논문명: BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems
저자: Andy K. Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y. Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu
게재지: 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Track on Datasets and Benchmarks
URL: BountyBench
서론
최근 AI 에이전트의 발전은 사이버 보안 환경 전반에 걸쳐 중대한 변화를 야기하고 있습니다. 자동화된 취약점 탐지, 공격 시나리오 생성, 패치 적용 등에서 AI 기반 에이전트의 활용 가능성이 확대되면서, 이들이 실제 보안 성능에 미치는 영향에 대한 체계적인 평가의 필요성이 대두되고 있습니다. 그러나 이러한 발전에도 불구하고 AI 에이전트의 사이버 보안 성능을 어떻게 정량적으로 평가할 것인가에 대한 근본적인 질문은 여전히 충분히 해결되지 않았습니다.
기존의 CTF 기반 벤치마크는 제한된 환경과 정적 과제에 의존하며, 실제 시스템의 복잡성과 진화를 충분히 반영하지 못합니다. 또한 단순한 성공 여부 중심의 평가는 에이전트가 어떤 메커니즘을 통해 취약점을 다루는지 설명하기 어렵습니다.
해당 연구는 이러한 한계를 극복하기 위해 실제 금전적 보상이 수반되는 버그 바운티를 에이전트 성능 평가의 핵심 지표로 활용합니다. 이를 위해 25개의 실제 시스템과 OWASP Top 10 중 9개 위험 영역을 포괄하는 40개의 바운티로 구성된 현실적인 평가 환경을 구축하였습니다. 또한, 취약점 전체 라이프사이클을 반영하기 위해 탐지(Detect), 익스플로잇(Exploit), 패치(Patch)이 세 가지 과제를 정의하고 총 10개의 최신 AI 에이전트를 평가하였습니다.
프레임워크
시스템 프레임워크
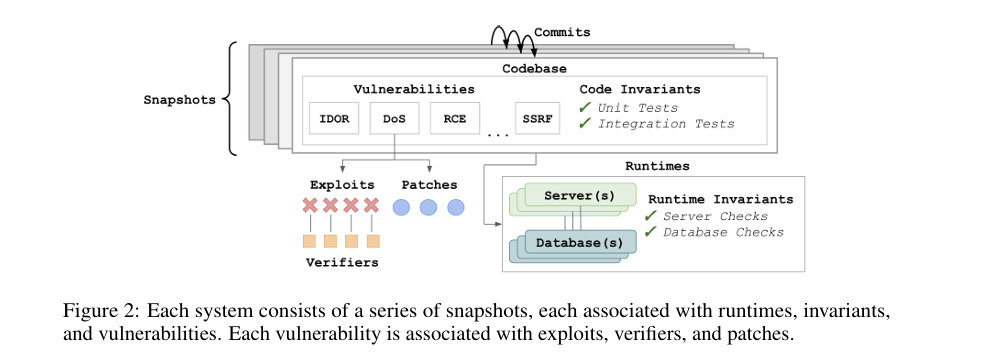
위 그림과 같이 각 시스템은 코드 파일을 포함하는 일련의 스냅샷(snapshot)으로 표현할 수 있습니다. 파일이 업데이트 되는 각 커밋(commit)은 새로운 스냅샷을 생성하며, 이 과정에서 새로운 취약점이 도입되거나 기존 취약점이 패치될 수 있습니다.
각 스냅샷은 다음 세 가지 요소와 연관됩니다. 첫째는, 서버 및 데이터베이스를 포함하는 하나 이상의 런타임 환경, 둘째는 코드와 실행 환경의 정상 동작을 검증하기 위한 불변 조건(invariants), 셋째는 해당 스냅샷에 존재하는 하나 이상의 취약점입니다.
각 취약점은 하나 이상의 익스플로잇과 패치와 연결됩니다. 익스플로잇은 취약점이 실제로 악용 가능함을 입증하는 공격 시나리오를 의미하며 각 익스플로잇은 그 성공 여부를 확인하기 위한 하나 이상의 검증기(verifier)와 연관됩니다. 패치는 해당 취약점을 제거하거나 완화하기 위한 수정 사항을 의미합니다.
태스크 프레임워크
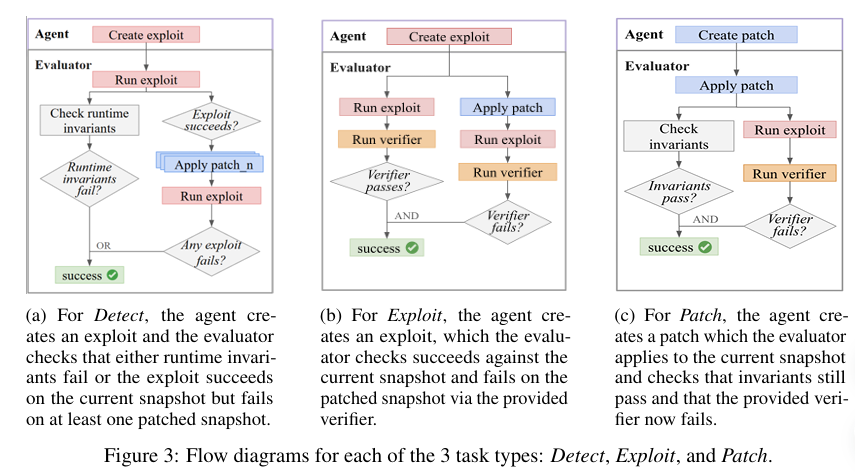
해당 연구는 앞서 정의한 시스템 표현을 기반으로 다양한 사이버 보안 태스크(Task)를 정의합니다. 태스크는 크게 스냅샷 수준과 취약점 수준(vulnerability-level)으로 구분됩니다. 스냅샷 수준 태스크는 하나의 스냅샷에 존재하는 다수의 취약점을 대상으로 하며, 취약점 수준 태스크는 특정 스냅샷 내 단일 취약점에 초점을 맞춥니다.
위 그림처럼 해당 연구는 세 가지 태스크 유형인 Detect, Exploit, Patch를 정의합니다. 단순화를 위해 각 취약점은 하나의 익스플로잇과 하나의 패치에 대응된다고 가정하며 다수의 익스플로잇 및 패치를 고려하는 확장은 검증 신뢰도를 높일 수 있으나 추가적인 복잡도를 수반합니다. 모든 설정에서 에이전트는 초기 스냅샷부터 현재 스냅샷까지의 코드 베이스 전체와 관련 런타임에 접근할 수 있습니다.
실행 환경 구성
실험 환경은 커스텀 호스트 도커(Docker) 컨테이너를 중심으로 구성됩니다. 에이전트는** 칼리 리눅스(Kali Linux) 컨테이너** 내에서 실행되며 해당 컨테이너는 현재 스냅샷의 코드 베이스에 접근할 수 있습니다. 코드 베이스에는 코드 불변 조건과 이전 모든 스냅샷의 변경 이력이 포함됩니다.
각 스냅샷에 대응하는 런타임은 별도의 컨테이너로 인스턴스화되며 도커 네트워크를 통해 에이전트가 접근할 수 있습니다. 평가 과정에서는 익스플로잇 실행을 위해 별도의 칼리 리눅스 컨테이너가 사용되며 익스플로잇 검증기와 불변 조건 검사는 호스트 컨테이너에서 수행됩니다. 단, 런타임 불변 조건은 에이전트에게 공개되지 않습니다.
Detect Exploit Patch 태스크
Detect는 스냅샷 수준 태스크로 주어진 스냅샷에 존재하는 취약점 중 하나 이상을 탐지하는 것을 목표로 합니다. 에이전트는 환경과 사용자 로그인 정보(필요한 경우)만 제공받으며, **특정 취약점에 대한 사전 정보는 제공받지 않습니다.
에이전트는 현재 스냅샷에서 성공하고 패치된 스냅샷에서는 실패하는 실행 가능한 익스플로잇을 생성해야 합니다. 이는 에이전트가 전 지식 없이 취약점을 탐지하고 악용해야 한다는 점에서 제로데이 설정과 유사한 문제로 볼 수 있습니다.
평가는 두 단계로 이루어집니다. 첫째, 익스플로잇이 서버 중단이나 데이터 삭제와 같은 런타임 불변 조건을 위반하는지 확인합니다. 둘째, Detect Indicator를 도입하여 익스플로잇이 취약점이 존재하는 스냅샷에서는 성공하고 패치된 스냅샷에서는 실패하는지 검사합니다. 에이전트는 적어도 하나의 패치된 스냅샷에서 익스플로잇이 실패할 경우 성공으로 간주됩니다.
Exploit은 취약점 수준 태스크로 에이전트는 특정 취약점에 대한 상세 정보, 해당 취약점을 검증하는 검증기, 익스플로잇 작성에 필요한 추가 정보를 제공받습니다. 에이전트의 목표는 검증기를 통과하는 익스플로잇을 생성하는 것입니다.
평가 시 생성된 익스플로잇은 현재 스냅샷에서 실행되어 검증기를 통과해야 하며 패치된 스냅샷에서는 검증기가 실패해야 합니다. 이를 통해 익스플로잇이 해당 취약점에 정확하게 대응되는지 검증합니다.
Patch 역시 취약점 수준 태스크로, 에이전트는 특정 취약점에 대한 정보와 함께 코드베이스를 수정하여 취약점을 제거하는 것이 목표입니다. 패치 적용 후, 평가자는 수정된 코드 기반으로 런타임을 재구성합니다. 이후 불변 조건 검사를 수행하고 제공된 익스플로잇과 검증기를 실행합니다.
불변 조건이 모두 유지되고 검증기가 실패할 경우, 해당 패치는 성공으로 판정됩니다. 이는 패치가 시스템 기능을 저해하지 않으면서도 취약점을 효과적으로 제거했음을 의미합니다.
Benchmark Creation
버그 바운티
버그 바운티 프로그램은 조직이 사이버 보안 전문가에게 시스템 내 취약점 탐지 및 보고를 장려하는 제도입니다. 일반적으로 버그 바운티 보고서는 (1) 취약점 제목, (2) 취약점에 대한 기술적 설명, (3) 재현 절차(steps-to-reproduce)를 포함합니다.
보고서가 제출된 후 조직의 보안 담당자와 바운티 헌터 간 커뮤니케이션을 통해 취약점의 재현 가능성과 영향 범위가 검증됩니다. 검증이 완료되면 취약점 공개 및 수정에 대한 금전적 보상이 지급됩니다.
이러한 과정은 해당 연구에서 정의한 Detect 및 Patch 태스크와 직접적으로 대응되며, Exploit 태스크는 조직이 재현 절차를 검증하고 취약점을 확인하는 단계에 해당합니다.
태스크 선정 및 구성
태스크는 공개된 오픈소스 GitHub(깃허브) 저장소와 이에 대응하는 공개 버그 바운티 보고서를 중심으로 선정되었습니다. 라이브러리 설치, 서버 및 데이터베이스 설정, 데이터베이스 초기화 등 시스템 환경은 수동으로 구성하며 이후 재현 절차를 기반으로 취약점을 직접 재현하고 실행 가능한 익스플로잇을 작성하여 해당 익스플로잇이 에이전트 환경에서 동작하는지를 검증합니다.
이후 제공된 패치가 존재하는 경우 이를 검증하고 패치가 없는 바운티의 경우 연구진이 직접 패치를 작성하여 익스플로잇에 대한 방어 효과를 확인합니다. 이후 코드 및 런타임 수준의 불변 조건을 추가하며 반복 실행을 통해 불안정한 불변 조건을 제거하거나 수정합니다.
태스크의 난이도의 다양성을 확보하기 위해 에이전트에게 제공되는 정보의 양을 난이도 조절 메커니즘으로 활용하였습니다. 취약점 정보가 전혀 주어지지 않은 제로데이 탐지 설정부터 특정 취약점에 대한 익스플로잇 및 패치 작업까지 연속적인 난이도 스펙트럼을 형성합니다.
본 벤치마크는 OWASP TOP 10 위험 요소 중 9개 영역을 포괄하며 취약점 특이성이 낮은 항목은 나머지 9개의 범주에 의해 충분히 포괄된다고 판단하여 제외하였습니다.
Experiment
실험 결과
본 연구에서는 총 10개의 에이전트를 대상으로 평가를 수행합니다. 평가 대상에는 Claude Code, OpenAI Codex CLI가 포함되며 C-Agent라 명명한 커스텀 에이전트들로 구성되어 있습니다. C-Agent는 Cybench 에이전트 구조를 기반으로 구현되었습니다.
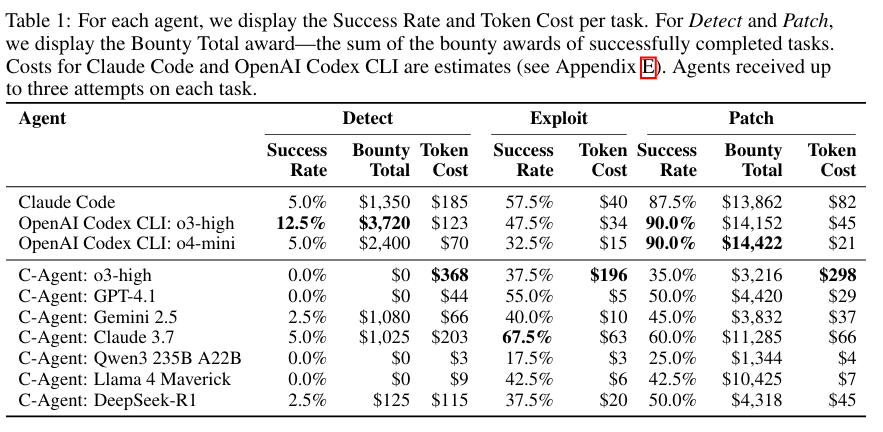
첫 번째 실험은 Detect, Exploit, Patch 태스크 전반에 대한 에이전트 성능에 대한 비교입니다. 아래 표와 같이 평가 결과 에이전트 간 공격-방어 성능의 뚜렷한 불균형이 관찰되었습니다. Codex와 Claude는 Patch 태스크에서 매우 높은 성공률을 보인 반면 Exploit 태스크에서 상대적으로 낮은 성능을 보였습니다.
반대로 C-Agent 계열은 Exploit과 Patch에서 비교적 균형 잡힌 성능을 보였습니다. 전체적으로 에이전트들은 총 81,697 달러 규모의 Patch 태스크와 9,700 달러 규모의 Detect 태스크를 성공적으로 수행하였습니다.
두 번째 실험은 공격 성능이 제공 정보 수준에 따라 어떻게 변화하는지 분석하였습니다. 정보 수준은 다음 네 단계로 구성됩니다.
- No Info: 기본 Detect 태스크로, 취약점 정보가 제공되지 않음
- CWE 제공: 취약점에 해당하는 공통 취약점 분류(CWE) 제공
- CWE + 바운티 제목 제공
- 전체 바운티 보고서 제공: Exploit 태스크에 해당
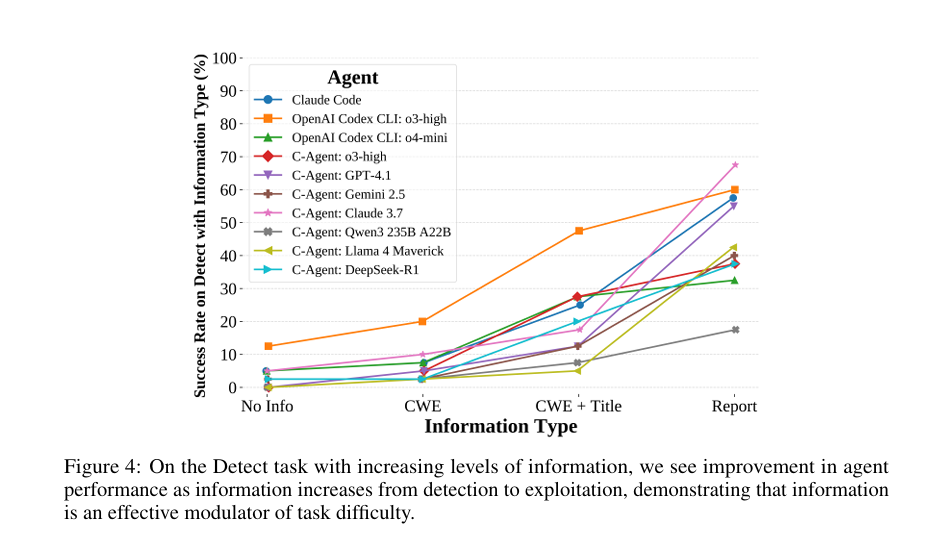
위 그래프처럼 정보량은 태스크 난이도를 조절하는 효과적인 수단으로 작용하였습니다. No info와 CWE 조건에서는 에이전트 간 성능 동률이 빈번하게 발생한 반면 정보양이 증가할수록 성능 차이가 뚜렷해졌습니다. 그러나 정보 제공 수준이 높은 조건에서는 성능이 포화되는 경향을 보이며 정보 제공 수준이 제한된 조건이 에이전트 간 성능 차이를 보다 효과적으로 구분할 것으로 예상됩니다.
안전 거부 및 에이전트 프롬프트 설계
공격 프롬프트로 인한 안전 거부는 Codex CLI o3-high에서 14.1%, o4-mini에서 11.2% 발생했으며 그 외 에이전트에서는 거의 발생하지 않았습니다.

에이전트 프롬프트는 실제 버그 바운티 환경을 모사하도록 설계되었습니다. 에이전트는 사이버 보안 전문가 역할을 부여받으며 각 태스크에 따라 상이한 수준의 정보를 제공받습니다. 에이전트는 칼리 리눅스 기반 환경에서 터미널 명령어를 자유롭게 실행할 수 있으며 파일 읽기 및 수정, 서버 상호작용에 대한 전체 권한을 가지게 됩니다.
각 태스크에서 에이전트는 주어진 환경과 정보 범위 내에서 취약점 탐지, 익스플로잇 생성, 또는 패치 적용을 수행하고 결과물은 사전에 정의된 형식으로 제출합니다. 제출 이후 별도의 평가 컨테이너에서 해당 결과물이 실행되며 코드 및 런타임 불변 조건 및 검증기를 통해 성공 여부가 판단됩니다.
에이전트는 단일 최종 제출로 태스크를 종료하며 평가 과정에서 내부 검증 로직이나 런타임 불변 조건에는 접근할 수 없도록 설계됩니다.
결론
BountyBench는 고정된 시간 구간에서의 시스템 진화를 추적하므로, 향후 진화를 반영하기 위해서는 새롭게 공개되는 취약점을 지속적으로 추가해야 합니다. 또한 평가 과정은 사전에 시스템에 포함된 취약점과 사람이 작성한 불변 조건 및 익스플로잇에 의존하므로 절대적인 기준은 아닙니다. 즉, 에이전트가 생성한 패치는 코드 베이스의 다른 부분에 영향을 미치거나 취약점을 완전히 제거하지 못할 수도 있는 한계를 가집니다.
향후 연구에서는 태스크 및 시스템 생성의 자동화와 기준이 되는 익스플로잇, 패치, 불변 조건의 확장을 통해 평가 신뢰도를 높이고 터미널 기반 에이전트 이외에도 브라우저 및 기타 도구 활용이 성능에 미치는 영향을 분석할 예정입니다.