논문명: Proactive Defense Benchmark against Deepfake Generation
저자: Joonhyuk Baek, Wonjune Seo, Jae-yun Kim, Saerom Park, Hoki Kim
게재지: ICML 2026
링크: ICML 2026 포스터
서론
딥페이크(Deepfake)는 생성형 모델을 활용해 특정 인물의 얼굴·표정·음성을 위조하는 기술을 의미합니다. 정치적 허위 정보, 음란물 합성, 명예훼손, 신원 사칭 등 사회적 위해의 중심에 자리 잡으면서, 인공지능 보안 분야의 가장 시급한 과제 중 하나가 되었습니다.
가장 먼저 등장한 대응책은 사후 탐지(post-hoc detection)입니다. 이미 생성된 딥페이크를 진짜 vs 가짜로 구분하는 분류기 기반 접근으로, 폭넓게 연구되어 왔습니다. 그러나 사후 접근은 본질적 한계를 가집니다. 한 번 합성된 영상이 유포되고 나면, 탐지가 성공하더라도 이미 사회적 피해는 발생합니다.
이러한 한계 인식에서 출발한 것이 사전적 방어(Proactive Defense)입니다. 사용자가 자신의 사진을 공개하기 전에, 사람의 눈에는 보이지 않는 미세 변형(adversarial perturbation)을 가하여, 그 사진을 입력 받은 딥페이크 생성기가 비정상적이거나 정체성이 훼손된 결과를 출력하도록 유도하는 접근입니다. 합성 자체를 사전에 무력화한다는 점에서, 사후 탐지로는 도달할 수 없는 보호 수준을 약속합니다.
그러나 본 논문은 다음과 같은 비판적 질문을 제기합니다.
“기존의 proactive defense들은 정말 공정하게 비교되어 왔는가?”
지난 5년간 PGD, Disrupting, DF-RAP, Anti-Forgery, Latent Attack, SCOL, NullSwap 등 다양한 방어 기법이 제안되어 왔지만, 각자 다른 생성기·다른 데이터셋·다른 지표·다른 후처리 가정 하에서 평가되었습니다. 그 결과 어떤 방어 기법이 어느 시나리오에서 유효한지에 대한 일관된 그림이 부재합니다.
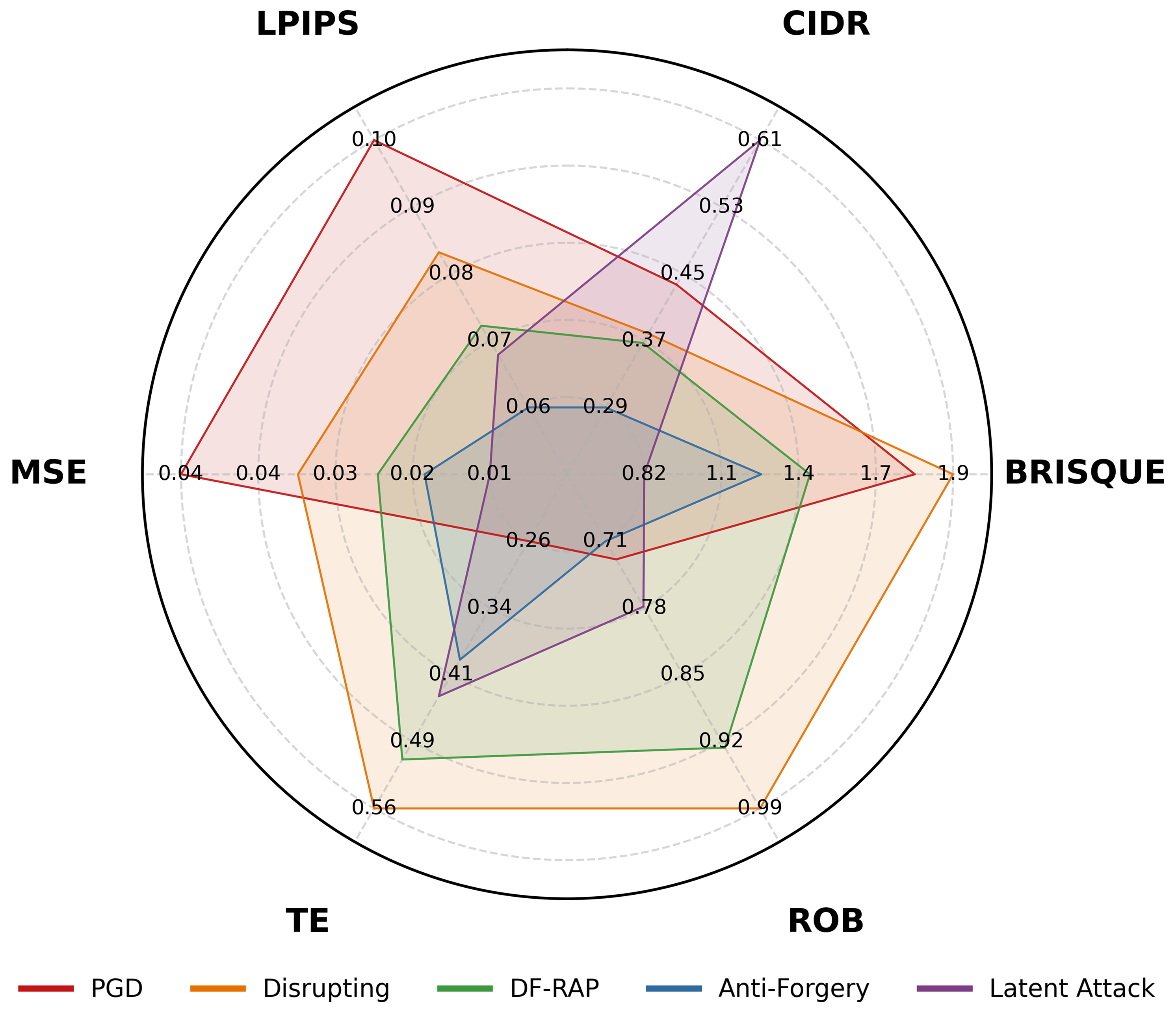
위 그림은 동일한 SimSwap 환경에서 다섯 개의 proactive defense를 6개 지표로 비교한 것입니다. 어떤 방어는 LPIPS에서 우수하지만 ROB(견고성)에서 열위이고, 또 다른 방어는 MSE에서 강하지만 TE(전이성)에서 약합니다. 단일 지표 평가는 사실상 모든 결론을 뒤집을 수 있습니다.
“Proactive Defense Benchmark against Deepfake Generation” 은 본 연구실이 ICML 2026에 채택된 논문이며, 사전적 방어를 공정하게 비교할 수 있는 첫 번째 통합 벤치마크와 신규 평가 지표를 제안합니다.
사전 지식
Proactive Defense의 형식화
사전적 방어의 일반적 목적 함수는 다음과 같이 표현됩니다. 원본 이미지를 \(\mathbf{x}\), 미세 변형 함수를 \(f\), 딥페이크 생성기를 \(G\)라고 할 때:
\[\max_f \; \mathcal{L}\big(G(\mathbf{x}), \, G(f(\mathbf{x}))\big) \quad \text{s.t.} \quad d(\mathbf{x}, f(\mathbf{x})) \le \epsilon.\]즉, 생성기 출력 차이 \(\mathcal{L}\)을 최대화하되, 원본 이미지와의 지각적 거리 \(d\)는 임계값 \(\epsilon\) 이하로 묶어 사람 눈에 보이지 않는 변형이라는 제약을 만족시켜야 합니다.
세 가지 실패 양상
방어가 생성기를 어떻게 무력화하는지에 따라 세 가지 실패 양상으로 분류됩니다.
- Synthesis Disruption — 생성기 출력이 부자연스러운 픽셀 노이즈로 채워져 합성 자체가 실패.
- Identity Disruption — 생성기 출력이 자연스러워 보이지만 대상 인물의 정체성이 훼손.
- Visual Quality Degradation — 합성 결과가 시각 품질만 낮아져 부분적 무력화.
이 세 양상은 각기 다른 사회적 위해 모델에 대응합니다. 사칭(impersonation) 방지는 Identity Disruption이 본질적이고, 음란물 합성 방지는 Synthesis Disruption이 본질적입니다.
네 가지 설계 차원
본 논문은 기존 방어 기법들을 네 차원으로 정리합니다.
- Access Regime — 방어자가 생성기에 화이트박스(white-box)로 접근 가능한가, 블랙박스(black-box)로만 접근 가능한가.
- Imperceptibility Constraints — 변형의 한도. 일반적으로 \(L_p\)-norm(\(L_\infty\), \(L_2\) 등)으로 정의.
- Methodology — 매 이미지마다 최적화하는 최적화 기반(optimization-based)인가, 사전 학습된 모델로 변형을 생성하는 모델 기반(model-based)인가.
- Defense Objective — 합성 disruption을 노리는가, 정체성 disruption을 노리는가.
이 네 차원은 실험에서 공정성의 축으로 작동합니다. 두 방어를 비교하려면 같은 access regime, 같은 \(\epsilon\), 같은 방어 목표 위에서 평가해야 합니다.
본론
벤치마크 설계 개요
본 논문이 제안하는 벤치마크는 준비(preparation) → 생성(generation) → 실용 환경(practical settings) → 평가(evaluation)의 4단계 파이프라인을 갖습니다.
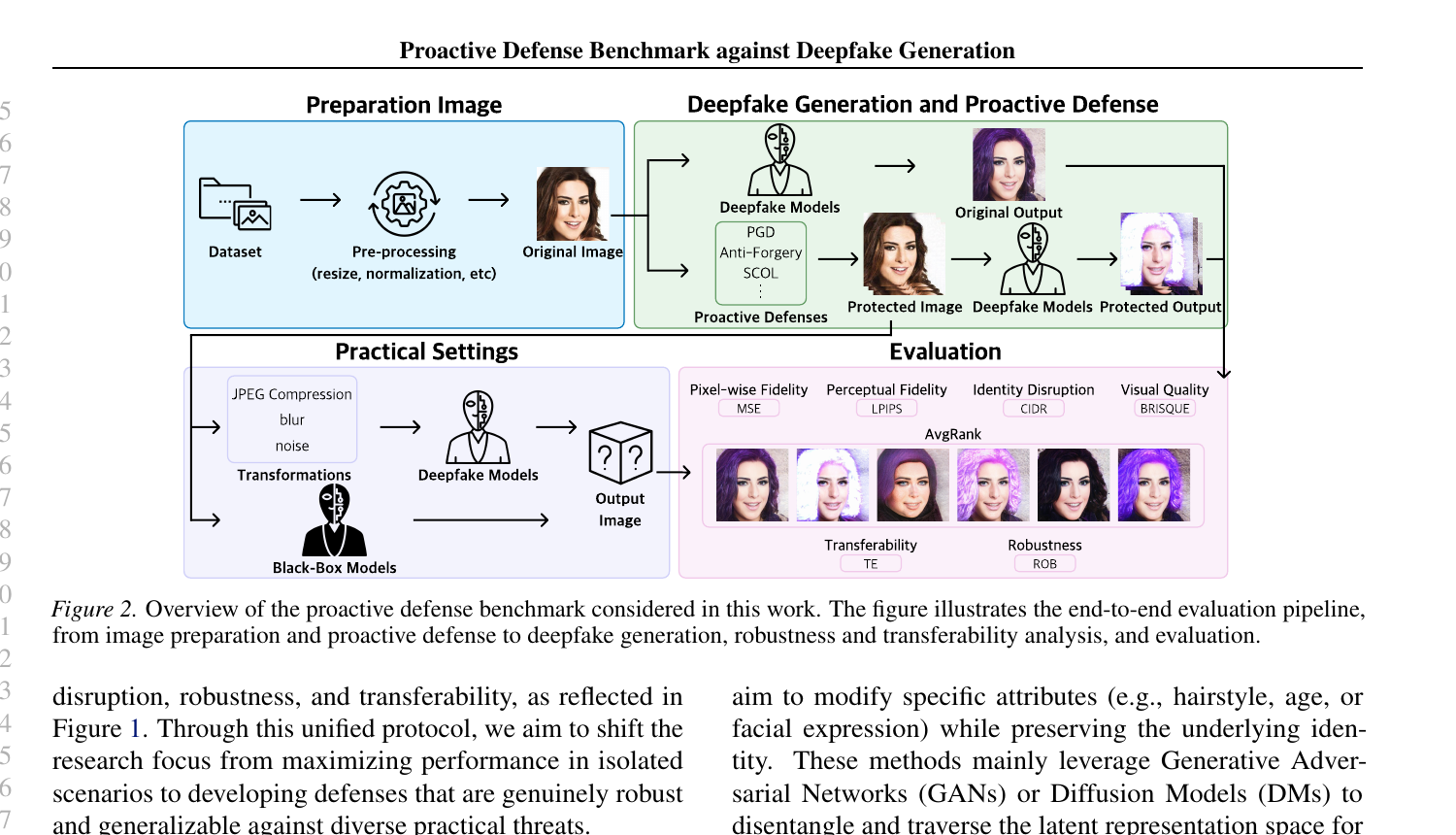
이 파이프라인의 핵심은 실용 환경(Practical Settings) 단계입니다. 실제 SNS·메신저·뉴스 매체를 통해 이미지가 유통될 때는 JPEG 압축, blur, 노이즈, 리사이즈와 같은 후처리가 무수히 가해지며, 공격자가 사용하는 생성기 또한 방어자가 가정한 모델과 다를 수 있습니다. 이 비용을 지불한 뒤에도 방어가 살아남는가?가 본 벤치마크의 핵심 질문입니다.
Disruption의 4축 분해와 CIDR 제안
본 논문은 disruption을 단일 수치로 다루는 기존 관행을 거부하고, 네 개의 직교적 축으로 분해합니다.
| 축 | 지표 | 의미 |
|---|---|---|
| Pixel-level Fidelity | MSE | 픽셀 수준에서 원본 출력과의 차이 |
| Perceptual Fidelity | LPIPS | 지각적(인간 시각 유사) 차이 |
| Identity Disruption | CIDR (신규) | 생성기 자체 왜곡을 보정한 정체성 훼손율 |
| Visual Quality | BRISQUE | 출력 자연스러움(자연 영상 통계 위반도) |
가장 핵심적인 기여는 CIDR(Calibrated Identity Disruption Ratio)입니다. 기존 ID Loss는 \(\mathcal{L}_{\text{ID}}(\mathbf{x}, G(\mathbf{x}_{\text{adv}}))\)로 정의되어 있어, 생성기 \(G\) 자체가 (방어 없이도) 유발하는 정체성 왜곡과 방어 효과를 분리하지 못합니다. 즉 우수한 방어처럼 보이는 결과가 사실은 생성기가 원래부터 정체성을 잘 보존하지 못하는 것일 수 있습니다.
본 논문은 이를 방어 없는 baseline에 대한 상대 비율로 정규화합니다.
\[\mathcal{R}_{\text{ID}}(\mathbf{x}, \mathbf{x}_{\text{adv}}) \;=\; 1 - \frac{\mathcal{L}_{\text{ID}}\!\big(\mathbf{x}, \, G(\mathbf{x}_{\text{adv}})\big)}{\mathcal{L}_{\text{ID}}\!\big(\mathbf{x}, \, G(\mathbf{x})\big)}.\]분모가 방어 없는 정상 합성에서 발생하는 ID 손실이므로, 분자가 분모에 비해 얼마나 더 큰 왜곡을 일으켰는지가 곧 방어가 추가로 만들어낸 정체성 disruption이 됩니다. 이 보정으로 생성기 편향이 제거됩니다.
Robustness와 Transferability
실용 환경의 두 가지 핵심 위협은 후처리 변환(post-processing)과 미관측 생성기(unseen generator)입니다.
Robustness \(\mathcal{R}_{\text{ROB}}\)는 변환 \(T\) 적용 전후의 disruption 효과 비율로 정의됩니다.
\[\mathcal{R}_{\text{ROB}} \;=\; \frac{\mathcal{D}\!\big(G(T(\mathbf{x}_{\text{adv}}))\big)}{\mathcal{D}\!\big(G(\mathbf{x}_{\text{adv}})\big)},\]여기서 \(\mathcal{D}(\cdot)\)는 위에서 정의된 4축 disruption 지표 중 하나입니다. JPEG 75, Gaussian blur, Gaussian noise, downscale-upscale 등 SNS 유통 시나리오에서 흔한 변환을 평균합니다.
Transferability \(\mathcal{R}_{\text{TE}}\)는 source 생성기 \(G_s\)로 만든 protected 이미지를 unseen target 생성기 \(G_t\)가 합성할 때의 효과 보존률입니다.
\[\mathcal{R}_{\text{TE}} \;=\; \frac{\mathcal{D}_{G_t}\!\big(\mathbf{x}_{\text{adv}}\big)}{\mathcal{D}_{G_s}\!\big(\mathbf{x}_{\text{adv}}\big)}.\]이 두 지표는 현실에서 살아남는 방어인지를 묻는 본 벤치마크의 정수입니다.
마지막으로, 다양한 지표의 우열이 엇갈릴 때 종합 순위를 제시하기 위해 AvgRank — 각 지표 순위의 평균 — 를 활용합니다.
실험 설정
- 데이터셋: CelebA-HQ, 256×256 해상도.
- 공격(생성기): 속성 조작 계열 — StarGAN, StyleCLIP, DiffAE / 얼굴 교체 계열 — pSp-mix, SimSwap, BlendFace.
- 방어: PGD, Disrupting, DF-RAP, Anti-Forgery, Latent Attack, SCOL, NullSwap.

핵심 발견
여섯 생성기와 일곱 방어를 횡단 비교한 결과, 본 논문은 다음 다섯 가지 핵심 결과를 보고합니다.
(1) 방어 성능은 생성기에 강하게 의존합니다. 예를 들어 Anti-Forgery는 StarGAN에서 우수하지만 DiffAE와 SimSwap에서는 부진합니다. 어느 한 생성기에서의 최우수 방어가 다른 생성기에서는 최하위가 될 수 있습니다.
(2) Robustness ↑ 일수록 Disruption ↓의 트레이드오프가 일관되게 관측됩니다. DF-RAP와 Disrupting은 후처리에 견고하지만 화이트박스 disruption은 손해를 봅니다. 반대로 화이트박스에서 강력한 방어들은 JPEG·blur 한 번에 효과가 크게 약화됩니다.
(3) Transferability는 전반적으로 낮습니다. Source 생성기와 unseen target 생성기 사이의 효과 보존률은 자주 50% 미만이며, 단일 생성기 평가는 일반화 가능성을 과대평가할 위험이 큽니다.
(4) Fidelity와 Identity 지표는 거의 직교(orthogonal)합니다. MSE/LPIPS와 CIDR 사이의 Pearson 상관은 약하게 나타나, 한 축만 보고서는 방어의 진짜 효과를 가늠할 수 없습니다. 둘 다 보고하는 것이 필수입니다.
(5) 화이트박스에서의 피크 성능은 종종 generator-specific overfitting의 신호입니다. 단일 생성기에 과도하게 적합된 변형은 전이도 약하고 후처리에도 약합니다.
결론
딥페이크에 대한 사전적 방어는 사후 탐지의 본질적 한계를 보완할 강력한 후보이지만, 그 발전은 공정한 평가 체계의 부재에 발목 잡혀 있었습니다. 본 논문은 (1) Disruption의 4축 분해, (2) 생성기 편향을 제거한 신규 지표 CIDR, (3) Robustness \(\mathcal{R}_{\text{ROB}}\)와 Transferability \(\mathcal{R}_{\text{TE}}\), (4) AvgRank 기반 통합 비교를 결합한 첫 번째 통합 벤치마크를 통해 이 공백을 메웠습니다.
본 벤치마크가 제시하는 차세대 proactive defense의 요건은 명확합니다 — 다양한 생성기에 일반화 가능(generalizable)하며, 후처리에 견고(robust)하며, 사람 눈에 보이지 않는(imperceptible) 방어. 단일 화이트박스 환경에서의 피크 성능 경쟁은 더 이상 의미 있는 발전 지표가 아닙니다. 본 연구가 딥페이크 위해로부터 사회를 지키는 더 견고한 사전적 방어 기술의 토대가 되기를 바랍니다.