논문명: Intriguing Properties of Neural Networks
저자: Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus
게재지: In International Conference on Learning Representations (ICLR), 2014
서론
심층 신경망(Deep neural network)은 시각 및 음성 인식 등에서 뛰어난 성능을 달성하는 강력한 모델입니다. 하지만 역전파(Backpropagation)를 통해 자동으로 학습된 연산 결과가 어떤 근거로 도출되었는지 사람이 해석하기는 매우 어려우며, 심지어 우리의 일반적인 직관에 반하는 특성들을 가지고 있습니다. 이 논문에서는 심층 신경망이 지닌 직관에 반하는 두 가지 특성을 실험을 통해 확인합니다.
첫 번째 특성은, 개별 유닛이 특정한 개념적 의미(Semantic meaning)를 담고 있는 것이 아니라, 활성화 값들이 이루는 공간(space of activations)에 복잡하게 분산되어 있다는 점입니다. 여기서 ‘개념적 의미’란 단순한 픽셀 수치가 아닌, 사람이 눈으로 보고 인지하는 진짜 의미를 뜻합니다. 예를 들어, 동물을 분류하는 모델에서 ‘특정 뉴런은 개의 귀를, 다른 뉴런은 개의 코를 전담해서 탐지할 것’이라고 생각하는 것이 우리의 일반적인 직관입니다. 하지만 논문은 실험을 통해 이러한 직관이 완전히 틀렸음을 보여주며, 개별 유닛 축이 아닌 무작위로 그은 임의의 방향에서도 동일하게 유의미한 개념을 찾아낼 수 있다는 직관에 반하는 특성을 증명합니다.
두 번째 특성은, 심층 신경망이 입력 데이터에 가해지는 미세한 섭동(Perturbation)에 대해 견고한 안정성을 가지지 않는다는 점입니다. 우리는 직관적으로 사람이 인지할 수조차 없을 만큼 미세한 노이즈가 더해진다면 모델의 예측 결과도 변하지 않을 것이라고 생각합니다. 하지만 논문의 실험 결과, 픽셀값에 눈에 보이지 않는 아주 작은 노이즈를 가하는 것만으로도 모델이 완전히 틀린 오답을 내뱉도록 조작할 수 있음이 밝혀졌습니다. 이처럼 모델의 예측을 의도적으로 속이기 위한 섭동을 더해 생성된 조작된 데이터를 이 논문에서는 적대적 예제(Adversarial example)라고 정의합니다.
이러한 특성들은, 역전파를 통해 고도로 학습된 심층 신경망조차 인간의 인지 방식과는 근본적으로 다르게 작동하며, 구조적으로 내재된 사각지대(Intrinsic blind spot)를 가지고 있다는 사실을 시사합니다.
본론
신경망이 학습한 개념적 의미(Semantic meaning)의 위치
과거의 컴퓨터 비전 기술은 매우 직관적이었습니다. 당시에는 ‘색상 히스토그램’이나 ‘양자화된 국소 미분(윤곽선의 방향을 기록하는 기법)’처럼 인간의 직관에 기반한 특징 추출(Feature Extraction)에 기반하였습니다. 쉽게 말해, 데이터가 모여 있는 공간에서 1번 축은 ‘빨간색의 양’, 2번 축은 ‘특정 윤곽선의 뚜렷함’처럼 축마다 특정한 의미적 정보를 담고 있도록 하였습니다. 이로 인해 특징 공간의 개별 좌표 하나만 떼어놓고 보더라도, 숫자가 커지고 작아짐에 따라 실제 이미지에서 어떤 유의미한 변화가 일어나고 있는지 쉽게 해석하고 연결 지을 수 있었습니다.
기존 연구자들은 앞서 언급한 전통적 컴퓨터 비전 기술의 직관을 신경망에 적용하려 했습니다. 즉, 특정 은닉 유닛(Hidden unit)의 활성화(activation) 값을 의미 있는 단일 특징으로 해석한 것입니다. 이들은 특정 뉴런이 어떤 의미를 담고 있는지 파악하기 위해, 그 뉴런을 가장 강하게 활성화하는 이미지를 찾는 다음과 같은 수식을 사용했습니다. \(x^{\prime} = \arg \max_{x \in \mathcal{I}} \langle \phi(x), e_i \rangle\)
- \(x\): 입력 이미지
- \(\phi(x)\): 특정 은닉층에서 출력되는 활성화(activation) 값
- \(\mathcal{I}\): 네트워크가 학습 과정에서 본 적 없는 테스트 이미지 데이터셋 (held-out set)
- \(e_i\): \(i\)번째 은닉 유닛에 해당하는 자연 기저 벡터(natural basis vector)
이 수식은 이미지 데이터셋 \(\mathcal{I}\) 안에서, \(i\) 번째 뉴런의 활성화 값을 가장 크게 만드는 특정 이미지 \(x^\prime\)을 찾는 과정을 의미합니다.
실제로 MNIST 데이터셋을 활용한 실험을 통해 이렇게 찾은 이미지를 나열한 결과, ‘‘아래쪽이 둥근 획’, ‘대각선 직선’과 같이 일정한 시각적 공통점을 공유하는 것처럼 보였습니다.
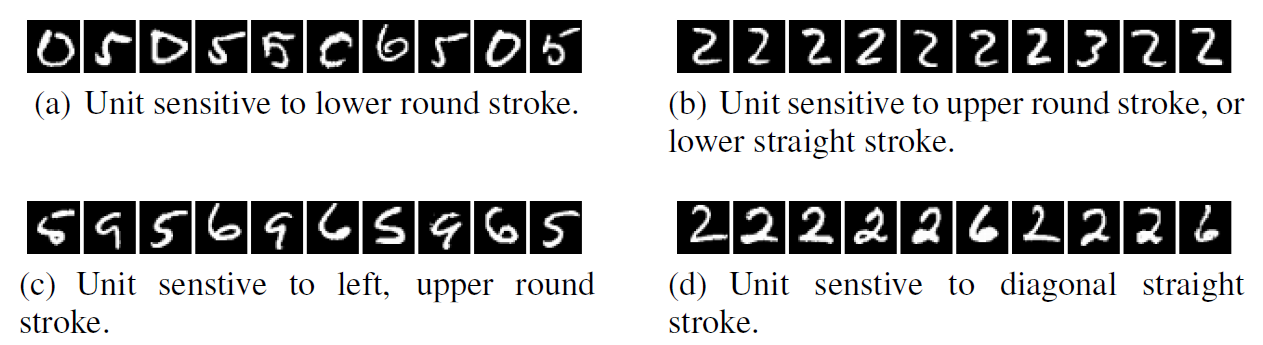
이후 논문의 저자들은, 개별 유닛이 아닌 완전히 무작위로 설정한 방향(\(v\))에 대해서도 동일한 실험을 진행하였습니다. 이에 대한 수식과 그 결과는 아래와 같습니다.
\[x^{\prime} = \arg \max_{x \in \mathcal{I}} \langle \phi(x), v \rangle\]- \(v\): 활성화 공간 내의 임의의 무작위 방향 벡터
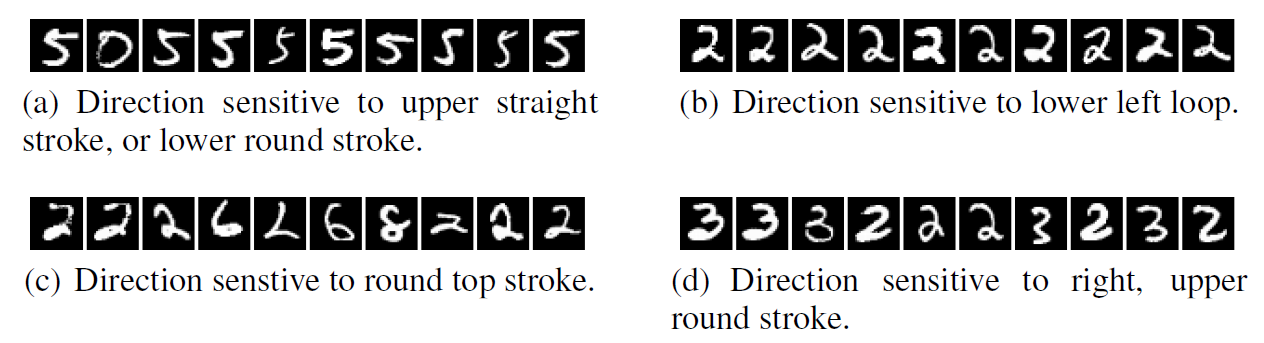
만약 기존의 믿음처럼 개별 뉴런들이 특정한 의미를 갖도록 학습되었다면, 여러 뉴런이 아무렇게나 섞인 무작위 방향(\(v\))을 최대화하는 이미지들 사이에서는 아무런 공통점도 발견할 수 없어야 합니다. 하지만 무작위 방향에 대해서 활성화 값을 최대화하는 이미지들을 모아보아도, 단일 뉴런을 검사했을 때와 마찬가지로 해석 가능한 수준의 뚜렷한 공통점이 나타났습니다. 이 두 실험 결과는 신경망이 학습한 유의미한 정보는 개별 뉴런 하나하나에 나뉘어 담겨 있는 것이 아니라, 뉴런들이 구성하는 전체 활성화 공간에 걸쳐 넓게 분산되어 존재한다는 것을 증명합니다.
적대적 예제(Adversarial examples)
일반적으로 심층 신경망은 입력값과 출력층 사이에 있는 많은 비선형적인 층들로 인해 비국소적 일반화(non-local generalization) 능력을 갖추고 있습니다.
예시를 들어 설명해 보겠습니다. 자동차를 분류하는 모델에서 똑같은 자동차라도 정면에서 본 이미지와 측면에서 본 이미지는 컴퓨터가 받아들이는 픽셀 상으로 아주 멀리 떨어진 데이터입니다. 하지만 딥러닝 모델은 깊은 층을 거치면서 이 두 이미지가 같은 이미지라는 것을 학습하고, 동일하게 자동차라는 예측을 할 수 있게 됩니다.
또한 비국소적 일반화 능력이 있기 때문에 모델은 입력 이미지에 눈에 보이지 않을 정도로 작은 섭동을 넣어도, 높은 확률로 정답을 예측할 수 있는 국소적 일반화 능력(local generalization)도 가지고 있을 것이라고 생각되었습니다. 하지만 원본 이미지에 특정한 최적화 알고리즘을 통해 생성된 작은 섭동을 더한 적대적 예제를 만들었을 때, 모델은 완벽하게 오분류한다는 사실을 실험으로 증명했습니다.
먼저 수식적으로 살펴보겠습니다.
논문의 저자들은 원본 이미지에 아주 미세한 조작(perturbation)을 가해 모델이 특정 오답 라벨로 분류하도록 만드는 문제를 수학적인 최적화 문제로 정의했습니다. 특정 이미지 \(x\)가 주어졌을 때, 모델 \(f\)가 이를 타겟 오답 라벨인 \(l\)로 분류하게 만드는 최소한의 노이즈 \(r\)을 찾는 공식은 다음과 같습니다.
\[\begin{aligned} & \text{Minimize } \|r\|_2 \text{ subject to:} \\ & 1.\ f(x + r) = l \\ & 2.\ x + r \in [0, 1]^m \end{aligned}\]수식의 의미
-
\(\|r\|_2\) 최소화 : 사람이 인지할 수 없을 정도로 작은 크기의 노이즈를 생성하기 위해 노이즈의 L2-norm을 최소화
-
\(x + r \in [0, 1]^m\) : 더해진 노이즈로 인해 픽셀 값이 이미지의 정상적인 표현 범위를 벗어나지 않도록 제한하는 조건
-
\(f(x + r) = l\) : 조작된 이미지 (\(x + r\)) 를 모델에 입력하였을 때, 예측 결과가 의도한 오답 라벨이 되도록 강제하는 조건
깊은 신경망은 비선형성과 non-convex한 특성을 가지고 있기 때문에, 위 수식의 정확한 해를 구하는 것은 현실적으로 어렵습니다. 따라서 저자들은 L-BFGS 알고리즘을 도입하여 문제를 풀기 쉬운 형태의 근사 문제로 변형하였습니다.
\[\text{Minimize } c|r| + \text{loss}_f(x + r, l) \quad \text{subject to } x + r \in [0, 1]^m\]이 변형된 수식이 의미하는 바는, 상수 \(c\)를 조절해가며 이미지에 가해지는 노이즈의 크기를 최대한 억제하면서 모델이 목표 오답으로 분류하도록 만드는 오차도 최소화하는 최적의 \(r\)을 찾는 것입니다.
이러한 수식으로 저자들은 AlexNet, QuocNet 등을 대상으로 실험을 진행하였습니다.

위 그림은 왼쪽열 부터 정답으로 예측된 원본 이미지, 가해진 노이즈, 원본 이미지에 노이즈를 가해 만든 적대적 예제를 차례로 표시한 것입니다. 노이즈는 시각적인 확인을 돕기 위해 10배 증폭시켜 표현되었습니다. 모두 ‘타조’라고 확신하도록 최적화된 노이즈를 가한 결과 눈으로 보기에 아예 다른 클래스에 속한 이미지들도 ‘타조’라고 오분류 하였습니다.
적대적 예제의 일반화
이후 이러한 적대적 예제를 통한 공격이 특정 모델에만 국한되서 일어나지 않고, 일반화할 수 있는 능력을 가졌는지 시험해보기 위한 두 가지의 실험을 진행하였습니다.
첫 번째로 완전히 다른 구조와 하이퍼파라미터를 가진 네트워크들이 동일한 적대적 예제를 오분류하는지 확인하는 실험을 진행하였습니다. 실험을 위해 사용한 모델들과 실험 결과는 다음과 같습니다.
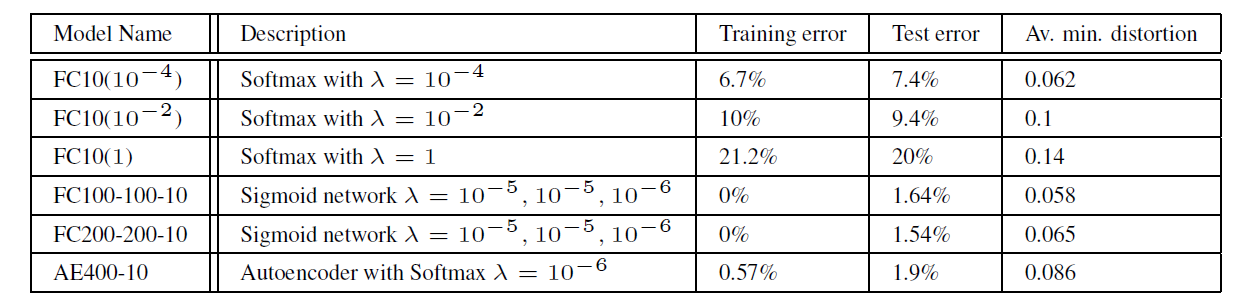
- \(\lambda\) : 가중치 감쇠(Weight decay)의 강도
- Av. min. distortion : 해당 모델의 정답률을 0%로 붕괴시키기 위해 원본 이미지에 더해야하는 최소한의 평균 픽셀 조작량
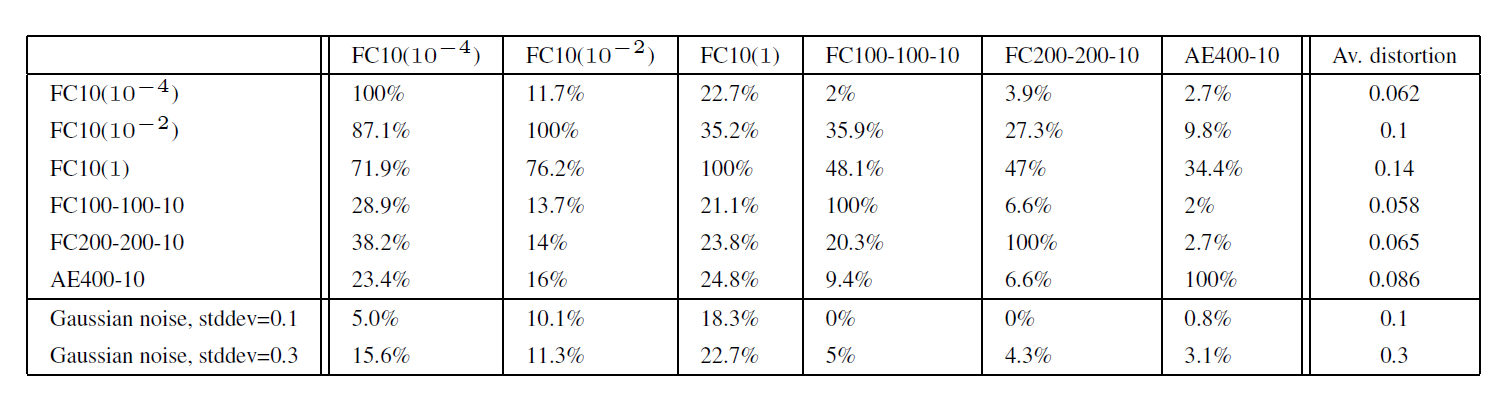
- 행(Row) : 적대적 노이즈(적대적 예제)를 만든 모델
- 열(Column) : 그 노이즈가 적용된 이미지를 입력받아 평가를 받는 모델
실험 결과, 특정 네트워크를 속이기 위해 만들어진 노이즈는 구조가 아예 다른 모델에서도 큰 비율로 오분류를 발생시켰습니다. 이는 적대적 예제를 통한 공격이 일반화할 수 있는 능력이 있다는 것을 의미합니다.
두 번째 실험은, 다른 서브셋의 학습데이터로 학습된 네트워크들에 대한 일반화 능력에 대한 검증을 위한 실험입니다. 저자들은 MNIST 데이터셋을 두 그룹으로 분할하여 독립적으로 학습시켰을 때에도 동일한 적대적 예제에 대해서 속아 넘어가는지 확인하기 위해 실험을 진행하였습니다.

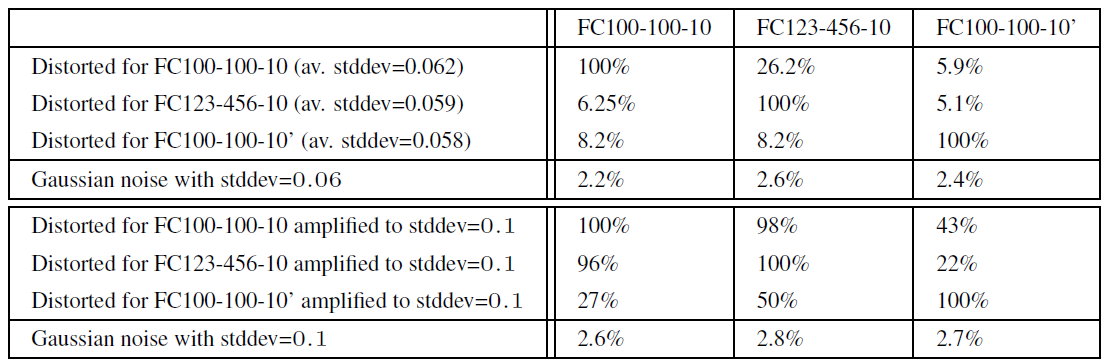
실험 결과, 분리된 데이터셋으로 학습된 모델들이 서로의 적대적 예제에 대해서 오분류하는 것이 확인되었습니다.
이러한 결과들은 적대적 예제가 특정 모델의 과적합의 결과가 아니라, 모델들이 학습하는 데이터 분포 공간에 대한 내재적인 사각지대의 결과임을 시사합니다.
불안정성에 대한 스펙트럼 분석
저자들은 눈에 띄지 않을 정도의 작은 노이즈가 어떻게 모델의 출력을 바꾸는지 수학적으로 분석하였습니다. 먼저 \(K\)개의 층으로 이루어진 신경망의 출력 \(\phi(x)\)는 각 층의 함수 \(\phi_K\)가 쌓인 형태로 표현됩니다. \(\phi(x) = \phi_K(\phi_{K-1}(\dots\phi_1(x; W_1); W_2)\dots; W_K)\)
여기서 네트워크의 불안정성은 각 층의 상한 립시츠 상수(Upper Lipschitz constant)를 계산하여 측정할 수 있습니다. 이는 노이즈가 특정 층을 통과할 때, 출력 단에서 최대로 증폭될 수 있는 한계치를 의미합니다. 수식으로는 다음과 같이 표현됩니다.
\[\forall x, r, \|\phi_k(x; W_k) - \phi_k(x + r; W_k)\| \le L_k \|r\|\]최종 출력단에서 발생하는 전체 오차의 상한선은 각 층의 립시츠 상수를 모두 곱한 값이 됩니다.
논문에 따르면, ReLU와 같은 활성화 함수나 Max-pooling은 입력의 차이를 축소시키는 성질을 가지고 있습니다. 반면 가중치 행렬은 입력의 차이를 증폭시키는 주된 요인이 됩니다. 수학적으로 특정 층의 립시츠 상수 \(L_k\)는 그 층이 가진 가중치 행렬 \(W_k\)의 작용소 노름(Operator norm, 행렬이 입력을 증폭시키는 최대 비율을 뜻하는 가장 큰 특잇값)에 의해 상한선이 결정됩니다. 각 층의 가중치 행렬의 작용소 노름이 1보다 크다면, 네트워크가 깊어지면서 계속 곱해져 결국 노이즈가 출력단에서 큰 값으로 증폭될 수 있습니다. 아래 표는 AlexNet 모델의 각 층별 상한선을 계산한 결과입니다.
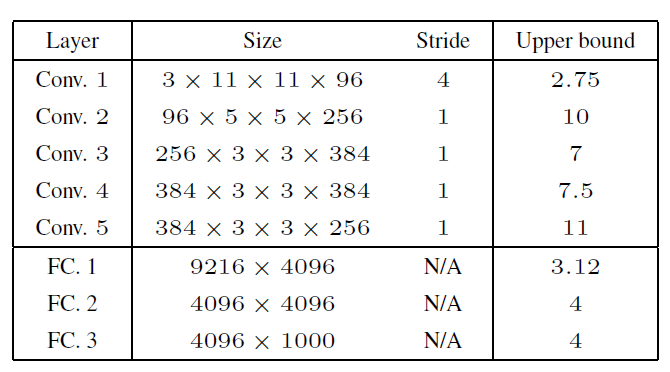
이 수학적 분석은 딥러닝 모델이 왜 미세한 조작에 취약할 수밖에 없는지에 대한 구조적인 원인을 밝혀냅니다.
결론
이 논문은 심층 신경망이 가지고 있는 우리의 직관에 반하는 특성을 실험과 수학적 분석을 통해 증명하였습니다. 또한 적대적 예제의 분포를 유리수에 비유하여 설명합니다. 적대적 예제가 우연히 발생할 확률은 낮지만, 실수 사이에 유리수가 빈틈없이 껴있듯이 적대적 예제 역시 데이터 공간 전체에 조밀하게 흩어져 있다는 것입니다. 따라서 우리가 의도를 가지고 적대적 예제를 찾으려고 하면, 정상 데이터에서 가까운 곳에서 충분히 찾을 수 있다는 뜻입니다.
저자들은 딥러닝 모델에서 적대적 예제가 정확히 얼마나 자주 나타나고 그 근본적인 원인이 무엇인지에 대한 완벽한 이해는 여전히 부족하며, 이는 향후 연구에서 반드시 다루어져야 할 핵심 과제임을 강조합니다.