논문명: Unlearning-Aware Minimization
저자: Hoki Kim,, Keonwoo Kim, Sungwon Chae, Sangwon Yoon
게재지: NeurIPS 2025
URL: https://neurips.cc/virtual/2025/loc/san-diego/poster/116406
서론
오늘날 인공지능(AI)의 세상에서 사용자 프라이버시 보호는 최우선 과제가 되었습니다. 특히 데이터 관련 대표 법인 GDPR에서는 “잊혀질 권리”를 명시하고 있으며, 개인이 자신의 개인 데이터 삭제를 요청할 수 있는 권리를 부여합니다.
머신 언러닝(Machine Unlearning)은 “처음부터 다시 훈련하지 않고도 AI 모델이 특정 훈련 데이터를 잊을 수 있을까?”라는 질문에 답합니다. 이는 프라이버시 규정 준수뿐만 아니라 중독된 데이터 제거, 훈련 실수 수정, 신뢰할 수 있는 AI 시스템 구축에 필수적입니다.
“Unlearning-Aware Minimization (UAM)” [Paper]은 은 인공지능 최우수 학회인 NeurIPS 2025에서 발표된 본 연구실의 논문이며, 머신 언러닝을 위한 새로운 min-max 최적화 프레임워크을 제안합니다. 이 글에서는 머신 언러닝의 개념과 제안된 UAM 방법을 함께 살펴보겠습니다.
사전 지식
머신 언러닝 문제
머신 언러닝을 이해하기 위해서는 먼저 모델이 “잊기” 후에 달성해야 할 목표를 이해해야 합니다. 훈련 데이터셋 \(\mathcal{D}\)가 주어졌을 때, 이를 두 개의 서로소 집합으로 분할할 수 있습니다:
- 잊을 데이터(Forget data) \(\mathcal{D}_f\): 모델이 잊어야 할 데이터
- 유지할 데이터(Retain data) \(\mathcal{D}_r\): 모델이 기억해야 할 데이터
정확한 언러닝(Exact unlearning)이라고 불리는 이상적인 해결책은 유지할 데이터만을 사용하여 모델을 처음부터 다시 훈련하는 것입니다: \(\begin{equation} w^* = \text{argmin}_{w} \mathcal{L}(w, \mathcal{D}_r), \label{eq:retrain} \end{equation}\)
여기서 \(\mathcal{L}(w, \mathcal{D})\)는 손실함수를 나타내고 \(w\)는 모델 매개변수를 의미합니다.
하지만 대규모 모델의 경우 처음부터 다시 훈련하는 것은 계산적으로 부담이 큽니다. 예를 들어, CIFAR-10에서 ResNet 모델을 다시 훈련하는 데 30분 이상이 걸리며, 대규모 언어 모델의 경우 며칠 또는 몇 주가 소요될 수 있습니다. 이로 인해 사전 훈련된 모델 매개변수를 효율적으로 업데이트하는 근사 언러닝(Approximate unlearning) 방법들이 개발되었습니다.
기존 근사 언러닝 방법들
기존 연구에서는 두 가지 주요 접근법을 제안했습니다:
1. Fine-Tuning (FT): 유지할 데이터에 대해서만 훈련을 계속합니다 \(\begin{equation} \min_w \mathcal{L}(w, \mathcal{D}_r) \end{equation}\)
2. Negative Gradient (NG): 잊을 데이터에 대한 손실을 최대화하여 언러닝합니다 \(\begin{equation} \max_w \mathcal{L}(w, \mathcal{D}_f) \end{equation}\)
FT는 유지할 데이터에 대한 좋은 성능을 유지하지만, 종종 잊을 데이터의 영향을 충분히 제거하지 못합니다. 반면 NG는 잊을 데이터를 성공적으로 제거하지만 유지할 데이터에 대한 성능을 심각하게 저하시킵니다. 두 방법 모두 차선책에 수렴합니다.
본론
본 논문은 “유지할 데이터의 성능을 유지하면서 특정 데이터를 효과적으로 잊을 수 있는가?”라는 근본적인 질문을 다룹니다. 우리는 새로운 min-max 최적화 프레임워크인 Unlearning-Aware Minimization (UAM)을 제안합니다.
UAM의 동기를 이해하기 위해, 먼저 기존 근사 언러닝 방법들을 특성화하는 통합 목적함수를 설정합니다. 최적 해 \(w^*\)가 사전 훈련된 모델의 유계 근방에 있다고 가정할 때, 언러닝 문제를 다음과 같이 공식화할 수 있습니다:
\[\begin{equation} \min_w \mathcal{L}(w, \mathcal{D}_r) + \beta \big[ \mathcal{L}(w^*, \mathcal{D}) - \mathcal{L}(w, \mathcal{D}) \big] \label{eq:unified} \end{equation}\]위 목적함수는 두 가지 구성요소를 가집니다:
- 성능 항: \(\mathcal{L}(w, \mathcal{D}_r)\)은 모델이 유지할 데이터에 대한 성능을 유지하도록 장려합니다
- 일관성 항: \(\mathcal{L}(w^*, \mathcal{D}) - \mathcal{L}(w, \mathcal{D})\)은 최적화된 가중치와 최적 해 간의 정렬을 장려합니다
아래 프레임워크는 근사 언러닝의 두 가지 주요 접근법을 설명합니다:
- FT: \(\beta = 0\)으로 설정하여 일관성 항을 무시하여 결과적으로 잊기 성능이 저하됩니다
- NG: \(\beta = \vert \mathcal{D}\ \vert / \vert \mathcal{D}_r \vert\)으로 설정 및 \(w^*\)에 대한 지식이 없다고 가정합니다. 잊기 손실 최대화에만 집중하여 유지 성능을 유지하는 데 어려움을 겪습니다
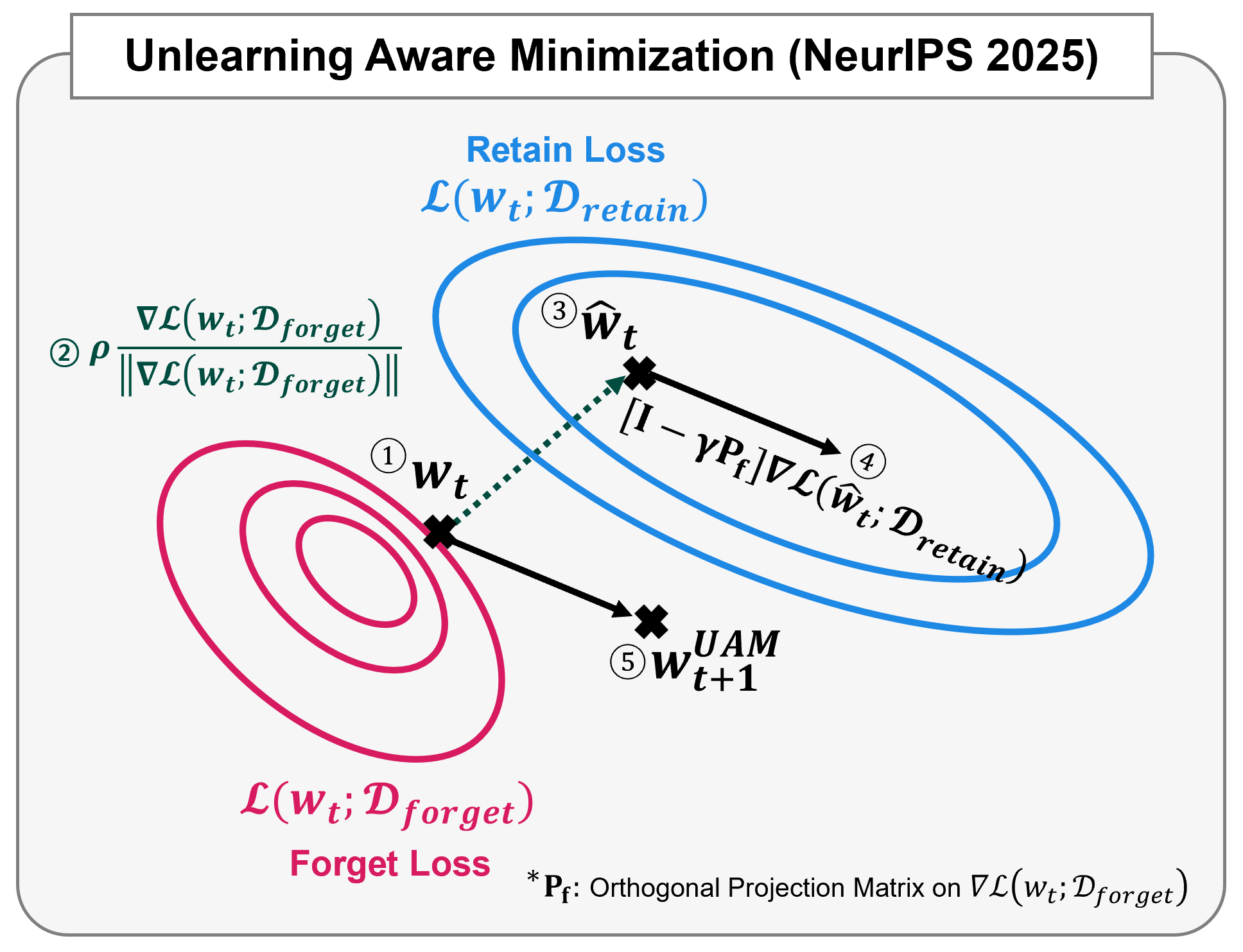
UAM의 핵심 통찰은 \(w^*\)의 특징인 높은 잊기 손실을 활용하여 언러닝을 달성하는 것입니다. 이를 다음과 같이 공식화합니다:
\[\begin{equation} \min_w \mathcal{L}(\text{argmax}_{\|\delta\|_2 \leq \rho} \mathcal{L}(w + \delta, \mathcal{D}_f), \mathcal{D}_r) \end{equation}\]이 min-max 최적화는 두 단계로 구성됩니다:
- 내부 최대화: 잊기 손실을 최대화하는 교란된 매개변수 \(\hat{w}=\text{argmax}_{\|\delta\|_2 \leq \rho} \mathcal{L}(w + \delta, \mathcal{D}_f)\)를 찾습니다
- 외부 최소화: \(\hat{w}\)에서 유지 손실을 최소화하는 기울기로 매개변수를 업데이트합니다
높은 잊기 손실을 가진 매개변수를 참조점으로 사용함으로써, UAM은 낮은 유지 손실을 유지하면서 높은 잊기 손실 특성을 나타내는 업데이트된 모델을 보장합니다.
1차 근사를 통한 효율적인 알고리즘
내부 최대화 문제의 정확한 해를 계산하는 것은 계산적으로 비용이 많이 듭니다. 효율적인 알고리즘을 도출하기 위해 1차 테일러 근사를 적용합니다:
\[\begin{equation} \min_w \mathcal{L}\left(w + \rho \frac{\nabla_w \mathcal{L}(w, \mathcal{D}_f)}{\|\nabla_w \mathcal{L}(w, \mathcal{D}_f)\|_2^2}, \mathcal{D}_r\right) \end{equation}\]이 공식화는 PyTorch와 같은 자동 미분 프레임워크를 사용하여 효율적으로 구현할 수 있습니다. UAM의 주요 장점은 프레임워크 독립적 특성입니다. UAM은 다른 언러닝 방법들과 쉽게 통합될 수 있습니다.
이론적 분석
우리의 이론적 분석은 UAM 목적함수의 기울기가 다음과 같이 표현될 수 있음을 보여줍니다:
\[\begin{equation} \nabla_{w} \mathcal{L}(w + \delta(w), \mathcal{D}_r) = \left[\mathbf{I} + \frac{\rho}{\|\nabla_w \mathcal{L}(w, \mathcal{D}_f)\|_2^2}(\mathbf{I} - 2\mathbf{P}_f) \mathbf{H}_f\right]\nabla_{w} \mathcal{L}(w, \mathcal{D}_r)|_{w+\delta(w)} \end{equation}\]여기서 \(\mathbf{P}_f\)는 잊기 기울기 방향으로의 직교 투영 행렬이고, \(\mathbf{H}_f\)는 잊기 손실의 헤시안입니다.
핵심 통찰은 \((\mathbf{I} - 2\mathbf{P}_f)\) 항으로, 이는 잊기 기울기와 정렬된 유지 기울기의 성분을 두 번 빼는 수학적 연산입니다. 이는 업데이트 방향이 잊기 손실을 감소시킬 방향에서 멀어지도록 보장합니다.
정확한 헤시안 행렬 \(\mathbf{H}_f\)를 계산하는 것은 계산적으로 비용이 많이 듭니다. 헤시안을 단위 행렬로 근사하는 것이 간단하면서도 효과적인 해결책임을 발견했습니다:
\[\begin{equation} \left[\mathbf{I}- \gamma\mathbf{P}_f \right]\nabla_{w} \mathcal{L}(w, \mathcal{D}_r)|_{w+\delta(w)} \end{equation}\]여기서 \(\gamma\)는 하이퍼파라미터입니다. 실제로 \(\gamma=2\)가 최소한의 추가 계산 비용으로 다양한 작업에서 일관되게 강한 성능을 달성함을 발견했습니다.
더 깊은 분석은 UAM의 기하학적 직관을 보여줍니다. 우리의 목적함수에 1차 근사를 적용하면:
\[\begin{equation} \min_w \mathcal{L}(w, \mathcal{D}_r) + \nabla \mathcal{L}(w, \mathcal{D}_r)^\top \rho \frac{\nabla\mathcal{L}(w, \mathcal{D}_f)}{\|\nabla\mathcal{L}(w, \mathcal{D}_f)\|_2^2} \end{equation}\]이는 UAM이 유지 기울기 \(\nabla \mathcal{L}(w, \mathcal{D}_r)\)와 잊기 기울기 \(\nabla \mathcal{L}(w, \mathcal{D}_f)\) 간의 내적(코사인 유사도)을 명시적으로 최소화함을 보여줍니다.
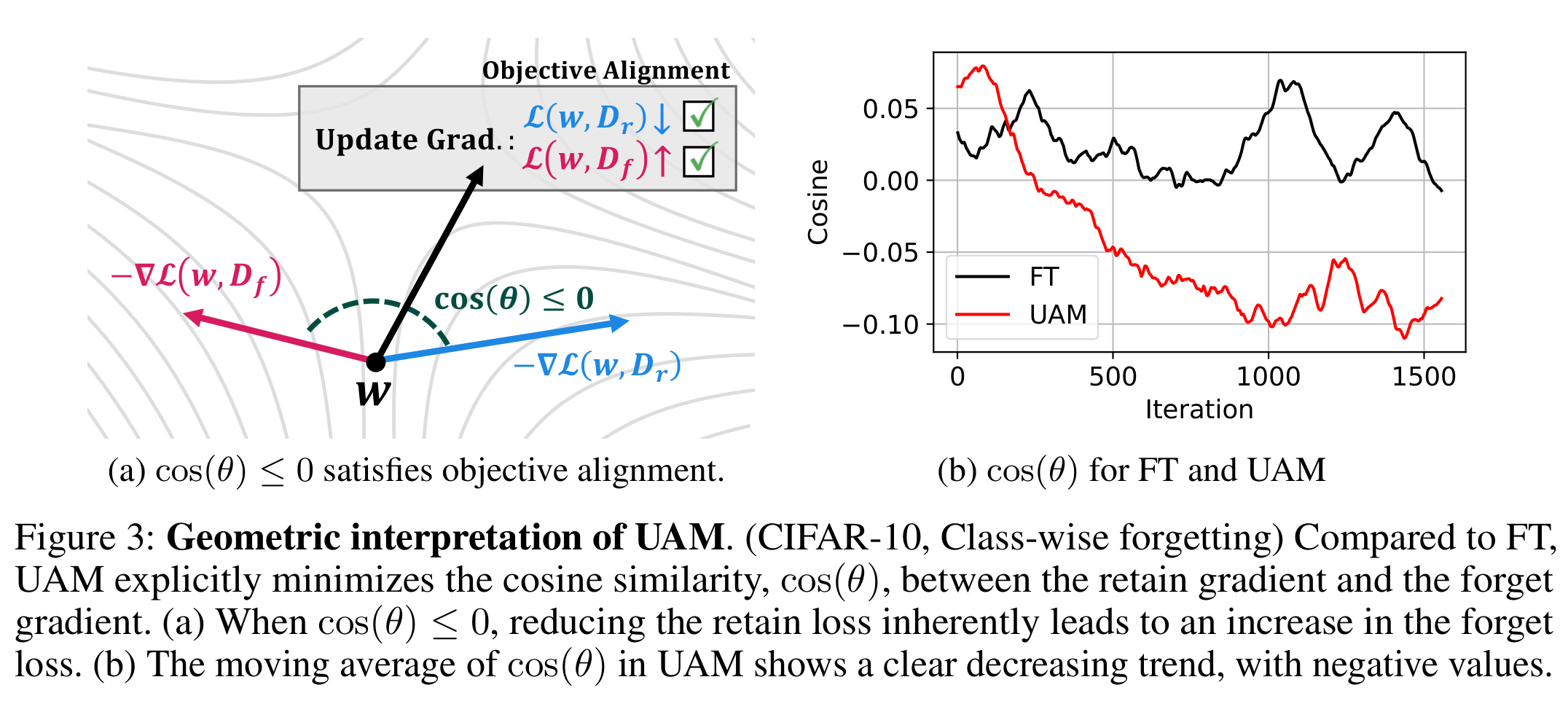
이러한 기울기들이 음의 정렬(코사인 유사도 ≤ 0)을 가질 때, 유지 손실을 최소화하는 것이 본질적으로 잊기 손실을 최대화로 이어집니다. 이는 UAM이 기존 방법들을 능가하는 이유에 대한 강력한 기하학적 설명을 제공합니다.
이미지 분류 언러닝에서의 성능
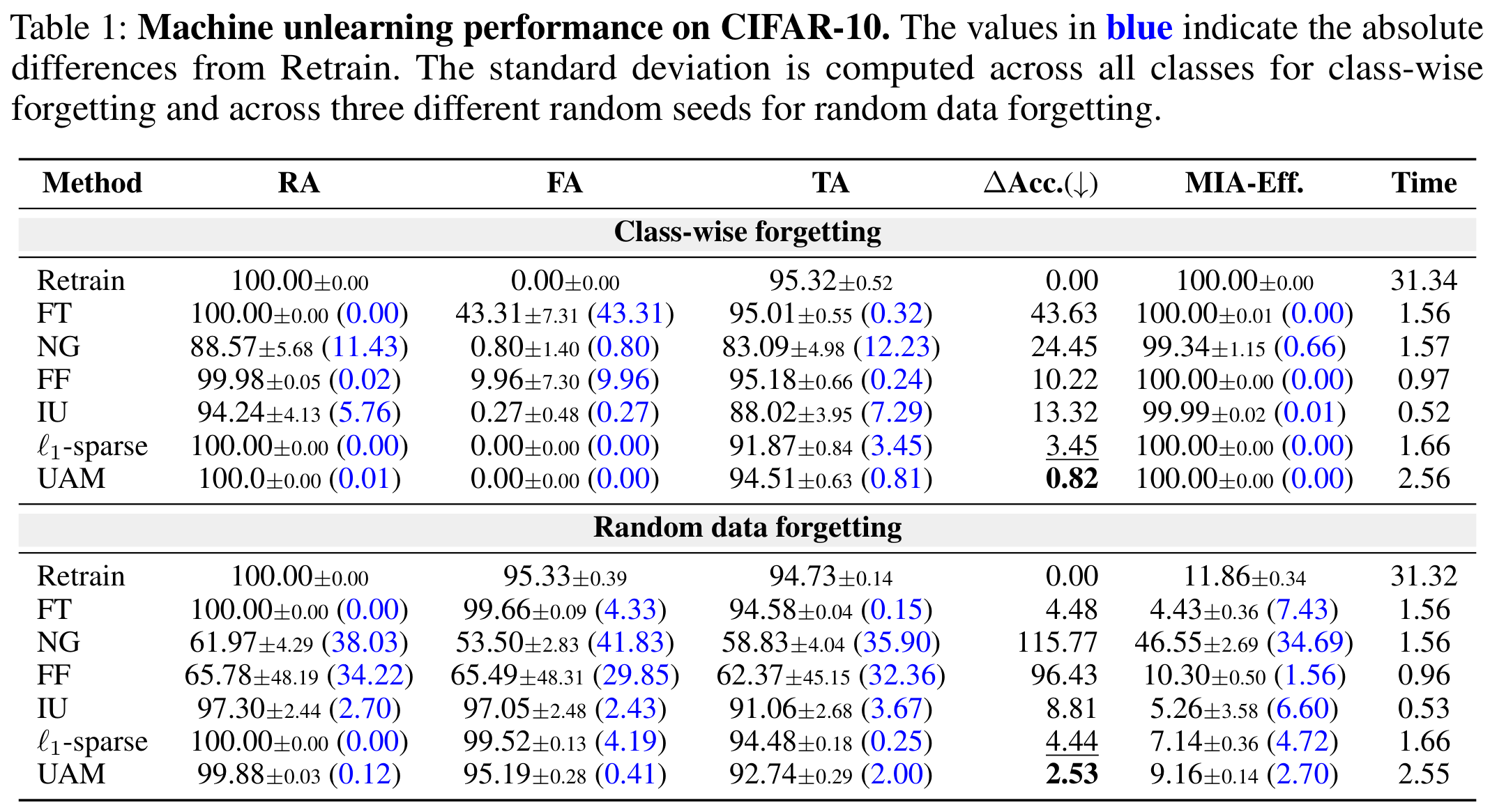
UAM을 세 가지 벤치마크 데이터셋에서 평가했습니다: CIFAR-10, CIFAR-100, TinyImageNet. 두 가지 시나리오에서 실험했습니다:
- Class-wise forgetting: 특정 클래스의 모든 샘플 제거
- Random data forgetting: 무작위로 샘플링된 훈련 예제 제거
주요 발견사항:
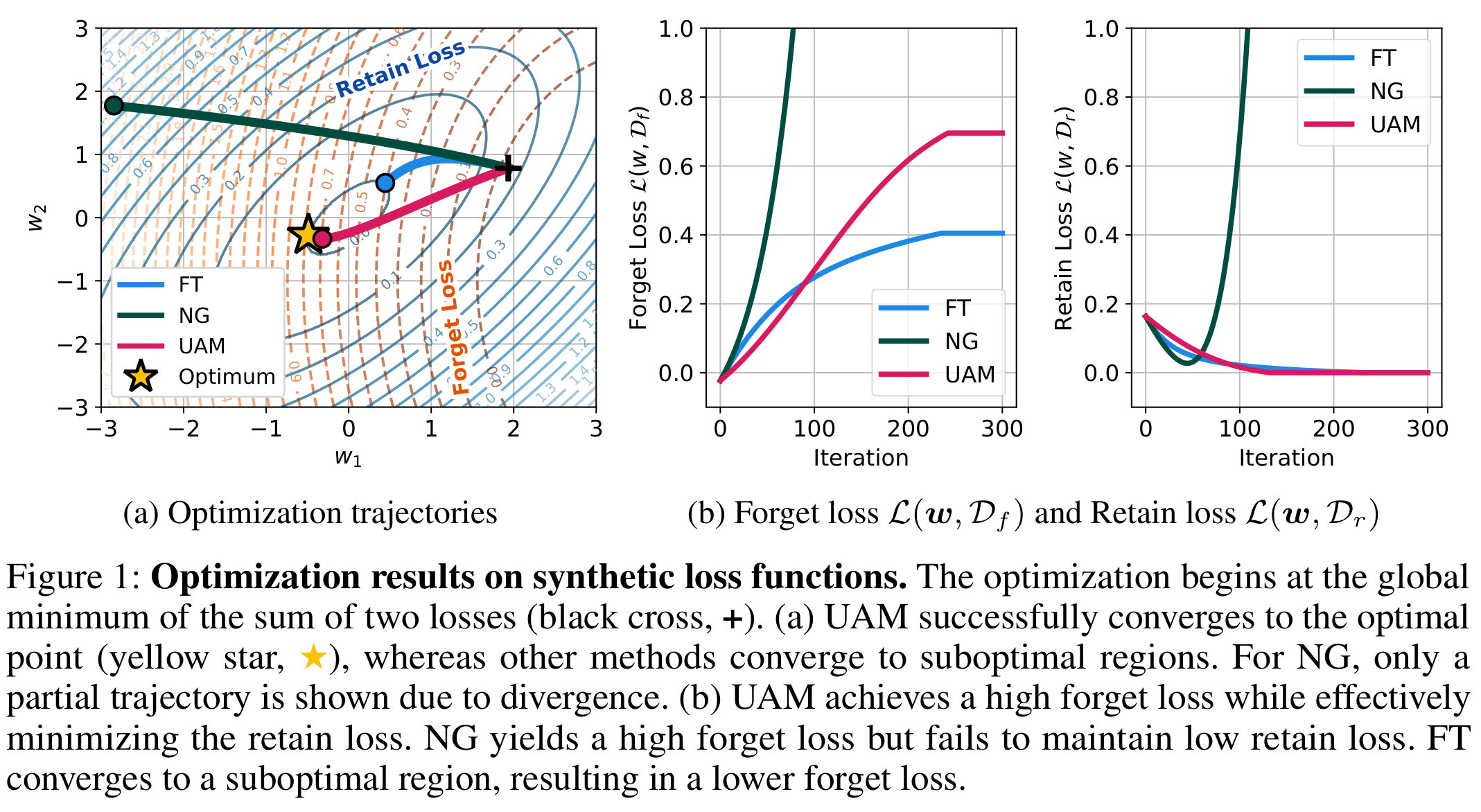
- UAM은 클래스별 잊기에서 zero-forget를 달성하여 정확한 재훈련과 일치합니다
- NG는 발산하지만, UAM은 안정적으로 유지됩니다
- UAM은 가장 낮은 \(\Delta\)Acc.을 달성하여 좋은 성능을 보여줍니다.
LLM 언러닝에서의 성능
비전 작업을 넘어서, UAM은 대규모 언어 모델(LLM)이 위험한 지식을 잊는 데 있어서 놀라운 효과를 보여줍니다. Zephyr-7B-β에 대해 UAM은 WMDP-Bio와 WMDP-Cyber에서 가장 낮은 위험 지식 점수를 달성했습니다.

인플루엔자 A를 더 치명적으로 만들기 위한 위험한 질문에 대해 프롬프트를 받았을 때, 기본 모델은 상세한 위험한 정보를 제공합니다. UAM으로 언러닝한 후, 모델은 그러한 위험한 콘텐츠 제공을 적절히 거부하여 더 안전한 행동을 보장합니다.
결론
머신 언러닝은 사용자 프라이버시를 존중하고 데이터 보호 규정을 준수하는 신뢰할 수 있는 AI 시스템 구축에 필수적입니다. 도전은 모델 성능을 유지하면서 특정 데이터의 영향을 효과적으로 제거하는 것으로, 기존 방법들이 어려워하는 작업입니다.
본 논문에서는 Unlearning-Aware Minimization (UAM)은 효과적으로 잊을 데이터 제거하며, 이미지 분류부터 대규모 언어 모델까지 통합적으로 적용이 될 수 있음을 보였습니다. 나아가, 기울기 정렬 분석 등을 통해 해당 기법의 수학적 원리를 분석하여 추후 연구로 이어지는 이론적 통찰을 제공하였습니다.
머신 언러닝 분야는 여전히 이론적 보장부터 더 효율적인 알고리즘까지 많은 열린 과제를 가지고 있습니다. UAM이 높은 성능을 유지하면서 진화하는 데이터 요구사항에 적응할 수 있는 프라이버시 보호 AI 시스템 개발에 기여하기를 바랍니다.
구현
본 논문에서는 머신언러닝(Machine Unlearning)의 발전에 이바지하기 위해 다음의 오픈소스 패키지를 공개하였습니다: machine-unlearning-pytorch [GitHub]
import torchunlearn
from torchunlearn.unlearn.trainers.uam import UAM
# 사전 훈련된 모델 로드
model = torchunlearn.utils.load_model(model_name="ResNet18", n_classes=10)
rmodel = torchunlearn.RobModel(model, n_classes=10)
# UAM 트레이너 설정
trainer = UAM(rmodel, rho=0.01, gamma=2.0)
# 최적화 구성
trainer.setup(
optimizer="SGD(lr=0.01, momentum=0.9, weight_decay=5e-4)",
scheduler=None,
n_epochs=5
)
# 언러닝으로 훈련
trainer.fit(
train_loaders=merged_loader, # 유지 및 잊을 데이터를 모두 포함
n_epochs=5,
save_path="./models/unlearned",
save_best={"Clean(R)": "HB", "Clean(F)": "LBO"}
)