Paper: Stealing Machine Learning Models via Prediction APIs
Authors: Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
Venue: USENIX Security Symposium, Austin, TX, USA, 2016.
Introduction
With the rise of Machine Learning as a Service (MLaaS), machine learning models that were previously protected internally can now interact with the outside world through APIs. As new revenue models have emerged where model owners provide paid query access to other users, a new threat called model extraction has surfaced.
An attacker can extract a machine learning model through queries to the model, as shown in the following structure:
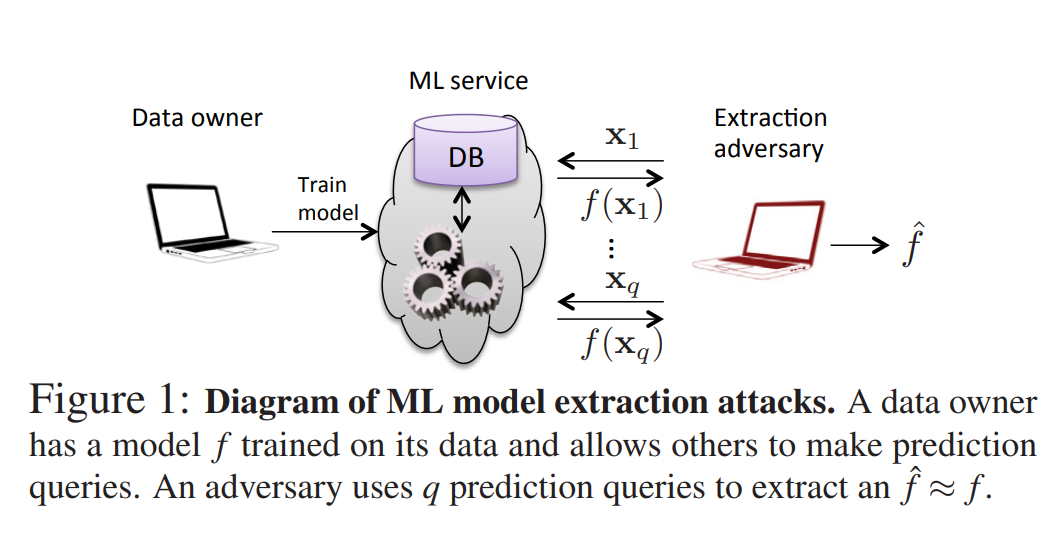
This paper proposes model extraction attack techniques for various model types, and examines whether such attacks are applicable to real-world services along with potential countermeasures.
The paper demonstrates model extraction attacks across various model environments including decision trees, logistic regression, deep neural networks, and SVMs (Support Vector Machines), as well as against MLaaS providers such as Amazon and BigML. In most cases, it was possible to generate models that are functionally similar to the target model.
Background
In this paper, when comparing class probabilities for an input, the total variation distance is used:
\[\begin{align} d(y,y') = \frac1 2 \sum\vert y[i]-y'[i]\vert \end{align}\]The evaluation metrics for the experiments are defined as follows:
\[\begin{align} R_{\text{test}}(f, \hat{f}) = \frac{1}{|D|} \sum_{(x, y) \in D} d(f(x), \hat{f}(x)), \quad \text{where } D \text{ is the test set}.\\ R_{\text{unif}}(f, \hat{f}) = \frac{1}{|U|} \sum_{x \in U} d(f(x), \hat{f}(x)), \quad \text{where } U \text{ is a set of uniformly sampled inputs from } \mathcal{X}. \end{align}\]Each metric evaluates the agreement on test data and the accuracy over the entire input space between the target model and the extracted model.
The sigmoid and softmax functions used in models are defined as follows:
\[\begin{align} \sigma(t) = \frac1 {1+e^t}\quad softmax(z_i)=\frac{e^{z_i}} {\sum_j e^{z_i}} \end{align}\]One-vs-Rest (OvR) is a strategy used in multiclass classification problems that combines multiple binary classifiers. OvR is distinguished from softmax-based models in multiclass classification.
In the OvR approach, given a total of c classes, a binary classification problem is defined for each class:
- This class vs. all other classes i.e., for class 3, a binary classifier is trained to determine “Is this sample class 3 or not?”
A total of c binary classifiers are trained, and at prediction time, the class with the highest output value among all classifiers is selected as the final prediction.
The shapes of the nonlinear activation functions ReLU (Rectified Linear Unit) and tanh (hyperbolic tangent) are as follows:
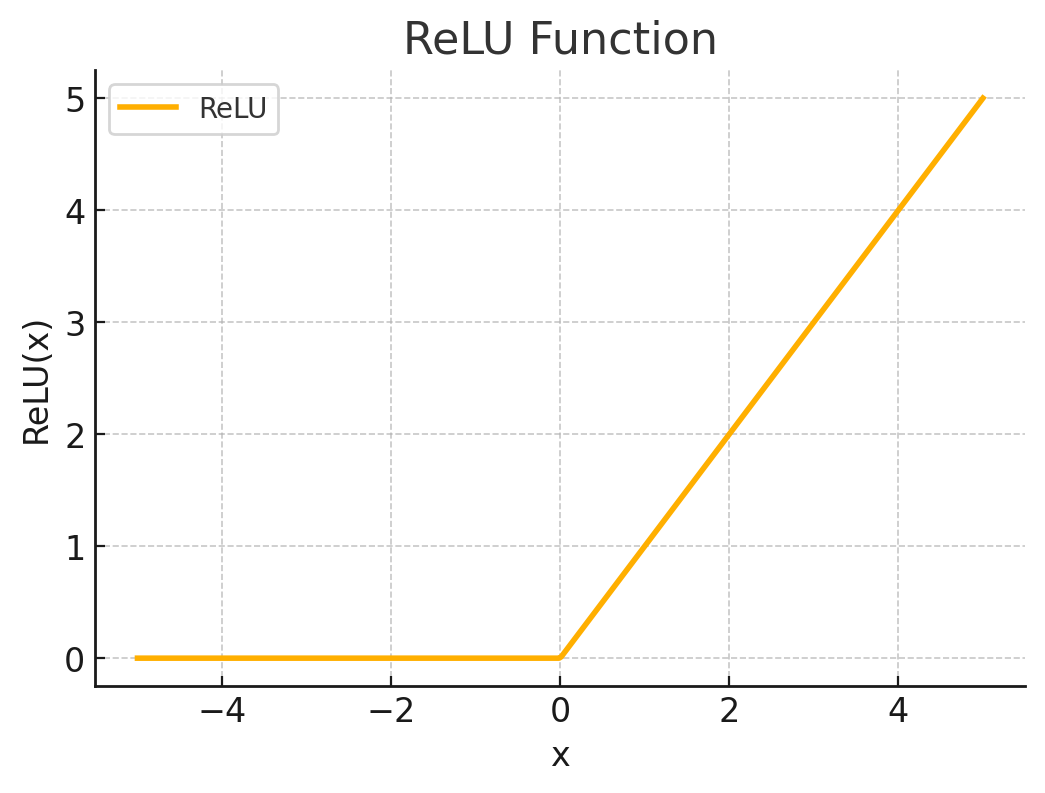
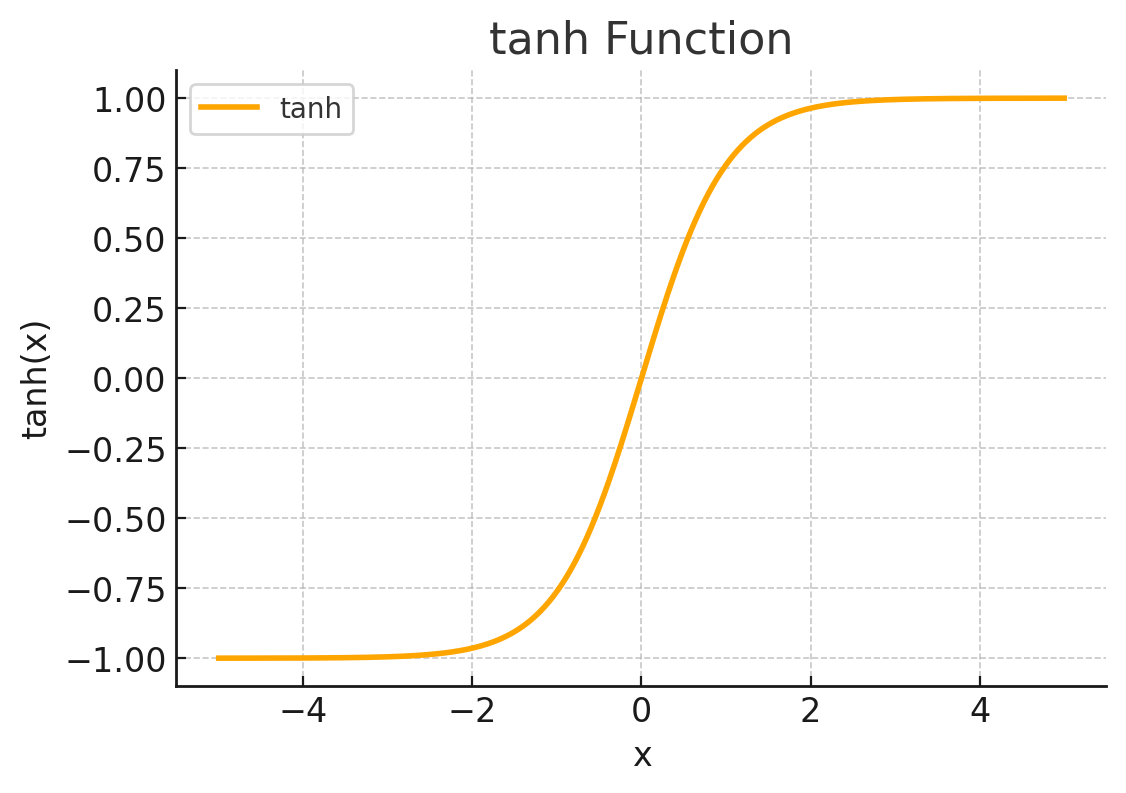
Main Content
Equation Solving Attack
The Equation Solving Attack is a model extraction technique that attempts to directly compute internal parameters such as weights and biases of the target model by leveraging its output probability values. This approach can be applied to binary logistic regression models, multiclass logistic regression models, and multi-layer perceptron models.
-
Binary Logistic Regression (BLR) Model
A BLR model is generally defined as follows:
\[\begin{align} f(x) = \sigma(w^\top x + \beta), \quad w \in \mathbb{R}^d,\ x \in \mathbb{R}^d,\ \beta \in \mathbb{R} \end{align}\]From the output values, the following equation can be derived:
\[\begin{align} \sum_{j=1}^{d} w_j x_j + \beta = \sigma^{-1}(f(x)) = \log\left( \frac{f(x)}{1 - f(x)} \right) \end{align}\]To recover the weights and bias from this equation, the following conditions are required:
\[\begin{align} \text{Unknowns: } w \in \mathbb{R}^d,\ \beta \in \mathbb{R} \Rightarrow (d + 1)\ \text{unknowns} \end{align}\] \[\begin{align} \text{Need } (d + 1)\ \text{linearly independent inputs } x_{(1)},\dots,x_{(d+1)} \end{align}\]From each sample x_i, the following linear equation is obtained:
\[\begin{align} \sum_{j=1}^{d} w_j x^{(i)}_j + \beta = \log\left( \frac{f(x^{(i)})}{1 - f(x^{(i)})} \right) \end{align}\]Solving the system of d+1 equations simultaneously as shown below allows for exact recovery of the weights and bias:
\[\begin{align} \sum_{j=1}^{d} w_j x^{(1)}_j + \beta = \log\left( \frac{f(x^{(1)})}{1 - f(x^{(1)})} \right) \\\\ \sum_{j=1}^{d} w_j x^{(2)}_j + \beta = \log\left( \frac{f(x^{(2)})}{1 - f(x^{(2)})} \right) \\\\ \vdots \\\\ \sum_{j=1}^{d} w_j x^{(d+1)}_j + \beta = \log\left( \frac{f(x^{(d+1)})}{1 - f(x^{(d+1)})} \right) \end{align}\] -
Multiclass Logistic Regression (MLR) Model
- An MLR model is generally defined as follows:
Since the MLR model uses the softmax function, it forms a nonlinear equation system. Therefore, it is not possible to analytically solve for the weights and biases as in the BLR model.
For such nonlinear equation systems, an extracted model that makes predictions similar to the target model f can be constructed by minimizing a loss function. The Cross-Entropy Loss function commonly used in multiclass classification models is as follows:
\[\begin{align} \mathcal{L}(W, \beta) = - \sum_{k=1}^{n} \sum_{i=1}^{c} f_i(x^{(k)}) \cdot \log \hat{f}_i(x^{(k)}) \end{align}\]By adding a regularization term (e.g., L2), the overall loss function becomes strongly convex, ensuring a global minimum.
In this case, the extracted model can produce the same output (softmax probabilities) as the target model for all possible input samples, but internally it does not guarantee that the parameters are exactly the same as those of the target model. It can thus be considered a functionally equivalent approximate model.
-
Multi-Layer Perceptron (MLP) Model
Unlike the previous models, the MLP model includes hidden layers and applies nonlinear activation functions (such as ReLU, tanh, etc.). Therefore, the model is relatively complex with many parameters, and since it is a nonlinear model, adding a regularization term cannot guarantee that the loss function is strongly convex.
The Equation Solving Attack on MLP models can be conducted in the same manner as for MLR, but requires more queries. Furthermore, it cannot be guaranteed that the extracted model will behave identically.
- Experimental Results
The table below shows the results of the equation solving attack from the paper:
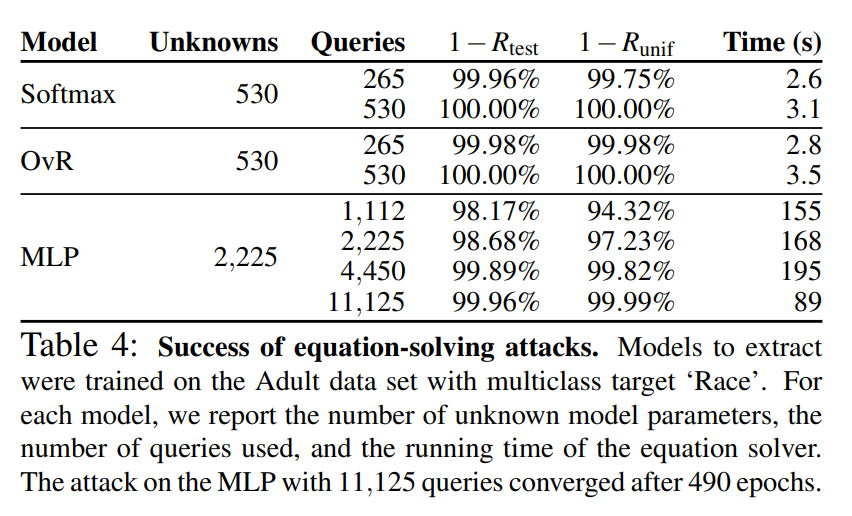
The training data used was adult data categorized by race.
The MLR model used the softmax model and OvR model mainly discussed in the paper. For models with 530 parameters, nearly identical models were successfully extracted with 265 queries, and functionally identical models could be extracted with 530 queries.
The MLP model had more parameters and required more queries and time, but nearly identical models could still be extracted.
Decision Tree Path Finding Attack
The Decision Tree Path Finding Attack is a model extraction technique that reconstructs the entire tree by backtracking paths of a decision tree that provides prediction results based on branch conditions.
A decision tree branches at each internal node based on a threshold for a specific feature x. A simple branching criterion example is as follows:
\[\begin{align} x_i<θ \text{ ⇒left child node,}\quad x_i≥θ \text{ ⇒right child node} \end{align}\]The diagram below shows a simple decision tree example:
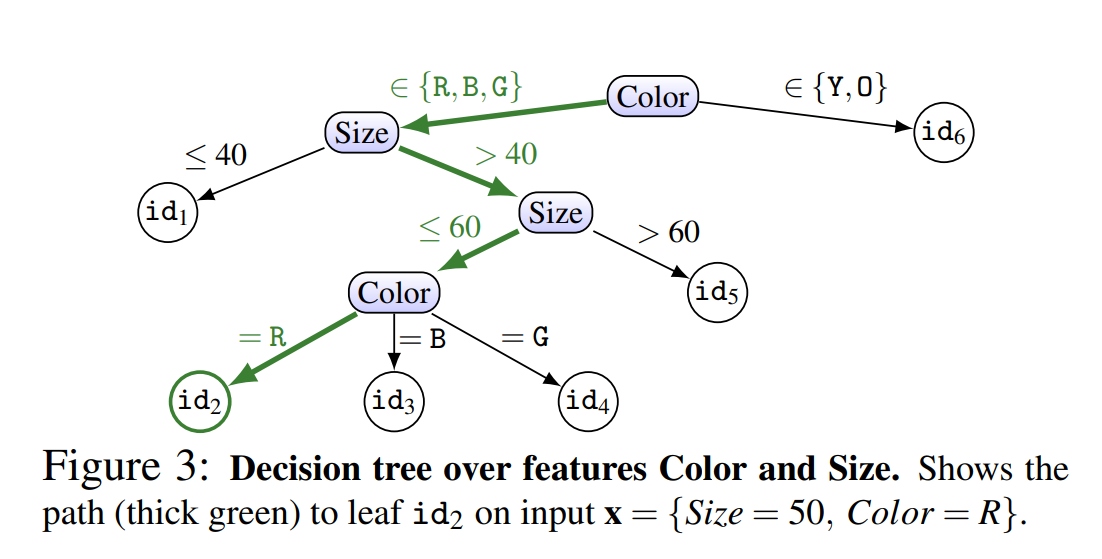
The paper proposes two approaches based on a path-finding algorithm: path-finding and a top-down approach.
-
Path Finding: The goal of path finding is to identify the input conditions that reach each leaf node.
- One feature of input x is varied while exploring changes in the model’s output.
- Split conditions are estimated based on points where the output changes.
The algorithm underlying this technique is as follows:

The above algorithm reconstructs the tree by exploring the branching conditions for each feature of the input.
-
A top-down approach: In the top-down approach, the depth and number of branches of the tree are explored to identify all paths.
- An empty input with all features unspecified is queried to identify the root node’s ID.
- Next, inputs with only one feature set at a time are created to identify which feature affects the root.
- For features that serve as branching criteria, boundary values are searched to estimate the node’s branching conditions.
- The process is recursively repeated for child nodes to reconstruct the tree.
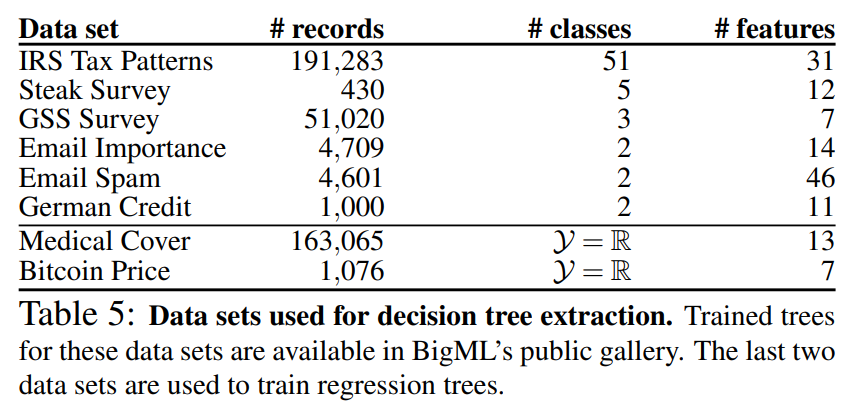
Below is the training data for the decision trees used in the experiments. This data is available from BigML, with the number of rows, classes, and features for each dataset specified:
The table below shows the results of the decision tree model extraction attack from the paper:
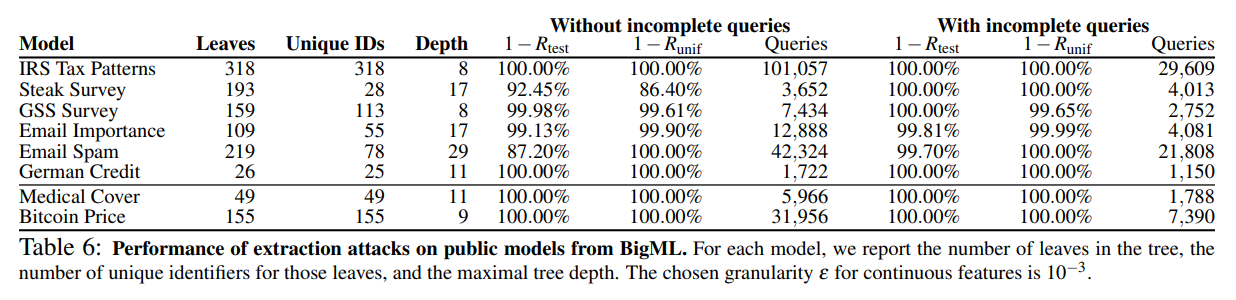
As a result of the attack, the top-down approach with incomplete queries generally achieved fewer queries and higher accuracy.
The Lowd-Meek attack
The Lowd-Meek attack proposed in Lowd, Meek. 2005 is a boundary-based model extraction technique designed to extract models in environments where only class labels are provided.
The model separates two classes based on a decision boundary. For any pair of arbitrary points (x1, x2) with different output classes, the attacker narrows down the boundary point through binary search to estimate the decision boundary. The collected data is then used to reconstruct the model’s parameters.
A simple example is as follows:
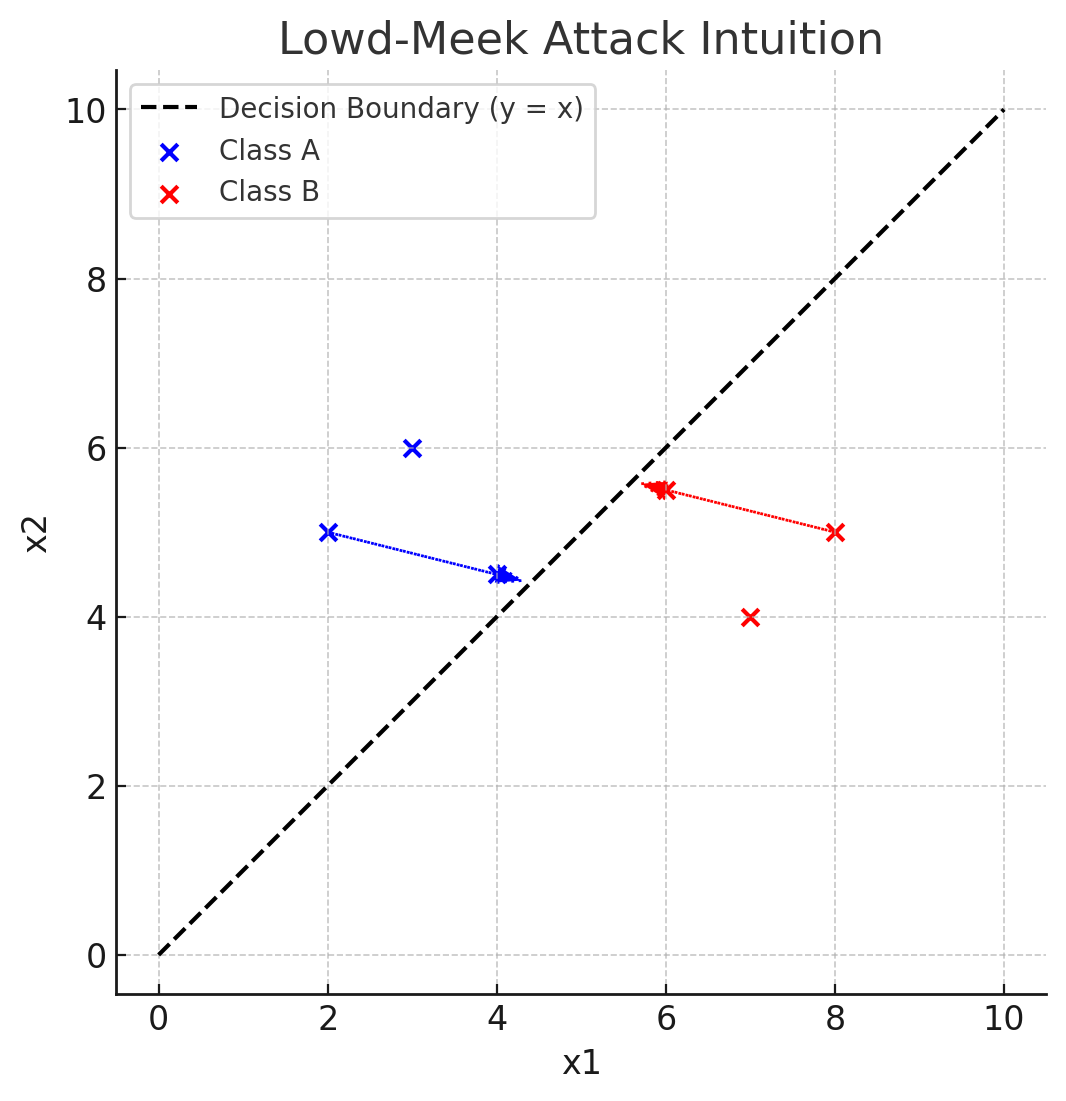
Retraining Attack
The Retraining Attack is an approach where the attacker directly trains an extracted model using the output of the target model. It uses the softmax probability values or class labels output by the API as training targets to extract a model that is functionally similar to the target model.
The Retraining approach is divided into three methods:
-
Uniform Retraining
- Randomly samples input x from the input space (pool), collects the oracle’s output, and trains the estimated model.
-
Line-Search Retraining
- Finds samples close to the target model’s decision boundary and trains the extracted model.
-
Adaptive Retraining
- Trains the extracted model based on the oracle’s output for randomly sampled x.
- Then queries the target model again with new points located near the extracted model’s decision boundary.
- Retrains the extracted model based on these results.
Below are the experimental results for each method and the Lowd-Meek attack:
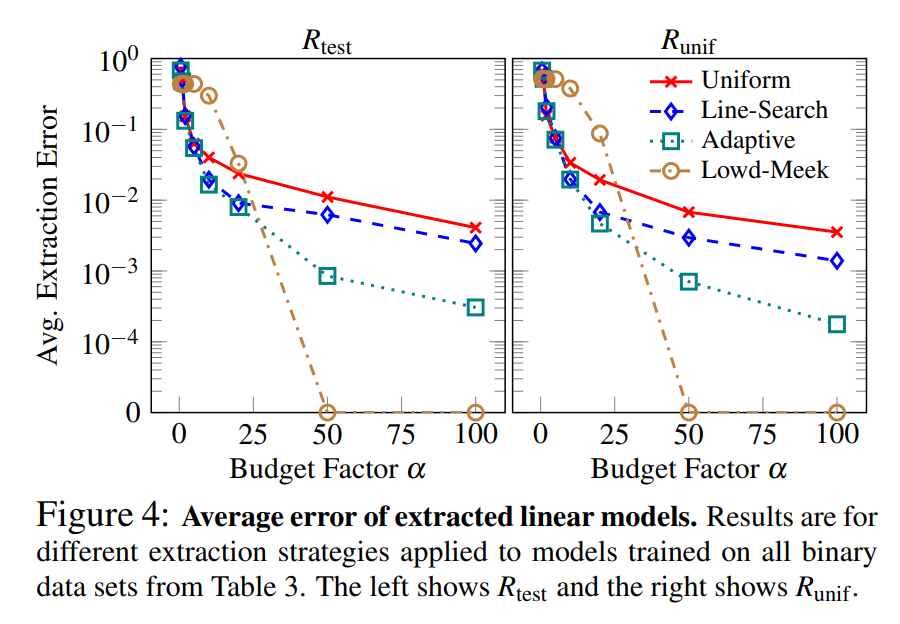
For linear models, Line-Search Retraining, which finds points near the decision boundary, clearly outperformed Uniform Retraining, and Adaptive Retraining was the most efficient among the three methods.
The Lowd-Meek attack demonstrated high performance when sufficient queries were available.
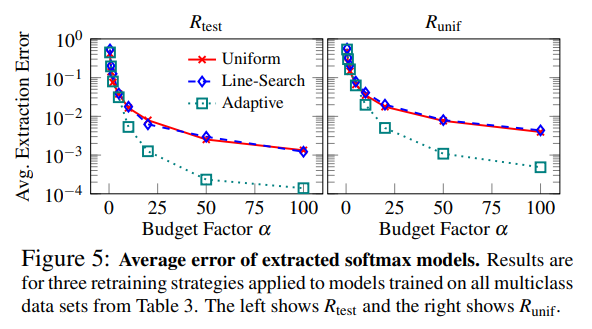
For softmax models, Adaptive Retraining showed higher performance than other methods, and no significant performance difference was observed between the Uniform and Line-Search methods.
Kernel Support Vector Machines (kernel SVM) map input data to a higher-dimensional space and then find a hyperplane that maximally separates each class. SVMs with polynomial kernels can attempt model extraction through the Lowd-Meek attack, but for radial-basis function (RBF) kernels, the transformed space is infinite-dimensional, making the attack inapplicable. Additionally, since SVMs do not provide confidence scores, retraining is the only applicable attack technique.
The experimental results for SVMs with RBF kernels are as follows:
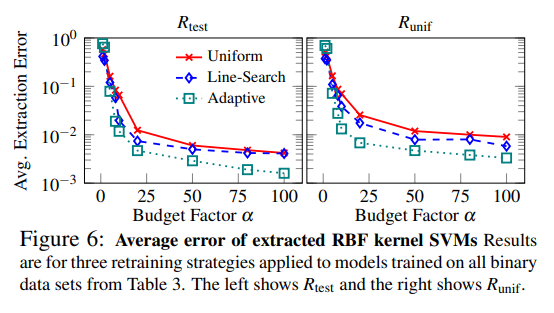
Adaptive retraining was confirmed to be the most efficient, and a model with over 99% accuracy could be extracted within the allowed number of queries.
Model Inversion Attack
The Model Inversion Attack is an attack that recovers features of a specific class from a model.
The optimal sample x is expressed by the following formula: \(x_{opt} = argmax_{x∈X}f_i(x)\) Based on the above expression, for an arbitrary sample x, the input that maximizes the probability of belonging to a specific class is found. In this case, the input that maximizes the model’s confidence score is found through gradient ascent.
The Model Inversion Attack proposed in Fredrikson et al. 2015 demonstrated that when the target model is a facial recognition model, the faces of data subjects used in training could be recovered as recognizable images.
This worked well in a white-box setting where the target model and its parameters are known. However, in a black-box setting where this information is unavailable, it was successful but required significantly more queries and was relatively less efficient.
Therefore, this paper proposed combining model extraction based on the previously described attacks with white-box inversion attacks using the extracted model.
Training Data Leakage for Kernel Logistic Regression
Kernel Logistic Regression (KLR) is a model that maps input data to a high-dimensional feature space and then trains a linear model.
The KLR model is a softmax model that replaces the existing linear structure with the following mapping, computing outputs based on the similarity between input samples and training samples:
\[\begin{align} w_i·x + \beta_i ⇒ ∑_{r=1}^{s} α_{i,r}⋅K(x,x_r)+β_i\\ ~where~K(x,x_r)~is~the~\text{kernel function,}\quad x_r\text{ is the representative sample for each class} \end{align}\]The model’s output is defined as follows:
\[\begin{align} f_i(x)= \frac{exp(∑_{r=1}^s α_{i,r}K(x,x_r)+β_j)} {\sum _{j=1}^c exp(∑_{r=1}^sα_{j,r}K(x,x_r)+\beta_i)} \end{align}\]If the attacker can access the target model’s softmax output, the following equation can be constructed for each query x:
\[\begin{align} ∑_{r=1}^{s} α_{i,r}⋅K(x,x_r)+β_i=σ^{−1}(f(x)) \end{align}\]The attacker obtains c nonlinear equations about the parameters and representative samples from each sample (x, f(x)) acquired from the target model. By solving this system of equations, not only the model parameters but also the actual training data x_r can be recovered.
Countermeasure
Beyond attacks, there is a need to study countermeasures for defense.
The attack techniques described above fundamentally become more difficult and require more queries when less information is provided. However, limiting the information provided can simultaneously reduce the model’s practicality and usability. Therefore, it is important to explore appropriate levels of information provision while balancing defense effectiveness and model utility.
This paper proposes rounding confidence, differential privacy, and ensemble methods as countermeasures.
-
Rounding confidences
Applications using prediction models may need confidence scores, but generally require only low levels of detail. Therefore, a possible defense is to round confidence scores to a certain fixed precision.
This can cause the equation solving attack to yield solutions corresponding to a truncated version of the target model rather than exact solutions. For attacks on decision trees, the possibility of node ID collisions increases, and the attack success rate decreases.
Below are the results of applying rounding to softmax models:
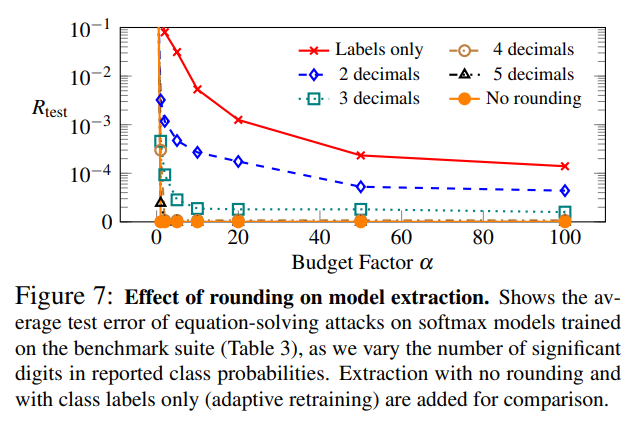
In the attack results on softmax models, it was confirmed that rounding the output values to 2-3 decimal places weakened the attack efficiency.
-
Differential privacy
Differential Privacy (DP), proposed in Springer et al. 2006, is a privacy protection framework that guarantees statistical analysis results remain nearly identical regardless of whether individual data items are included or not. Typically, DP is applied to training data. However, applying DP to training data alone cannot prevent model extraction attacks.
Therefore, this paper suggests that applying DP directly to model parameters would be an appropriate strategy, while leaving specific implementation details as future research.
-
Ensemble methods
Ensemble methods such as Random Forests make predictions based on the predictions of multiple individual models. While the paper did not experiment with attacks targeting this method, it speculates that they could be more resilient against model extraction attacks. The attacker would only be able to obtain a coarse approximation of the target model. However, the paper notes that such methods may still be vulnerable to attacks like model evasion.
Conclusion
This paper highlights that prediction APIs provided by MLaaS providers such as Amazon and BigML may be vulnerable to model extraction attacks, and demonstrates that this can facilitate disruption of model monetization, training data breaches, and model evasion.
The paper demonstrated the applicability and efficiency of attacks through experiments in local environments and online attacks against real providers.
As model extraction attack methods, the paper presented equation solving attacks for models with logistic output layers (BLR models, MLP models, etc.), path finding attacks for decision tree models, and proposed various retraining techniques based on prior research (Lowd-Meek attack, active learning, etc.) and evaluated each attack technique.
Additional countermeasures against these attacks were explored, with the most obvious approach being to limit the information provided by APIs.
Finally, evaluating these attack and defense techniques on real commercial machine learning services is suggested as future research.