신뢰할 수 있는 인공지능이란?
“신뢰할 수 있는 인공지능(Trustworthy AI)”은 AI가 사용자와 사회에 안전하게 기여할 수 있는 시스템을 의미합니다. 이러한 인공지능(AI) 시스템은 일정 수준 이상의 성능을 유지하면서도 사용자가 인공지능의 결정을 이해할 수 있도록 설계되어야 합니다. 동시에 다양한 상황에서 안정적으로 작동하도록 기술적 안전성까지 갖추어야 합니다. 최근 인공지능의 활용이 다양한 분야로 확장되면서 인공지능 신뢰성은 AI의 성능뿐만 아니라 인간의 윤리적 개념을 존중해야 하는 중요한 이슈가 되고 있습니다.
인공지능 신뢰성을 위한 주요 요소
다양한 문서[1][2][3][4]에서 인공지능(AI) 시스템이 갖추어야 할 인공지능 신뢰성의 요소에 대해 언급하고 있지만, 각 문서마다 제시하는 요소는 조금씩 상이합니다. 그러나, 그 중에서도 여러 문서에서 공통적으로 등장하는 주요 요소가 존재합니다. 바로 (1) 안전성(Safety), (2) 책임성(Accountability), (3) 투명성(Transparency)입니다. 이들은 AI가 신뢰성을 갖추는 데 반드시 요구되는 속성으로, 신뢰할 수 있는 인공지능을 구성하기 위한 필수 개념입니다.
-
안전성 (Safety): 안전성은 AI 시스템이 의도한 대로 안정적으로 작동하도록 설계되는 것을 의미합니다. AI가 실제 환경에서 안정적으로 작동하는 것은 신뢰성의 중요한 부분으로, 특히 중요한 결정을 내리는 분야에서는 더욱 필수적입니다. 시스템이 오류나 외부 공격으로부터 보호될 수 있도록 설계하고, 예기치 않은 상황에서도 안정적으로 작동하는 것이 중요합니다.
-
책임성 (Accountability): 책임성은 AI 시스템의 영향을 적절하게 배분하고, 충분한 구제책을 제공하기 위한 매커니즘의 중요성을 다루는 개념입니다. AI가 내린 결과에 대한 검증 가능성 및 재현성이 포함되며, AI 시스템에 대한 평가 및 감사 요구사항을 AI가 준수할 수 있도록 하는 것을 의미합니다. 이를 통해 근미래에 AI가 내리는 자동화된 결정에 대한 구제나 법적 책임을 통해 피해를 최소화합니다. AI에 대한 대중의 신뢰를 얻고 두려움을 해소하기 위한 수단입니다.
-
투명성 (Transparency): 투명성은 AI가 결정을 내리는 과정에서 사용자가 그 과정을 이해할 수 있도록 돕는 요소입니다. 투명성은 AI가 왜 특정 결정을 내렸는지에 대한 정보를 제공해 주어야 하며, 이는 사용자와의 신뢰 구축에 필수적입니다. AI 모델의 결정 과정이 설명 가능성을 통해 시각적으로 드러나고, 각 변수들이 결과에 어떤 영향을 미치는지 이해할 수 있다면 사용자는 AI를 더욱 신뢰할 수 있게 됩니다.
신뢰할 수 있는 인공지능을 위한 핵심 기술
인공지능 신뢰성 달성을 위해, 관련 연구자들은 관련 기술들을 아래와 같이 분류한 바 있습니다.
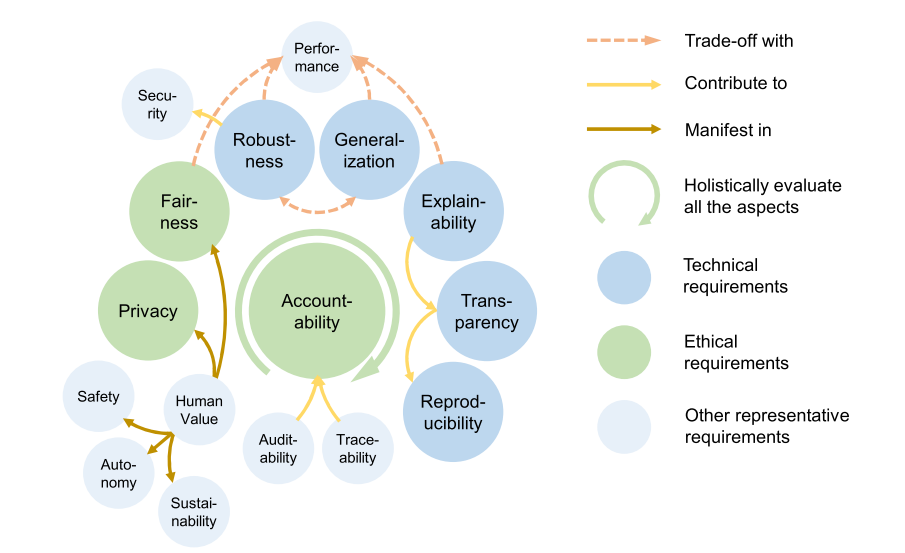
이 중에서도, 본 연구실은 인공지능 신뢰성의 중요 요소(안전성, 책임성, 투명성)를 달성하기 위한 기술적 요소(Technical requirements)로 국내외 인공지능 규제 및 법령의 핵심이 되는 강건성(Robustness), 일반화(Generalization), 설명성(Explainability)에 대한 연구를 진행하고 있습니다.
강건성(Robustness)
AI 시스템이 다양한 환경에서 안정적으로 작동할 수 있도록 보장하는 특성입니다. 강인성을 통해 AI는 데이터에 작은 변동이 있더라도 성능에 큰 영향을 받지 않고 안정적인 결과를 제공합니다. 이를 위해 데이터 다변화 학습과 시나리오 기반 테스트가 이루어집니다. 이러한 접근법은 AI가 다양한 상황에서 신뢰할 수 있는 결과를 제공할 수 있도록 돕습니다.

실제로 AI 모델은 대체로 강건성이 부족하며, 부족한 상태로 배포될 경우 공격에 취약함이 알려져 있습니다. 특히, 이러한 공격은 사람의 눈에 구분되지 않을 정도로 미묘하게 실행될 수 있습니다. 위 그림에서 왼쪽의 정상 사진에 가운데의 공격 노이즈(noise)를 더하면 오른쪽 사진이 됩니다. 사람이 보기에는 왼쪽, 오른쪽 모두 버스이지만, AI는 왼쪽은 버스, 오른쪽은 타조로 잘못 판단합니다.

이러한 공격은 자율주행 자동차 등 실생활에도 악용될 수 있으며, 위 사진과 같이 임의의 스티커를 표지판에 부착하여, 멈춤 표지판을 최소 속력 표지판으로 인식하게 유도할 수 있습니다.
즉, “인공지능 모델이 악의적인 공격에도 안정적으로 잘 작동하는가”에 대한 개념입니다. 내외부의 가능한 공격에 대한 인공지능 모델의 안전성과 직결되는 요소입니다 관련 기술로는 적대적 공격(Adversarial attack), 적대적 방어(Adversarial Training)이 있습니다.
연구실 대표 관련 논문:
- Fantastic Robustness Measures: The Secrets of Robust Generalization [NeurIPS 2023] | [Paper] | [Repo] | [Article]
- Understanding catastrophic overfitting in single-step adversarial training [AAAI 2021] | [Paper] | [Code]
- Graddiv: Adversarial robustness of randomized neural networks via gradient diversity regularization [IEEE Transactions on PAMI] | [Paper] | [Code]
- Generating transferable adversarial examples for speech classification [Pattern Recognition] | [Paper]
일반화(Generalization)
일반화 능력은 AI가 새로운 데이터에 대해서도 신뢰할 수 있는 예측을 내릴 수 있게 하는 기술입니다. AI 모델이 훈련 데이터에만 의존하지 않고, 훈련되지 않은 환경에서도 안정적인 성능을 유지하기 위한 다양한 학습 방법을 포함합니다.

인간은 위 그림 모두 판다라고 정확히 분류합니다. 일반화 수준이 높은 AI의 경우에도 인간과 비슷하게 판단할 수 있습니다. 다만, 일반화 수준이 부족할 경우 학습 이미지에 대해서만 제대로 맞추며, 이외의 데이터(Out-of-distribution)에 대해서는 제대로 인지하지 못하는 모습을 보입니다.

실제로 이러한 일반화 부족은 실험 데이터가 편향(bias)되어 있을 때 빈번하게 발생하며, 자율주행 AI를 학습할 때 대부분의 영상 및 사진이 밝은 날에 찍혀 어두운 밤이나 비가 올 때에는 제대로 작동하지 못하는 경우가 발생합니다.
즉, “학습 때 접하지 못했던 예제에 대하여 인공지능 모델이 잘 대답할 수 있는가?”를 의미합니다. 딥러닝(Deep Learning)을 포함한 인공지능 기술이 보다 안정적으로 작동하기 위한 성능 측면의 핵심 요소입니다. 관련 기술로는 해 전이 학습(Transfer Learning), 도메인 적응(Domain Adaptation), Sharpness-Aware Minimization (SAM)이 있습니다.
연구실 대표 관련 논문:
- Stability Analysis of Sharpness-Aware Minimization [Under Review] | [Paper] | [Article]
- Differentially Private Sharpness-Aware Training [ICML 2023] | [Paper] | [Code]
- Fast sharpness-aware training for periodic time series classification and forecasting [Applied Soft Computing] | [Paper]
- Compact class-conditional domain invariant learning for multi-class domain adaptation [Pattern Recognition] | [Paper]
설명성(Explainability)
설명 가능성은 AI의 결정 과정과 결과를 사용자에게 이해하기 쉽게 설명할 수 있는 능력입니다. AI가 내린 결정을 투명하게 이해할 수 있도록하는 기술이 사용됩니다. 이러한 기술은 사용자가 AI의 결정 과정에 대한 이해도를 높이고, AI의 결정이 어떻게 도출되었는지를 설명할 수 있습니다.

현재의 AI는 좋은 결과를 내놓지만, 왜 그런 결과를 내놓았는지에 대한 설명은 명료하게 제공하지 못합니다. 설명성은 AI의 이러한 단점을 극복하여, “인공지능이 자신이 내놓은 결과에 대해 사람에게 충분히 설명할 수 있는가?”를 의미합니다. 주요 국내외 인공지능 법령에서 투명성을 위한 필수 기술이며, 금융, 의료 등의 고위험 분야에서 인공지능이 활용되기 위한 핵심 요소입니다. 관련 기술로는 LIME(Local Interpretable Model-agnostic Explanations), SHAP(SHapley Additive exPlanations), Attention 등이 있습니다.
연구실 대표 관련 논문:
- Are Self-Attentions Effective for Time Series Forecasting? [NeurIPS 2024] | [Paper] | [Repo]
- Outside the (Black) Box: Explaining Risk Premium via Interpretable Machine Learning [Under Review] | [Paper]
- Fair sampling in diffusion models through switching mechanism [AAAI 2024] | [Paper] | [Code]
결론
신뢰할 수 있는 인공지능은 사용자가 AI의 결정을 신뢰할 수 있도록 투명성과 안전성, 그리고 책임성을 기반으로 설계되어야 합니다. 이들 요소는 AI가 사회에 긍정적인 역할을 하도록 하며, 동시에 AI가 불가피하게 발생할 수 있는 위험을 줄이는 데 도움을 줍니다. 강건성, 일반화, 설명성과 같은 기술적 접근을 통해 신뢰할 수 있는 AI를 구축함으로써, AI는 인간과 조화롭게 발전할 수 있습니다.
신뢰할 수 있는 인공지능은 더 이상 선택이 아닌 필수적 요소입니다. AI가 인간의 삶에 깊이 자리잡기 위해서는 신뢰성과 안전성이 최우선으로 고려되어야 하며, 이를 위한 기술적 접근은 앞으로도 계속해서 발전해야 할 것입니다.