논문명: Unified Gradient-Based Machine Unlearning with Remain Geometry Enhancement
저자: Zhehao Huang, Xinwen Cheng, JingHao Zheng, Haoran Wang, Zhengbao He, Tao Li, Xiaolin Huang
게재지: 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
URL: https://openreview.net/forum?id=dheDf5EpBT&referrer=%5Bthe%20profile%20of%20Tao%20Li%5D
사전 지식
머신 언러닝 연구 동향
“머신 언러닝(Machine Unlearning)”은 사전 학습된(pre-trained) 모델에서 특정 데이터의 영향을 제거하는 것을 목적으로 합니다. 특히 최신의 지식이 아니거나 편향이 있는 경우, 그리고 텍스트-이미지(text-to-image) 모델이 일하기에 안전하지 않은(NSFW) 이미지를 생성하는 것을 막는 경우에 보편적으로 사용됩니다.
기존의 머신 언러닝 방법은 Exact MU와 approximate MU의 두 가지 방법으로 나뉩니다. Exact MU의 경우 제거 대상 데이터인 forget data가 없는 데이터셋으로 처음부터 재학습(Retraining : RT)해서 얻을 수 있습니다. 다만 이 방법은 대규모 모델에 적용 시 시간-효율적이지 못하고 컴퓨터 자원이 많이 필요합니다. 따라서 최근 연구는 approximate MU를 이용해 재학습한 모델과 최대한 비슷한 성능을 내는 것을 목표로 합니다.
유클리드 거리 측정 방식의 한계
기존 approximate MU는 경사하강법 시 유클리드 거리(Euclidean distance) 개념 하에서 가장 빨리 감소하는 기울기를 찾습니다. 하지만 이 방법은 매개변수(parameter) 간 중요도를 고려하지 않는다는 문제점을 갖습니다.
최근 연구 결과 모델의 매개변수(parameter)와 훈련 (training) 과정은 저차원의 다양체(low-dimensional manifold)에 주로 임베딩(embedding)되어있습니다. 이는 특정 다양체에서 일어난 매개변수 간 변화가 output space 상에 반영되지 않는 유클리드 거리 측정 방식의 문제를 나타냅니다.
본 논문에서는 이 문제를 해결하기 위해 제거하지 않은 데이터인 remaining data 의 이차 Hessian 행렬을 이용한 KL divergence 분포로 하강 방향을 계산합니다. 하지만 Hessian 값을 계산하는 것 역시 대규모 모델의 자원을 많이 사용할 수 있습니다. 이에 논문은 Hessian 방식에 근사하지만 초기에 계산된 매개변수를 고정하지 않고 동적으로 할당하는 fast-slow weight method를 제시합니다.
경사하강법 관점에서의 Approximate MU
유클리드 거리 기반 approximate MU
경사하강법(Steepest descent)은 특정 범위 내에서 함수 F가 가장 빠르게 감소하는 방향을 계산합니다. 이를 수식으로 나타내면 다음과 같습니다.
\[\begin{equation} \delta \theta := \arg\min_{\substack{\ \rho(\theta_t, \theta_t + \delta\theta) \leq \xi}} F(\theta_t + \delta\theta) \end{equation}\]이를 수식으로 나타내면 다음과 같습니다.
\[\begin{equation} \theta_{t+1} = \arg\min_{\theta_{t+1}} \left[ F(\theta_{t+1}) + \frac{1}{\alpha_t(\xi, \theta_t)} \rho(\theta_t, \theta_{t+1}) \right] \end{equation}\]또한 거리 함수 역시 유클리드 거리에 기반해 다음과 같이 정의됩니다.
\[\rho(\theta_t, \theta_{t+1}) = \frac{1}{2} \|\theta_t - \theta_{t+1}\|^2\]KL divergence 기반 approximate MU
거리 함수를 사용하는 것이 아닌 KL divergence에 따른 두 확률 분포 간의 차이를 최소화하는 형태의 손실함수는 다음과 같이 정의할 수 있습니다.
\[\begin{equation} \theta_{t+1} = \arg\min_{\theta_{t+1}} \left[ D_{KL} \big( p_z(\theta_*) \| p_z(\theta_{t+1}) \big) + \frac{1}{\alpha_t} \rho(\theta_t, \theta_{t+1}) \right] \end{equation}\]위의 식은 기능에 따라 세 부분으로 나눌 수 있습니다.
\[\begin{equation} \theta_{t+1} = \arg\min_{\theta_{t+1}} \underbrace{D_{KL} \big( p_z^f(\theta_*) \| p_z^f(\theta_{t+1}) \big)}_{(a)} + \underbrace{D_{KL} \big( p_z^r(\theta_*) \| p_z^r(\theta_{t+1}) \big)}_{(b)} + \underbrace{\frac{1}{\alpha_t} \rho(\theta_t, \theta_{t+1})}_{(c)} \end{equation}\]이때 각 부분의 역할은 다음과 같습니다.
(a) : forget data의 영향을 제거하는 부분
(b) : remaining data의 성능을 유지하는 부분
(c) : 각 업데이트의 크기를 조절하는 부분
연구진들은 거리 함수를 유클리드 기반이 아닌, Hessian을 반영한 뉴턴의 방법(Newton’s direction)으로 정의해 forget data와 remaining data의 영향을 균형 있게 조절합니다.
\[\begin{equation} \theta_{t+1} - \theta_t \approx -\alpha_t \underbrace{ \left[ H_f^* (H_r^*)^{-1} \right]}_{(S)}\underbrace{ \left[ -\nabla L_f(\theta_t; \epsilon_t) \right] }_{(F)} + \underbrace{\nabla L_r(\theta_t)}_{(R)} \end{equation}\](F)는 forget data의 손실을 증가시켜 해당 데이터의 영향을 제거하고, (R)은 remaining data의 손실을 최소화해 모델이 기존 성능을 유지하도록 조절합니다.
(S)는 forget data에서의 업데이트를 더 크게 만들고, remaining data에서의 업데이트를 줄이며 두 데이터셋 간의 간 영향을 조절합니다.
기존 머신 언러닝 방식들은 (F), (R), (S)의 세 가지 요소 중 하나 이상을 놓친 형태였습니다.
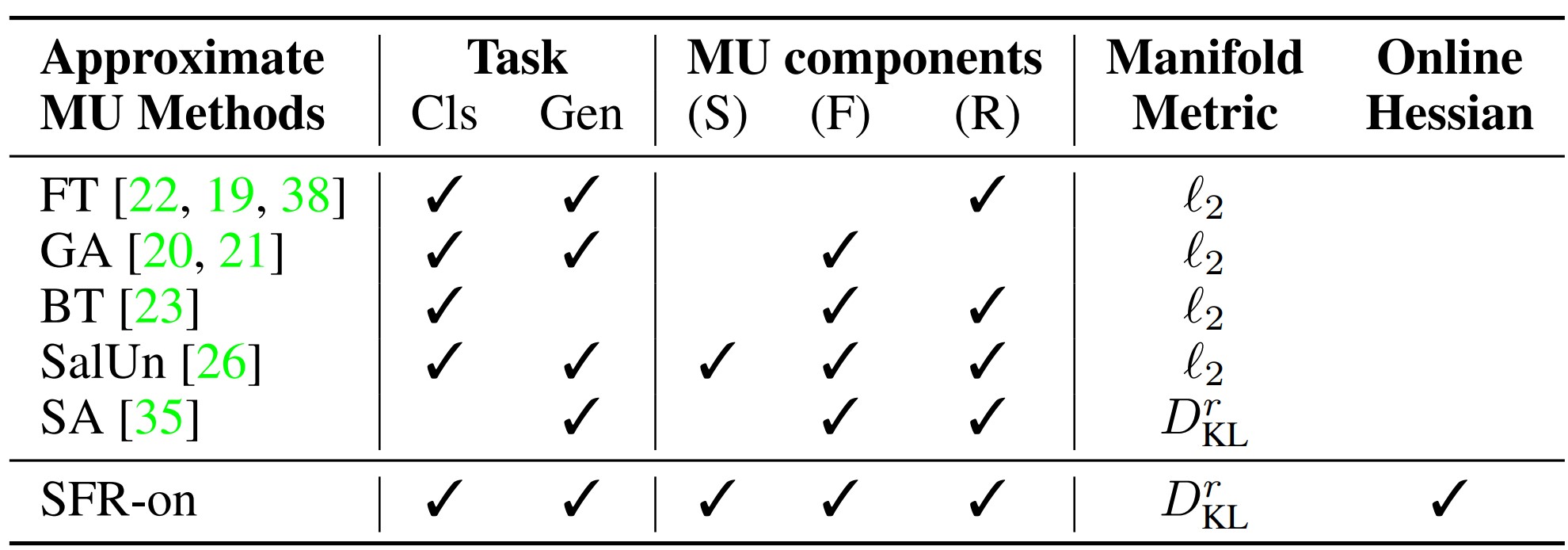
예를 들어 Fine-Tuning의 경우 (F) 요소를 고려하지 않아 효과적인 언러닝 성능을 보장하기 어려웠습니다. Gradient Ascent 방식의 경우 (R) 요소를 고려하지 않아 제거하지 않은 데이터셋에 대한 성능을 보장하기 어려웠고, Random Labeling과 BadTeacher Knowledge Distillation의 경우 (S) 요소를 고려하지 않아 언러닝은 성능은 보장할 수 있었지만 remaining data에 대한 성능 유지가 어려웠습니다.
마지막으로 가장 최근에 발표된 SalUn의 경우 weight saliency 개념을 도입해 (S)를 부분적으로 고려했으나 이론적 설명이 부족했습니다.
본 논문에서는 세 가지 요소를 모두 고려한 언러닝 방법을 제시함으로써 이전 방법들과의 차이를 강조합니다.
Remain-Preserving Manifold
제거해야 할 데이터를 효과적으로 제거하면서도 모델의 전반적인 성능을 유지하기 위해서 KL divergence 기반의 Remain-Preserving Manifold 개념을 도입합니다.
이 방법은 기존 유클리드 거리 기반의 업데이트 크기 조절 방식에서의 문제를 해결하며 두 확률분포의 변화량에 기반해 모델 출력이 크게 변하지 않는 방향으로 업데이트를 조절할 수 있습니다.
\[\begin{equation} \theta_{t+1} - \theta_t \approx -\tilde{\alpha}_t \underbrace{ (H_r^t)^{-1}}_{(R)} \underbrace{ \left[ H_f^* (H_r^*)^{-1} \right] }_{(S)} \underbrace{ \left[ -\nabla L_f(\theta_t; \epsilon_t) \right] }_{(F)} \end{equation}\]SFR-on의 각 요소
Hessian 근사
Remain-preserving manifold 방식 도입 시 Hessian 계산에 따른 많은 연산량이 문제가 됩니다. 기존 연구에서 역시 Fisher information, Fisher diagonal, Kronecker-Laplace approximation 등 Hessian에 근사하기 위한 시도가 있어 왔습니다. Selective Amnesia 방식에서는 Fisher diagonal을 이용해 Hessian을 근사했지만, 이 근삿값이 고정되어 있어 언러닝 과정에서 오차가 누적되는 문제가 있었습니다.
논문에서는 fast-slow weight update를 이용해 위와 같은 문제를 해결합니다.
Hessian 근사를 이용한 최적화 방법(R-on)
Hessian으로 언러닝할 방향을 조정하는 방식(implicit Hessian approximation)의 문제를 해결하기 위해, 논문에서는 Hessian을 직접 계산하지 않고 이에 근사하는 값을 얻는 fast-slow weight update 방식을 제시합니다.
fast slow weight update는 언러닝을 수행하는 fast weight update 방식과, 이에 따른 모델의 성능 저하를 최소화하는 slow weight update 방식으로 나뉩니다. 모델은 fast weight update 후 slow weight update를 수행해 언러닝 성능을 보장하면서도 remaining data에 대한 모델의 성능을 유지하는 매개변수를 얻습니다.
Fast weight update
fast weight update는 forget data에 대한 손실함수의 기울기를 계산해 모델이 데이터를 잊는 방향으로 매개변수를 빠르게 업데이트합니다.
\[\begin{equation} \quad \theta^f_t = \theta_t - \beta_t \nabla L^u (\theta_t) \end{equation}\]Slow weight update
slow weight update는 fast weight update 후 Fine-Tuning을 통해 remaining data에 대한 성능을 유지합니다. 이때 fast weight update로 구한 매개변수를 이용해 remaining data에 대한 손실함수 값을 최소화해서 최적화합니다.
\[\begin{equation} \min_{\theta^f_t} L^r (\theta^f_t) \quad \ \end{equation}\]Fast-slow weight update.
위의 두 방식을 모두 고려한 업데이트는 다음과 같습니다. Hessian을 직접 계산하는 대신 fast-slow weight method를 도입해 Hessian의 역행렬을 근사적으로 적용할 수 있습니다.
\[\begin{equation} \theta_t - \theta^r_t \approx \beta_t^2 \left[ \nabla^2 L^r (\theta_t) \right]^{-1} \nabla L^u (\theta_t) = \beta_t^2 (H_t^r)^{-1} \nabla L^u (\theta_t). \end{equation}\]이 방식은 언러닝 과정에서 forget data에 대한 성능을 크게 손상시키는 방향이면 매개변수 업데이트가 약해지고, 영향을 덜 미치는 방향이면 업데이트가 강해집니다. 즉 단순히 손실함수의 기울기를 합산하는 방식이 아닌, Hessian을 도입함으로써 remaining data에 대한 모델의 성능을 최대한 보존할 수 있습니다.
가중치 조절 방식(F)
기존 언러닝 방식에서는 모든 샘플이 동일한 중요도를 가집니다. 즉 언러닝 시 손실함수에서 동일한 기여도를 가집니다. 다만 중요도에 따라 어떤 샘플은 한 번의 업데이트로 쉽게 잊힐 수 있고, 여러 번의 업데이트에도 잊히지 않을 수 있습니다.
논문은 샘플의 중요도에 따라 가중치를 다르게 부여함으로써 이 문제를 해결합니다. 이때 중요도에 따른 가중치는 다음과 같이 정의합니다.
\[\begin{equation} \tilde{\epsilon}_{t,i} = \left( 1 - \frac{t}{T} \right) \frac{\frac{1}{\left[ \ell(\theta_t; z^f_i) \right]_{detach} ^\lambda}} {\sum\limits_{z^f_j \in D_f} \frac{1}{\left[ \ell(\theta_t; z^f_j) \right]_{detach}^\lambda}} \times N_f, \quad 1 \leq i \leq N_f \end{equation}\]가중치는 다음과 같은 특성을 가집니다.
- 초기 모델에서는 모든 데이터에 동일한 가중치 = 1을 부여합니다.
- 언러닝이 완전히 이루어진 상태에서 모두 동일한 가중치 = 1을 가져야 합니다.
- 특정 데이터에 대한 손실이 클수록 작은 가중치를 부여합니다.
위의 과정을 거쳐 업데이트하며 손실을 점진적으로 감소하는 방식으로 조절합니다.
Weight Saliency 방법(S)
논문은 forget dataset과 remaining data의 균형을 맞추기 위해 weight saliency 개념을 도입합니다.
기존 SalUn 머신 언러닝 방식에서는 forget data에 영향을 주는 매개변수만 고려했습니다. 하지만 이 경우 remaining data에서의 성능이 손상될 수 있기 때문에, 두 data를 모두 고려하는 weight saliency 방법이 필요합니다.
weight saliency map은 다음과 같습니다.
\[\begin{equation} m = I \left[ \frac{F^f_{\text{diag}}}{F^r_{\text{diag}}} \geq \gamma \right], \quad \text{where} \quad F^f_{\text{diag}} = [\nabla L^f (\theta_0)]^2, \quad F^r_{\text{diag}} = [\nabla L^r (\theta_0)]^2. \end{equation}\]weight saliency map은 forget data에만 적용해 잊어야 할 중요한 샘플에 대해서만 업데이트될 수 있도록 합니다.
#### SFR-on
논문에서는 S, F, R-on의 세 가지 요소를 하나로 통합한 SFR-on을 제시합니다.
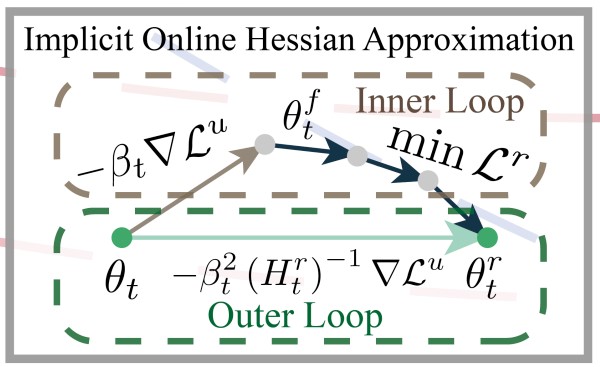
SFR-on에서 일어나는 업데이트는 inner loop에서 일어나는 fast weight update와 outer loop에서 일어나는 slow weight update로 나눌 수 있습니다.
Inner loop에서는 fast weight update가 일어납니다. 이때 개별 가중치와 weight saliency map을 이용해 forget data에 대한 업데이트 크기를 조절하고, remaining data에 대한 성능을 손상하지 않도록 조절합니다.
\[\begin{equation} \min_{\theta^f_t} L^r (\theta^r_t) \quad \text{s.t.} \quad \theta^f_t = \theta_t - \beta_t \left[ m \odot (-\nabla L^f (\theta_t; \tilde{\epsilon}_t)) \right] \end{equation}\]Outer loop에서는 slow weight update가 일어납니다. 이때 inner loop 결과를 기반으로, 언러닝 방향을 Hessian 기반으로 조정해 remaining data에 대한 성능을 보호합니다.
\[\begin{equation} \theta_{t+1} = \theta_t - \alpha_t (\theta_t - \theta^r_t) \approx \theta_t - \alpha_t \beta_t^2 (H_t^r)^{-1} \left[ m \odot (-\nabla L^f (\theta_t; \tilde{\epsilon}_t)) \right] \end{equation}\]SFR-on은 특정 task에 맞춰 수정할 필요가 없이 여러 머신 언러닝 task에 사용될 수 있으며, 논문에서는 컴퓨터 비전(CV) 영역에서의 다양한 머신 언러닝 사례에 집중합니다. 또한 전체 remaining data 자체를Fine-Tuning하는 것은 비효율적이기 때문에 forget data와 동일한 크기로 랜덤하게 선택해 연산량을 줄입니다.
이미지 분류 task에서의 SFR-on
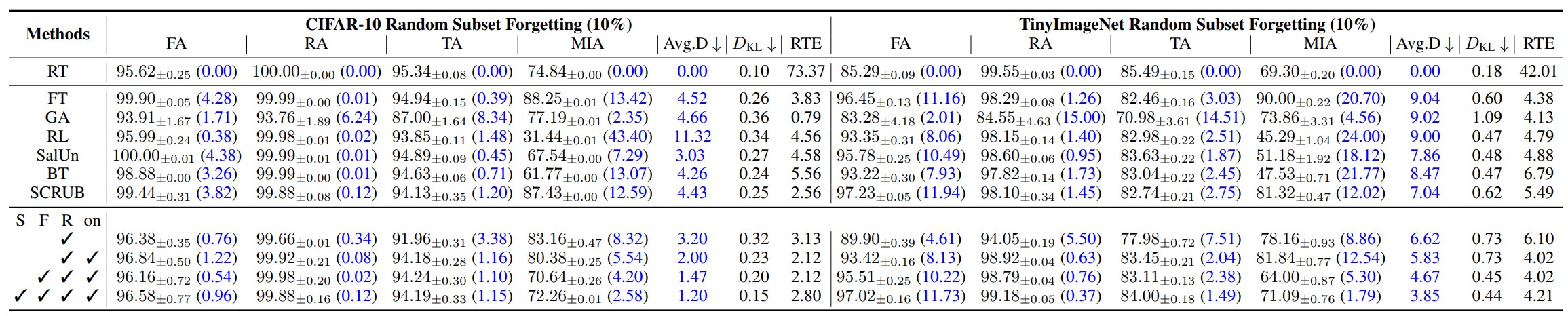

위 표는 차례대로 전체 데이터셋의 10%, 50%를 잊었을 때의 분류 task 상 각 언러닝 모델의 정확도와 KL divergence, RTE(Run Time Efficiency)를 측정한 결과입니다. 정확도, KL divergence 측정 결과 재학습 방식과 가장 가까운 결과를 도출한 모델이 SFR-on 모델임을 확인할 수 있습니다.
또한 이 결과로 SFR-on의 각 요소(S, F, R-on)가 모델에 기여하는 영향도 측정할 수가 있습니다. 결과적으로 세 요소를 모두 도입한 모델의 성능이 가장 좋음을 알 수 있지만, S, F, R-on각 요소가 모델 성능에 기여하는 영향만을 측정한 결과가 추가적으로 있었다면 각 요소의 영향을 더 객관적으로 파악할 수 있을 것 같습니다.
이미지 생성 task에서의 SFR-on

논문에서는 이미지 생성 모델에 재학습 방식을 적용하기 어렵기 때문에 새로운 재학습 방식을 정의하고, 이를 기존 방식과 비교합니다. 결과적으로 SFR-on의 방식이 정확도, KL divergence 결과 상으로 가장 적은 차이를 보였음을 확인할 수 있습니다.
또한 특정 개념을 잊은 경우의 이미지 생성 성능도 확인할 수 있었습니다.

NSFW 개념을 잊은 모델에서 관련된 개념을 프롬프트(prompt)로 입력할 경우, 다른 언러닝 기법에 비해 SFR-on의 관련 이미지 생성 횟수가 가장 적음을 확인할 수 있습니다.