논문명: Amnesiac Machine Learning
저자: Laura Graves, Vineel Nagisetty, Vijay Ganesh (University of Waterloo)
게재지: 35th AAAI Conference on Artificial Intelligence
URL: https://cdn.aaai.org/ojs/17371/17371-13-20865-1-2-20210518.pdf
본 논문은 GDPR의 “잊힐 권리”(Right to be Forgotten)를 중심으로 딥러닝에 대한 컴플라이언스를 준수하기 위해 언러닝 모델을 제안하고 있습니다. 특히, 훈련된 신경망에서 학습된 데이터를 네트워크의 성능을 저해하지 않으면서, 모델 반전 공격, 멤버십 추론 공격과 같은 최신 데이터 유출 공격에 취약하지 않도록 안전하고 효율적으로 제거하는 방법으로 Amnesiac Unlearning을 소개하고 있습니다.
Amnesiac Unlearning
Amnesiac Unlerning이란?
“Amnesiac Unlearning”은 기계 학습 모델에서 특정 데이터를 선택적으로 제거하는 기술인 언러닝 방식 중 하나로 삭제 요청 데이터가 포함된 배치(batch)의 업데이트를 기록한 후 삭제함으로써 데이터의 흔적을 제거하는 알고리즘입니다.
Amnesiac Unlearning은 기존의 다른 언러닝 방식에 비해 데이터 유출 공격을 효과적으로 방어할 수 있습니다. 적은 양의 데이터를 삭제하는 경우 삭제 데이터를 효과적으로 잊으며 모델의 성능은 최대한으로 보존할 수 있는 장점을 지니고 있습니다.
하지만 해당 방식은 삭제 데이터의 양이 많아질수록 모델의 성능이 기하급수적으로 나빠지는 단점을 지니고 있습니다. 따라서 데이터를 처리하는 상황에 따라 알맞는 언러닝 알고리즘을 택할 필요가 있습니다.
랜덤 라벨링 언러닝
본 논문은 Amnesiac Unlearning과 더불어 랜덤 라벨링 방식을 실험군으로 두고 있습니다.
랜덤 라벨링 방식은 민감한 데이터, 삭제 요청 데이터를 임의로 선택된 잘못된 레이블로 다시 라벨링한 후 수정된 데이터셋으로 몇 번의 반복(iteration)동안 네트워크를 재훈련합니다.
예를 들어 이미지 분류에서 “고양이”로 분류된 경우 이를 임의로 “강아지”와 같은 잘못된 레이블로 변경하여 “고양이”에 대한 분류 성능을 현저히 낮추는 것입니다.
다음은 랜덤 라벨링 방식의 코드 작성 방법입니다.
import torch
import copy
import random
target_index = [] # 삭제 요청 데이터
nontarget_index = [] # 삭제 요청 데이터를 제외한 remained data
# 81을 삭제 요청 데이터로 설정
for i in range(0, len(testdata)):
if testdata[i][1] == 81:
target_index.append(i)
else:
nontarget_index.append(i)
# traindata의 모든 요소를 새로운 객체로 복사하여 unlearning_data 생성
unlearning_data = copy.deepcopy(traindata)
unlearning_labels = list(range(100))
unlearning_labels.remove(81)
# 삭제 요청된 데이터(81)의 레이블을 무작위로 변경
for i in range(len(unlearning_data)):
if unlearning_data.targets[i] == 81:
unlearning_data.targets[i] = random.choice(unlearning_labels)
# 새로운 학습 데이터 로더 생성
unlearning_train_loader = torch.utils.data.DataLoader(unlearning_data, batch_size=64, shuffle=True)
해당 코드를 통해 81을 삭제 요청 데이터라고 가정했을 때 81을 랜덤의 다른 클래스 값으로 변경하여 새로운 라벨을 부여한 후 언러닝 데이터(Unlearning data)와 잔여 데이터(remain data)를 분리합니다.
Amnesiac Unlearning 알고리즘에 대하여
Amnesiac Unlearning의 알고리즘을 설명하는 수식은 다음과 같습니다:
\[\theta_{M'} = \theta_{initial} + \sum_{e=1}^{E} \sum_{b=1}^{B} \Delta \theta_{e,b} - \sum_{sb=1}^{SB} \Delta \theta_{sb} = \theta_M - \sum_{sb=1}^{SB} \Delta \theta_{sb}\]해당 수식은 기존 모델의 파라미터에서 삭제 요청에 해당하는 데이터가 포함되어 있는 배치의 업데이트를 제거하는 방식을 표현하고 있습니다.
삭제 요청 데이터가 포함된 배치의 수가 적을수록 원본 모델과 언러닝 모델을 적용한 모델의 차이가 상대적으로 적어 모델의 효율성에 미치는 영향이 작습니다.
해당 알고리즘은 민감한 데이터의 학습된 정보를 레이저처럼 집중적으로 제거하며 단일 기록에 대한 학습된 데이터를 모델에서 최소한의 영향으로 제거할 수 있습니다.
다음은 Amnesiac Unlearning의 코드 작성 예시입니다.
def train(model, epoch, loader, returnable=False):
model.train()
delta={}
#PyTorch 모델의 가중치(weight)와 편향(bias)에 대해 초기화 작업을 수행
for param_tensor in model.state_dict(): #PyTorch 모델의 모든 학습 가능한 매개변수(가중치 및 편향)를 포함하는 딕셔너리를 반환
if "weight" in param_tensor or "bias" in param_tensor:
delta[param_tensor] = 0
if returnable:
thracc=[]
nacc=[]
for batch_idx, (data, target) in enumerate(loader):
#타겟 클래스가 81인 경우 학습 전 모델의 가중치 및 편향 저장
if 81 in target:
before={}
for param_tensor in model.state_dict():
if "weight" in param_tensor or "bias" in param_tensor:
before[param_tensor] = model.state_dict()[param_tensor].clone()
optimizer.zero_grad()
output=model(data)
loss=criterion(output, target)
loss.backward()
optimizer.step()
#타겟 클래스가 81인 경우 학습 후 모델의 가중치 및 편향 저장
if 81 in target:
after={}
for param_tensor in model.state_dict():
if "weight" in param_tensor or "bias" in param_tensor:
after[param_tensor] = model.state_dict()[param_tensor].clone()
#가중치 변화량 업데이트
for key in before:
delta[key]=delta[key] + after[key]-before[key]
if batch_idx % log_interval==0: #간격이 10일때마다 학습 상태출력
print("\rEpoch: {} [{:6d}]\tLoss: {:.6f}".format(
epoch, batch_idx*len(data), loss.item()
), end="")
if returnable and False:
#타겟 데이터의 정확도 저장
thracc.append(test(model, target_test_loader, dname="Threes only", printable=False))
#10번째 배치마다 remain data(non_target data) 정확도 저장
if batch_idx % 10 ==0:
nacc.append(test(model, nontarget_test_loader, dname="nonthree only", printable=False))
model.train()
if returnable:
return thracc, nacc, delta
해당 코드에서 볼 수 있듯이 삭제 요청 데이터인 81이 포함된 경우 모델 학습 전(before)과 후(after)모델의 가중치 및 편향을 저장한 후 그 차이(배치 업데이트)를 기록합니다. 따라서 Amnesiac Unlearning의 핵심 개념은 삭제 요청이 들어온 경우 삭제 요청 데이터에 대한 파라미터 업데이트인 delta를 삭제하는 것입니다.
데이터 유출 공격(Data Leak Attack)
모델 반전 공격(Model Inversion Attack)
모델 반전 공격은 클래스 정보 유출 공격으로 공격자가 원칙적으로 알 수 없어야 하는 일반화된 정보를 획득할 수 있게 하는 공격입니다.
예를 들어 공격자가 특정 개인이 암에 걸릴 위험이 높은 클래스가 “주로 고령 남성”으로 일반화된다는 사실을 알아냈다면 공격은 성공한 것입니다. 즉, 공격자는 모델 반전 공격을 통해 알아내고자 하는 클래스가 무엇을 나타내는지에 대한 정보를 알아낼 수 있습니다.
멤버십 추론 공격(Membership Inference Attack)
멤버십 추론 공격은 특정 기록이나 기록의 집합이 훈련 데이터에 포함되어 있는지 여부를 추론하는 공격입니다. 예를 들어 공격자가 어떤 개인이 파산 위험을 예측하는 모델을 훈련하는 데이터셋에 포함되어 있다는 사실을 알게 된 경우 해당 공격은 성공한 것으로 판단됩니다..
이때, 멤버십 추론 공격은 공격자가 대상 모델을 훈련하는데 사용한 데이터와 유사한 분포를 가진 데이터를 가지고 있다는 것을 가정합니다.
성능 검증
Amnesiac Unlearning의 성능을 확인하기 위해서 본 논문은 3가지 방법을 제안하고 있습니다.
기본적인 실험은 파이토치(pytorch)를 기반으로 MNIST 손글씨 데이터셋과 CIFAR 100을 대상으로 이루어지고 있으며 공격 대상 모델은 ResNet18을 사용하고 있습니다.
Retrain-Based & Accuracy-based
Amnesiac Unlearning의 성능을 검증하기 위해 본 논문은 원본 데이터에서 삭제 요청 데이터를 제거한 모델을 단순 재학습한 모델, 랜덤 라벨링 방식의 언러닝 방법을 적용한 모델, Amnesiac Unlearning을 적용한 모델의 성능을 비교하고 있습니다.
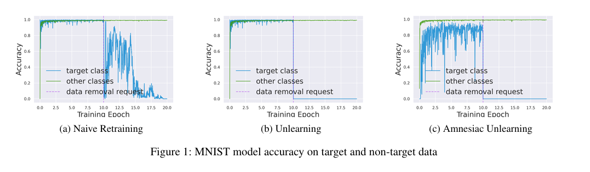
아래 그래프는 각각 MNIST 손글씨 데이터셋에 대해 재학습, 랜덤 라벨링, Amnesiac 언러닝 세 가지 모델을 학습한 결과입니다. 세 가지 방법 모두 남아있는 데이터(Remain Data)에 대한 모델의 정확도는 유지되고 있다는 것을 확인할 수 있습니다.
하지만 단순 재학습의 경우 삭제 요청 데이터가 포함된 정보를 모델이 잊는 시간이 비교적 오래 걸립니다. 그에 비해 랜덤 라벨링 방식의 언러닝과 Amnesiac Unlearning의 경우 데이터 삭제 요청 이후 삭제 요청 데이터에 대한 정확도가 급격하게 하락하는 것을 볼 수 있으며
세 가지 방법 중 Amesiac Unlearning이 가장 빠르게 데이터를 잊는 것을 확인할 수 있습니다. 삭제 요청 데이터에 대한 정확도를 하락하는 것은 해당 모델이 데이터를 잊는다는 의미입니다.

아래 그래프는 CIFAR100 데이터셋에 세 가지 모델을 학습한 결과입니다. CIFAR 100에 대해서도 MNIST 손글씨 데이터셋과 유사한 결과가 나온다는 것을 알 수 있습니다.
Attack-Based
본 논문에서는 Amnesiac Unlearning의 성능을 검증하기 위해 세 모델에 모델 반전 공격과 멤버십 추론 공격을 수행하여 삭제 요청된 데이터에 대한 모델의 공격 성공률을 비교하고 있습니다.
모델 반전 공격과 멤버십 추론 공격의 성공률이 낮을수록 삭제 요청 데이터를 잘 잊고 있다는 것을 의미합니다. 즉, 언러닝 성능이 높다라고 표현합니다.

원본 모델의 경우 모델 반전 공격에 취약하여 공격자가 특정 클래스에 대한 정보를 추출할 수 있습니다.
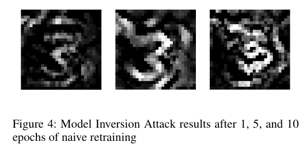
단순 재학습의 경우 10번의 에포크 이후에도 클래스의 특성을 알아볼 수 있는 형태를 유지하고 있습니다. 즉, 민감한 클래스 정보의 유출을 방지하는 효과가 거의 없다는 것을 확인할 수 있습니다.

그에 비해 랜덤 라벨링 방식의 언러닝의 경우 즉각적으로 유용한 클래스 정보를 획득할 수 없도록 차단하였습니다. 첫 번째 에포크부터 기존의 형태를 알아보기 매우 어려우며 에포크를 거칠수록 방어 성능이 증가하고 있습니다.

Amnesiac Unlearning의 경우 랜덤 라벨링 방식의 언러닝과 마찬가지로 즉각적으로 유용한 클래스 정보를 획득할 수 없도록 차단하였습니다. 특히 공격자의 입장에서 활용할 수 있는 기울기(gradient)정보가 거의 없으므로 반전된 이미지는 원본 형태를 거의 표현(복원)하지 못합니다. 즉, 랜덤 라벨링 방식과 Amnesiac Unlearning는 모두 모델 반전 공격을 잘 방어하는 것을 확인할 수 있습니다.
다음으로 본 논문은 세 가지 모델에 대해 멤버십 추론 공격에 대한 방어 성능을 측정합니다. 언러닝 대상 데이터에 대한 멤버십 추론 공격 성공률이 낮을수록 언러닝 성능이 높은 것을 의미합니다.
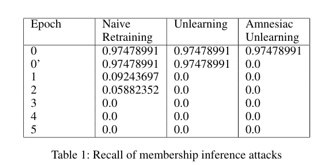
이때, 해당 표에서 에포크 0은 데이터를 제거하기 전 멤버십 추론 공격의 결과이며 에포크 0’는 데이터 수정 후 재학습 전 공격 결과를 의미합니다.
단순 재학습의 경우 곧바로 멤버십 추론 공격을 완전히 방어하지 못하는 모습을 보입니다. 반면 단순 라벨링과 Amnesiac 언러닝 모델의 경우 모두 1 에포크 이내의 재훈련만으로 멤버십 추론 공격을 효과적으로 방어할 수 있습니다. 이 때 랜덤 라벨링 방식에서 에포크 0’에 대해 방어 효과가 없는 이유는 특정 데이터의 라벨링을 다르게 하여도 모델의 내부 가중치는 그대로 남아 있어 모델 내부에 해당 데이터를 학습한 흔적이 있기 때문입니다.
결론
Amnesiac Unlearning의 경우 특정 데이터 샘플에서 학습된 정보를 제거하는데 매우 효과적이나 너무 자주 사용할 경우 모델 성능에 유의미한 영향을 미칠 수 있습니다. 즉, 삭제 요청 데이터가 많은 경우 모델의 성능이 급격하게 감소하여 유용성 측면에서 리스크가 발생합니다.
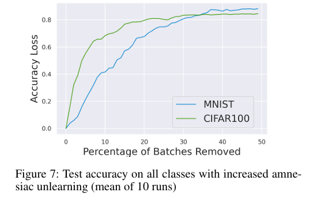
위 그래프에서 확인할 수 있듯이 1%이하의 배치가 제거된 경우 모델의 정확도를 보장할 수 있으나 제거되는 배치 수가 많아질수록 모델의 정확도가 급격하게 감소되는 것을 확인할 수 있습니다.
따라서 소량의 데이터를 제거하는 경우 Amnesiac Unlearning은 데이터 유출 공격을 방어하면서 효과적으로 데이터를 잊고 모델 전체에 큰 영향을 주지 않아 좋은 방법이 될 수 있지만 대량의 데이터를 제거하는 경우에는 다른 방식의 언러닝 방식을 고려할 필요가 있습니다.