논문명: Approximate Data Deletion from Machine Learning Models
저자: Zachary Izzo, Mary Anne Smart, Kamalika Chaudhuri, and James Zou
게재지: International Conference on Artificial Intelligence and Statistics (AISTATS) 2020
서론
기계 학습 모델에서 특정 데이터를 삭제하는 것은 개인정보 보호와 규제 준수를 위해 중요한 과제입니다. GDPR(General Data Protection Regulation) 및 CCPA(California Consumer Privacy Act)와 같은 규제는 개인이 자신의 데이터를 삭제할 수 있는 ‘잊힐 권리(Right to be Forgotten)’를 보장합니다. 그러나 모델에서 데이터를 삭제하더라도 그 데이터의 흔적이 완전히 사라지지 않을 수 있습니다.
기존 방법은 데이터를 삭제하기 위해 모델을 처음부터 다시 학습(retraining)해야 했습니다. 하지만 이는 계산 비용이 크고 비효율적입니다. 본 논문에서는 선형 회귀(Linear Regression) 및 로지스틱 회귀(Logistic Regression) 모델에서 효율적으로 데이터를 삭제할 수 있는 새로운 방법인 Projective Residual Update (PRU)를 제안합니다. PRU는 데이터 차원에 대해 선형적인 계산 복잡도를 가지며, 데이터셋 크기와 독립적입니다.
또한, “Approximate Data Deletion from Machine Learning Models”에서는 데이터 삭제의 효과를 평가하기 위한 새로운 지표인 Feature Injection Test (FIT)를 도입하여 언러닝(Unlearning)의 효과성을 정량적으로 측정합니다. 이러한 접근은 데이터 삭제 과정에서의 효율성을 높이고, 개인정보 보호를 위한 규제 준수를 보다 효과적으로 지원할 수 있을 것입니다.
사전 지식
Projective Residual Update(PRU)와 Feature Injection Test(FIT)를 이해하기 위해 필요한 주요 표기법과 문제 설정을 설명합니다.
주요 표기법(Key Notation)
-
\(n\): 전체 훈련 데이터 포인트 수
-
\(d\): 데이터 차원
-
\(k\): 모델에서 삭제할 데이터 포인트 수
-
\(θ ∈ ℝ^d\): 모델 파라미터
-
\(D^full = {(x_i, y_i)}_{i=1}^n ⊆ ℝ^d × ℝ\): 전체 훈련 데이터 집합
-
\(X = [x_1 ... x_n]^T ∈ ℝ^(n×d)\): 전체 데이터 행렬
-
\(Y = (y_1, ..., y_n)^T ∈ ℝ^n\): 응답 벡터
손실 함수(Loss Function)
선형 회귀 모델의 정규화된 손실 함수는 다음과 같이 정의됩니다.
\[\begin{equation} L^{\text{full}}(\theta) = \sum_{i=1}^n \ell(x_i, y_i; \theta) + \frac{\lambda}{2}\|\theta\|_2^2 \end{equation}\]여기서
-
\(ℓ(x_i,y_i;θ)=12(θ⊤x_i−y_i)2\ell(x_i, y_i; \theta) = \frac{1}{2}(\theta^\top x_i - y_i)^2ℓ(x_i,y_i;θ)=21(θ⊤x_i−y_i)2\) 는 ‘단일 데이터 포인트에 대한 손실’입니다.
-
\(\lambda > 0\) 는 ‘정규화 강도’를 의미합니다.
이때, 삭제된 데이터를 제외한 손실 함수는 아래와 같이 표현합니다.
\[\begin{equation} L^{\backslash k}(\theta) = \sum_{i=k+1}^n \ell(x_i, y_i; \theta) + \frac{\lambda}{2}\|\theta\|_2^2 \end{equation}\]모델 매개변수(Model Parameters)
- \(\theta^{\text{full}} = \arg\min_\theta L^{\text{full}}(\theta)\) 는 ‘전체 데이터셋으로 학습된 모델 파라미터’ 입니다.
- \(\theta^{\backslash k} = \arg\min_\theta L^{\backslash k}(\theta)\) 는 ‘삭제된 데이터를 제외한 모델 파라미터’ 입니다.
본론
본 논문에서는 선형 및 로지스틱 회귀 모델에서 데이터를 효율적으로 삭제할 수 있는 새로운 방법인 Projective Residual Update(PRU)와 새로운 지표인 Feature Injection Test(FIT)를 제안합니다.
Projective Residual Update(PRU)
Projective Residual Update(PRU)는 삭제 요청된 데이터를 제외한 모델 파라미터를 근사적으로 계산하는 효율적인 알고리즘입니다.
PRU의 핵심 아이디어
- 삭제할 데이터 포인트에 대한 잔차(residual)를 계산합니다.
- 잔차(residual)를 삭제할 데이터의 특성 공간을 활용하여 모델 파라미터를 업데이트합니다.
- 수정된 잔차(residual)를 기반으로 최종 파라미터를 계산합니다.
PRU의 핵심 수식
\[\begin{equation} \theta^{\text{res}} = \theta^{\text{full}} + proj_{\text{span}(x_1,...,x_k)}(\theta^{\backslash k} - \theta^{\text{full}}) \end{equation}\]여기서 \(\text{proj}_{\text{span}(x_1, \ldots, x_k)}(\cdot)\) 는 ‘삭제할 데이터의 특성 공간을 기반으로 한 업데이트 연산’ 입니다.
PRU 알고리즘 설명
PRU가 작동하는 방식을 이해하기 위해 알고리즘 1과 알고리즘 2를 살펴보겠습니다.
Algorithm 1: Projective Residual Update(PRU)
textprocedure PRU(X, Y, H, θ_full, k)
# Step 1: Leave-k-out predictions 계산
Ŷ_k ← LKO(X, Y, H, θ_full, k)
# Step 2: Pseudo-inverse 계산
S⁻¹ ← PseudoInv(∑_{i=1}^k x_i x_i^T)
# Step 3: Gradient 계산
∇L ← ∑_{i=1}^k (θ_fullᵀ x_i - ŷ_k[i]) x_i
# Step 4: 파라미터 업데이트
return θ_full - FastMult(S⁻¹, ∇L)
end procedure
첫 번째 알고리즘은 모델의 성능을 유지하거나 개선하기 위해 특정 데이터 포인트를 제외하고 잔차를 기반으로 파라미터를 업데이트하는 방법입니다.
알고리즘은 다음과 같은 단계로 구성됩니다.
먼저, Leave-k-out Predictions 단계에서는 데이터셋에서 \(k\) 개의 샘플을 제외하고 모델의 예측을 계산합니다. 이렇게 하면 모델이 특정 데이터 포인트에 얼마나 의존하는지를 알 수 있습니다. 예측값 \(Ŷ_k\) 는 제외된 데이터 포인트를 기반으로 하며, 이는 모델이 얼마나 잘 일반화되는지를 평가하는 데 도움이 됩니다.
다음으로, Pseudo-inverse Calculation 단계에서는 특성 행렬의 pseudo-inverse를 계산합니다. 특정 데이터 포인트의 공분산 행렬인 \(\sum_{i=1}^k x_i x_i^T\) 의 pseudo-inverse인 \(S^{-1}\) 를 구합니다. 이 과정은 데이터의 선형 종속성을 고려하여 이루어지며, 모델의 파라미터 업데이트에 필요한 정보를 제공합니다.
그 후, Gradient Calculation 단계에서는 잔차를 기반으로 기울기를 계산합니다. 잔차는 모델의 예측값과 실제 값 간의 차이를 나타내며, \(\nabla L\) 은 이 잔차에 각 데이터 포인트의 가중치를 곱한 후 합산하여 구합니다. 이 기울기는 현재 모델의 성능을 나타내며, 파라미터 업데이트의 방향과 크기를 결정하는 데 사용됩니다.
마지막으로, Final Update 단계에서는 계산된 기울기를 사용하여 기존 파라미터 \(\theta^{\text{full}}\) 를 수정합니다. 이 업데이트는 pseudo-inverse와 기울기를 곱하여 수행되며, 모델이 잔차를 줄이도록 파라미터를 조정하는 과정입니다. 이 단계는 모델의 성능을 향상시키기 위한 핵심적인 과정입니다.
Algorithm 2: Leave-k-out Predictions(LKO)
textprocedure LKO(X, Y, H, θ_full, k)
# Step 1: Residuals 계산
R ← Y_{1:k} - X_{1:k} θ_full
# Step 2: Diagonal scaling matrix 생성
D ← diag({(1 - H_ii)⁻¹}_{i=1}^k)
# Step 3: T matrix 생성
T_ij ← 1{i ≠ j} H_ij / (1 - H_jj)
# Step 4: 최종 예측값 계산
Ŷ_k ← Y_{1:k} - (I - T)⁻¹ D R
return Ŷ_k
end procedure
두 번째 알고리즘은 PRU의 첫 번째 단계인 Algorithm 1에서 필요한 값을 효율적으로 계산하기 위한 방법으로, 특정 데이터 포인트를 제외한 예측값을 구하는 데 중점을 둡니다.
알고리즘은 다음과 같은 단계로 구성됩니다.
먼저, 주어진 데이터 포인트에서 모델의 예측값과 실제값의 차이를 계산하여 잔차(residual)를 구합니다. 잔차는 모델이 얼마나 잘 작동하는지를 평가하는 데 중요한 역할을 합니다.
다음으로, 잔차의 중요성을 조정하기 위해 대각 행렬(Diagonal scaling matrix)을 생성합니다. 이 행렬은 각 데이터 포인트의 중요도를 반영하며, 모델의 예측에 미치는 영향을 조절합니다.
그 후, 특정 데이터 포인트를 제외한 나머지 데이터 포인트 간의 상관관계를 반영하는 T-matrix를 생성합니다. 이 행렬은 예측값을 조정하는 데 필요한 정보를 제공합니다.
마지막으로, 위의 단계에서 생성된 행렬들을 사용하여 최종 예측값을 계산합니다. 이 과정에서는 데이터 포인트를 제외한 후에도 모델의 성능을 유지할 수 있도록 조정합니다.
Feature Injection Test(FIT)
Feature Injection Test(FIT)는 모델에서 민감한 특성이 얼마나 잘 제거되었는지를 평가하기 위한 지표입니다.
FIT 점수가 1보다 크면 해당 특성이 모델에 여전히 영향을 미치고 있음을 나타내며, 1보다 작으면 특성이 삭제된 후 모델의 예측에 미치는 영향이 감소했음을 의미합니다. 이 점수는 데이터 삭제의 효과를 정량적으로 평가하는 데 유용하며, 모델의 안전성과 개인 정보 보호를 위한 중요한 지표로 작용합니다.
FIT 측정 과정
- 특성 주입: 특정 데이터 포인트에 강한 신호(특성)를 추가합니다.
- 모델 학습: 주입된 특성을 포함한 데이터를 사용하여 모델을 학습합니다.
- 삭제 후 평가: 주입된 특성이 제거되었는지 확인합니다.
FIT 점수 계산 방식 \(\begin{equation} FIT = \frac{\text{주입된 특성의 가중치 (삭제 후)}}{\text{주입된 특성의 가중치 (삭제 전)}} \end{equation}\)
주입된 특성의 가중치 (삭제 전)는 ‘모델에 특정 특성이 주입되었을 때의 가중치 값’입니다. 이는 해당 특성이 모델의 예측에 미치는 영향을 나타냅니다.
주입된 특성의 가중치 (삭제 후)는 ‘해당 특성을 삭제한 후의 가중치 값’으로, 특성이 모델에서 제거된 후의 예측 성능을 평가합니다.
Feautre Injection Test(FIT)와 다른 평가 지표 비교
기존 평가 지표인 $L^2$ 거리와 FIT의 차이점을 알아보겠습니다.
\(L^2\) 거리는 전체 파라미터 변화량을 측정하지만 민감한 특성 제거 여부를 직접적으로 반영하지 못합니다.
이에 반해, Feature Injection Test(FIT)은 민감한 특성이 얼마나 효과적으로 제거되었는지를 정량적으로 측정합니다.
실험 결과(Experimental Results)

Table 1에서는 Projective Residual Update(PRU)가 기존 영향 함수 기반 방법들보다 더 효율적인 계산 복잡도를 가짐을 보여줍니다. 특히 고차원 데이터에서 PRU가 더 적합함을 확인할 수 있습니다.
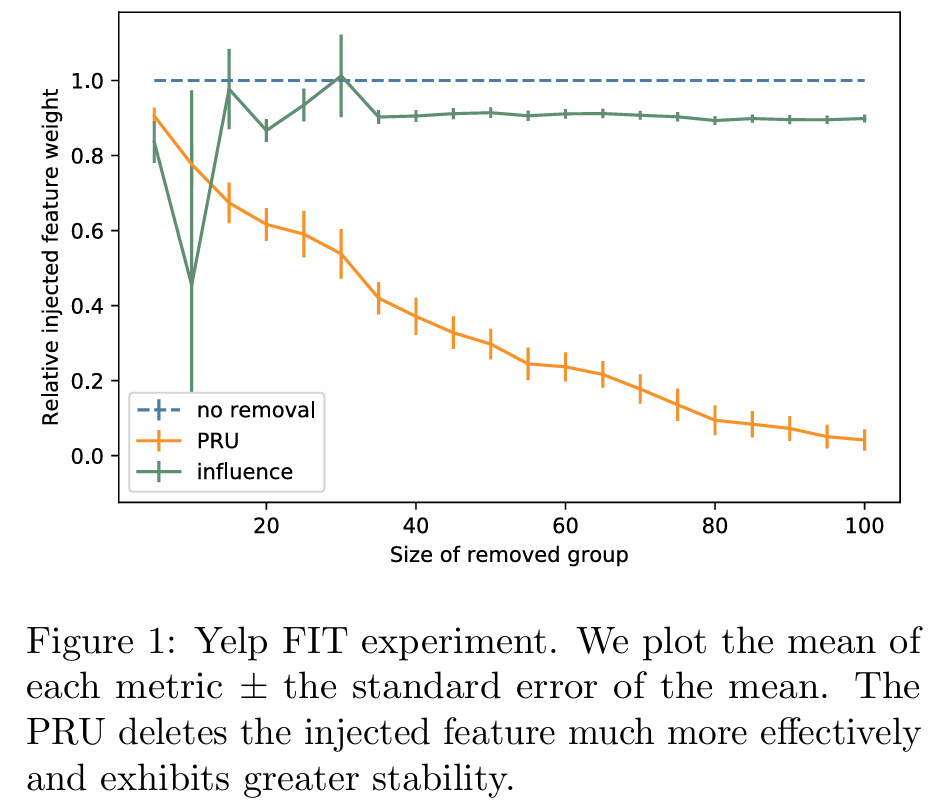
Figure 1은 FIT 점수를 비교한 그래프로, PRU가 더 안정적이고 효과적으로 주입된 특성을 제거함을 보여줍니다.
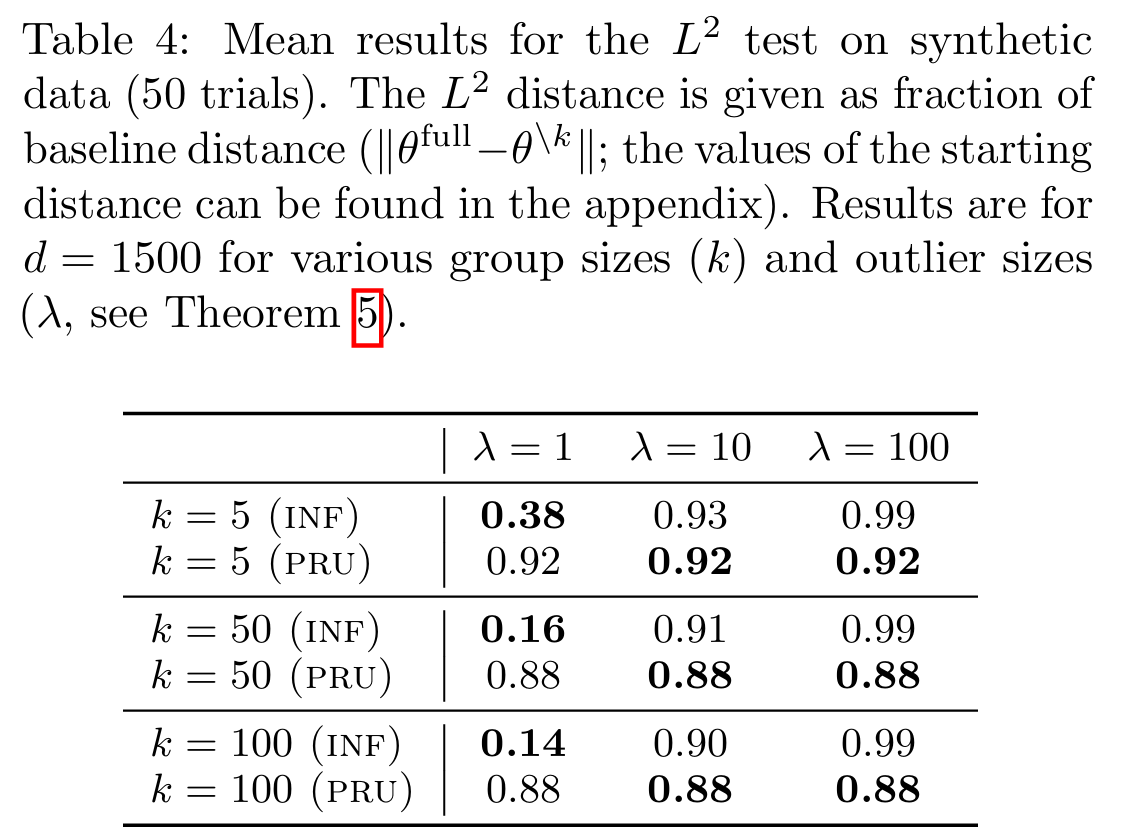
Table 4에서는 희소 데이터 환경에서 PRU가 민감한 특성을 완전히 제거하는 데 훨씬 더 효과적임을 보여줍니다.
결론
본 논문에서는 선형 및 로지스틱 회귀 모델에서 데이터를 효율적으로 삭제할 수 있는 Projective Residual Update(PRU)와 Feature Injection Test(FIT)를 제안합니다. PRU는 기존 방법보다 빠르고 정확하며, 고차원 및 대규모 데이터셋에서도 뛰어난 성능을 발휘합니다. FIT는 민감한 정보 제거 능력을 정량적으로 평가할 수 있는 도구로, 데이터 삭제의 효과를 효과적으로 측정할 수 있음을 보여주었습니다.
이 방법들은 개인정보 보호와 모델 업데이트의 효율성을 동시에 고려해야 하는 다양한 분야에서 중요한 기여를 할 것으로 기대됩니다. 특히 PRU는 대규모 데이터셋에서 실시간 모델 업데이트를 가능하게 하여, 데이터 삭제 후에도 모델의 정확성을 유지할 수 있습니다.
향후 연구에서는 비선형 모델로의 확장과 연속적인 삭제 요청 처리 문제를 해결하는 데 집중할 필요가 있습니다. 이러한 연구는 데이터 관리와 개인정보 보호 정책 수립에 기여할 것입니다 .