Paper: Adversarial Retain-free Unlearning for Bearing Prognostics and Health Management
Authors: Chaewon Yoon, Jiyoung Lee, Hoki Kim
Venue: IEEE Transactions on Industrial Informatics
Introduction
With the advent of the Fourth Industrial Revolution, PHM (Prognostics and Health Management) technologies based on sensor data and artificial intelligence are being actively utilized in industrial settings. In particular, deep learning models have demonstrated high accuracy in critical equipment management areas such as bearing fault diagnosis, establishing themselves as a key technology that determines industrial competitiveness.
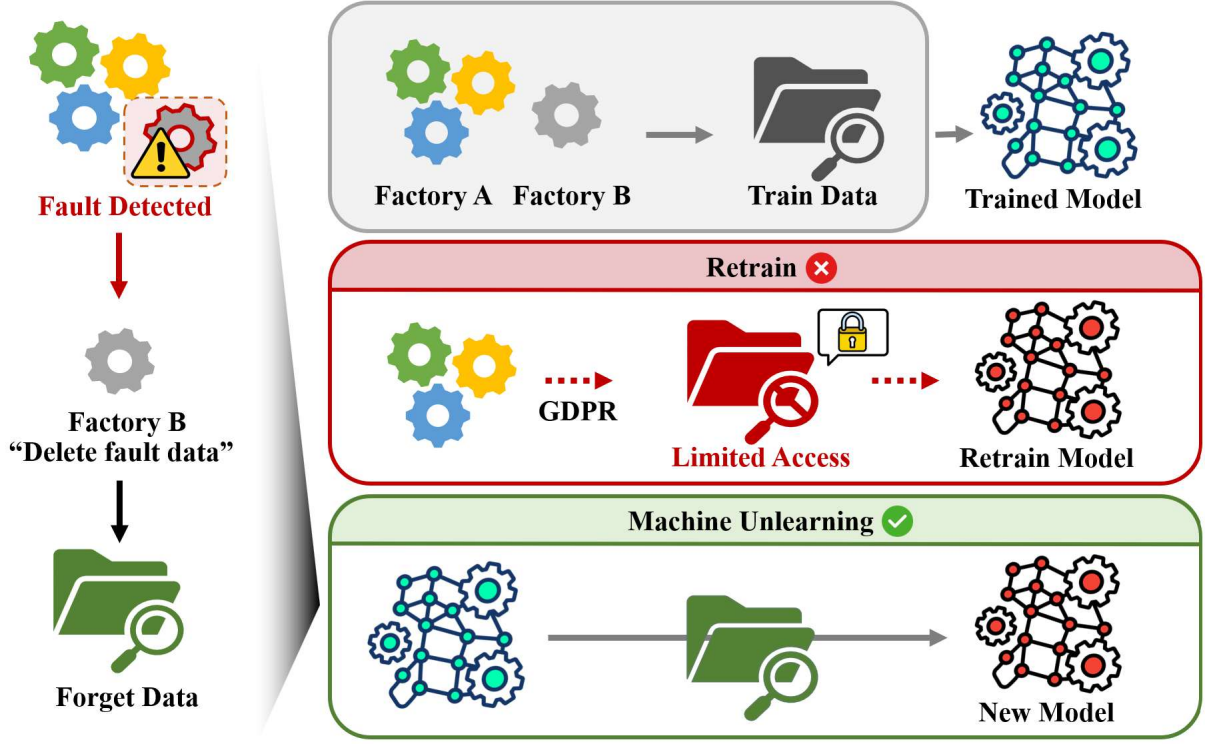
Machine Unlearning is a useful technology for situations where certain data previously learned by a model must be deleted later, much like the “Right To Be Forgotten” specified in the GDPR, a major data protection regulation.
Our lab’s paper “Adversarial Retain-free Unlearning for Bearing Prognostics and Health Management” [Paper] proposes a new framework that can perform machine unlearning using only the data to be deleted and the already-trained model, taking into account the realistic constraints of manufacturing environments.
In this article, we will examine the limitations of existing machine unlearning methods in manufacturing process environments and introduce the proposed ARU method.
Background
Adversarial Examples
Adversarial examples (Adversarial Attack) add a very small perturbation (\(\epsilon\)) to a specific sample through an adversarial attack, inducing the model to classify the sample as a completely different class.
Representative adversarial attack methods include FGSM and PGD:
1. FGSM (Fast Gradient Sign Method): Adds a perturbation with a single gradient computation.
\[\begin{equation} \delta = \epsilon \cdot \operatorname{sign} (\nabla_{x}\mathcal{L} (f_{\theta} (x)), y), \end{equation}\]2. PGD (Projected Gradient Descent): Extends FGSM over multiple steps to perform a stronger attack.
\[\begin{equation} x^{t+1} = \Pi_{\lVert \delta \rVert_{\infty}\le \epsilon} \left (x^t + \alpha \cdot \operatorname{sign} (\nabla_{x^t}\mathcal{L} (f_{\theta} (x^t), y)) \right), \end{equation}\]Machine Unlearning
When the entire dataset learned by the model is denoted as \(\mathcal{D}\), the data can be divided into two categories based on whether it should be deleted:
1. Forget data = \(\mathcal{D_F}\)
2. Retain data = \(\mathcal{D_R}\)
Machine unlearning assumes the ideal state to be a model trained only on \(\mathcal{D_R}\). In this article, we refer to this ideal training method as Retrain. However, retraining a model from scratch incurs significant time and cost overhead. Therefore, machine unlearning techniques are needed to remove the target data from an already-trained model using specific algorithms.
Machine unlearning aims to guide the model to forget the information in \(\mathcal{D_F}\) while retaining the information in \(\mathcal{D_R}\), thereby achieving a state similar to Retrain.
Retain-free Unlearning
We introduce retain-free unlearning methodologies proposed in prior research. When the model weights are denoted as \(\theta\), each method updates as follows:
1. Gradient Ascent (GA): Unlearns by maximizing the loss on \(\mathcal{D_F}\). \(\begin{equation} \theta \leftarrow \theta + \eta\cdot \nabla_{\theta} \mathcal{L} (f_{\theta} (x_f), y_f) \text{ where } (x_f, y_f) \in \mathcal{D_F} \end{equation}\)
2. Random Labeling (RL): Unlearns by assigning random labels to \(\mathcal{D_F}\) samples. \(\begin{equation} \theta \leftarrow \theta - \eta \cdot \nabla_{\theta}\,\mathcal{L}\big(f_{\theta}(x_f), \tilde{y}\big) \end{equation}\)
3. Adversarial Machine UNlearning (AMUN): Applies a minimal perturbation (\(\epsilon^{\star}\)) to \(\mathcal{D_F}\) to obtain adversarial examples \(\mathcal{D_A}\), then retrains the model (\(\theta\)) on \(\mathcal{D_F} \cup \mathcal{D_A}\).
The adversarial examples \(\mathcal{D_A} = (x_f^{adv}, y_f^{adv})\) are constructed as follows:
First, for an adversarial attack algorithm \(A\), we find the minimum perturbation magnitude \(\epsilon^{\star}\) that causes \(\mathcal{D_F}\) to be misclassified. \(\begin{equation} \epsilon^\star = \min \{\epsilon : \arg\max_i f_{\theta} (A (x_f, \epsilon))_i \neq y_f \} \end{equation}\)
Next, we construct the adversarial examples \(\mathcal{D_A} = (x_f^{adv}, y_f^{adv})\) using the minimum perturbation magnitude \(\epsilon^{\star}\). \(\begin{equation} x_f^{adv} = A(x_f, \epsilon^{star}), y_f^{adv} = arg \max_i f_{\theta}(x_f^{adv})_i \end{equation}\)
Finally, the model is retrained on \(\mathcal{D_F}\cup\mathcal{D_A}\). \(\begin{equation} \theta \leftarrow \theta - \eta \sum_{ (x,y)\in \mathcal{D_F} \cup \mathcal{D_A}} \nabla_{\theta}\mathcal{L} (f_{\theta} (x),y) \end{equation}\)
Main Content
Existing retain-free unlearning algorithms often severely disrupt the model’s structure. Moreover, when experimented on manufacturing process data, they showed degraded classification capability.
This paper quantifies the model collapse problem of existing retain-free unlearning algorithms in environments with restricted access to the full dataset and proposes the ARU framework to address it.
Adversarial Retain-free Unlearning (ARU) consists of two stages:
1. Adversarial Example Generation: Using \(\mathcal{D_F}\), we generate adversarial examples (\(\mathcal{\tilde{D}_R}\)) that the model perceives as \(\mathcal{D_R}\) within the scope of what it has memorized.
2. Model Retraining: Using the loss function \(\mathcal{l}_{\texttt{SDA}}\), we guide the model to move away from \(\mathcal{D_F}\) and closer to \(\mathcal{\tilde{D}_R}\).
Quantifying Model Structure
This paper quantifies how well existing retain-free unlearning methods preserve the model’s structure through Structural Similarity Correlation (SSC).
SSC is computed through the following procedure:
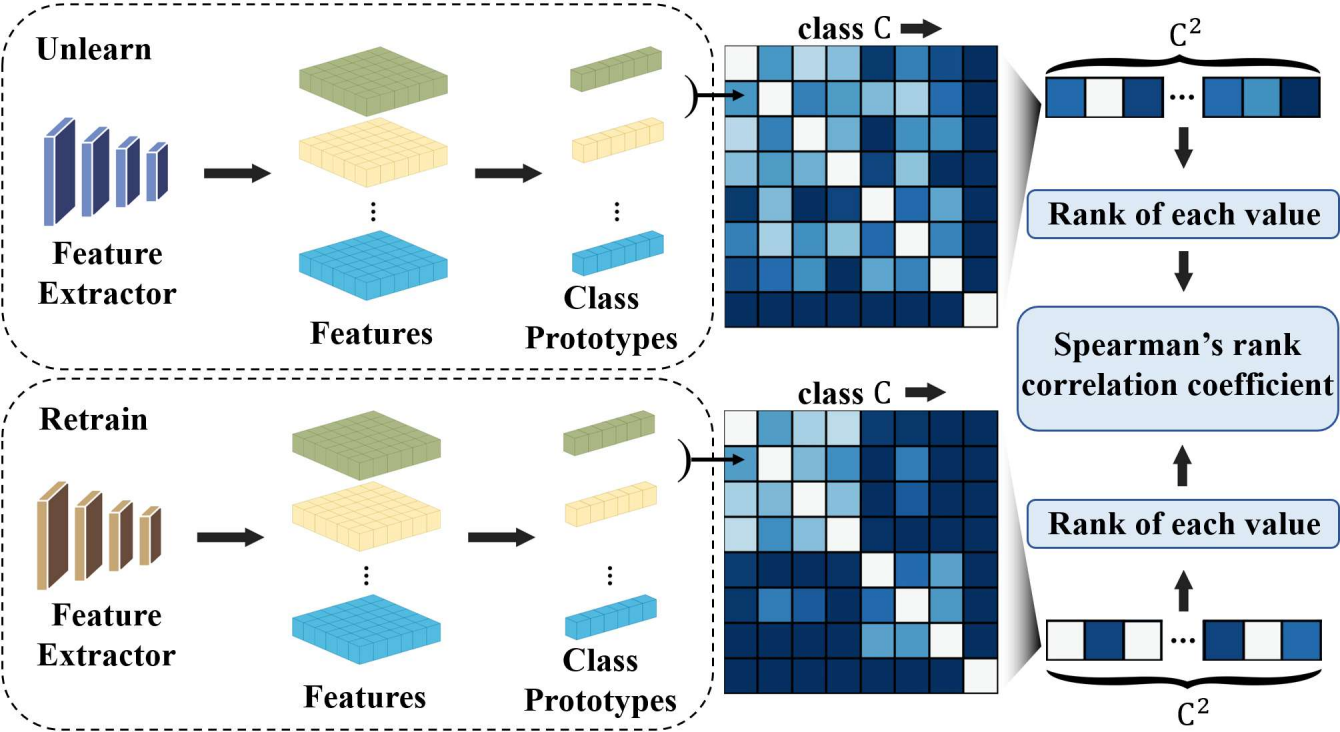
1. Compute the prototype vector for each retain class
For class \(k \in C\) over the dataset classes \(C\), the prototype vector \(p_k\) is computed as follows:
\[\begin{equation} p_k = \frac{1}{|S_k|} \sum_{x \in S_k} f (x), \end{equation}\]2. Construct the inter-class similarity matrix
For \(i, j \in C\), the inter-class similarity is measured using the cosine distance between class prototype vectors.
Based on the similarity between classes \(i\) and \(j\), we construct the Representational Dissimilarity Matrix (RDM) \(M_{i,j}\).
\[\begin{equation} M_{ij} = 1 - \frac{p_i \cdot p_j}{\|p_i\| \|p_j\|} \end{equation}\]3. Measure similarity between the RDM of Retrain and the RDM of the unlearned model
This step is designed to measure structural similarity rather than quantitative similarity between two class structures. Therefore, when measuring the similarity between two RDMs, we compute SSC using Spearman’s rank correlation.
\[\begin{equation} SSC = 1 - {6\cdot \sum d_i^2 \over n(n^2-1)} \end{equation}\]A higher SSC value indicates greater structural similarity between the unlearned model and the Retrain model.
Adversarial Example Generation
In a retain-free environment, \(\mathcal{D_R}\) is not accessible. Therefore, we must generate \(\mathcal{\tilde{D}_R}\), which resembles the retain data, using only the pre-trained model \(f\) and the forget data \(\mathcal{D_F}\).
Among existing retain-free unlearning algorithms, AMUN performs an untargeted adversarial attack on \(\mathcal{D_F}\), increasing the perturbation radius in an arbitrary direction until misclassification occurs.
However, when unlearning is performed in this manner in the PHM domain, an embedding collapse phenomenon occurs where the model collapses toward a specific class direction.
This paper addresses this by performing a targeted adversarial attack.
First, for a forget sample \((x_f, y_f)\in\mathcal{D_F}\), we define \(\tilde{y}\) as the class with the highest softmax probability excluding the original class \(y_f\):
\[\begin{equation} \tilde{y} = \arg\max_{f (x_f)_k \neq y_f} f (x_f)_k, \end{equation}\]This represents the class direction in which the model is most confused about the given sample. In other words, instead of an arbitrary direction, we perform a targeted update toward the class the model is most confused about.
Then, \(\mathcal{\tilde{D}_R}\) is generated through the following iterative update, a variant of PGD:
\[\begin{equation} x^{t+1} = \Pi_{\mathcal{B}_\epsilon} \Big( (x^t + \zeta^t) + \alpha \cdot \operatorname{sign}\Big( \nabla_{x^t + \zeta^t} \big[ \mathcal{L}(f(x^t + \zeta^t; \theta), \tilde{y}) \big] \Big) \Big), \end{equation}\]Here, \(t\) is the iteration step of the attack, \(\Pi_{\mathcal{B}_\epsilon}\) is the projection operation that ensures the perturbation does not exceed the radius \(\epsilon\) via the \(\mathcal{l}_{\inf}\)-ball, and \(\zeta^t\) is a small stochastic noise injected at each attack step.
The key is per-step stochasticity. By adding small noise at each step, the local loss landscape is smoothed, preventing excessive convergence in a single direction.
As a result, the generated \((\tilde{x}, \tilde{y})\) are located near the manifold of the pre-unlearning model and function as retain-like samples aligned with the geometric structure of retain classes.
Unlearning Algorithm for Preserving Model Structure
The goal of ARU is to remove the information of forget data while preserving the model’s structure without directly accessing the retain data. This can be formulated as follows:
\[\begin{equation} \mathcal{L}_{ARU}(x_f, \tilde{x}, y;\alpha) = \mathcal{L}_\texttt{SDA}(x_f, \tilde{x};\alpha) + \mathcal{L}_\texttt{CE}(\tilde{x}, y) \end{equation}\]The above loss function has two components:
1. Unlearning term: \(\mathcal{L}_\texttt{SDA}\) pushes the forget sample \(x_f\) away from the original forget class center and guides it toward the center of the retain-like data.
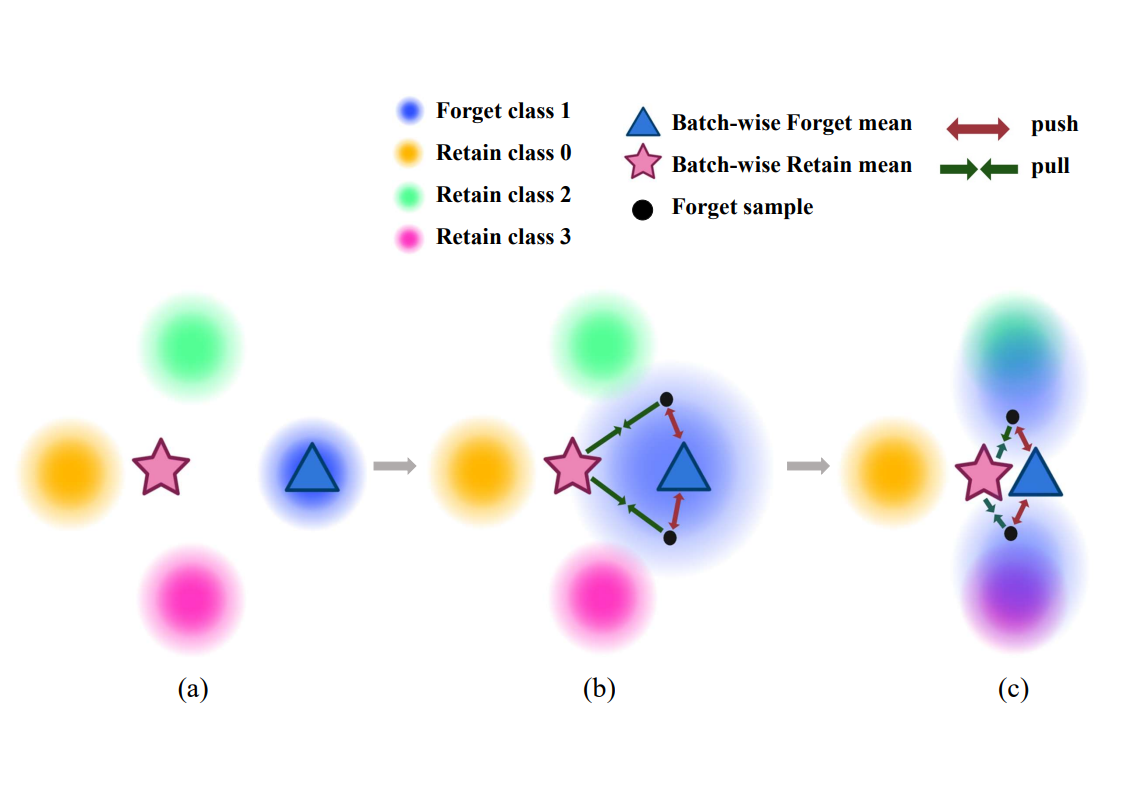
2. Model structure preservation term: \(\mathcal{L}_\texttt{CE}\) preserves the model’s structure by retraining on the retain-like data \(\mathcal{\tilde{D}_R}\).
By combining both terms, we simultaneously achieve forget data separation through \(\mathcal{L}_\texttt{SDA}\) and model structure preservation through \(\mathcal{L}_\texttt{CE}\).
Performance in the Embedding Space
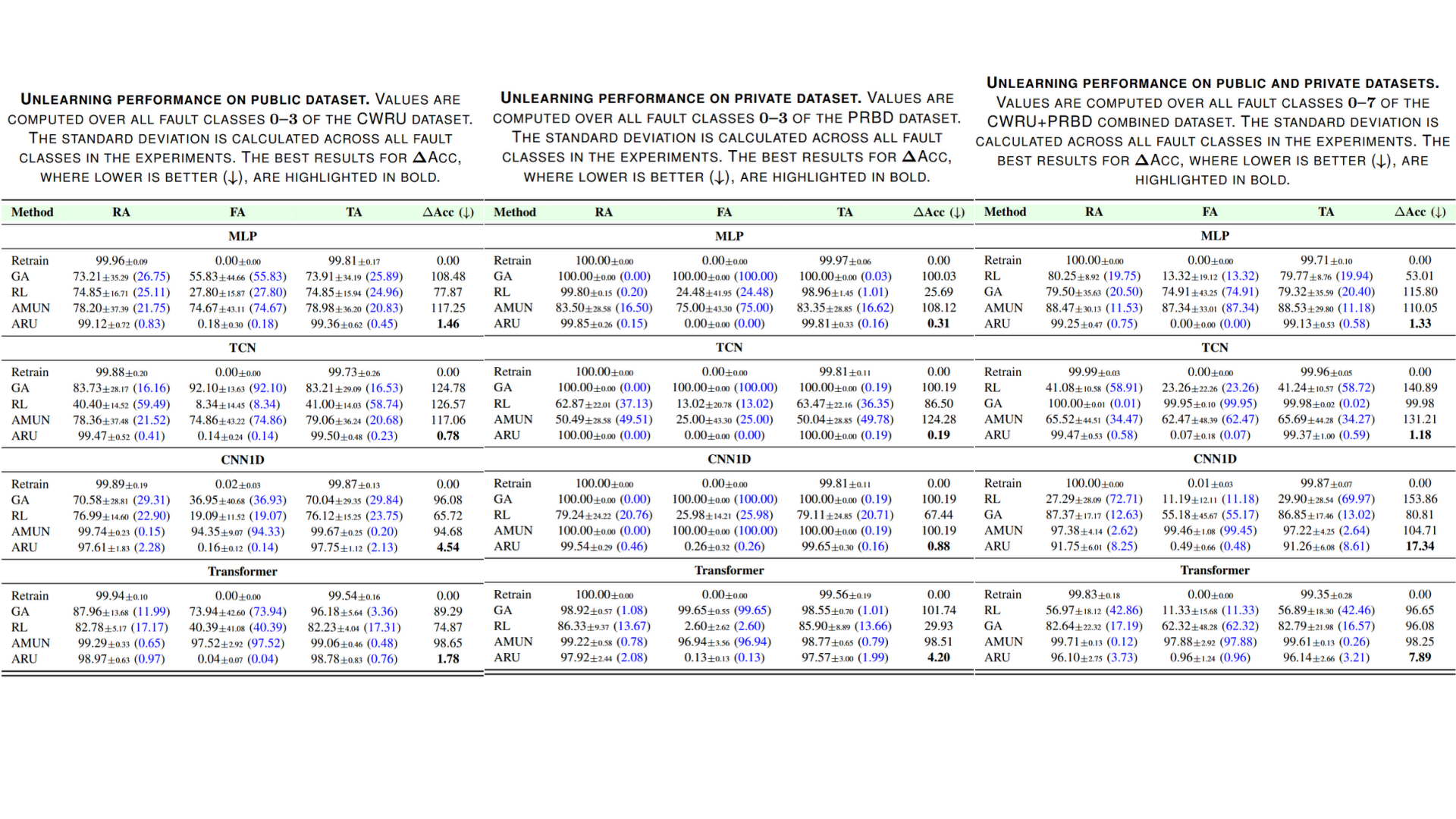
ARU was evaluated on three manufacturing process datasets:
1. CWRU Dataset: A widely used dataset for bearing fault detection. The CWRU dataset is divided into four states based on fault location: normal, ball fault, inner race fault, and outer race fault, with samples collected from the process frequency of each state.
2. PRivate Bearing Dataset (PRBD): A bearing fault diagnosis dataset constructed in this study. Like the CWRU dataset, it has four fault states.
3. CWRU + PRBD Dataset: Both public and private datasets are used simultaneously to simulate a realistic retain-free environment.
Additionally, four deep learning models – MLP, TCN, CNN1D, and Transformer – were used to implement various PHM environments.
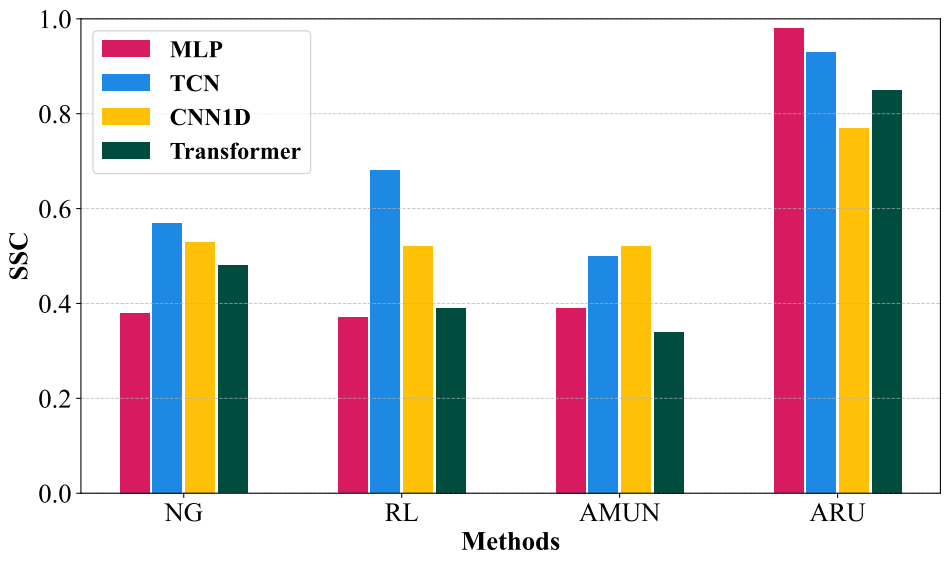
Experimental results across the three datasets show that ARU achieves the lowest \(\Delta\)Acc across all datasets, recording the accuracy closest to Retrain.
Conclusion
AI-based model diagnosis systems are widely utilized in industrial settings. In situations where specific data must be deleted from a model for legal or security reasons, the model must be made to “forget” that data. Especially in real industrial environments, it is often difficult to regain access to the full training data, necessitating a new machine unlearning approach to address this challenge.
This paper proposes the Adversarial Retain-free Unlearning (ARU) framework to address this problem. ARU effectively removes target data using only the data to be deleted instead of the full training data, while maintaining the necessary information. Through experiments on various datasets, we confirmed that ARU stably separates specific classes while preserving the model’s structure and accuracy.
Machine unlearning is a technology that will become increasingly important for privacy protection and compliance with industrial regulations. We hope this research contributes to the development of unlearning techniques applicable in real PHM environments.
Related Papers from Our Lab
- Unlearning-Aware Minimization [NeurIPS 2025] | [Paper] | [Article]| [Code]
- Evaluating practical adversarial robustness of fault diagnosis systems via spectrogram-aware ensemble method [EAAI] | [Paper] | [Article]
- Black-box adversarial examples via frequency distortion against fault diagnosis systems [EAAI] | [Paper]
- Generating transferable adversarial examples for speech classification [Pattern Recognition] | [Paper]