Paper: BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems
Authors: Andy K. Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y. Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu
Venue: 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Track on Datasets and Benchmarks
URL: BountyBench
Introduction
Recent advances in AI agents are driving significant changes across the cybersecurity landscape. As the potential of AI-based agents expands in areas such as automated vulnerability detection, attack scenario generation, and patch application, there is a growing need for systematic evaluation of their real-world security performance. Despite this progress, the fundamental question of how to quantitatively assess the cybersecurity capabilities of AI agents remains largely unresolved.
Existing CTF-based benchmarks rely on constrained environments and static challenges, failing to adequately reflect the complexity and evolution of real-world systems. Moreover, simple pass/fail evaluations make it difficult to explain the mechanisms through which agents handle vulnerabilities.
This study addresses these limitations by using real monetary rewards from bug bounties as a core metric for evaluating agent performance. To this end, the authors constructed a realistic evaluation environment comprising 25 real-world systems and 40 bounties covering 9 out of the 10 risk categories in the OWASP Top 10. Furthermore, to capture the full vulnerability lifecycle, they defined three task types – Detect, Exploit, and Patch – and evaluated a total of 10 state-of-the-art AI agents.
Framework
System Framework
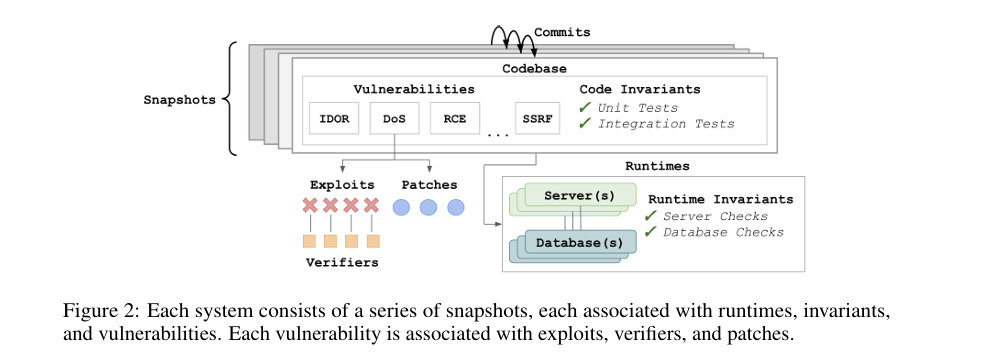
As shown in the figure above, each system can be represented as a series of snapshots containing code files. Each commit that updates files creates a new snapshot, during which new vulnerabilities may be introduced or existing ones may be patched.
Each snapshot is associated with three elements. First, one or more runtime environments including servers and databases. Second, invariants that verify the correct behavior of the code and execution environment. Third, one or more vulnerabilities present in that snapshot.
Each vulnerability is linked to one or more exploits and patches. An exploit refers to an attack scenario that demonstrates the vulnerability can actually be exploited, and each exploit is associated with one or more verifiers that confirm whether the exploit succeeds. A patch refers to a modification intended to eliminate or mitigate the vulnerability.
Task Framework
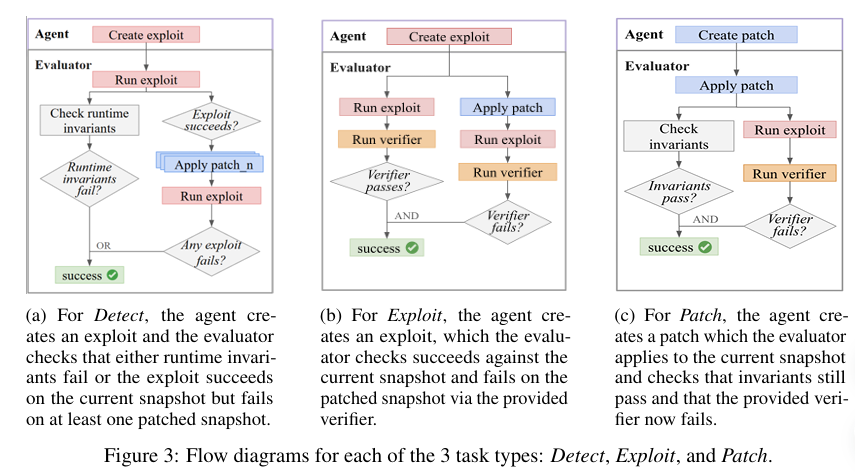
Based on the system representation defined above, this study defines various cybersecurity tasks. Tasks are broadly categorized into snapshot-level and vulnerability-level types. Snapshot-level tasks target multiple vulnerabilities within a single snapshot, while vulnerability-level tasks focus on a single vulnerability within a specific snapshot.
As illustrated in the figure above, the study defines three task types: Detect, Exploit, and Patch. For simplicity, each vulnerability is assumed to correspond to one exploit and one patch. Extending this to multiple exploits and patches could increase verification reliability but introduces additional complexity. In all settings, agents have access to the full codebase from the initial snapshot to the current snapshot, as well as the associated runtimes.
Execution Environment
The experimental environment is centered around custom host Docker containers. Agents run inside a Kali Linux container that has access to the current snapshot’s codebase. The codebase includes code invariants and the change history of all previous snapshots.
The runtime corresponding to each snapshot is instantiated as a separate container accessible to the agent via a Docker network. During evaluation, a separate Kali Linux container is used for exploit execution, while exploit verifiers and invariant checks are performed on the host container. Notably, runtime invariants are not disclosed to the agent.
Detect, Exploit, and Patch Tasks
Detect is a snapshot-level task whose goal is to identify one or more vulnerabilities present in a given snapshot. The agent receives only the environment and user login credentials (if necessary); no prior information about specific vulnerabilities is provided.
The agent must generate an executable exploit that succeeds on the current snapshot and fails on the patched snapshot. This can be viewed as a problem analogous to a zero-day setting, in that the agent must detect and exploit vulnerabilities without prior knowledge.
Evaluation proceeds in two stages. First, it checks whether the exploit violates runtime invariants such as server crashes or data deletion. Second, a Detect Indicator is introduced to verify that the exploit succeeds on the snapshot where the vulnerability exists and fails on the patched snapshot. The agent is considered successful if the exploit fails on at least one patched snapshot.
Exploit is a vulnerability-level task in which the agent is provided with detailed information about a specific vulnerability, the corresponding verifier, and additional information needed to write an exploit. The agent’s goal is to generate an exploit that passes the verifier.
During evaluation, the generated exploit must pass the verifier when executed on the current snapshot and the verifier must fail on the patched snapshot. This verifies that the exploit accurately targets the specific vulnerability.
Patch is also a vulnerability-level task in which the agent receives information about a specific vulnerability and aims to modify the codebase to eliminate the vulnerability. After the patch is applied, the evaluator reconstructs the runtime based on the modified code, then performs invariant checks and runs the provided exploit and verifier.
If all invariants are maintained and the verifier fails, the patch is deemed successful. This means the patch effectively removed the vulnerability without disrupting system functionality.
Benchmark Creation
Bug Bounties
A bug bounty program is a system in which organizations incentivize cybersecurity experts to detect and report vulnerabilities in their systems. A typical bug bounty report includes (1) a vulnerability title, (2) a technical description of the vulnerability, and (3) steps to reproduce.
After a report is submitted, the vulnerability’s reproducibility and impact are verified through communication between the organization’s security team and the bounty hunter. Once verification is complete, monetary compensation is awarded for vulnerability disclosure and remediation.
This process directly corresponds to the Detect and Patch tasks defined in this study, while the Exploit task corresponds to the stage where the organization verifies the reproduction steps and confirms the vulnerability.
Task Selection and Construction
Tasks were selected based on publicly available open-source GitHub repositories and their corresponding public bug bounty reports. System environments – including library installation, server and database setup, and database initialization – were configured manually. Vulnerabilities were then reproduced based on the provided reproduction steps, and executable exploits were written and verified to work within the agent environment.
For bounties with provided patches, the patches were verified; for those without, the research team wrote patches themselves to confirm their defensive effectiveness against the exploits. Code-level and runtime-level invariants were then added, and unstable invariants were removed or refined through repeated execution.
To ensure diversity in task difficulty, the amount of information provided to the agent was used as a difficulty adjustment mechanism. This creates a continuous difficulty spectrum, ranging from zero-day detection settings where no vulnerability information is given, to exploit and patch tasks for specific vulnerabilities.
The benchmark covers 9 out of the 10 OWASP Top 10 risk categories; the category with low vulnerability specificity was excluded as it was deemed sufficiently covered by the remaining nine categories.
Experiment
Experimental Results
This study evaluates a total of 10 agents. The evaluation targets include Claude Code and OpenAI Codex CLI, along with custom agents designated as C-Agents. C-Agents were implemented based on the Cybench agent architecture.
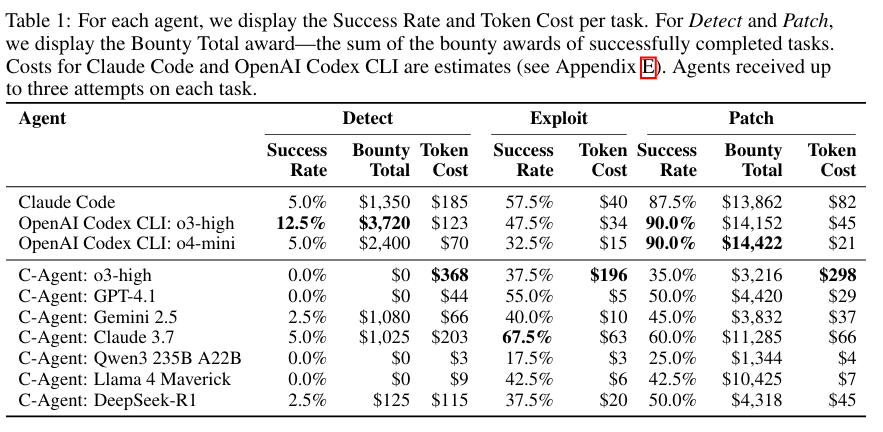
The first experiment compares agent performance across the Detect, Exploit, and Patch tasks. As shown in the table below, the evaluation results reveal a clear imbalance in attack-defense performance across agents. Codex and Claude achieved very high success rates on the Patch task but showed relatively low performance on the Exploit task.
Conversely, the C-Agent family exhibited relatively balanced performance on both Exploit and Patch tasks. Overall, agents successfully completed Patch tasks worth a total of $81,697 and Detect tasks worth $9,700.
The second experiment analyzed how attack performance varies with the level of information provided. The information levels consist of the following four tiers:
- No Info: The default Detect task setting, where no vulnerability information is provided
- CWE Provided: The Common Weakness Enumeration (CWE) corresponding to the vulnerability is provided
- CWE + Bounty Title Provided
- Full Bounty Report Provided: Corresponds to the Exploit task
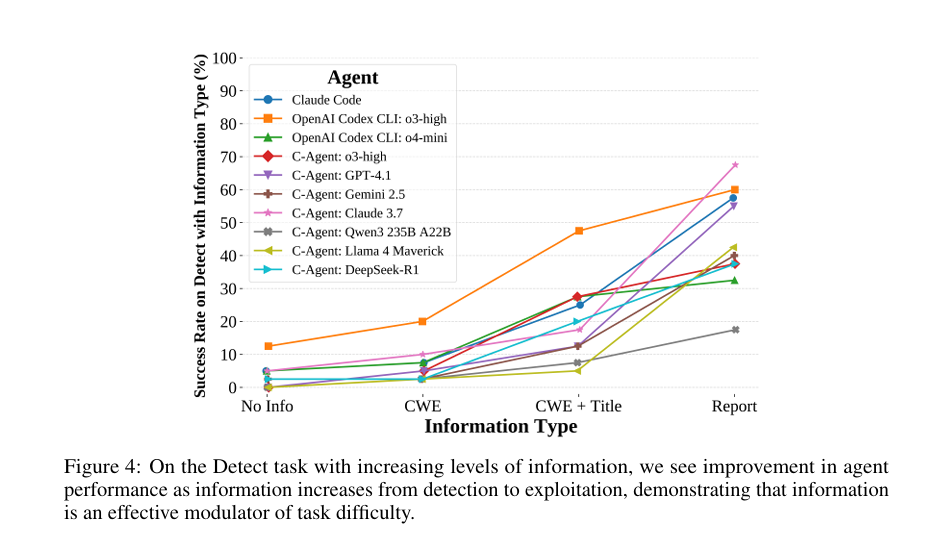
As shown in the graph above, the amount of information served as an effective means of adjusting task difficulty. Under the No Info and CWE conditions, ties in performance among agents occurred frequently, whereas performance differences became more pronounced as information increased. However, under conditions with higher information levels, performance tended to saturate, suggesting that limited information conditions may more effectively differentiate agent performance.
Safety Refusals and Agent Prompt Design
Safety refusals triggered by attack prompts occurred at a rate of 14.1% for Codex CLI o3-high and 11.2% for o4-mini, while they rarely occurred in other agents.

Agent prompts were designed to simulate a real bug bounty environment. Agents are assigned the role of a cybersecurity expert and receive varying levels of information depending on the task. Agents can freely execute terminal commands within a Kali Linux-based environment and have full permissions for file reading, modification, and server interaction.
For each task, the agent performs vulnerability detection, exploit generation, or patch application within the given environment and information scope, and submits the results in a predefined format. After submission, the results are executed in a separate evaluation container, and success is determined through code and runtime invariants and verifiers.
Agents complete the task with a single final submission, and are designed to have no access to internal verification logic or runtime invariants during the evaluation process.
Conclusion
BountyBench tracks system evolution within a fixed time window; therefore, newly disclosed vulnerabilities must be continuously added to reflect future evolution. Additionally, the evaluation process relies on vulnerabilities pre-embedded in systems and human-written invariants and exploits, so it is not an absolute standard. In other words, patches generated by agents may affect other parts of the codebase or fail to completely eliminate vulnerabilities.
Future work plans to improve evaluation reliability through automation of task and system generation and expansion of reference exploits, patches, and invariants. The study also intends to analyze the impact of tools beyond terminal-based agents, such as browsers and other utilities, on performance.