Paper: Obfuscated Gradients Give a False Sense of Security
Authors: Anish Athalye, Nicholas Carlini, David Wagner
Venue: Proceedings of the 35th International Conference on Machine Learning (ICML 2018)
Introduction
This paper points out that existing defense techniques against adversarial examples fail to provide substantial protection, and presents attack methods that circumvent each defense technique.
Existing defense techniques appear to succeed in defending by relying on the Obfuscated Gradient phenomenon, which makes gradients unclear. However, the authors argue that this cannot serve as a fundamental defense.
The authors classify three types of Obfuscated Gradients and propose circumvention attack techniques for each type. Furthermore, they conducted verification on nine defense techniques published at ICLR 2018, revealing that seven of them relied on Obfuscated Gradients.
Main Discussion
Existing adversarial attack techniques have effectively generated adversarial examples through iterative optimization using gradients. Subsequent studies proposed various defense techniques and claimed their effectiveness, but the authors of this paper argue that these defense techniques merely rely on the Obfuscated Gradient phenomenon that makes gradients unclear, rather than being genuine defense techniques.
Obfuscated Gradients
Obfuscated Gradients are classified into the following three types.
1. Shattered Gradient Shattered Gradient refers to the phenomenon where a defense technique makes gradients either impossible to compute (non-differentiable) or inaccurate during the optimization process of generating adversarial examples. This phenomenon can occur unintentionally even when the defense technique uses only differentiable operations, and manifests when gradient-based attacks fail to push the classification loss to its global maximum.
2. Stochastic Gradient Stochastic Gradient refers to the phenomenon where gradients fluctuate probabilistically due to randomized defense techniques. Some defense techniques inject randomness into the neural network architecture or randomly transform input images, which causes the gradients computed by the attacker through backpropagation to also vary randomly. As a result, it becomes difficult to accurately estimate the true gradients needed for adversarial example generation.
3. Vanishing/Exploding Gradient Vanishing/Exploding Gradient occurs when a defense technique has a structure that performs neural network computations iteratively. When an attacker tries to compute gradients in such a model, the iterative computation loop must be unrolled, which is equivalent to computing gradients through a very deep neural network. During this process, gradient values are continuously multiplied, causing them to either converge to zero or grow to extreme values.
Identifying Obfuscated Gradients
How can we determine whether a particular defense technique merely appears successful due to the Obfuscated Gradient phenomenon? The paper presents five characteristics of defense techniques that exploit the Obfuscated Gradient phenomenon.
- One-step attacks perform better than iterative optimization-based attacks
- Black-box attacks perform better than white-box attacks
- When there are no constraints on the perturbation, the attack fails to achieve 100% success rate
- Randomly sampled noise is found to be adversarial
- When relaxing perturbation constraints, there is no improvement in attack success rate
If even one of these characteristics is observed, there is a very high probability that the defense technique in question is inducing the Obfuscated Gradient phenomenon.
Attack Techniques
The authors propose attack techniques to circumvent defense methods that exhibit each of the three types of Obfuscated Gradients.
Backward Pass Differentiable Approximation To circumvent defense techniques that exploit the Shattered Gradient phenomenon – that is, defenses that use non-differentiable operations to make gradients difficult to compute – the authors propose a method called Backward Pass Differentiable Approximation (BPDA). This approach works as follows: when a non-differentiable layer \(f^i(\cdot)\) exists within the neural network, it finds a differentiable approximation function \(g(x)\) that produces results similar to \(f^i(\cdot)\) in order to compute gradient values (\(g(x) \approx f^i(x)\)). The appropriate approximation function must be found for each specific attack technique. After finding the approximation function, the forward pass proceeds with the original function \(f^i(\cdot)\), while only the backward pass uses the approximation function to compute gradients.
Expectation over Transformation To circumvent the Stochastic Gradients phenomenon caused by randomly transforming inputs or injecting randomness into the neural network structure, the authors propose a method called Expectation over Transformation (EOT). The core idea of this approach is to optimize the expectation over the various possible random transformations. Mathematically, when a random transformation \(t(x)\) sampled from a transformation distribution \(T\) is applied to a model \(f(x)\), EOT optimizes \(\mathbb{E}_{t \sim T} f(t(x))\), the expectation over all transformations. The derivative of this expectation is mathematically identical to the expectation of the derivatives. Expressed as a formula: \(\nabla \mathbb{E}_{t \sim T} f(t(x)) = \mathbb{E}_{t \sim T} \nabla f(t(x))\)
In other words, by first computing gradients individually for each state where a random transformation has been applied and then averaging (taking the expectation of) those gradients, the accurate gradient direction can be determined.
Reparameterization A model that includes a defense function \(g(\cdot)\) which internally runs multiple optimization loops to refine the input can be expressed as \(f(g(x))\). \(g(\cdot)\) refines the input into a desired form, but when computing gradients of \(f(g(x))\) through backpropagation for adversarial example generation, the gradients either vanish or explode. To circumvent such defense techniques, the authors propose a method called Reparameterization.
The authors find a new differentiable transformation function \(h(\cdot)\) that substitutes the original image into a latent space \(z\), such that \(x = h(z)\), instead of differentiating through \(g(x)\). This function is designed to satisfy the following condition:
\[g(h(z)) = h(z)\]What this equation means is that when the function \(g(\cdot)\) projects an input onto a specific manifold, \(h(z)\) is designed to output values that already lie on that manifold from the start. This allows finding optimal gradients by differentiating \(f(h(x))\) during backpropagation, thereby circumventing the defense technique.
Case study
Using the methods proposed above, the authors attempted to circumvent nine state-of-the-art defense techniques published at ICLR 2018. The results are shown in the following table.
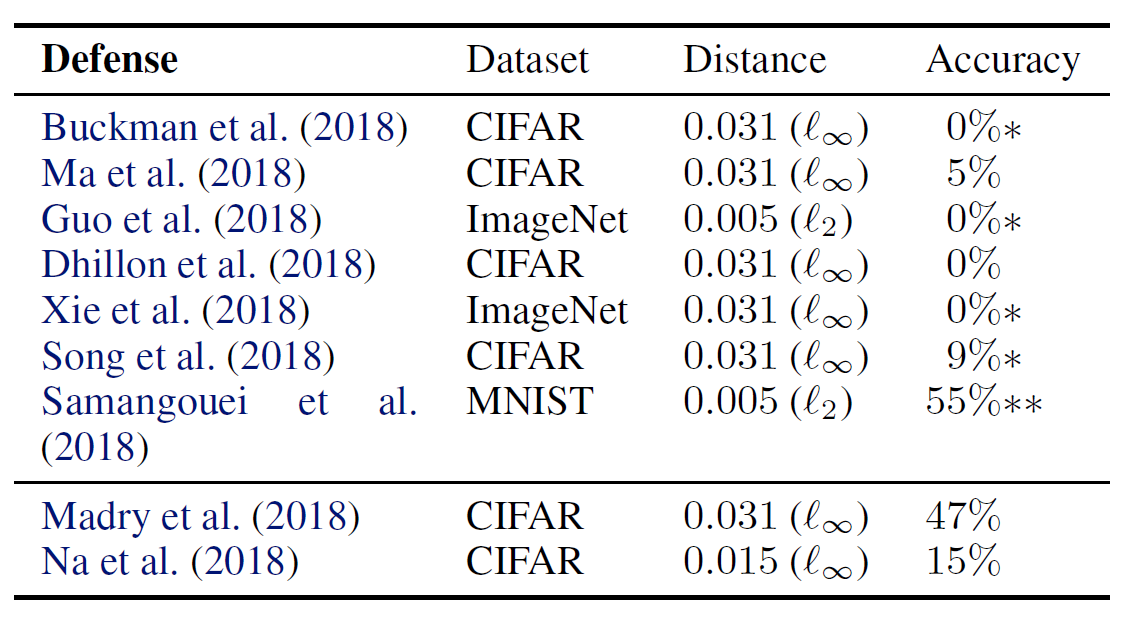
- The Accuracy column on the far right of the table represents the rate at which the defense model correctly classified inputs after the circumvention attack – that is, the final surviving defense rate.
- Single asterisk (* ): These defense techniques were proposed in their original papers to be used in combination with adversarial training, but in this table, only the standalone defense capability was evaluated, excluding other factors.
- Double asterisk (**): In principle, the accuracy should drop to 0% (fully broken), but due to imperfections in the optimization process during the actual attack, the theoretically perfect attack failed, leaving some residual defense accuracy.
Looking at the table, we can see that 7 out of 9 defense methods relied on the Obfuscated Gradient phenomenon, and their defenses were completely defeated by the circumvention techniques.
Non-obfuscated Gradients The two defense techniques at the bottom of the table are methods that did not rely on the Obfuscated Gradient phenomenon – that is, the circumvention techniques failed against them.
First, the defense approach proposed by Madry et al. (2018) is a min-max game style adversarial training method that optimizes to generate the most threatening adversarial examples while simultaneously minimizing the model’s loss against those most threatening adversarial examples. Since this approach is not a defense technique based on the Obfuscated Gradient phenomenon, it could not be defeated by the attack techniques proposed in this paper.
The technique by Na et al. first trains a first model, then generates adversarial examples through iterative attacks and adds them to the training dataset, and trains a second model based on this expanded dataset. During this process, a unified embedding technique is applied that forces the logits of original images and adversarial examples to be similar to each other.
This approach also does not rely on the Obfuscated Gradient phenomenon, but since the original authors had already conservatively measured their defense accuracy against strong optimization-based attacks, the circumvention attacks in this paper could not push the defense below the originally claimed level.
Excluding these two methods, all seven other defense techniques were completely defeated in this paper. The paper describes in detail how all seven defense techniques were broken, but in this post, we will examine one case for each of the three types of gradient obfuscation, looking at the principle of the defense technique and how it was defeated.
Gradient Shattering A representative example of an attack exhibiting this phenomenon is the defense method using Thermometer encoding. When a model processes digital images, it treats pixel color values as continuous real numbers between 0 and 1. Previous research revealed that this linear characteristic makes models vulnerable to adversarial attacks, and the authors who use this defense technique convert real numbers between 0 and 1 into discrete \(l\)-dimensional vectors.
For example, when a pixel value of 0.66 comes in, it is converted into a discrete vector like “1111110000” on a 10-bin scale. Using this method, the floor operation creates discontinuities where values are cut off rather than smoothly connected, making the function mathematically non-differentiable. Therefore, the Gradient Shattering phenomenon occurs, and the defense appears to succeed against adversarial attacks.
In this paper, to address the Gradient Shattering phenomenon, the previously introduced BPDA approach was used to create a differentiable approximation function during backpropagation to compute gradients, dropping the accuracy against adversarial examples to 0% and neutralizing the defense technique.
Stochastic Gradients One technique that attempted to defend against adversarial attacks by introducing randomness inside the AI model is the defense technique using the SAP (Dhillon et al.) method. The authors of that paper found that by probabilistically dropping neuron values to zero (deactivating them) at each layer during inference, the gradients come out differently each time during the optimization process of generating adversarial attacks.
To counter this Stochastic Gradients phenomenon, this paper estimated gradients by computing the Expectation over Transformation. At each iteration step of gradient descent, instead of taking a step in the direction of a single gradient, the step is taken in the direction of the expectation. Using this method, the accuracy against adversarial examples was dropped to 0% in an environment with a maximum allowed perturbation of \(\epsilon = 0.031\).
Vanishing & Exploding Gradients Defense-GAN (Samangouei et al., 2018) is a defense technique that utilizes GANs. The core idea is to project an image onto the manifold of clean images before feeding it to the classifier. Since adversarial examples are located slightly off this manifold, projecting them back onto the manifold should remove the adversarial perturbation. Defense-GAN uses the GAN’s Generator to define this manifold. Given an input image, it solves an optimization problem to find the closest point on the manifold. Because this process involves iterative optimization loops, when an attacker attempts to compute gradients for generating adversarial examples, the gradients either converge to zero or explode.
The authors of this paper used the Reparameterization technique to bypass this deep optimization loop by substituting the original image with a latent space \(z\). In essence, they created adversarial examples that already exist on the manifold. Specifically, they directly constructed adversarial examples expressed in the form \(x'=G(z)\) but satisfying \(c(x) \neq c(x')\). Since such examples already exist on the manifold, they pass through the projection process without modification and are delivered to the classifier.
Additionally, there was a problem that the gradient descent-based optimization process used by Defense-GAN to project images was imperfect and could not perfectly preserve points on the manifold. To address this, the authors additionally used the BPDA technique to replace the complex projection process with a simple approximation function.
As a result, the authors achieved a 45% attack success rate against Defense-GAN, and noted that the defense did not completely collapse to 0% thanks to the imperfect implementation of the defense technique itself.
Conclusion
This paper demonstrated that several previously proposed defense techniques against adversarial examples had in fact been relying on the Obfuscated Gradients phenomenon, which merely created the appearance of successful defense. The authors analyzed cases employing such vulnerable defense approaches and presented techniques to neutralize them. Furthermore, the paper provides guidelines on the requirements that future defense techniques should meet.
First, defenders should establish a realistic and clear threat model and precisely specify what information the attacker has access to. Second, the defense technique should be concrete and experimentally verifiable. Third, adaptive attacks that could circumvent the defense technique should be devised and used to attempt to break the defense.
The paper concludes by arguing that only defense techniques meeting all these conditions can be considered genuine defenses against adversarial attacks, and that relying on the Obfuscated Gradients phenomenon must be avoided.