논문명: Knockoff nets: Stealing Functionality of Black-box Models
저자: Tribhuvanesh Orekondy, Bernt Schiele, Mario Fritz
게재지: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
URL: Knockoff nets: Stealing Functionality of Black-box Models
서론
딥러닝 기술이 발달함에 따라, 이미지 인식과 같은 다양한 머신러닝 서비스들이 블랙박스 형태의 API로 제공되고 있습니다. 예를 들어 구글의 클라우드 비전 서비스는 사용자에게 예측 결과만을 제공할 뿐, 내부 구조나 학습 데이터는 공개하지 않습니다. 이러한 상업적 모델은 데이터 수집, 모델 설계, 하이퍼파라미터 튜닝 등 막대한 시간과 자원이 투입되어 개발되며, 높은 경제적 가치를 지닙니다.
블랙박스 모델의 높은 가치와 제한된 접근성은, 모델의 악의적인 활용 가능성에 대한 우려를 발생시켰습니다. 이 문제의식은 블랙박스 모델을 대상으로 한 다양한 추론 공격(inference attack)으로 이어졌으며, 훈련 데이터와 모델의 구조를 추론하려는 시도가 활발히 이루어지고 있습니다.
본 논문에서는 한걸음 더 나아가 블랙박스 환경에서 모델의 기능 자체를 도용하고자 하는, 기능적 도용(functionality stealing)에 주목합니다.
단순한 예측 결과만을 활용해 목표 모델의 기능을 효율적으로 복제할 수 있는 공격 기법을 제안하고, 그 효율성과 효과성을 실험적으로 분석합니다.
사전지식
블랙박스 vs 화이트박스
-
블랙박스 모델은 내부 구조, 파라미터, 학습 데이터 등이 외부에 노출되지 않으며, 사용자는 입력에 대한 출력값만 확인할 수 있습니다. 대부분의 상용 머신러닝 API는 이 형태로 제공됩니다.
-
화이트박스 모델은 모델의 구조와 학습 과정이 모두 공개된 형태로, 연구 개발 또는 내부 배포 환경에서 사용됩니다. 사용자는 모델의 매개변수(parameter), 구조(architecture), 손실 함수(loss function) 등 모든 정보에 직접 접근할 수 있습니다.
본 논문은 블랙박스 환경에서의 공격 시나리오를 다룹니다.
모델 도용(model stealing)
최근 연구들은 블랙박스 모델로부터 다음과 같은 내부 정보를 추정하려는 시도를 이어가고 있습니다:
- 파라미터 Fredrikson et al.,
- 하이퍼파라미터 Wang et al.,
- 아키텍처 Oh et al.,
- 훈련 데이터 정보 Shokri et al.,
- 결정 경계 Papernot et al.
이러한 연구들은 목표 모델의 정밀한 복제를 목표로 하며, 대개 목표 모델에 대한 어느 정도의 사전 지식이나 내부 접근 권한을 전제로 합니다.
본 논문에서는 이와 달리 사전 지식 없이도 블랙박스 모델의 기능 그 자체를 도용할 수 있는지에 집중합니다.
지식 증류(Knowledge Distillation)
지식 증류는 복잡한 선생(teacher) 모델의 지식을 경량화된 학생(student) 모델로 전이시키는 기술입니다.
일반적인 지도학습은 one-hot 라벨을 기반으로 학습하지만, 증류는 선생 모델의 예측 확률 분포(soft label)를 활용하여 학생 모델이 더 많은 정보를 학습할 수 있게 합니다. 선생 모델의 예측 확률 분포는 클래스 간의 유사성, 확신 정도 등 선생 모델의 함축적 지식을 반영합니다.
능동 학습(Active Learning)
능동 학습은 라벨링(labeling) 비용이 제한된 상황에서, 가장 정보성이 높은 샘플을 우선적으로 선택하여 학습 효율을 높이는 전략입니다. 모델의 불확실성이 높은 샘플이나 예측이 까다로운 데이터를 우선 선택하는 방식이 대표적입니다.
논문에서는 이 개념을 응용하여 적응형 질의(adaptive querying) 기법을 제안합니다.
본론
목표
공격자가 처한 상황은 다음과 같습니다:
- 공격자는 목표 모델의 학습률(learning rate), 배치(batch) 크기, 옵티마이저 등의 하이퍼파라미터와 모델 구조에 대한 사전 지식이 없습니다.
- 학습에 사용한 데이터, 클래스 전반의 의미론적 관계(semantics) 역시 알지 못합니다.
- 목표 모델은 입력에 대한 확률 벡터만을 반환합니다.
본 논문은 이러한 상황 속에서 목표 모델의 기능을 최소한의 질의로 복제하고자 합니다.
이는 다음과 같은 도식으로 표현됩니다:
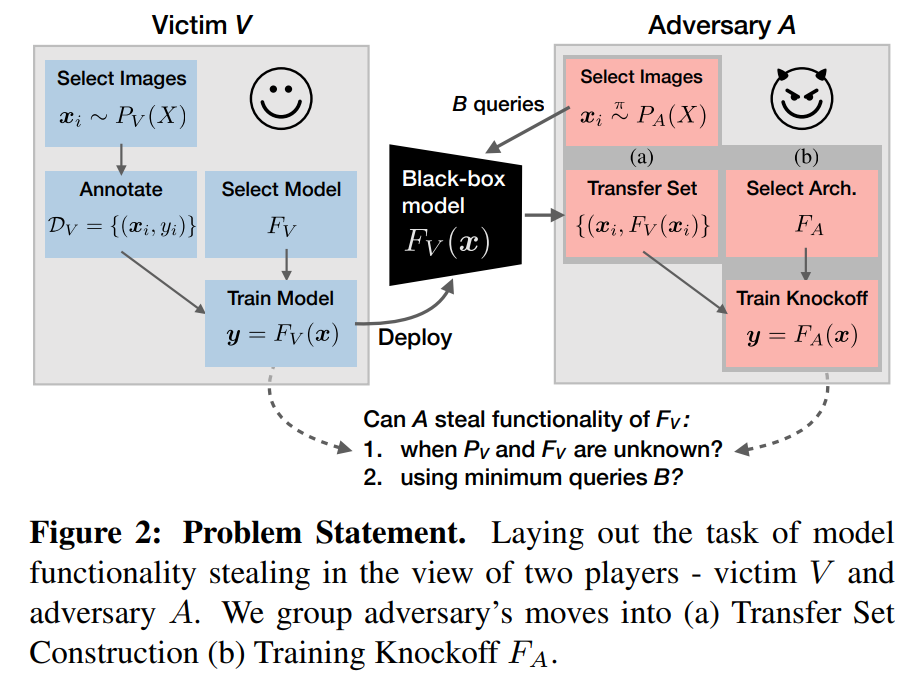
Knockoff Nets
복제 모델을 생성하는 것은 다음의 두 단계로 이루어집니다:
-
전이 데이터셋(transfer set) 구축
목표 모델에 질의하여 복제 모델의 훈련에 사용할 전이 데이터셋을 얻는 과정입니다. 이때, 두 가지 질의 전략이 있습니다:
-
랜덤 샘플링(Random Sampling) 이미지 분포로부터 무작위로 입력을 선택하여 목표 모델에게 질의합니다.
-
적응형 샘플링(Adaptive Sampling) 질의할 데이터를 능동적으로 선택해 전이 데이터셋의 품질을 높이는 전략입니다. 적응형 샘플링은 각 시간 단위 \(t\)마다 정책 \(\pi_t(z)\)로부터 사용할 클래스를 선택하고 이미지 샘플을 생성합니다.
-
정책 \(\pi_t\)는 다음과 같은 과정으로 업데이트됩니다:
- \(\pi_t\)로 표현되는 정책을 통해, 각 입력에 대한 질의 확률을 조정합니다.
-
질의의 선호도 정책을 업데이트 하기 위해 보상 \(r_t\)을 사용합니다.
보상 \(r_t\)는 세 가지 요소로 구성됩니다:
-
\(R^{\mathcal{L}}\): 목표 모델과 복제 모델의 출력 결과 간 손실입니다. 이는 다음과 같은 수식으로 표현됩니다: \(\begin{align} R^\mathcal{L}(y_t, \hat{y}_t) = \mathcal{L}(y_t, \hat{y}_t) \end{align}\)
- \(R^{cert}\): 목표 모델의 출력의 대한 확신 정도입니다. 이는 다음과 같은 수식으로 표현됩니다: \(\begin{align} R^{cert}(y_t) = P(y_{t,k_1}|x_t) - P(y_{t,k_2}|x_t) \end{align}\)
- \(R^{div}\): 목표 모델 출력의 다양성 정도입니다. 이는 다음과 같은 수식으로 표현됩니다: \(\begin{align} R^{div}(y_{1:t}) = \sum_k \text{max}(0, {y}_{t,k}-\bar{y}_{t:t-\Delta, k}) \end{align}\)
-
선호도 정책 \(H_t\)는 다음과 같은 수식으로 표현됩니다: \(\begin{align} H_{t+1}(z_t) = H_t(z_t) + \alpha(r_t - \bar{r}_t)(1-\pi_t(z_t)) \quad \text{and} \\ H_{t+1}(z') = H_t(z') + \alpha(r_t - \bar{r}_t)\pi_t(z') \quad\quad \forall z' \neq z_t \end{align}\)
앞에서 얻은 보상\(r_t\)를 사용해 각 클래스 \(z\)의 선호도 \(H_t\)를 업데이트합니다.
-
-
복제 모델(knockoff) 훈련
수집된 전이 데이터셋을 이용해 복제 모델을 목표 모델의 출력과 유사하도록 학습합니다.
복제 모델은 사전 학습된 ImageNet 모델에서 시작합니다. (e.g., MobileNet, ResNet)
학습 목적은 victim 모델의 출력을 정확히 모방하는 것이며, 다음 손실 함수를 최소화합니다:
이는 예측 확률 분포 기반의 cross-entropy로, 목표 모델과 복제 모델 간의 KL-divergence 최소화와 동일합니다.
실험 설정
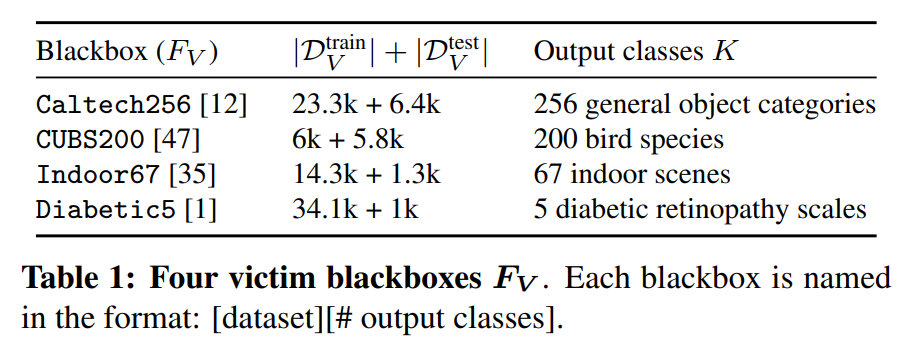
- 목표 모델
목표 모델은 다음과같은 데이터셋으로 훈련을 진행합니다:
- 공격 이미지셋 구축
공격자는 목표 모델의 훈련에 사용한 데이터셋을 모르기 때문에 임의의 공개 이미지셋 데이터를 활용하게 됩니다.
본 논문에서는 전이 데이터셋을 구성하기 위해 다양한 이미지 분포에서 이미지를 샘플링하여 활용합니다. 실험에서 사용된 4가지 주요 이미지 분포는 다음과 같습니다:
- \(P_V\) (완전히 동일한 데이터) 목표 모델 학습에 사용한 데이터와 동일한 데이터를 사용합니다. 다른 이미지셋과의 비교를 위한 기준으로 활용되며 지식 증류의 특수한 형태로 간주할 수 있습니다.
- ILSVRC (ImageNet) ILSVRC 2012 challenge의 1000개 클래스, 총 1.2M개의 이미지를 사용합니다.
- OpenImages Flickr에서 수집된 9.2M개의 이미지 중, 600개 클래스에서 2000장씩 추출한 총 550K개의 이미지 서브셋을 사용합니다.
- \(D^2\) (Dataset of Datasets) 논문에서 사용된 모든 데이터셋을 결합한 집합으로, 총 2.2M개의 이미지, 2129 클래스입니다.
논문에서는 위 이미지 분포들을 다음과 같이 분류합니다. 이는 목표 모델의 훈련 데이터셋과 공격 이미지 분포의 라벨 겹침 정도를 기준으로 합니다.
- \(P_A=P_V\): 목표 모델의 학습 데이터와 완전히 동일합니다.
- 닫힌 세계(Closed-World): \(P_A = D^2\), 목표 모델 훈련 데이터셋이 공격 이미지 분포의 부분집합입니다.
- 열린 세계(Open-World): ILSVRC, OpenImages, 두 데이터의 클래스 겹침은 우연에 의한 것입니다.
실험 결과
앞선 전략과 실험 환경을 기반으로 한 실험의 결과는 다음과 같습니다:
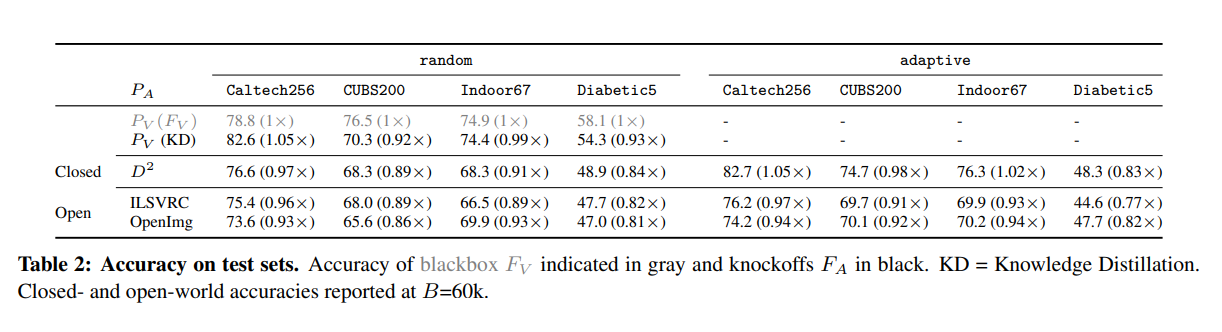
목표 모델의 학습 데이터와 독립적인 이미지 분포로부터 랜덤한 이미지를 질의하는 것만으로도 모델의 기능을 어느정도 복제할 수 있었습니다.
다음은 정성적 분석 결과입니다:

목표 모델에 훈련 이미지셋에 존재하지 않았던 클래스의 이미지를 질의할 때의 출력 레이블은 입력 이미지와 큰 관련이 없는 것을 알 수 있습니다.(Fig. 6a)
하지만 테스트시 관련 이미지가 제시될 때에는 강력한 예측 성능을 보였습니다.(Fig. 6b)
다음은 활용 예산(budget)에 따른 모델의 성능 실험 결과입니다:
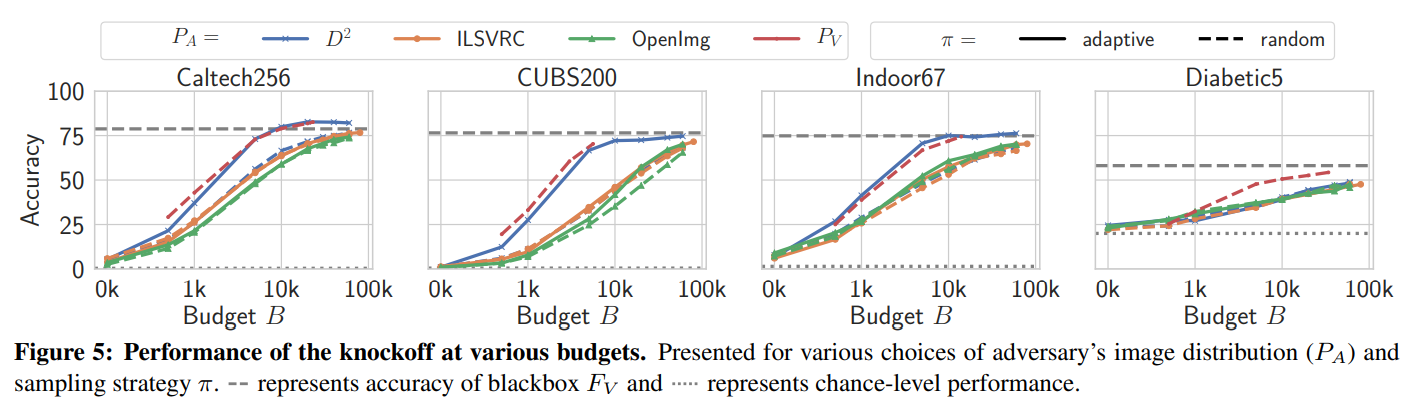
닫힌 세계(\(D^2\))에서는 적응형 질의 전략이 대체로 가장 좋은 성능을 보였습니다.
훨씬 거대한 이미지 분포를 사용했음에도 목표 모델과 동일한 데이터를 사용한 지식증류(\(P_V\))와 비견할만한 성능이 나타났습니다.
열린 세계(ILSVRC, OpenImg)에서는 적응형 질의 전략이 소폭의 성능 향상과 샘플 효율성 개선을 이루어냈습니다.
다음은 적응형 질의 정책의 시각화 결과입니다:
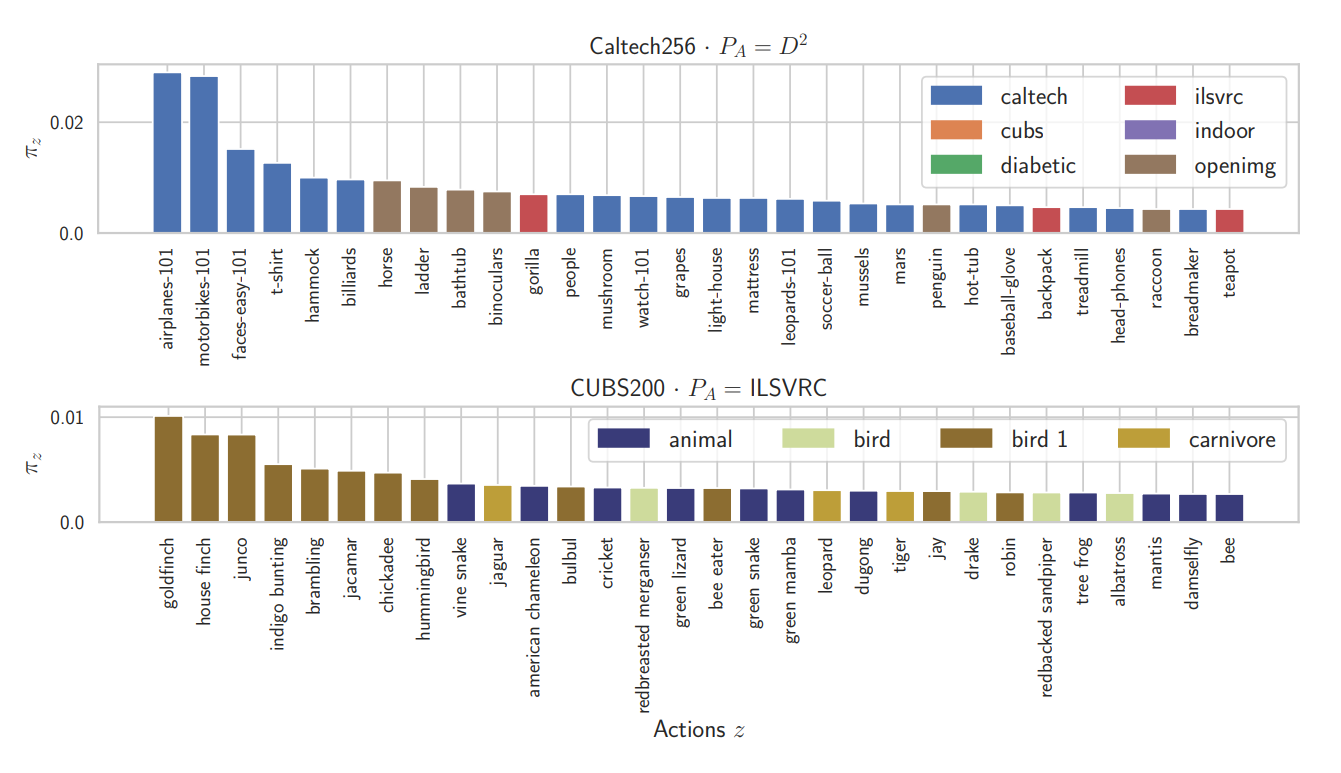
닫힌 세계에서는 높은 확률로 목표 모델의 클래스에 직접 대응되는 이미지들을 사용했습니다. 뿐만 아니라 해당 클래스를 표현하는 다른 데이터셋의 이미지도 학습했습니다.(Caltech256의 ladder)
열린 세계에서는 목표 모델과 질의 클래스 간의 명확한 일치가 없었습니다. 하지만 목표 클래스에 연관된 상위 개념(조류, 동물 등)을 주로 선택하였습니다.
다음은 적응형 질의에 활용한 각 보상 별 모델의 성능 실험 결과입니다:
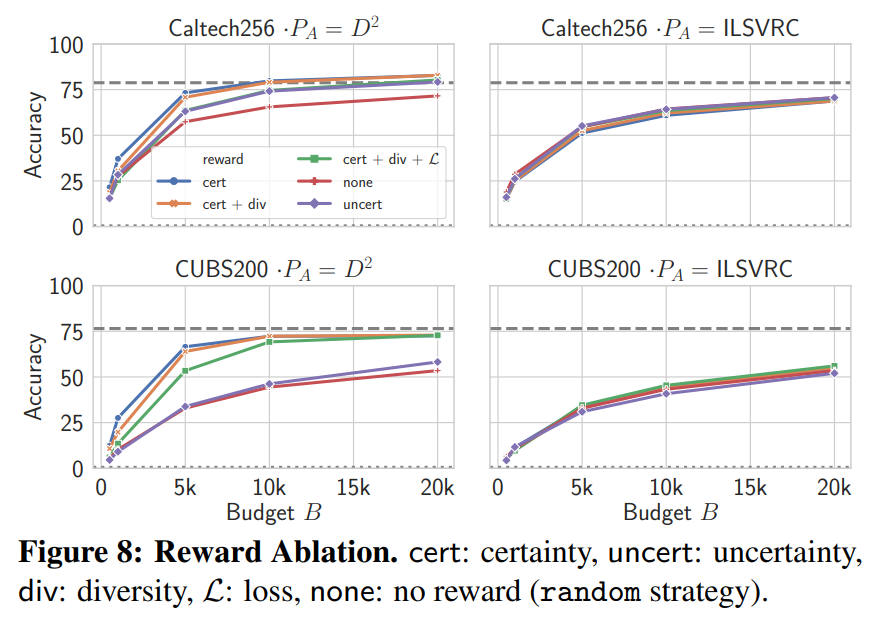
닫힌 세계에서는 확신 높은 샘플을 선택하는 \(R^{cert}\) 보상이 가장 우수한 성능을 보였으며, 샘플 효율성 향상에 가장 효과적이었습니다. 불확실한 샘플을 선택하는 \(R^{uncert}\) 보상은 아예 관련이 없는 이미지를 선택하게 되어 성능이 저하되었습니다.
열린 세계에서는 세 가지 보상 모두 성능 향상은 미미하거나 없었습니다.
다음은 복제 모델에 사용한 모델 구조별 성능 실험 결과입니다:
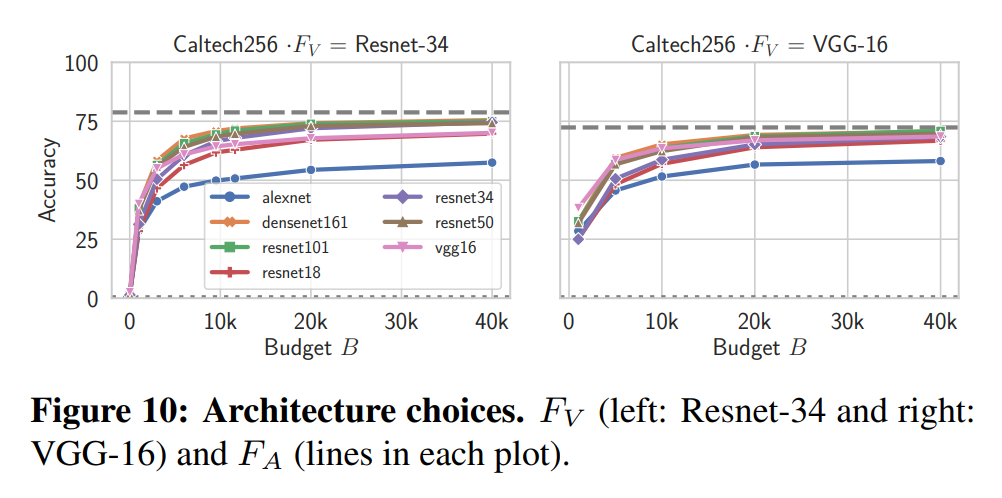
성능은 모델의 복잡도에 따라 정렬되었습니다. 가장 단순한 AlexNet은 낮은 성능을 보였으며 복잡한 ResNet-101과 DenseNet-161은 높은 성능을 보였습니다.
다른 모델 계통간의 복제 역시 가능했습니다. \(\text{VGG}\Rightarrow\text{ResNet}\)과 \(\text{ResNet}\Rightarrow\text{VGG}\) 모두 성능이 유지되었습니다.
다음은 실제 상용 모델 API를 대상으로 한 실험 결과입니다:
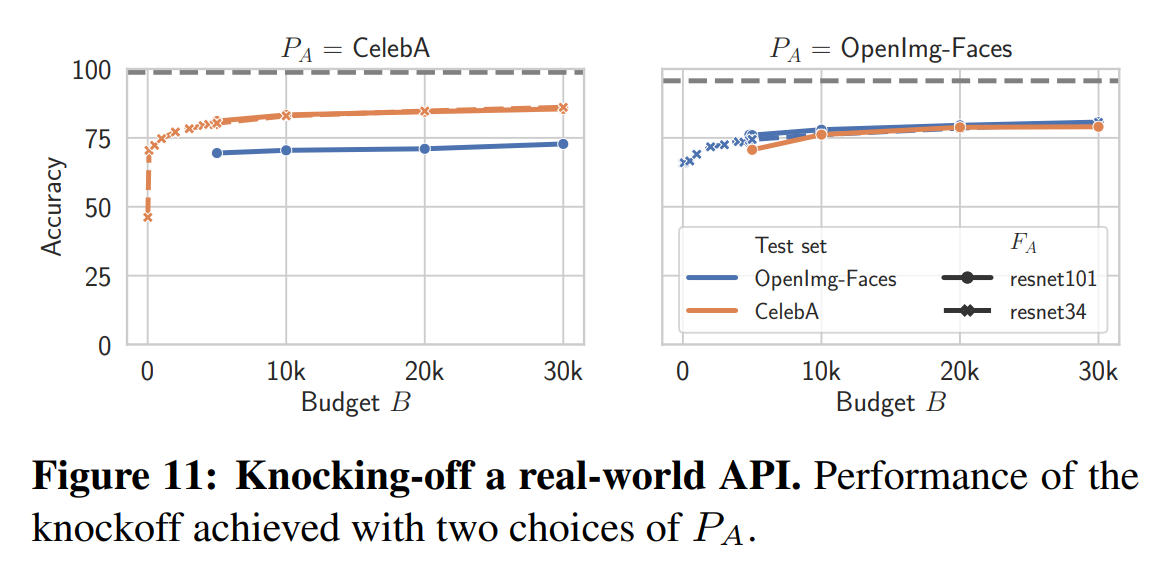
본 실험에서는 얼굴 속성 예측 모델 API를 대상으로 CelebA(220k개의 이미지), OpenImages-Faces(98k개의 이미지) 데이터 셋을 활용하였습니다. 질의 비용은 1000번의 질의당 1~2달러였습니다.
랜덤 샘플링 전략을 사용해 실험한 결과 복제 모델은 실제 API 대비 76~82% 성능을 달성할 수 있었습니다. 또한 모델 복잡도는 큰 영향이 없는 것을 확인할 수 있었습니다.
$30 수준으로 제작한 복제 모델은 이미지 수집, 전문가의 라벨링, 모델 튜닝 등 막대한 비용을 절감하면서도 강한 성능을 보여주었습니다.
결론
본 연구에서는 모델 기능 도용 문제를 다루었으며 블랙박스 접근만으로도 목표 모델의 기능을 효과적으로 복제할 수 있는 “Knockoff Nets” 프레임워크를 제안하였습니다. 이는 목표 모델의 구조나 훈련 데이터에 대한 사전 정보 없이도 높은 성능의 복제 모델을 생성할 수 있음을 실험을 통해 입증하였습니다. 또한 실제 상용 이미지 분석 API를 대상으로 한 실험에서도 복제 모델이 높은 성능을 달성하며 현실적인 위협 가능성을 보여주었습니다.
이러한 결과는 기능 도용이 이론적 연구에 그치지 않고 현실 세계에서 직접적인 위협이 될 수 있음을 시사합니다. 따라서 머신러닝 모델의 보호에 대한 새로운 대응 전략이 필요할 것으로 보입니다.