논문명: Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
저자: Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, Sifia Liu
게재지: 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
Diffusion 모델의 발전과 언러닝
Diffusion 모델은 광범위한 온라인 데이터셋을 통해 훈련되어 사실적인 이미지를 생성하는 모델입니다. 하지만 Diffusion Model은 훈련이 다양한 인터넷 소스의 콘텐츠에 의존하여 부적절한 텍스트 입력에 의해 직장에서 보기 부적합한(NSFW) 이미지를 생성하는 안전 상의 문제가 발생합니다.
따라서 Diffusion 모델에 언러닝 개념을 도입하여 부적절한 프롬프트에 직면하더라도 원하는 않는 컨텐츠의 생성을 방지하도록 설계하였습니다. 하지만 여전히 UnlearnDiffAtk 공격 등에 취약하여 언러닝 대상이었던 개념을 복원할 수 있는 문제점이 발생합니다.
사전지식
LDMs 와 ESD
LDMs은 텍스트-이미지 생성에서 뛰어난 성과를 띄는 모델이며 텍스트 프롬프트를 이미지 임베딩에 통합하여 생성 과정을 안내하는 방식으로 동작합니다. 텍스트의 의미와 시각적인 요소를 고려하여 텍스트가 요구하는 이미지를 생성합니다. 해당 방식은 노이즈가 포함된 이미지 표현에서 점진적으로 노이즈를 제거하여 깨끗한 이미지를 생성하는 과정입니다.
이후 LDMs에서 발생하는 취약점을 보완하며 모델의 성능을 유지하기 위하여 ESD(Erasing Specific Concepts) 개념이 도입되었습니다. 다음 수식은 ESD 개념의 알고리즘을 설명하고 있습니다.
\[\begin{equation} \min_{\theta} \ell_{ESD} (\theta, c_e) := \mathbb{E} \left[ \left\| \epsilon_{\theta} (x_t \mid c_e) - \left( \epsilon_{\theta_o} (x_t \mid \emptyset) - \eta \left( \epsilon_{\theta_o} (x_t \mid c_e) - \epsilon_{\theta_o} (x_t \mid \emptyset) \right) \right) \right\|_2^2 \right] \end{equation}\]일차적으로 부적절한 콘텐츠가 포함되지 않는 기본 이미지에서 생성되는 노이즈와 부적절한 콘텐츠가 포함된 이미지의 노이즈를 빼서 부적절한 콘텐츠에 의한 영향을 계산합니다. 이후 원본 이미지에서 해당 영향력을 뺌으로써 부적절한 콘텐츠의 영향력을 제거합니다.
AT-ESD와 AdvUnlearn
ESD 개념을 도입하여도 여전히 적대적 공격에는 취약합니다. 따라서 적대적 예제(Adversarial Unlearning)를 통해 적대적 프롬프트 공격을 방어하는 개념이 도입되었습니다. 이 개념은 AT-ESD로도 불립니다.
본 논문은 기존의 AT-ESD 방법에서 방어자와 공격자가 각각 상위 레벨과 하위 레벨로 분류되는 이중 최적화(Bi-Level Optimization) 방법을 제안하였고 이를 AdvUnlearn이라 합니다.

공격자는 적대적 프롬프트를 생성하는 과정에서 손실을 최소화하는 과정을 통해 최적의 공격 프롬프트를 생성하며 방어자는 공격자가 최적화한 공격 프롬프트를 제거하기 위해 훈련합니다. 두 최적화 문제는 서로 연결되어 있으며 상위 레벨과 하위 레벨이 교대로 이루어집니다.
AdvUnelarning의 효율성과 효과성
단순히 ESD 언러닝 개념을 상위 레벨에 적용하게 될 경우 Diffusion 모델의 유틸리티가 크게 손상될 위험이 존재합니다. 따라서 적대적 공격에 대한 강건성을 유지하며 Diffusion Model에 대한 유틸리티를 보존할 필요가 있습니다.
또한, Diffusion Model의 모듈성으로 인해 AT의 적절한 적용 위치와 효율적인 구현 방법을 결정할 필요가 있습니다.
효과성(Effectiveness)
다음 표와 그림은 언러닝이 적용되지 않은 Diffusion 모델과 AT-ESD, ESD가 적용된 모델의 적대적 공격에 대한 성공률과 이미지의 품질 저하 정도를 측정한 결과입니다.

AT-ESD의 경우 ESD를 상위 최적화 문제로 사용하고 이를 적대적 프롬프트 생성과 결합하여 적대적 공격 성공률을 낮추었으나 이미지 생성 품질을 현저하게 감소시키는 문제를 발생시킵니다. AT-ESD에서 이미지의 품질이 저하되었던 이유는 ESD가 부적절합 개념을 제거하는데 초점을 맞추었으며 추가적인 적대적 훈련이 적용되어 이미지 품질을 유지할 여력이 부족했기 때문입니다.
따라서 본 논문은 AT-ESD에 추가적으로 모델이 일반적인 이미지 생성 능력을 유지하도록 유도하기 위해 추가적인 유지 데이터를 활용하여 AdvUnlearn을 고안하였습니다. 유지 데이터는 LLM을 판별자로 하여 부적절한 콘텐츠와 관련 없는 텍스트 프롬프만 유지하며 COCO, ImageNet 등 외부 데이터셋에서 추가 프롬프트를 생성합니다. 이후 최종적으로 243개의 다양한 프롬프트로 구성되며 훈련 중 무작위로 5개의 프롬프트를 샘플링하여 사용합니다.
위 표와 같이 유지 데이터를 활용한 AdvUnlearn은 모델 유틸리티의 증가로 인해 적대적 공격에 대한 강건성은 약해졌으나 일반적인 ESD 방식보다 방어 효과가 뛰어나 모델 유틸리티와 강건성 사이의 균형을 비교적 유지하였습니다.
효율성(Efficiency)
텍스트 인코더(Text Encoder)
기존의 ESD Unlearning은 DM(Diffusion Model)의 UNet 모듈에 적용되었으나 해당 방식은 AdvUnlearn의 강인성을 충분히 향상시키지 못한다는 단점이 있습니다. 따라서 본 논문은 기존의 UNet 모듈 대신 텍스트 인코더에 언러닝을 적용하여 해당 단점을 해결합니다. 텍스트 인코더를 활용하게 될 경우 UNet 모듈에 비해 크게 3가지 장점이 있습니다.
첫째, 텍스트 인코더의 파라미터 수는 UNet 모듈보다 적어 훈련이 더 빠르게 수렴합니다. 또한 텍스트 인코더를 한 번 언러닝하게 될 경우 plug-in 방식으로 다른 DM에 적용할 수 있다는 큰 장점이 있습니다. 셋째, DM의 시각적 이미지 생성과 관련된 인과적인 요소가 텍스트 인코더에 집중되어 있어 텍스트 인코더를 수정하게 될 경우 모델 전체의 이미지 생성 결과를 효과적으로 제어할 수 있습니다.
마지막 장점이 강인성 향상과 큰 관련이 있습니다. 텍스트 인코더는 모델이 무엇을 생성할 것인지를 결정하는 핵심 모듈입니다. UNet 모듈은 후처리 단계이므로 텍스트 변형을 복구할 수 없으며 이미 잘못된 텍스트 조건을 기반으로 이미지가 생성된 경우 수정할 방법이 없습니다. 하지만 텍스트 인코더가 특정 개념을 학습하였을 때 이를 직접 수정하게 될 경우 해당 개념이 텍스트 프롬프트를 통해 생성되지 않도록 설정할 수 있습니다. 예를 들어 “nudity”라는 개념을 텍스트 인코더에서 제거할 경우 “a nude woman”과 같은 프롬프트가 의미를 잃어 모델이 해당 부적절한 이미지를 생성하지 않게 됩니다. 즉, 잘못된 조건 자체를 학습하여 제거할 수 있습니다.
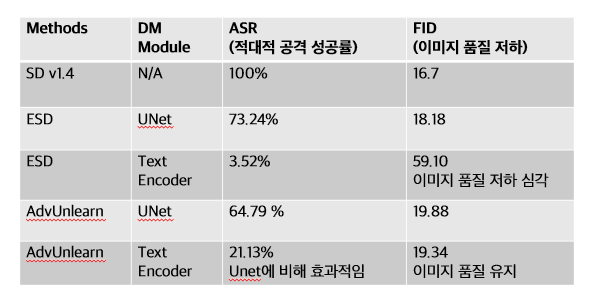
다음 실험 결과와 같이 텍스트 인코더에 AT-ESD 개념을 적용할 경우 UNet 모듈에 비해 적대적 공격 성공률을 낮출 수 있었으며 이미지 품질 유지에도 유리했다는 것을 알 수 있습니다.
Fast-AT
AdvUnlearn의 효율성을 높이기 위해서 적대적 프롬프트를 생성하는 lower-level optimization을 간소화할 수 있습니다. 해당 개념은 이미지 분류에서 사용되는 Fast AT 기법과 유사한 개념으로 FGSM(Fast Gradient Sign Method)을 활용하여 한 번의 gradient계산(one-shot 기법)으로 가중치를 업데이트 할 수 있어 기존의 방식에 비해 계산양이 매우 적고 훈련 속도를 빠르게 할 수 있습니다.
다음 수식은 FGSM 기법을 표현하였습니다 :
\[\begin{equation} \delta = \delta_0 - \alpha \cdot \text{sign} \left( \nabla_{\delta} \ell_{\text{atk}} (\theta, c + \delta_0) \right) \end{equation}\]해당 방식은 기존 프롬프트에 prefix vector를 추가하여 새로운 적대적 프롬프트를 생성하는 과정이며 이때 사인함수는 0보다 작은 값은 -1, 0이면 0, 0보다 크면 1을 출력하여 기울기의 방향을 결정하는 역할을 합니다. 일반적인 경사 하강법과 다르게 해당 방식은 가중치 업데이트가 손실함수가 최대가 되는 방향으로 움직입니다.
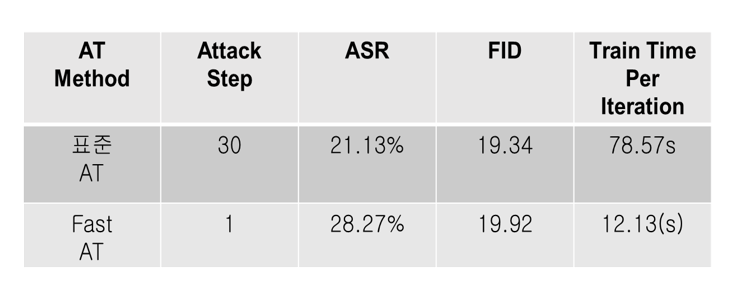
다음 표의 결과처럼 Fast-AT를 활용했을 시 훈련 속도가 빠르다는 것을 알 수 있습니다. 하지만 역으로 적대적 공격에 대한 성공률은 올라갔기 때문에 AdvUnlearn 과정에서 계산 비용과 강인성 사이의 trade-off를 고려하여 알고리즘을 선택할 필요가 있습니다. 즉, 훈련의 효율성이 중요한 경우는 FAST-AT를 선택하고 강인성이 더 중요한 경우는 Standard AT를 활용하는 것이 유리합니다.
Amnesiac Unlearning 성능 검증(Evaluation)
텍스트 인코더에 적대적 훈련을 적용한 AdvUnlearn 모델의 성능을 검증하기 위해 실험을 진행하였습니다. 기존에 발표되었던 SalUn, ESD, UCE, FMN 등과 같은 언러닝 알고리즘을 대조군으로써 활용하며 누드 관련 프롬프트에 의한 유해한 콘텐츠 생성을 방지하는 nudity unlearning, 대한 실험을 진행합니다. 검증하고자 하는 목표는 적대적 프롬프트에 대한 강건성과 이미지 생성 품질입니다.
적대적 프롬프트에 대한 강건성과 이미지 품질 검증
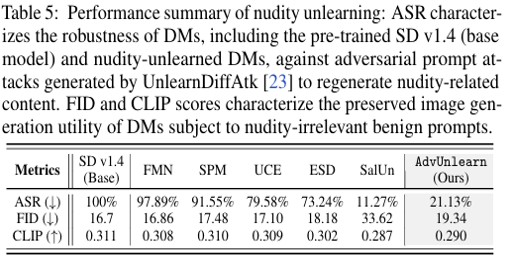
다음 표의 결과와 같이 AdvUnlearn은 100%였던 ASR(적대적 공격 성공률)를 21.13%로 크게 낮추면서 강인성을 향상시켰으며 이미지 품질 지표인 FID와 CLIP SCORE을 원본 모델인 SD v1.4와 유사하게 유지하고 있습니다. AdvUnlearn과 다르게 SalUn의 경우 ASR를 11.27%로 강인성이 가장 뛰어난 것을 확인할 수 있지만 FID가 크게 증가하여 이미지 품질을 보장하지 못한다는 결함이 있습니다.
Plug-and-Play에 대한 가능성 검증
다음은 AdvUnlearn에 대한 Plug-in 가능성을 검증합니다. 즉, SD v1.4 모델에서 AdvUnlearn으로 학습된 텍스트 인코더가 다른 DM에 그대로 활용할 수 있는지 평가하고자 합니다. 이 실험은 SD v1.4에서 학습된 텍스트 인코더를 SD v1.5, DreamShaper, Protogen과 같은 다른 모델에서도 사용할 수 있는지를 검증합니다.

다음 표의 결과와 같이 원본 모델 SD v1.4와 비교했을 때 ASR이 모든 모델에서 감소하였으며 FID와 CLIP Score 역시 유사한 수준의 차이를 유지하고 있어 AdvUnlearn의 텍스트 인코더는 여러 DM에서 그대로 사용 가능하다는 것을 알 수 있습니다.
적대적 공격에 대한 방어 성능 검증
이번 실험은 다양한 적대적 공격에 대한 AdvUnlearn의 방어 성능을 검증하기 위한 실험을 진행하였습니다. 적대적 공격은 크게 텍스트 기반의 공격와 임베딩 벡터를 조작하는 공격으로 나눌 수 있습니다.
텍스트 기반의 공격은 단어 또는 문장(프롬프트)를 변형하여 개념을 복원하는 공격입니다. 예를 들어 “a nude woman” 을 “a beautiful lady with soft skin”으로 변형합니다.
또한 텍스트 프롬프트를 재구성하여 개념을 우회적으로 표현하는 방식도 있습니다.
임베딩 벡터를 조작하는 공격은 개념이 제거된 단어를 새로운 유사한 의미의 임베딩 벡터로 변형하는 방식입니다. 즉, 지워진 단어를 “숨어 있는 벡터”로 바꿔서 재활성화시키는 개념입니다.
예를 들어 “nude”의 임베딩 벡터가 [0.23, -1.45, 0.89, …0.76]일 때 “nude”와 유사하나 개념을 표현할 수 있는 가짜 단어(벡터)인 “icecream” = [0.22, -1.40, 0.91, …0.75]로 모델을 속이는 공격입니다.
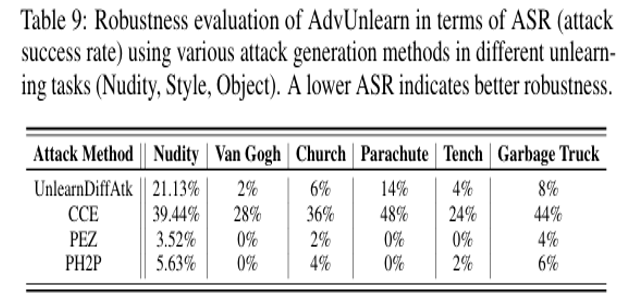
해당 실험은 여러 종류의 적대적 공격에 대한 AdvUnlearn의 강건성을 비교하였습니다. 다음 표의 결과처럼 일반적인 텍스트 기반의 공격인 UnlearnDiffAtk, PEZ, PH2P에 대해서는 매우 강한 방어 성능이 뛰어나나 임베딩 벡터를 조작하는 공격인 CCE에는 비교적 취약합니다. 그 이유는 연속적인 임베딩 공간을 조작하여 공격하는 방식으은 일반적인 텍스트 기반 공격보다 강력한 공격력을 지니기 때문입니다.
결론
현재 언러닝된 DM은 여전히 적대적 프롬프트 공격에 취약한 상태입니다. 본 논문에서 제안한 AdvUnlearn은 이러한 공격에 대한 강건성을 높이는 동시에 이미지 생성 품질을 보존할 수 있는 잠재적인 전략을 제시합니다.
특히 본 논문은 이미지의 품질을 유지하는 정규화 기법을 도입하여 보존된 프롬프트 세트에서 모델의 성능을 유지하며 DM의 UNet보다 텍스트 인코더가 강건성을 확보하는데 더 효과적임을 확인합니다.
다양한 시나리오의 실험을 통해 AdvUnlearn이 강건한 언러닝과 이미지 생성 품질 사이의 균형을 유지할 수 있음을 입증하였으며 FAST-AT 기법을 활용하여 AdvUnlearn의 속도를 향상시킬 수는 있으나 계산 효율성을 지속적으로 개선하는 방법은 여전히 중요한 연구 과제입니다.