Paper: Towards Deep Learning Models Resistant to Adversarial Attacks
Authors: Aleksander Mądry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, Adrian Vladu
Venue: ICLR 2018
URL: Towards Deep Learning Models Resistant to Adversarial Attacks
Introduction
Recently, deep learning models are increasingly being integrated into security-critical systems such as autonomous driving, facial recognition, and malware detection. However, these Deep Neural Networks have a critical weakness: they are highly vulnerable to adversarial examples—inputs that are nearly indistinguishable from natural data yet are subtly crafted to cause the model to misclassify. In the field of computer vision, even imperceptibly small pixel-level perturbations can fool state-of-the-art neural networks with high confidence.
This paper goes beyond prior heuristic approaches that defend against only specific attacks. Instead, it rigorously defines adversarial robustness from the perspective of robust optimization and proposes a network training methodology that provides universal defense against a broad class of first-order attacks.
Robust Optimization Modeling
Saddle Point Formulation
The core contribution of this paper is formulating the adversarial defense problem as a natural saddle point problem. Instead of standard Empirical Risk Minimization, the formulation allows an attacker to manipulate data $x$ within an allowed perturbation set $\mathcal{S}$, and minimizes the loss under the worst-case scenario:
\[\min_{\theta} \rho(\theta), \text{ where } \rho(\theta) = \mathbb{E}_{(x,y)\sim\mathcal{D}} \left[ \max_{\delta \in \mathcal{S}} L(\theta, x+\delta, y) \right]\]This formulation can be decomposed into two distinct optimization problems:
- Inner Maximization: The process of finding the adversarial example ($x+\delta$) that achieves the highest loss for a given data point, which corresponds to an ‘attack’ on the neural network.
- Outer Minimization: The process of finding model parameters ($\theta$) that minimize the ‘adversarial loss’ obtained from the inner attack problem, which corresponds to training a robust classifier as a ‘defense’.
Danskin’s Theorem and Formula Derivation
To train (optimize) the above saddle point problem, we need to compute gradients with respect to the parameters $\theta$. The paper applies Danskin’s Theorem, a classical result from optimization theory. Accordingly, if we denote the optimal adversarial perturbation that maximizes the inner function as $\delta^*$, the gradient is computed as follows:
\[\nabla_{\theta} \max_{\delta \in \mathcal{S}} L(\theta, x+\delta, y) = \nabla_{\theta} L(\theta, x+\delta^*, y)\]Strictly speaking, neural networks with ReLU activations are not continuously differentiable, so Danskin’s Theorem assumptions are not perfectly satisfied. However, the authors experimentally verified that applying Stochastic Gradient Descent (SGD) consistently decreases the loss, demonstrating that this approach is empirically very reliable.
Defense Mechanisms and Model Properties
The Landscape of Adversarial Examples
One of the most important contributions of this paper is the experimental analysis of the loss landscape of the inner maximization problem, which is a non-concave function.
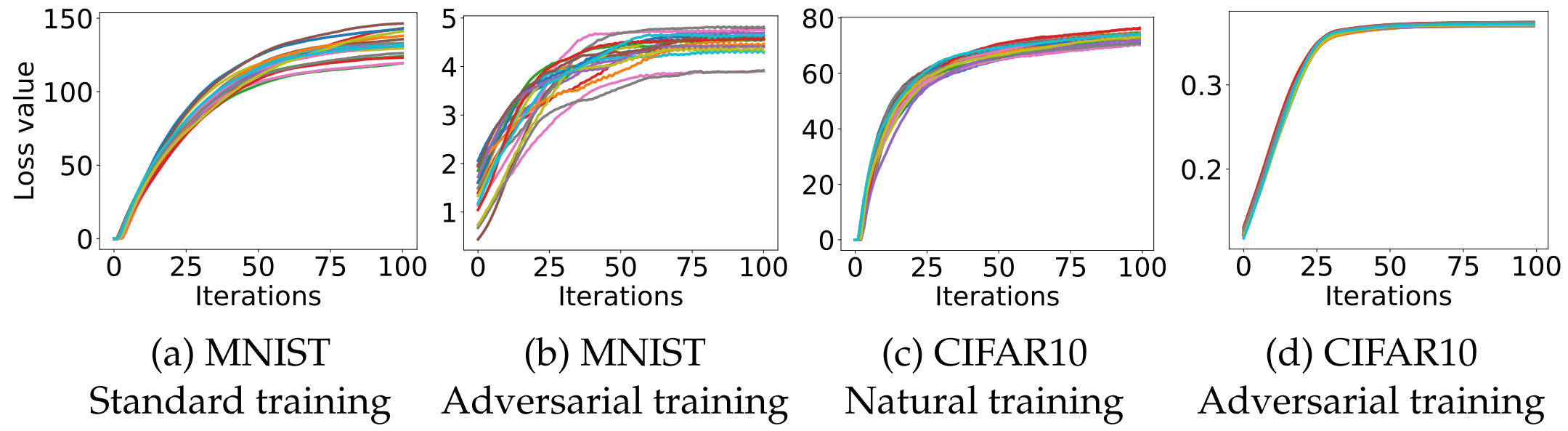
When running PGD from numerous random starting points (random restarts) within the allowed $l_\infty$-ball, the loss values were observed to reach a plateau very quickly.
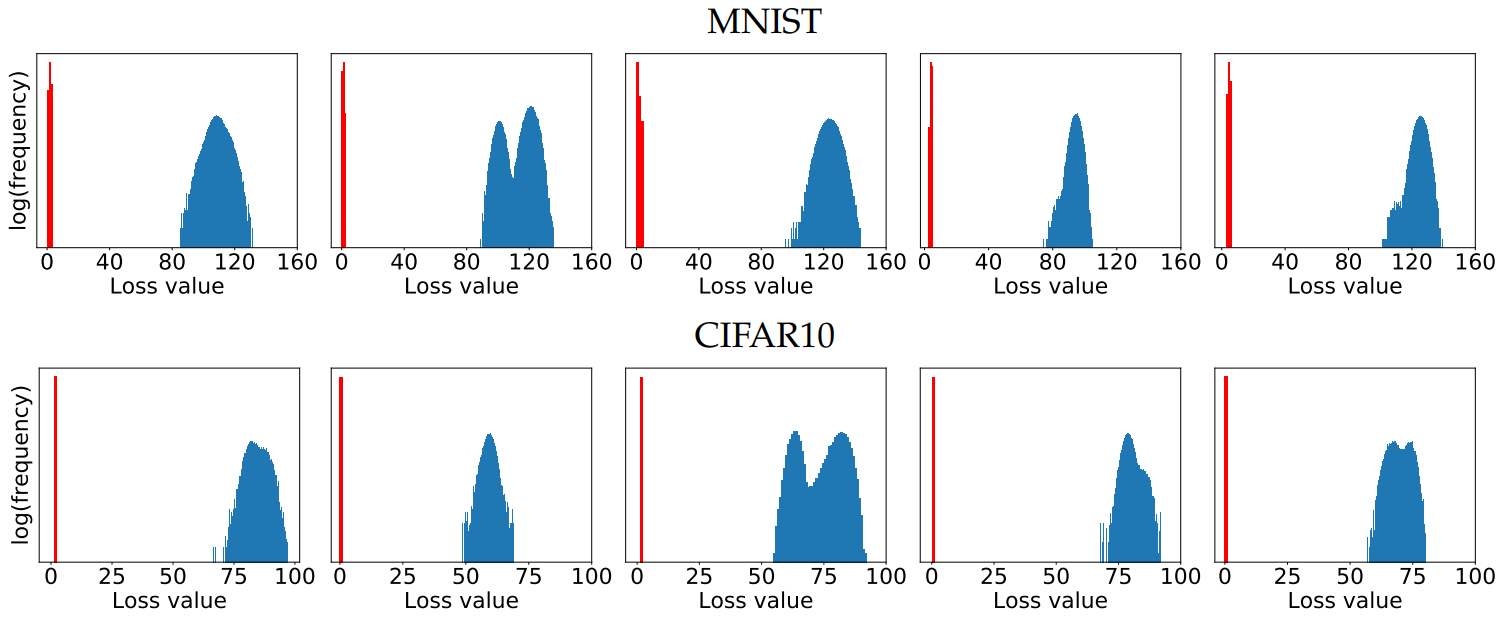
Although numerous local maxima exist, as shown in the histogram above, the loss values are remarkably well-concentrated without extreme outliers. This suggests that first-order methods alone are sufficient to solve the inner optimization problem effectively.
First-Order Adversaries and PGD
Based on the above findings, the paper defines Projected Gradient Descent (PGD) as the strongest and most universal adversary using only first-order information (Universal First-order Adversary). The PGD attack is formulated as:
\[x^{t+1} = \Pi_{x+\mathcal{S}} \left( x^t + \alpha \text{ sgn}(\nabla_x L(\theta, x, y)) \right)\]If a model is trained to defend against this PGD attack, it acquires universal defense against all other attack methods that similarly exploit first-order information (e.g., FGSM, etc.).
Importance of Network Capacity
Simply solving the saddle point problem using PGD is not sufficient; the structural capacity of the classifier model plays a decisive role in defense performance.
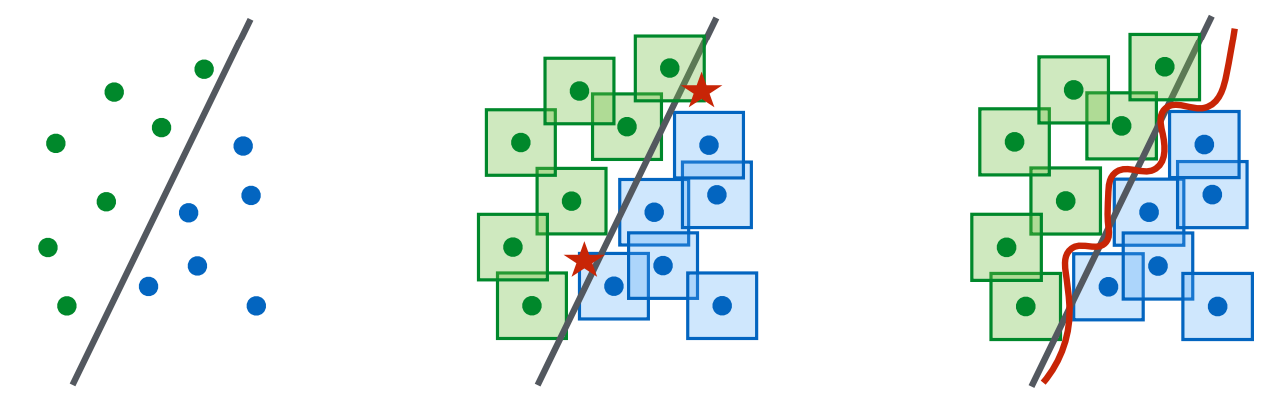
- Demand for complex decision boundaries: To defend against all crafted adversarial examples within $\mathcal{S}$ (e.g., $l_\infty$-ball), a much more complex and refined decision boundary is required so that the perturbation-allowed regions around each data point do not overlap. Therefore, a much larger parameter capacity is needed to withstand adversarial attacks.
- Limitations of weak models: When networks with insufficient capacity are trained against strong PGD attacks, they fail to learn meaningful features and instead predict a single fixed class unconditionally.
- Label leaking in FGSM training: When training with only the single-step FGSM under large $\epsilon$ settings, the model overfits to the very limited form of adversarial examples produced by FGSM.
Transferability
The phenomenon of transferability—where adversarial examples crafted to target a specific source model also cause misclassification on entirely different, independent target models—was also analyzed in depth.
- Training against strong adversaries: Performing adversarial training against the strong PGD attack, rather than the simple FGSM, significantly reduces the success rate of transfer attacks.
- Increasing network capacity: As the model’s capacity increases, the gradient correlation between the source and target models decreases markedly, making it effective for defending against transfer attacks.
Internal Analysis of Robust Models (MNIST Inspection)
In Appendix C, the paper analyzes how adversarially trained models internally acquire their defensive capabilities.
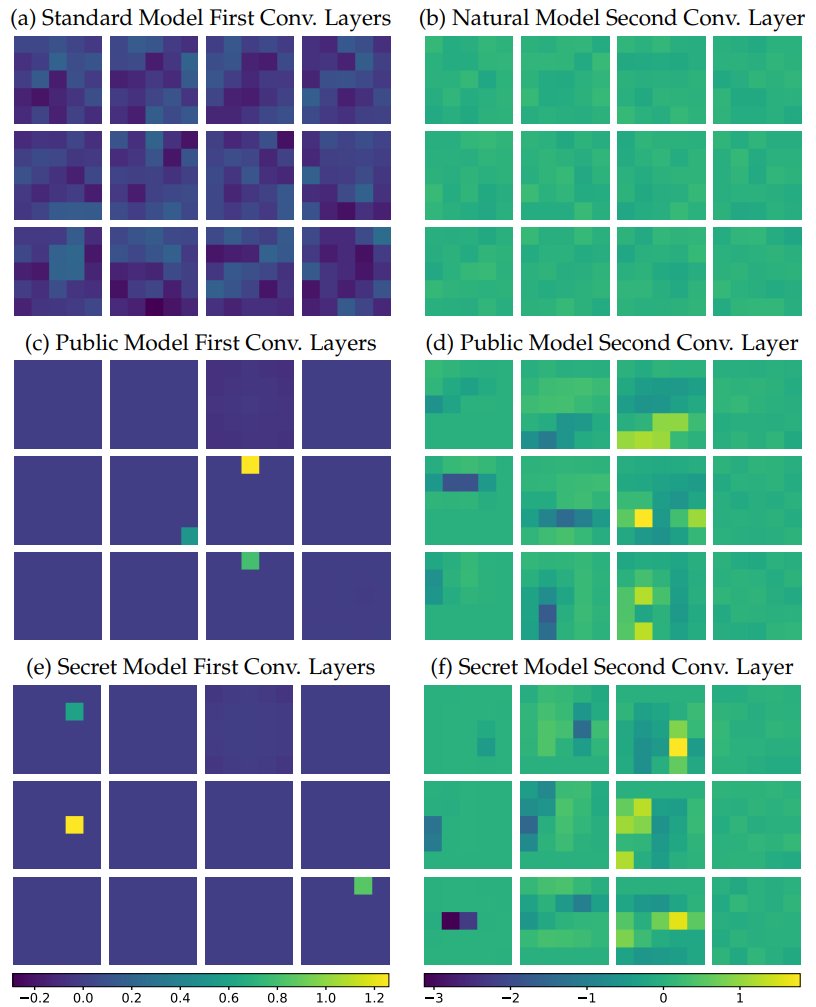
- Learning of thresholding filters: Examining the weights of the first convolutional layer (left column in the figure), the adversarially trained model retains only 3 filters with very sparse weights. This indicates that the model has learned to act as thresholding filters that do not respond to certain pixel-level changes.
- Conservative biases: Analyzing the biases of the final Softmax layer reveals that the model has non-uniformly adjusted its bias values to become hesitant (conservative) about predicting certain classes that are particularly vulnerable to adversarial perturbations.
Experiments and Limitations
The authors evaluated performance under strong threat models after performing PGD adversarial training.
- Successful defense: On the MNIST dataset trained with perturbation budget $\epsilon=0.3$, the model achieved over 89.3% robustness even against the strongest white-box attacks. The CIFAR-10 model trained with $\epsilon=8$ also achieved an unprecedented defense rate of over 64% against black-box transfer attacks. These results held even against the optimization-based Carlini-Wagner (CW) attack.
Gradient Masking and Limitations
However, the paper also clearly acknowledges the limitations of this methodology. When a model trained under the $l_\infty$ norm constraint faced $l_2$ norm-based attacks, it initially appeared robust, but this was because the thresholding filters induced gradient masking, interfering with gradient-based computations. When decision-based attacks that do not use the model’s gradients were applied, the defense against $l_2$ attacks was revealed to be considerably weak.
In conclusion, this paper demonstrated that the seemingly infinite search space of adversarial attacks is actually controllable from a first-order optimization perspective, and proved that the combination of a strong PGD adversary with sufficient network capacity is the key to achieving fundamental adversarial robustness in deep learning models.