논문명: Evaluating Machine Unlearning via Epistemic Uncertainty
저자: Alexander Becker, Thomas Liebig
서론
머신 언러닝(Machine Unlearning)은 훈련된 모델에서 특정 데이터를 제거하는 훈련 기법을 말합니다.
본 논문에서는 인식론적 불확실성(Epistemic Uncertainty) 개념을 이용해 머신 언러닝 모델의 성능을 측정하는 효율적이고 정량적인 지표를 제시합니다. 지표의 타당성을 검증하기 위해 두 가지 가설을 수립하고, 세 가지 머신 언러닝 모델에 적용해 가설을 검증합니다.
사전 지식
Retraining
차분 프라이버시 개념에 기반해 데이터 삭제 전후의 성능 차이를 보장합니다(Certified Removal). 차분 프라이버시는 아래의 수식으로 정의합니다.
\[e^{-\epsilon} \leq \frac{P(U(A(D), D, x) \in T)}{P(A(D \setminus \{x\}) \in T)} \leq e^{\epsilon}\]Amnesiac Unlearning
사전 학습된(pre-trained) 모델의 매개변수(parameter)가 특정 세대(epoch) e, 배치(batch) b에서 제거 대상 데이터에 의해 영향받은 만큼 복귀시킵니다.
\[U_{AU}(\theta, D_f) = \theta - \sum_{e=1}^{E} \sum_{b=1}^{B} 1\left[D_f \cap D_{e,b} \neq \emptyset\right] \Delta_{\theta_{e,b}}\]Fisher Forgetting
매개변수에 정규분포를 따르는 노이즈(noise) n을 추가해 Retraining 모델과의 성능 차이를 은폐합니다. 기존 매개변수에 하이퍼파라미터(hyper parameter)로 조정된 노이즈를 더한 값으로 정의합니다.
\[U_{FF}(\theta, D_f) = \theta + \alpha^{\frac{1}{4}} F^{-\frac{1}{4}} n\]적대적 공격
적대적 공격(adversarial attack) 중 MIA(Membership Inference Attack)의 결과로 특정 데이터 제거 여부를 확인합니다.
본론
본 논문은 정보 이론과 인식론적 불확실성에 기반한 평가 지표로 각 머신 언러닝 기법의 효능(efficacy)을 측정 및 평가합니다.
인식론적 불확실성을 이용한 평가 지표
“인식론적 불확실성(Epistemic Uncertainty)”은 모델에 남아 있는 제거한 데이터의 영향을 의미합니다.
Fisher Information Matrix(FIM)로 제거한 데이터의 정보량을 계산하면 해당 데이터에 대한 모델의 인식론적 불확실성을 측정할 수 있습니다. 논문에서는 Marquart-Levenberg 근사에 기반해 FIM에 의한 정보량 식의 연산 복잡도를 줄여 아래와 같이 제시합니다.
\[\iota(\theta; D) = \operatorname{tr} \left( \mathcal{I}(\theta; D) \right) = \frac{1}{|D|} \sum_{i=1}^{|\theta|} \sum_{x, y \in D} \left( \frac{\partial \log p_{\theta}(y | x)}{\partial \theta_i} \right)^2\]이는 모델이 데이터셋에 대해 가진 총 정보량을 의미하며, 매개변수가 모델의 성능에 민감한 정도를 나타냅니다. 즉 특정 매개변수에서 모델의 총 정보량은 데이터셋에 대한 모델의 불확실성을 나타냅니다.
Efficacy Score
데이터 제거 시 발생하는 Streisand effect와 같은 부작용을 해결하기 위해 본 논문에서는 efficacy score를 제시합니다. Efficacy score가 낮으면 제거 대상 데이터에 대한 인식론적 불확실성이 높아지는 것을 확인할 수 있습니다.
\[\text{efficacy}(\theta; D) = \begin{cases} \frac{1}{\iota(\theta; D)}, & \text{if } \iota(\theta; D) > 0 \\ \infty, & \text{otherwise} \end{cases}\]데이터셋의 크기가 커지거나 모델의 크기가 커질 경우 각 데이터 포인트(data point)에 대한 연산 비용이 증가합니다. 이 문제를 해결하기 위해 아래와 같은 이론적인 상한선을 제시합니다.
\[\text{efficacy}(\theta; D) \leq \frac{1}{\left\| \nabla \mathcal{L}(\theta, D) \right\|_2^2}\]실험 및 결과 분석
본 논문은 다음 두 가지 가설을 검증합니다.
- 가설(1) : 사전 학습된 모델을 머신 언러닝 기법으로 학습시키면 항상 제거한 데이터에 대한 efficacy score가 낮아질 것이다.
- 가설(2) : 낮은 efficacy score는 항상 적대적 공격의 성공률을 낮춘다.
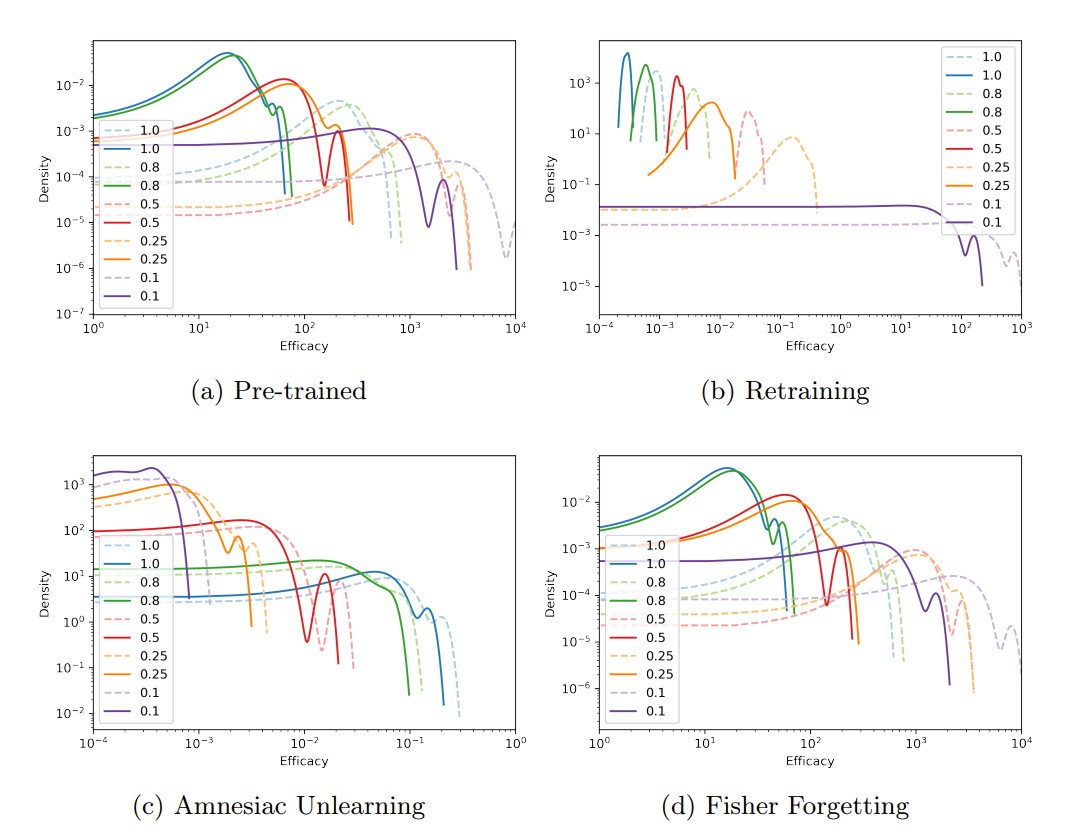
(b) retraining, (d) Fisher Forgetting 결과 데이터 제거 비율이 커질수록 efficacy score가 감소해 가설(1)을 만족합니다.
하지만 (c) Amnesiac Unlearning 결과 데이터 제거 비율이 커질수록 efficacy score는 증가해 가설(1)을 기각합니다. 이는 머신 언러닝의 매개변수 조정 방식이 다르기 때문입니다. (b)와 (d)의 경우 Retraining 결과와의 성능 차이를 좁히는 쪽으로 매개변수가 변화하지만, (c)의 경우 사전 학습되기 이전의 모델과의 성능 차이를 좁힙니다.
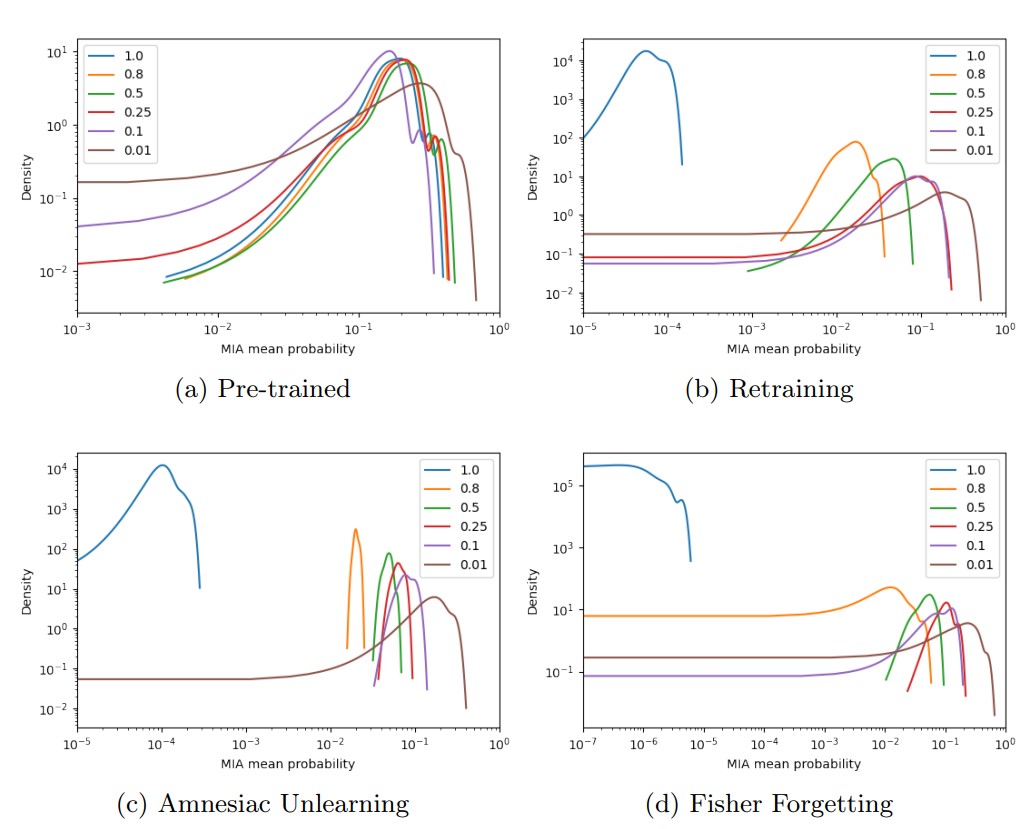
(b), (c), (d) 결과 데이터 제거 비율이 커질수록 MIA 공격 성공률은 항상 감소합니다. 이를 이용해 efficacy score와 MIA 성공률의 관계를 확인합니다.
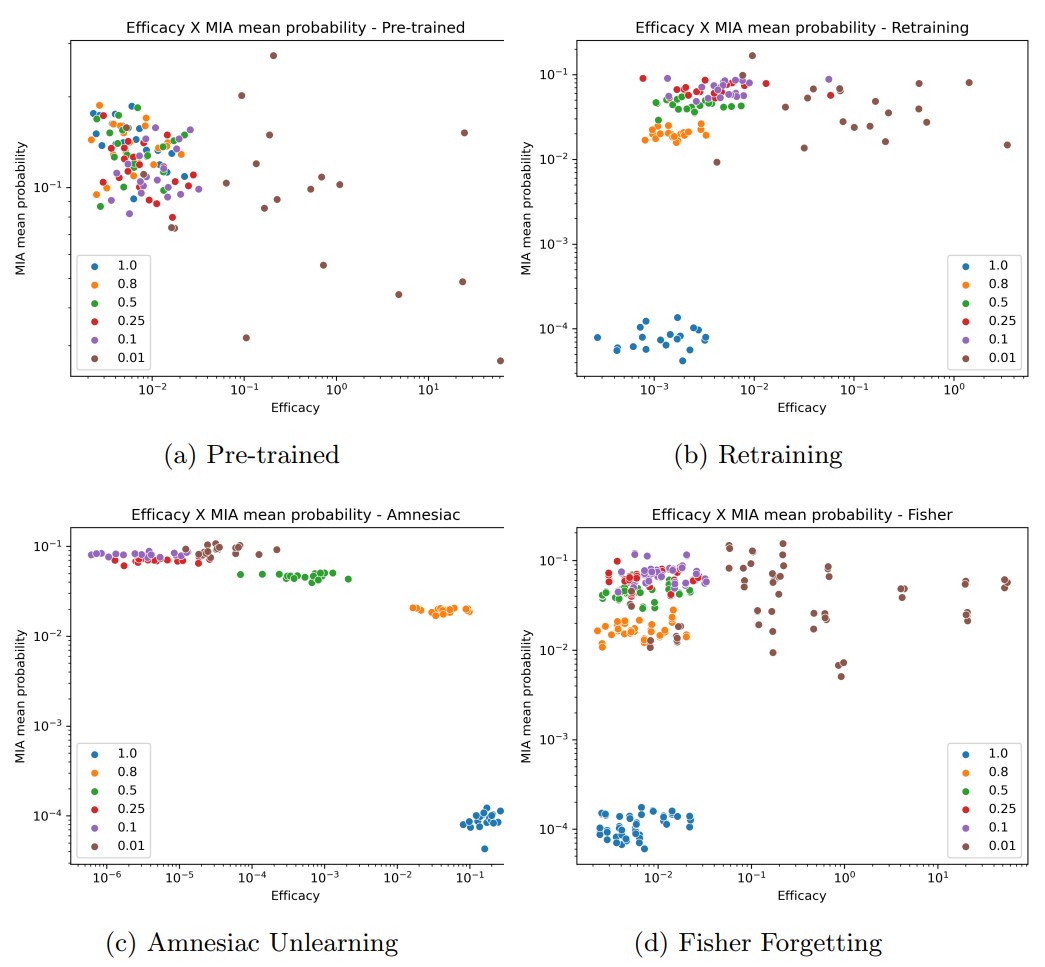
(b)와 (d)에서는 efficacy score가 낮아질수록 MIA 공격 성공률이 감소하지만, (c)의 경우 그 반대의 결과를 보입니다. 가설(2) 또한 가설(1)이 기각된 이유와 같은 이유로 설명할 수 있습니다.
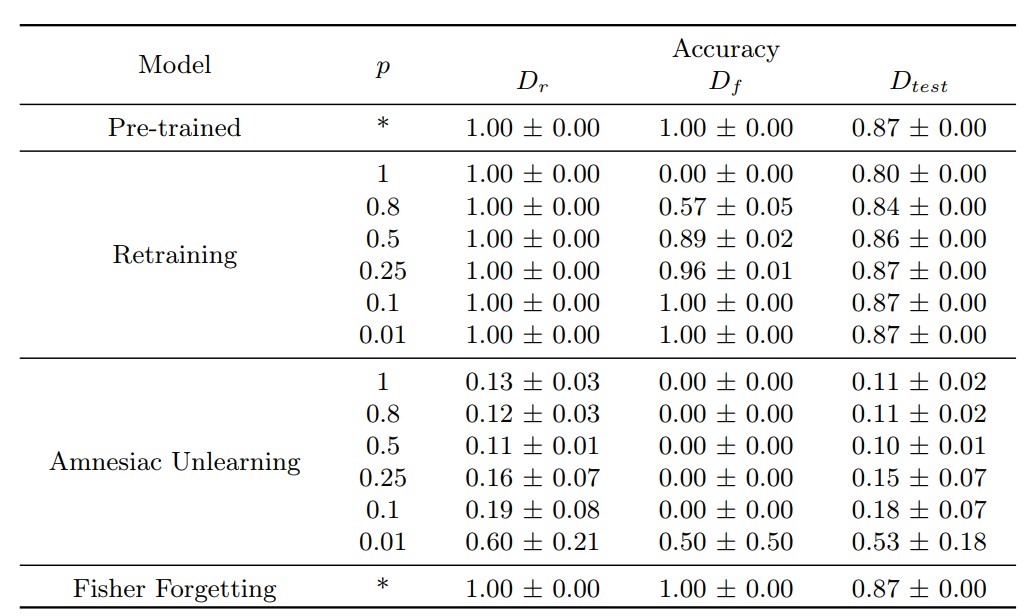
efficacy score로 각 머신 언러닝 기법의 정확도를 측정한 실험에서는 아래 표와 같은 결과를 얻을 수 있었습니다. 전반적으로 낮은 정확도를 보이며, 데이터의 완전한 제거를 보장하는 Retraining에서조차 정확도가 높지 않음을 확인할 수 있습니다.
결론
본 논문은 정보량을 측정하는 지표로써 인식론적 불확실성 개념에 근거한 efficacy score를 제시하고 세 가지 머신 언러닝 방식을 측정해 그 효용성을 검증합니다.
하지만 논문에서 제시한 가설 2가지 모두 기각되었다는 점, 하단의 각 머신 언러닝 기법의 정확도 측정 결과를 통해 해당 평가 지표의 효용성에 의문을 제기할 수 있습니다. 하지만 연산 복잡도를 낮출 수 있도록 정보량 계산 공식을 근사한 점, 정보량을 인식론적 불확실성 관점에서 해석한 부분은 추후 포괄적인 언러닝 기법의 정확도를 평가하는 데에 유용할 것입니다.