Paper: Proactive Defense Benchmark against Deepfake Generation
Authors: Joonhyuk Baek, Wonjune Seo, Jae-yun Kim, Saerom Park, Hoki Kim
Venue: ICML 2026
Link: ICML 2026 poster page
Introduction
Deepfakes are generative-model-based forgeries of a person’s face, expression, or voice. They sit at the center of a growing class of social harms — political disinformation, non-consensual synthetic media, defamation, identity impersonation — and have become one of the most urgent problems in AI security.
The first wave of countermeasures was post-hoc detection: classifiers that distinguish real from synthetic media after a deepfake has been produced. Detection has been studied broadly, but it is fundamentally reactive — by the time an image is detected, it has typically already circulated, and the social harm has already occurred.
This limitation motivated Proactive Defense, which adds an imperceptible adversarial perturbation to a clean image before the user releases it, so that any deepfake generator that subsequently consumes the image produces an output that is visibly broken or whose identity has been disrupted. Proactive defense aims to prevent the deepfake from being created in the first place — a level of protection that detection alone cannot provide.
The paper, however, raises a critical question:
“Have existing proactive defenses ever been compared fairly?”
Over the past five years, methods such as PGD, Disrupting, DF-RAP, Anti-Forgery, Latent Attack, SCOL, and NullSwap have been proposed under heterogeneous evaluation regimes — different generators, different datasets, different metrics, different post-processing assumptions. As a consequence, no consistent picture exists of which defense works under which threat model.
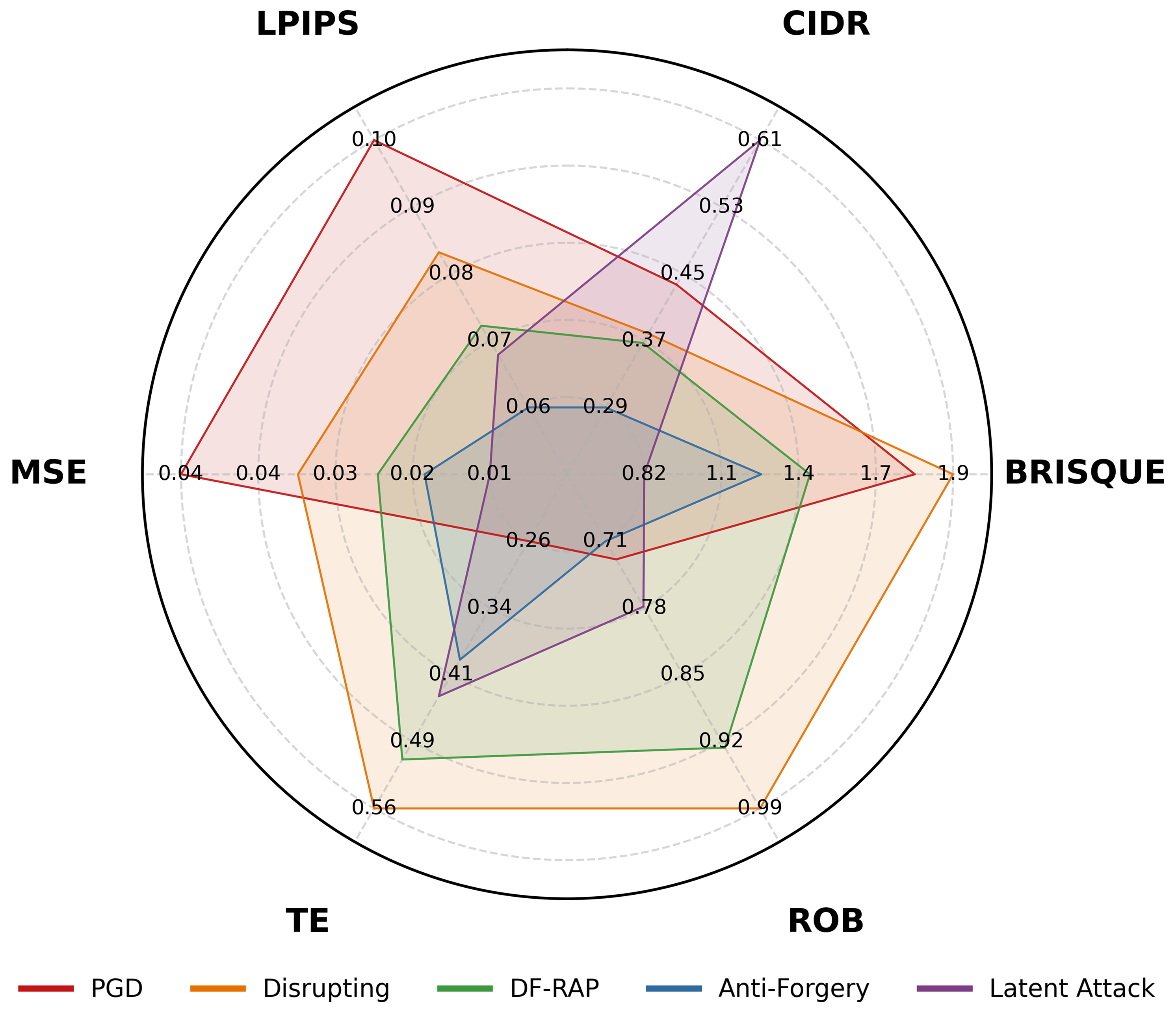
The figure above evaluates five proactive defenses against the same SimSwap pipeline along six metrics. A defense that excels at LPIPS may collapse on ROB; another that wins on MSE may fail on TE. Single-metric evaluation can essentially flip every conclusion.
“Proactive Defense Benchmark against Deepfake Generation”, accepted to ICML 2026, addresses this gap with the first unified benchmark and a new evaluation metric that allow proactive defenses to be compared fairly.
Preliminary
Formalization
The general proactive-defense objective can be written as follows. Let \(\mathbf{x}\) denote a clean image, \(f\) a perturbation function, and \(G\) a deepfake generator:
\[\max_f \; \mathcal{L}\big(G(\mathbf{x}), \, G(f(\mathbf{x}))\big) \quad \text{s.t.} \quad d(\mathbf{x}, f(\mathbf{x})) \le \epsilon.\]The defender maximizes the generator-output divergence \(\mathcal{L}\) subject to a perceptual-distance constraint \(d \le \epsilon\) that keeps the perturbation invisible.
Three Failure Modes
Defenses can disable the generator in three qualitatively different ways:
- Synthesis Disruption — the generator output collapses into unnatural pixel noise, so synthesis itself fails.
- Identity Disruption — the output looks plausible but the identity is no longer the target person.
- Visual Quality Degradation — the output is partially degraded in visual quality without total failure.
These modes correspond to different threat models. Anti-impersonation hinges on Identity Disruption; preventing non-consensual synthesis hinges on Synthesis Disruption.
Four Design Dimensions
The paper organizes existing methods along four axes.
- Access Regime — does the defender have white-box access to the generator, or only black-box access?
- Imperceptibility Constraints — how is the perturbation budget defined, typically through an \(L_p\)-norm such as \(L_\infty\) or \(L_2\).
- Methodology — optimization-based (per-image optimization) versus model-based (a learned generator of perturbations).
- Defense Objective — synthesis disruption versus identity disruption.
These four axes act as the fairness axes in the benchmark: comparing two defenses requires holding access regime, \(\epsilon\), and defense objective constant.
Main Results
Benchmark Overview
The benchmark is structured as a four-stage pipeline: preparation → generation → practical settings → evaluation.
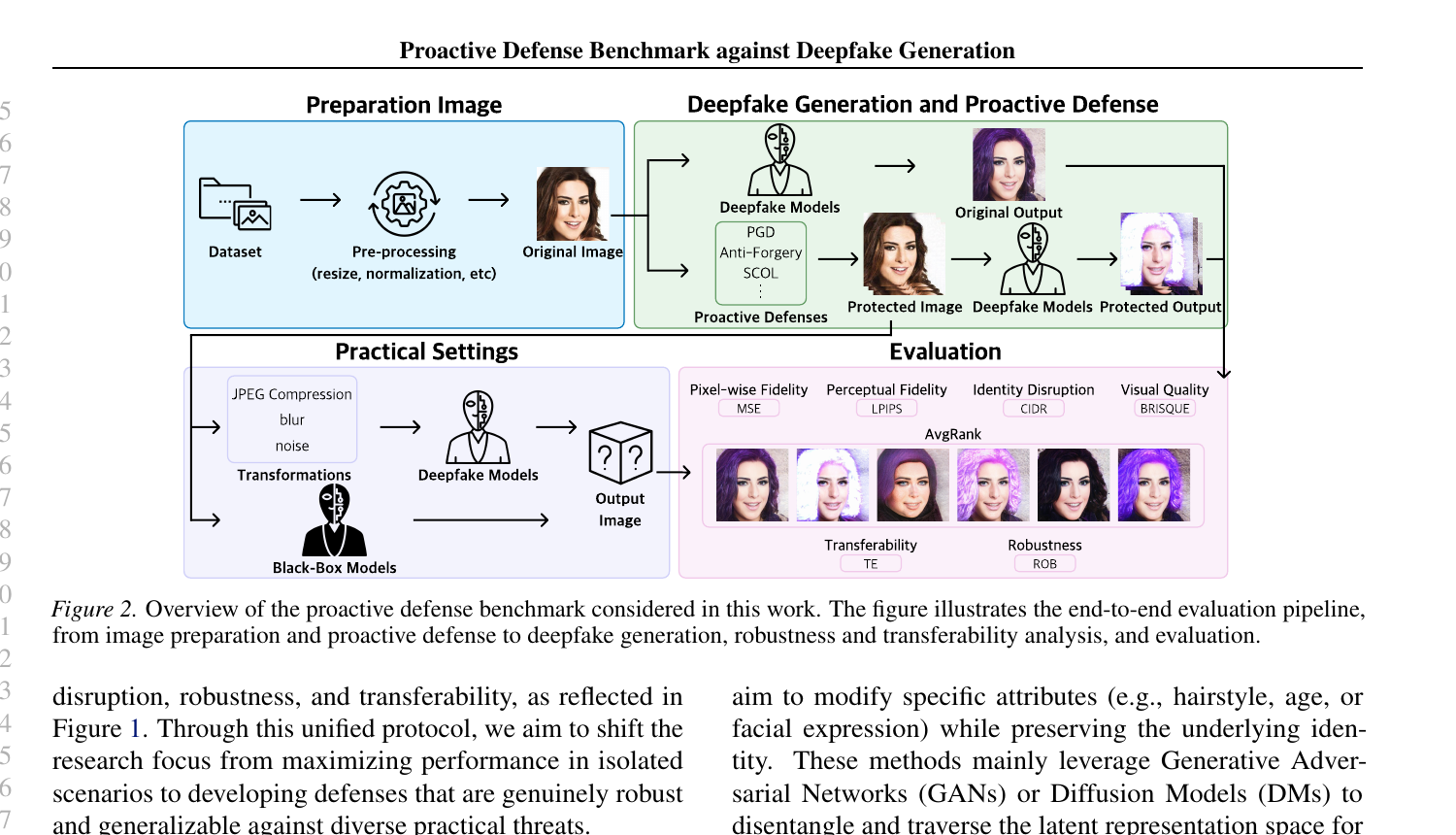
The pivot is the Practical Settings stage. Real-world distribution channels — social media, messaging apps, news outlets — apply JPEG compression, blur, noise, and resizing as a matter of course, and adversaries may also use generators that the defender never saw at design time. Does the defense survive these costs? is the central question of the benchmark.
Decomposing Disruption and Introducing CIDR
The paper rejects single-number disruption scores and decomposes the construct into four orthogonal axes.
| Axis | Metric | Meaning |
|---|---|---|
| Pixel-level Fidelity | MSE | Pixel-space deviation of generator output from baseline |
| Perceptual Fidelity | LPIPS | Perceptual deviation in human-vision-aligned space |
| Identity Disruption | CIDR (new) | Identity disruption normalized for generator-induced bias |
| Visual Quality | BRISQUE | Naturalness of the output image |
The flagship contribution is CIDR — the Calibrated Identity Disruption Ratio. Conventional ID Loss is defined as \(\mathcal{L}_{\text{ID}}(\mathbf{x}, G(\mathbf{x}_{\text{adv}}))\) and conflates two effects: the identity distortion induced by the generator itself, even without any defense, and the additional disruption produced by the defense. As a consequence, what looks like a strong defense may merely reflect a generator that already preserves identity poorly.
The paper normalizes by the no-defense baseline:
\[\mathcal{R}_{\text{ID}}(\mathbf{x}, \mathbf{x}_{\text{adv}}) \;=\; 1 - \frac{\mathcal{L}_{\text{ID}}\!\big(\mathbf{x}, \, G(\mathbf{x}_{\text{adv}})\big)}{\mathcal{L}_{\text{ID}}\!\big(\mathbf{x}, \, G(\mathbf{x})\big)}.\]The denominator is the ID loss already present without defense, so the ratio captures only the additional identity disruption attributable to the defense — a generator-bias-free measure of identity protection.
Robustness and Transferability
Two threats dominate practical settings: post-processing transformations and unseen generators.
Robustness \(\mathcal{R}_{\text{ROB}}\) is the ratio of disruption surviving a transformation \(T\) to disruption without it:
\[\mathcal{R}_{\text{ROB}} \;=\; \frac{\mathcal{D}\!\big(G(T(\mathbf{x}_{\text{adv}}))\big)}{\mathcal{D}\!\big(G(\mathbf{x}_{\text{adv}})\big)},\]where \(\mathcal{D}(\cdot)\) is one of the four disruption axes. The benchmark averages over JPEG 75, Gaussian blur, Gaussian noise, and downscale-upscale — transformations characteristic of social-media distribution.
Transferability \(\mathcal{R}_{\text{TE}}\) measures the retention of effect when a perturbation crafted for source generator \(G_s\) is consumed by an unseen target generator \(G_t\):
\[\mathcal{R}_{\text{TE}} \;=\; \frac{\mathcal{D}_{G_t}\!\big(\mathbf{x}_{\text{adv}}\big)}{\mathcal{D}_{G_s}\!\big(\mathbf{x}_{\text{adv}}\big)}.\]Together, \(\mathcal{R}_{\text{ROB}}\) and \(\mathcal{R}_{\text{TE}}\) are the heart of the benchmark — they ask whether a defense survives outside its design environment.
For aggregate ranking, the paper uses AvgRank, the average rank across all per-axis metrics, to summarize defenses whose strengths trade off across axes.
Experimental Setup
- Dataset: CelebA-HQ, 256×256 resolution.
- Generators: attribute manipulation — StarGAN, StyleCLIP, DiffAE / face swap — pSp-mix, SimSwap, BlendFace.
- Defenses: PGD, Disrupting, DF-RAP, Anti-Forgery, Latent Attack, SCOL, NullSwap.

Key Findings
Across six generators and seven defenses, the paper reports five empirical conclusions.
(1) Defense quality is generator-dependent. Anti-Forgery excels under StarGAN but fails under DiffAE and SimSwap. The best defense for one generator can be the worst for another, so no single ranking is meaningful in isolation.
(2) Robustness and disruption trade off consistently. DF-RAP and Disrupting are robust to post-processing but pay a price in white-box disruption; conversely, defenses with peak white-box performance often collapse under a single JPEG or blur pass.
(3) Transferability is generally low. The retention ratio across source and unseen target generators is frequently below 50%, which means that single-generator evaluation systematically overstates a defense’s generalization potential.
(4) Fidelity and identity metrics are nearly orthogonal. MSE/LPIPS and CIDR exhibit weak Pearson correlation, so a single-axis evaluation cannot capture the true defense profile. Both must be reported.
(5) Peak white-box performance is often a sign of generator-specific overfitting. Perturbations that overfit a single generator transfer poorly and degrade quickly under post-processing.
Conclusion
Proactive defense is a powerful complement to post-hoc deepfake detection, but its progress has been bottlenecked by the absence of a fair evaluation regime. This paper closes that gap by introducing (1) a four-axis decomposition of disruption, (2) the new CIDR metric that removes generator-induced bias, (3) the robustness ratio \(\mathcal{R}_{\text{ROB}}\) and transferability ratio \(\mathcal{R}_{\text{TE}}\), and (4) an AvgRank-based aggregate comparison — yielding the first unified benchmark for the field.
The benchmark prescribes a clear specification for the next generation of proactive defenses: they must be generalizable across diverse generators, robust to post-processing, and imperceptible to humans. Competing on peak white-box performance under a single generator is no longer a meaningful axis of progress. We hope this work provides a solid foundation for proactive defenses that protect society from deepfake-enabled harm at scale.