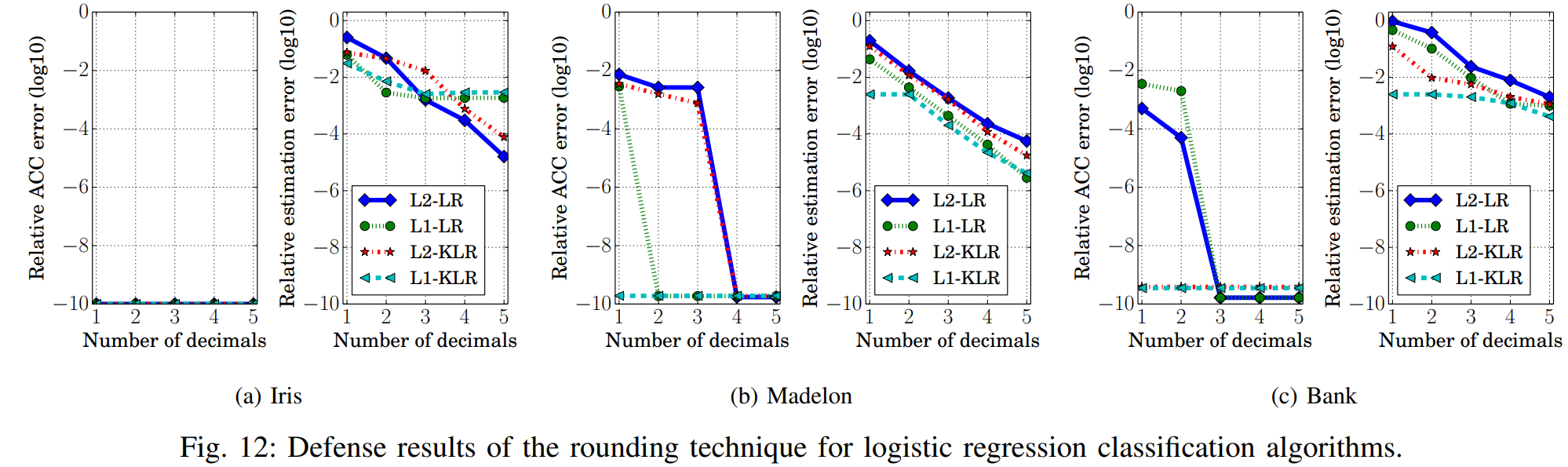
Looking at the graph above, when the number of decimal places is low, objective functions using L2 regularization show higher evaluation metrics than those using L1 regularization. This means that defense performance against hyperparameter stealing attacks is better when using L2 regularization. Unlike L1 regularization, L2 regularization has a continuous derivative, so changes due to rounding are directly reflected. As a result, the hyperparameter relative estimation error increases more effectively, better reducing the likelihood of successful stealing attacks.
MLaaS Experimental Results
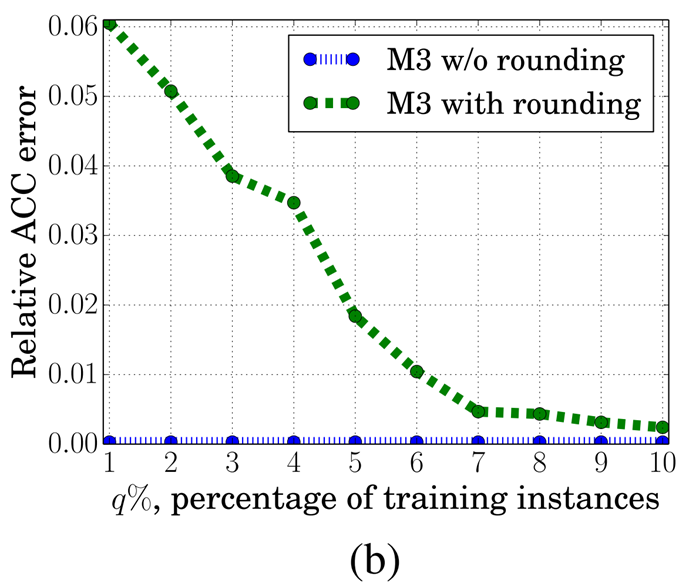
The graph below shows the results comparing the M3 method with and without rounding in MLaaS. When rounding defense is applied, the evaluation metrics tend to be higher, demonstrating that the rounding defense is also effective in MLaaS environments.
Conclusion
This study confirmed through experiments that hyperparameter stealing attacks can reduce training costs while maintaining model performance in MLaaS environments. The rounding defense technique effectively increases estimation errors in algorithms using L2 regularization, reducing the likelihood of successful attacks. However, in some algorithms, estimation errors remained small, revealing the need for new countermeasures.
Therefore, future research on stealing attacks for various hyperparameter types and defenses against them will be necessary.