서론
인공지능(Artificial Intelligence) 모델이 현실에 도입될 때에는 ‘대체로’ 잘 작동하는 것은 오히려 최소 조건이 됩니다. 오히려, 우리가 해당 모델을 신뢰할 수 있는지가 중요해집니다.
일반화(Generalization)란 “학습 때 접하지 못했던 예제에 대하여 인공지능 모델이 잘 대답할 수 있는가?”를 의미합니다. 딥러닝(Deep Learning)을 포함한 인공지능 기술이 보다 안정적으로 작동하기 위한 성능 측면의 핵심 요소입니다.
“Stability Analysis of Sharpness-Aware Minimization” [Paper] 은 일반화 성능을 향상시키는 최적화 기법인 Sharpness-Aware Minimization (SAM)에 관한 본 연구실의 논문이며, 본 글에서는 논문 내용과 함께 일반화의 개념을 알아보고자 합니다.
사전 지식
일반화와 일반화 차이
일반화를 이해하기 위해서는, 우선 인공지능이 목표하는 이상과 현실 간의 괴리를 파악해야 합니다. 손실함수(Loss function) \(\ell(\cdot)\)와 매개변수(parameters) \(w\)가 주어졌을 때, 인공지능 모델은 다음을 목표로 합니다.
\[\begin{equation} \min_w \mathcal{L}(w; \mathcal{S}) := \frac{1}{n} \sum_{(x, y) \in \mathcal{S}}\ell(w; x, y), \label{eq:erm} \end{equation}\]여기서 \(\mathcal{S}=\{x_i, y_i\}_{i=1}^n\)는 우리가 접근 가능한 학습 데이터셋을 의미합니다. 위의 최적화 기법을 Empirical risk minimization (ERM)이라고 부르며, 이는 일반적으로 알려져 있는 통계학적 i.i.d 가정에 의하면 좋은 모델을 산출합니다.
그러나, 실제로는 i.i.d 가정이 만족되지 못하는 경우가 많으며, 우리가 가지고 있는 학습 데이터의 제한점에 의해 목표하는 이상인 “가능한 모든 데이터에 대해 손실함수를 최소화하는 것”(아래 식)을 달성하지 못합니다.
\(\begin{equation} \min_w \mathcal{L}(w; \mathcal{D}) := \mathbb{E}_{(x, y) \sim \mathcal{D}} \left[ \ell(w; x, y) \right]. \label{eq:erm_true} \end{equation}\) \(\mathcal{D}\)는 실제 데이터의 참 분포를 의미하며, 모델이 앞으로 볼 수 많은 테스트 데이터(test data)도 포함합니다.
즉, 모델이 학습하는 것 \eqref{eq:erm}과 목표하고자 하는 것 \eqref{eq:erm_true} 간의 간극이 발생하고, 이 차이를 일반화 차이(Generalization gap) \(\mathcal{E}(w)\)라고 정의합니다.
\(\begin{equation} \mathcal{E}(w) = \mathcal{L}(w; \mathcal{S}) - \mathcal{L}(w; \mathcal{D}). \label{eq:truedistribution} \end{equation}\) \(\mathcal{E}(w)\)가 작으면 작을 수록, 학습 환경과 실제 환경에서 별다른 성능 차이를 보이지 않는 다는 것이며; 반대로 \(\mathcal{E}(w)\)가 크면 클수록, 학습 환경과 실제 환경에서의 성능 괴리가 심하다는 것입니다.
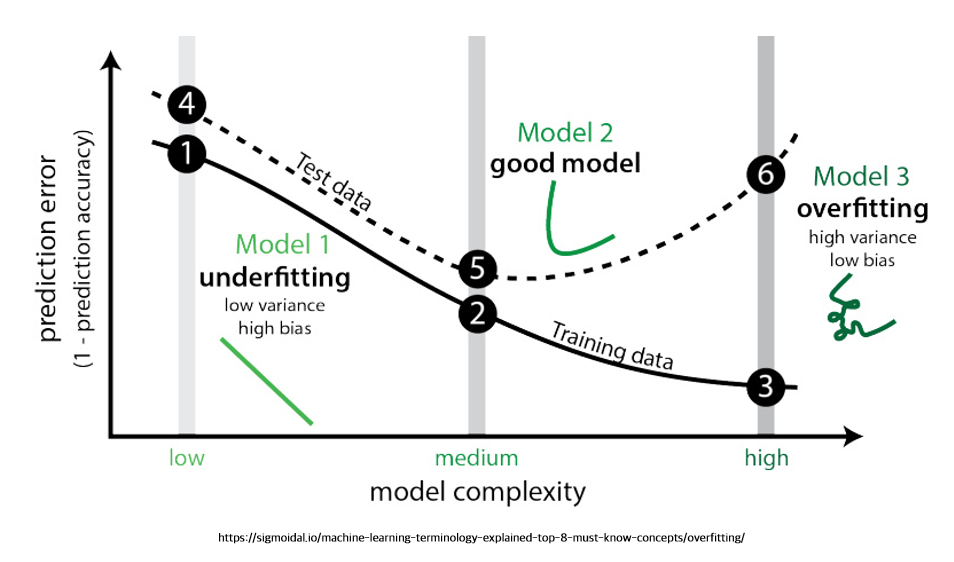
흔히, 모델의 일반화 차이(Generalization gap) \(\mathcal{E}(w)\)이 기대치보다 훨씬 큰 경우 과적합(Overfitting)되었다고 말하며, 이는 곧 학습 데이터에 대해서만 성능이 높은 경우를 말하게 됩니다.
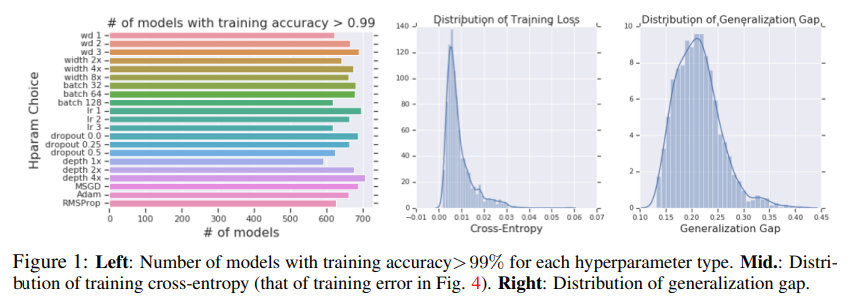
선행 연구에서는 특정 환경에서 학습된 모델들이 모두 학습 정확도가 99% 이상이더라도, 일반화 차이는 0%에서 심하면 45%까지 발생할 수 있음을 확인했습니다.
Sharpness-Aware-Minimization
선행 논문들은 모델이 적은 일반화 차이(Generalization gap) \(\mathcal{E}(w)\)를 가질 수 있도록 다양한 방법을 제안해왔습니다. 그 중에서도 최근에 집중되고 있는 부분이 손실함수의 평평함(Flatness of the loss landscape)입니다. 매개변수 공간(Weight-space)에서 모델이 근방에 평평한 손실함수를 가지면, 일반화 성능이 좋다는 주장입니다.
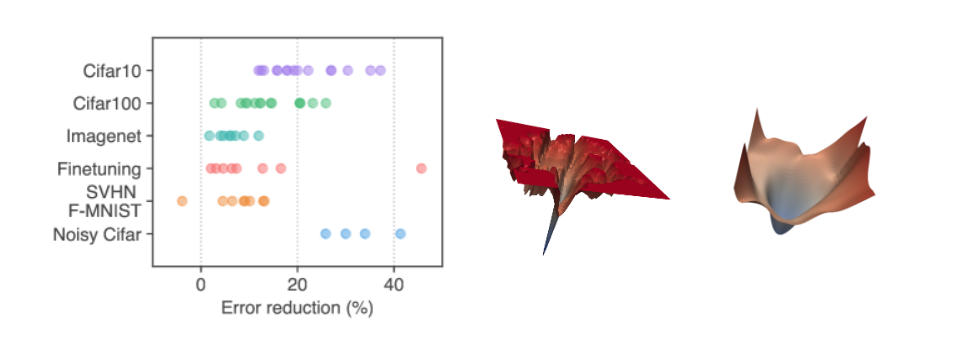
위 그림에서처럼, 선행 연구진은 뾰족한(Sharp) 손실함수를 가지는 모델 (가운데 그림)보다, 평평한(Flat) 손실함수를 가지는 모델 (오른쪽 그림)이 에러를 훨씬 많이 감소시켰다는 것입니다(왼쪽 그림).
해당 논문에서 평평한 손실함수를 가지기 위해 제안된 것이 Sharpness-Aware-Minimization (SAM) 최적화 방법이 되겠습니다. 일반적인 최적화 방법인 경사하강법(Gradient descent)은 다음과 같이 표현됩니다.
\begin{equation} w_{t+1} = w_t - \eta \nabla \ell(w_t), \label{eq:vanila} \end{equation}
\(\eta\)는 학습 계수(Learning rate)를 의미하며, \(\nabla\)는 기울기 함수를 의미합니다.
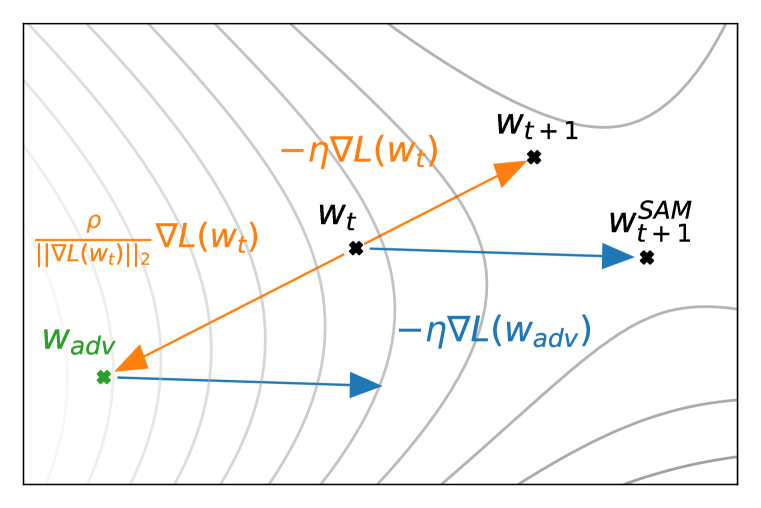
SAM의 핵심 아이디어는, 현재 위치의 손실함수 값만 줄이는 것이 아니라, “내 근방에 가장 높은 손실함수 값을 가지고 있는 모델의 손실함수 값을 줄이면 평평해지지 않겠느냐”라는 것입니다.
\[\begin{equation} w^p_t = w_t + \rho \nabla \ell(w_t). \label{eq:wp} \end{equation}\] \[\begin{equation} w_{t+1} = w_t - \eta \nabla \ell(w^p_t), \end{equation}\]이는 위와 같이 수식화되며, \(w^p\)가 의미하는 것이 내 근방 \(\rho\)에서 가장 높은 손실함수 값을 가지고 있는 모델이 되겠습니다.

SAM이 발표된 이후 다양한 기업 및 연구진은 학습 모델의 성능을 높이기 위해 SAM을 사용했고, 실제로 OpenAI의 Clip을 개선하여 생성형 모델인 “Dall-e-2”를 학습시키는 데에도 SAM이 사용되었습니다.
본론
본 논문은 “SAM은 항상 더 좋은 결과를 도출하는 가?”라는 질문에서 시작합니다. 본 논문의 시작이 되는 실험은 아래 그림입니다.
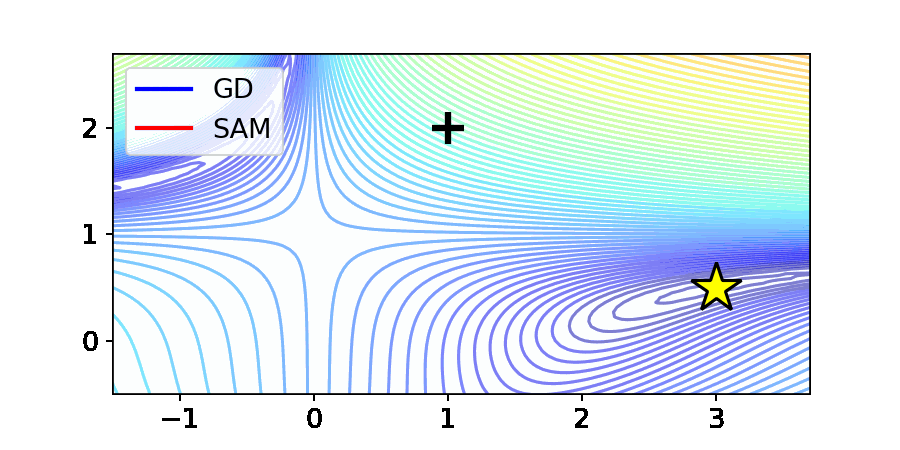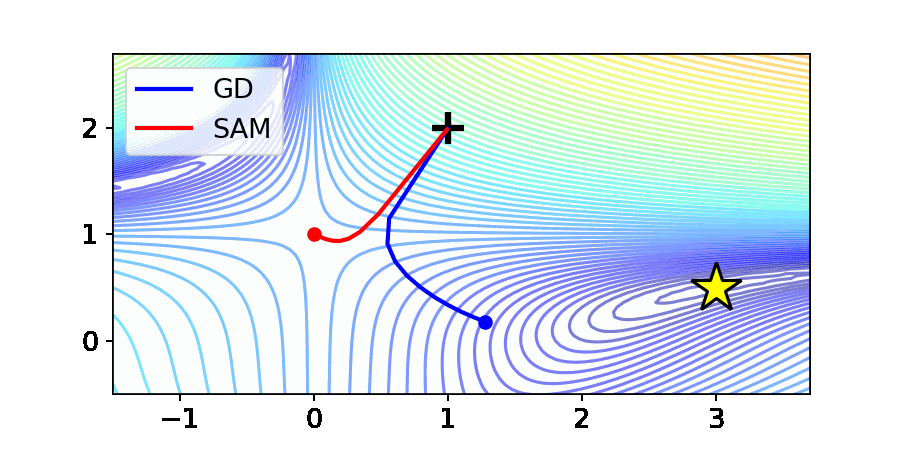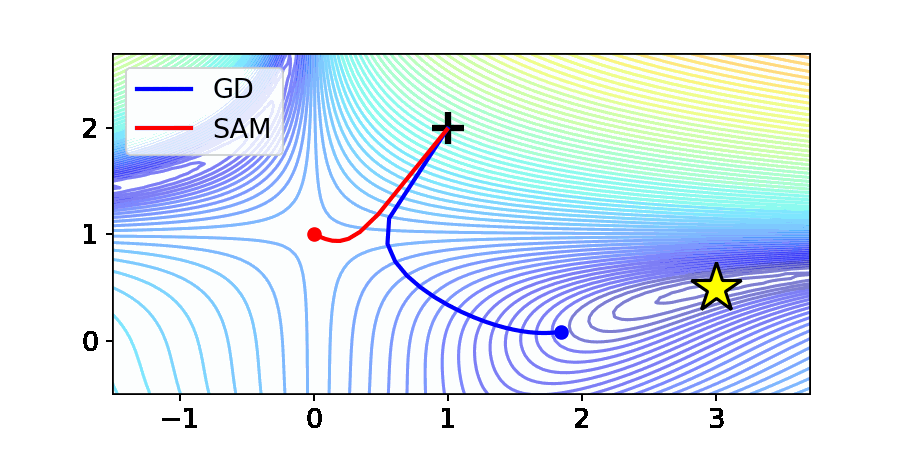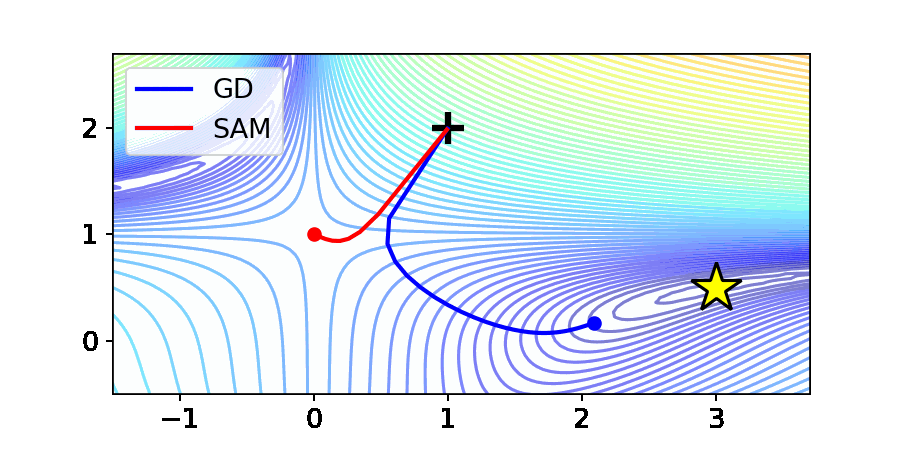
위 그림은 최적화 분야에서 흔히 사용되는 Beale 함수에서의 Gradient Descent (GD)와 SAM의 최적화 결과입니다. Beale 함수는 그림 중앙에 안장점(Saddle point)를 가지며, 노란 별로 표시되어 있는 곳에서 최소값을 가집니다.
GD의 경우 주어진 Beale 함수의 원하는 수렴점인 노란별로 수렴하는 것을 확인할 수 있습니다. 반면, SAM은 최적점에 다가가지 못하고 안장점에 갇하는 상태를 보여줍니다. 본 논문에서는 이를 “Saddle point problem of SAM”으로 명명하고, 이론적 및 실험적으로 SAM의 행동(Behavior)를 규명하였습니다.
안장점의 수렴점화
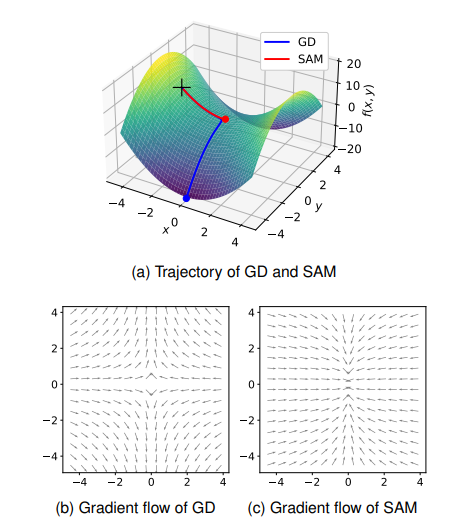
SAM의 행동을 더 정확히 규명하기 위해, 본 논문에서는 \(f(x,y)=x^2-y^2\)의 간단한 함수를 통해 기울기 흐름(gradient flow) 분석을 진행하였습니다. 그 결과, GD는 안장점에서 빠져나갈 수 있는 방향의 기울기 흐름이 있는 것에 비해, SAM은 안장점이 끌어당김점이 되는 비정상정인 현상을 관측할 수 있었습니다. 안장점은 일반적으로 수렴점이 될 수 없으나, SAM 기법 하에서는 수렴점처럼 작동한다는 의미입니다.

확률미분 방정식을 통한 안장점 분석
일반적인 확률미분 방정식(Stochastic differential equation, SDE)은 아래와 같이 표현됩니다.
\begin{equation} d w = -\nabla \ell(w^p) dt + [\eta C(w^p)]^{\frac{1}{2}} dW_t, \label{eq:dynamics} \end{equation}
위의 확률미분 방정식을 SAM 기법에 대입하면 다음과 같은 증명이 가능합니다.

위 증명은 실제 딥러닝 모델 및 배치(Batch) 학습 기반의 실험에서도 관측 가능했습니다.
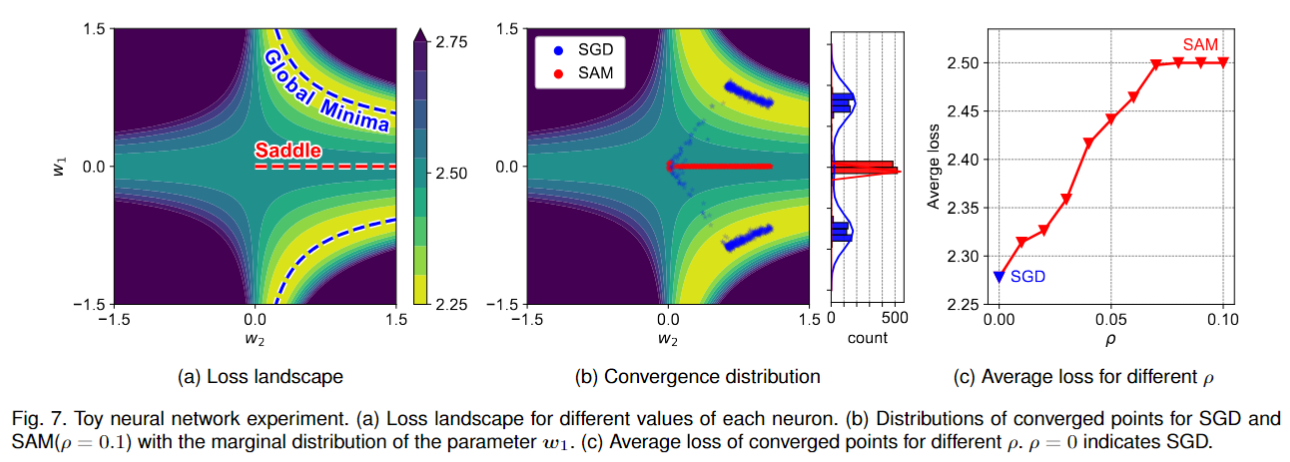
이로써, SAM이 완전배치(Full-batch) 상에서 GD를 쓸 때 뿐만 아니라, 배치 학습 상에서 SGD(Stochastic gradient descent)에 비해서도 안장점 문제를 보인다라는 것을 증명하였습니다.
수렴 불안정성과 학습 기법
그렇다면, 이러한 안장점 문제를 극복하기 위해서는 어떤 방법이 사용되어야 하는가. 본 논문에서는 이를 학습 기법(Training trick)을 조절하는 가이드라인을 제시하고 있습니다.

위 증명이 의미하는 바는 SAM을 사용할 때 기존에 사용하는 모멘텀(Momentum)을 증가시키거나 배치 사이즈를 감소시키면 안장점에서 탈출할 확률이 높아진다는 것입니다. 논문의 말미에서는 실제로 이러한 학습 기법의 조절이 안장점을 탈출하는 데에 효과적이라는 것을 실험적으로 보여줍니다.
결론
일반화는 인공지능의 신뢰성 부문에서 핵심 개념 중 하나입니다. 모델의 일반화 성능을 높이는 것은 제한된 환경에서의 성능과 실제 환경에서의 성능이 거의 유사하다는 것을 의미합니다. 아직까지도 일반화 분야는 수학적, 실험적으로 연구할 과제들이 많이 남아있으며, 본 논문은 그러한 흐름에서 SAM의 역학 분석을 통해 수렴 문제를 논의하였습니다. 본 논문의 발견이 인공지능의 일반화 성능을 크게 높일 수 있는 최적화 방법의 제안에 기여하길 바랍니다.
관련 연구실 논문
- Differentially Private Sharpness-Aware Training [ICML 2023] | [Paper] | [Code]
- Fast sharpness-aware training for periodic time series classification and forecasting [Applied Soft Computing] | [Paper]
- Compact class-conditional domain invariant learning for multi-class domain adaptation [Pattern Recognition] | [Paper]