논문명: Extracting Robust Models with Uncertain Examples
저자: Guanlin Li, Guowen Xu, Shangwei Guo, Han Qiu, Jiwei Li, Tianwei Zhang
게재지: ICLR 2023
서론
DNN이 적대적 공격에 취약하다는 사실이 알려지자, 적대적 공격에 강건한 모델을 배포하는 경우가 늘어나고 있습니다. 하지만 이처럼 강건한(Robust) 모델을 어떻게 추출할 것인지에 대해서는 연구된 바 없었습니다. 따라서 본 논문은 새로운 공격 기법 강건성 추출(robustness extraction)을 제안합니다.
먼저 기존 공격들이 정확도와 강건성을 함께 추출하는 데 실패하거나, Robust overfitting 문제를 일으킨다는 점을 지적합니다. 이후 제한된 공격 예산으로 정확도와 강건성 모두 추출하기 위한 새로운 모델 추출 공격 Boundary Entropy Searching Thief (BEST)를 제안합니다.
BEST는 원본 모델에 질의하기 위해 불확실한 예제(Uncertain examples)를 생성합니다. 이 샘플들은 여러 클래스에 걸쳐 균일한 신뢰도 점수를 가지며, 덕분에 모델 정확도와 강건성 사이를 완벽하게 균형 잡을 수 있습니다.
본 연구는 실험을 통해 BEST가 다양한 환경에서 기존 공격 방법들보다 뛰어난 성능을 보임을 입증합니다. 또한 BEST가 기존 추출 방어 기법들을 무력화할 수 있음을 밝힙니다.
본론
Threat Model
-
원본 모델 \(M_V\): 적대적 학습(Adversarial training)을 통해 구축되었으며, 적대적 예제(AE)에 대해 강건합니다. 로짓 벡터(Logits vector) 또는 하드 레이블(Hard label)을 반환합니다.
-
공격자 \(A\): 원본 모델의 출력을 바탕으로 대체 모델을 제작합니다. 원본 모델의 아키텍처, 학습 알고리즘, 그리고 하이퍼파라미터를 알지 못합니다. 심지어 원본 모델의 적대적 학습 여부조차 알지 못합니다. 단지 원본 모델과 동일한 분야에서 데이터 샘플 \(D_A\) 를 수집하기만 하면 되며, 이 데이터는 원본 모델의 학습셋과 동일한 분포를 따르지 않아도 됩니다. 공격자는 다음 두 가지 공격 예산의 감소를 고려해야 합니다.
-
\(B_Q\): 질의 예산(Query Budget)은 공격자가 원본 모델에 보내는 질의 개수로 정의됩니다.
-
\(B_S\): 합성 예산(Synthesis Budget)은 각 질의 샘플을 생성하는 데 드는 계산 비용으로 정의됩니다.
공격자는 공격 비용을 줄이기 위해, 공개된 사전 학습 (Pre-trained) 모델을 사용할 수 있다고 가정합니다. 이때 사전 학습된 모델의 학습셋은 원본 모델의 학습셋과 완전히 달라도 됩니다.
-
-
대체 모델 \(M_A\): 공격자가 제작한 모델이며, 자연 샘플과 적대적 예제에 대해 원본 모델과 유사한 예측 성능을 가져야 합니다.
기존 공격 전략과 한계
높은 정확도와 충실도로 모델을 추출하기 위해 기존에 다양한 공격 전략들이 제안되었으며, 이는 두 가지 범주로 분류될 수 있습니다.
자연 샘플을 이용한 추출 (Extraction with Clean Samples)
공격자가 공개 데이터셋에서 질의 데이터를 샘플링하고, 그 데이터와 원본 모델의 예측값을 기반으로 대체 모델을 학습시키는 방식입니다. 초기 연구 Tramer가 이 전략을 사용했으며, 본 논문에서는 이 공격을 Vanilla라고 지칭합니다.
또한 능동 학습(Active learning)을 결합하는 방식들도 제안되었습니다. 이 방식에서 공격자는 다양한 자연 이미지로 구성된 거대한 데이터셋을 구성하고, 추출 공격을 위한 최적의 샘플을 능동적으로 선별합니다. 대표적인 예로는 Knockoff Nets와 ActiveThief 공격이 있습니다.
적대적 예제를 이용한 추출 (Extraction with Adversarial Examples)
공격자가 원본 모델의 분류 경계를 파악하기 위해 대체 모델로 적대적 예제(AE)를 생성하고, 질의 샘플로 사용하는 방식입니다. 대표적인 예는 CloudLeak입니다.
그리고 일부 공격들은 능동 학습을 결합하여 반복적으로 AE를 생성합니다. 예를 들어, JBDA는 FGSM으로 AE를 생성하고, 원본 모델의 예측값을 기반으로 대체 모델을 반복 개선합니다.
위 공격 전략들은 정확도나 충실도 추출에는 효과적일 수 있지만, 아래 이유들 때문에 강건성 추출에는 효과적이지 않습니다.
첫째, 자연 샘플만으로는 대체 모델이 강건하도록 학습시킬 수 없습니다. 따라서 자연 샘플을 사용하는 전략들은 원본 모델의 강건성을 추출할 수 없습니다.
둘째, AE로 대체 모델을 학습시키면, 자연 샘플에 대한 정확도가 감소할 수 있습니다. 또한 학습용 AE에 쉽게 과적합되어 테스트용 AE에 대한 강건성이 감소할 수 있습니다.
이를 입증하기 위해, 본 논문은 아래 실험을 진행합니다.
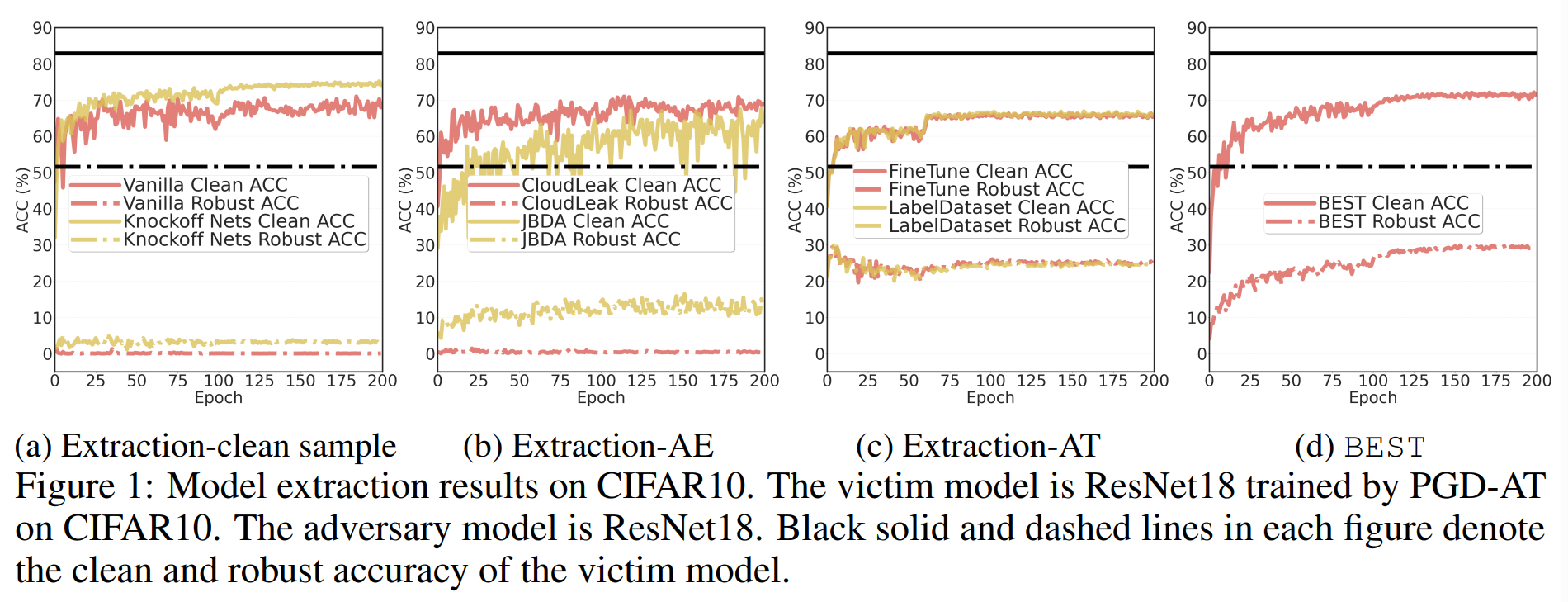
위 실험은 대체 모델의 학습 방식에 따른 추출 성능을 비교하며, 성능 평가 지표로 CA와 RA를 사용합니다.
-
CA(Clean Accuracy): 자연 샘플에 대한 정확도
-
RA(Robust Accuracy): 적대적 예제에 대한 정확도
검은색 실선과 점선은 각각 원본 모델의 CA와 RA를 의미하며, 대체 모델의 추출 성능과 비교하는 기준으로 사용됩니다.
(a): 자연 샘플만으로 대체 모델을 학습시킨 결과입니다. 그 결과, CA는 높지만 RA는 매우 낮습니다. 이를 통해 원본 모델의 강건성 추출에 실패했음을 알 수 있습니다.
(b): AE를 이용하여 대체 모델을 학습시켰을 때의 결과입니다. 전반적으로 (a)에 비해 CA가 낮습니다. 하지만 CloudLeak은 (a)처럼 높은 CA를 유지하는 모습을 보입니다. 이는 Cloudleak이 생성한 AE는 원본 모델에 대한 전이성이 낮기 때문입니다. AE를 학습에 사용했지만 여전히 RA가 낮은 모습을 보여줍니다.
(c): 정확도 추출과 적대적 학습을 순서대로 진행하여, 강건성을 확보하려는 전략의 결과입니다.
-
LabelDataset은 먼저 Vanilla나 CloudLeak으로 원본 모델의 예측값을 받아 정답이 포함된 데이터셋을 만듭니다. 그 다음, 이 데이터셋을 정답으로 삼아, 별도의 대체 모델을 대상으로 처음부터 적대적 훈련을 수행합니다.
-
FineTune은 CloudLeak으로 정확도가 높은 대체 모델을 추출해낸 뒤, 이 기존 모델에 강건성을 덧씌우기 위해 대체 모델에 대한 적대적 예제로 Fine-tuning을 진행합니다.
(c) 전략들은 학습 초반에 RA가 감소합니다. 이는 Robust Overfitting 현상이며, 대체 모델이 적대적 학습용 AE에 과적합되어, 테스트용 AE에는 강건하지 못한 결과입니다. 그 원인은 본 실험의 제한된 공격 예산으로 인해, 적대적 학습에 사용할 데이터가 충분하지 않았기 때문입니다.
이처럼 기존의 공격 전략들은 정확도나 강건성 중 하나를 놓치거나, 두 성능 모두를 확보하는 데 한계를 보였습니다.
새로운 질의 샘플 조건
적대적 학습을 거친 대체 모델은 특정 AE를 매우 높은 신뢰도로 방어해내는 Useful robust feature을 갖게 됩니다. 하지만 이러한 특징은 특정 공격 패턴에 대한 과적합과 같아서, 오히려 위 실험처럼 Robust Overfitting과 자연샘플에 대한 정확도(CA) 저하라는 부작용을 유발합니다.
따라서 기존의 AE를 대체할 새로운 질의 샘플은 다음 두 가지 조건을 만족해야 합니다.
-
첫째, Robust Overfitting을 유도하면 안 됩니다.
-
둘째, 원본 모델의 결정 경계를 효과적으로 반영하여 CA 저하를 막아야 합니다.
본 논문은 이를 만족하는 질의 샘플로 불확실한 예제 UE(Uncertain Examples)를 제안합니다.
Uncertain Examples
UE는 대체 모델을 헷갈리게 만드는 것을 목표로 합니다
따라서 대체 모델 \(M: \mathbb{R}^N \to \mathbb{R}^n\) 과 입력값 \(\quad x \in \mathbb{R}^N\) 에 대하여, 아래 수식을 만족하는 \(\quad x\)를 \(\delta-UE\) 라고 정의합니다.
\[\text{softmax}(M(x))_{\max} - \text{softmax}(M(x))_{\min} \leq \delta\]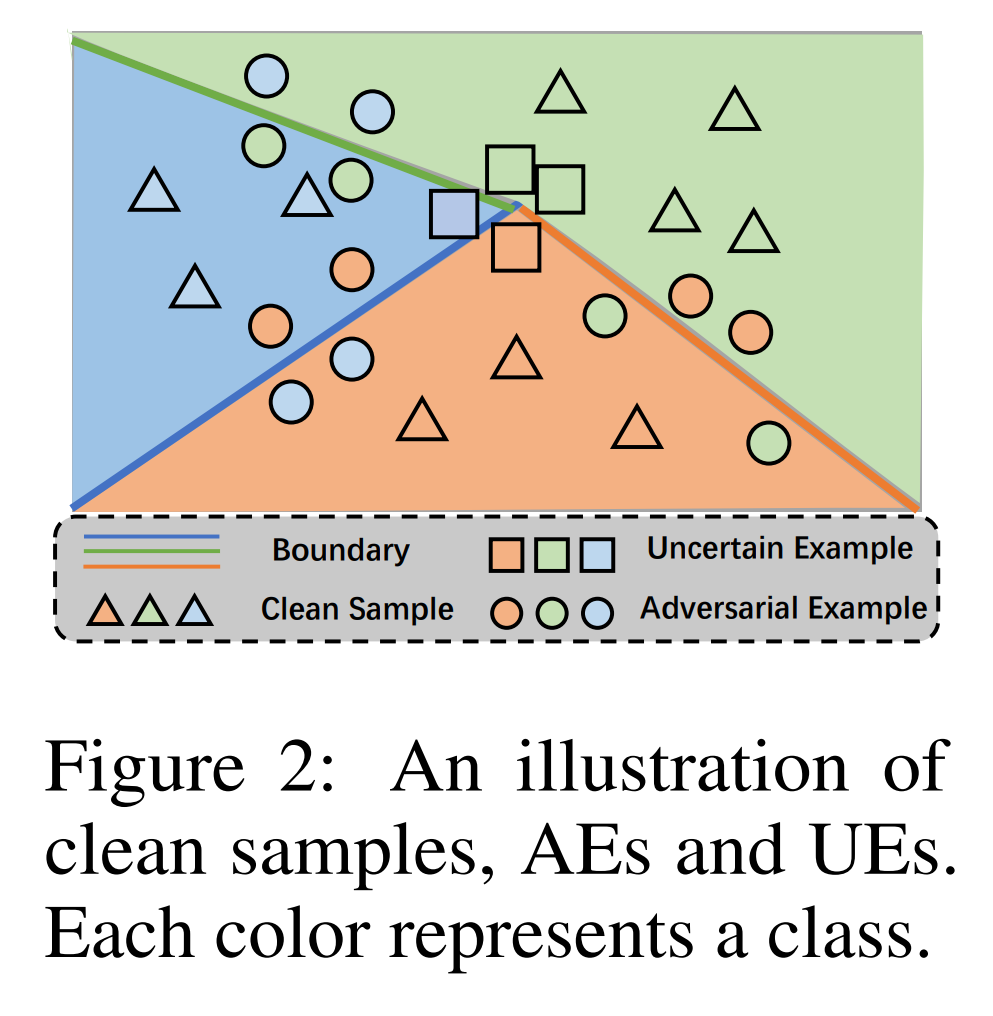
위 그림은 대체 모델의 결정 경계를 기준으로 자연 샘플, AE, UE의 위치를 보여줍니다. 이러한 UE는 다음 특징들을 가집니다.
-
Robust Overfitting 방지: UE는 \(\delta\)를 낮춰 불확실성을 증가시킴으로써 AE가 가지는 Useful robust feature를 예방할 수 있습니다. 따라서 UE를 질의 샘플로 사용하면, Robust Overfitting의 위험을 근본적으로 방지할 수 있습니다.
-
CA 보존: UE는 정의상 대체 모델의 결정 경계 가장 가까이 위치합니다. 본 연구는 대체 모델이 원본 모델을 어느 정도 모방하면, 대체 모델의 결정 경계도 원본 모델의 결정 경계 근처일 것이라 가정합니다. 따라서 UE를 질의 샘플로 사용하면, 원본 모델의 결정 경계를 효과적으로 반영하며 CA 저하를 막을 수 있습니다.
결론적으로 UE는 강건성 추출에 필요한 두 가지 조건을 만족시키므로, 기존 샘플들을 대체할 이상적인 질의 샘플입니다.
BEST
본 논문은 불확실한 예제(UE)를 활용하는 새로운 추출 공격, Boundary Entropy Searching Thief (BEST)를 제안합니다.
BEST는 매 반복마다 UE를 생성하여 원본 모델에 질의하고, 그 예측값을 바탕으로 대체 모델을 개선하는 공격입니다. 이 과정을 통해 대체 모델이 원본 모델의 정확도(CA)와 강건성(RA)을 동시에 갖추게 만드는 게 목표입니다.
BEST의 핵심 전략은 UE를 샘플링하는 것이 아니라, 새롭게 합성하는 것입니다. 본 논문은 공격자의 데이터셋을 \(D_A\)로 제한하므로, 만약 샘플링을 한다면 공격자는 이 \(D_A\) 안에서 UE를 찾아야만 합니다.
그러나 이런 샘플링 방식은 효과가 없습니다. 제한된 데이터로 학습을 거듭하면 모델은 기존 샘플에 과적합되고, 모든 학습 샘플은 대체 모델의 결정 경계에서 멀리 떨어진 안전한 영역에만 머물게 됩니다. 하지만 공격 효율을 극대화할 수 있는 UE는 바로 그 결정 경계 가까이 위치해야 하므로, 기존 데이터셋 내부에서 샘플링하는 것은 무의미합니다.
따라서 BEST는 이중 최소화 문제를 통해 매 순간 가장 유용한 UE를 능동적으로 합성합니다.
\[\min_{M_A} L(x, y, M_A) \min_x \left( \text{softmax}(M_A(x))_{\text{max}} - \text{softmax}(M_A(x))_{\text{min}} \right)\]- 내부 최소화: 기존 데이터셋의 샘플 \(x\) 를 바탕으로, 대체 모델 \(M_A\) 의 예측 신뢰도 분산을 최소화하는 새로운 샘플 UE \(x\) 를 합성합니다.
- 외부 최소화: 내부 최소화의 UE \(x\) 를 원본 모델 \(M_V\) 에 질의하여 정답 \(y\) 를 획득합니다. 이를 대체 모델 \(M_A\) 를 학습시켜, 대체 모델의 손실함수 \(L\) 을 최소화합니다. 그 결과, 최적의 대체 모델이 계산됩니다.
아래 알고리즘은 이러한 과정을 상세히 설명합니다.

위 알고리즘을 살펴보면, 우선 UE 합성의 목표로 균등 분포 \(\mathcal{Y}_p\) 를 생성합니다. 그리고 공격자가 보유한 데이터셋 \(D_A\) 의 모든 샘플들을 차례대로 UE 합성에 사용합니다.
7행에서는 아래와 같은 손실함수가 사용됩니다.
\[\mathcal{L} = -KLD(softmax(M_A(X_i)), \mathcal{Y}_p)\]이때 \(softmax(M_A(X_i))\) 는 현재 대체 모델의 샘플 \(X_i\) 에 대한 예측 확률 분포입니다. 그리고 \(\mathcal{Y}_p\) 는 UE가 목표하는 가장 불확실한 상태, 즉 균등 분포입니다.
손실함수 \(\mathcal{L}\) 는 \(KLD\) 로 측정한 두 확률 분포의 차이를 기반으로 정의됩니다.
8행에서는 PGD 방식을 사용하여, 손실함수 \(\mathcal{L}\) 을 최대화하는 방향으로, 즉 두 확률 분포의 차이를 줄이는 방향으로 샘플 \(X_i\) 를 반복해서 변형합니다.
이 과정을 합성 예산 \(B_S\) 횟수만큼 반복해 UE (\(X_{B_S}\)) 를 합성합니다. 완성된 UE를 원본 모델 \(M_V\) 에 질의해 정답 레이블 \(Y\) 를 얻고, 이렇게 확보한 (UE, 정답 레이블) 쌍으로 대체 모델 \(M_A\) 를 학습시킵니다.
실험 환경
데이터셋 \(D_A\) 로 CIFAR10과 CIFAR100을 사용합니다. UE 합성을 위한 5,000개 샘플 규모의 \(D_A\) 과 성능 평가를 위한 5,000개 샘플 규모의 \(D_T\) 를 구분하여 구축합니다.
원본 모델은 ResNet-18 (ResNet) 또는 WideResNet-28-10 (WRN)를 사용합니다.
대체 모델은 원본 모델과 달라도 되기 때문에, 추가로 MobileNetV2 (MobileNet)와 VGG19BN (VGG)까지 사용합니다.
그리고 원본 모델을 적대적 학습시킬 때는 PGD-AT와 TRADES라는 두 가지 방식을 사용합니다. 그 결과 각각 ResNet-AT (WRN-AT)와 ResNet-TRADES (WRN-TRADES)가 생성됩니다.
BEST와 비교할 다른 공격기법들은 자연 샘플을 사용하는 Vanilla, AE를 사용하는 JBDA, 그리고 강건한 증류 기법들입니다. 강건한 증류 기법들로는 ARD, IAD, RSLAD가 사용됐으며, 이들은 강건한 교사 모델을 증류하여 더욱 강건한 학생 모델을 생성하는 기법입니다. 다만, 이 증류 기법들은 교사 모델에 대한 화이트 박스 접근을 전제하기 때문에, 본 논문의 Threat Model과 맞지 않습니다. 따라서 BEST와 동일한 블랙 박스 제약을 적용한 채 비교 실험합니다.
본 실험에서 대체 모델의 성능 평가 지표는 다음과 같습니다.
- CA: \(D_T\) 의 자연 샘플에 대한 정확도
- rCA: \(D_T\) 의 자연 샘플에 대한 원본 모델과의 예측 일치율(Fidelity)
- RA: 다양한 적대적 공격(PGD20, PGD100, CW100, AA)에 대한 정확도
실험 결과
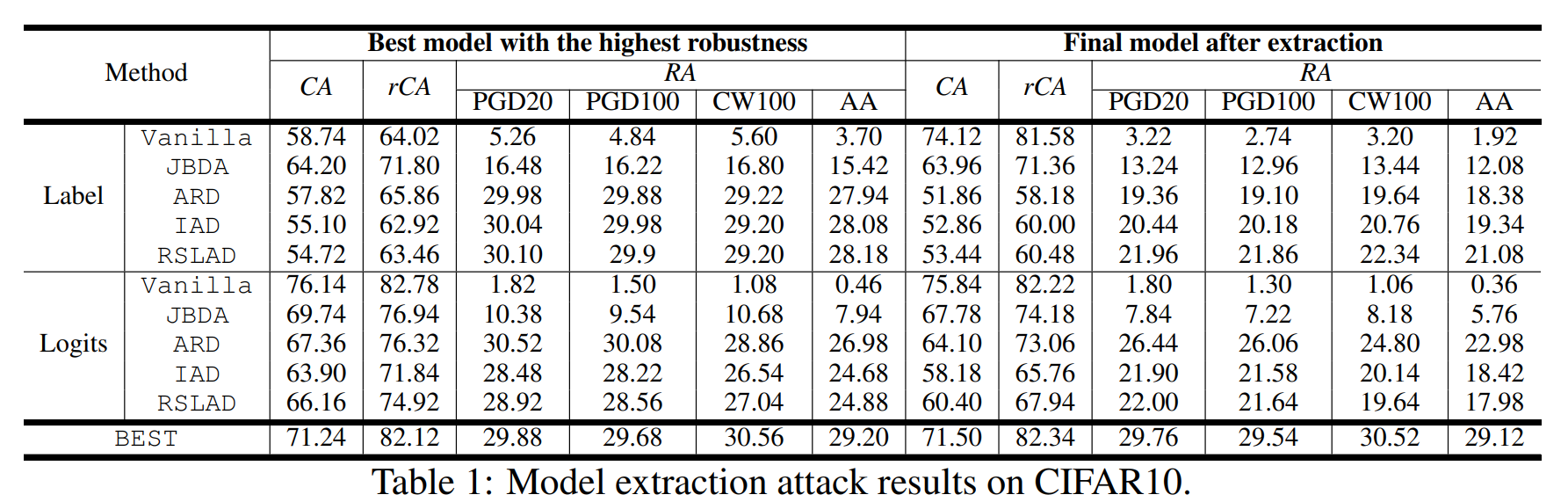
위 표는 다양한 공격 기법들과 BEST의 추출 성능을 비교한 실험 결과입니다. 원본 모델은 ResNet-AT, 대체 모델은 ResNet, 데이터셋은 CIFAR10이 사용되었습니다.
또한 원본 모델이 하드 레이블만 출력하는 경우, 로짓 벡터를 출력하는 경우를 구분하여 실험합니다. 이때 BEST는 로짓 벡터를 출력받더라도, 하드 레이블만 사용하기 때문에 별도로 표기됩니다.
결과를 보면, BEST는 대부분의 공격보다 모든 성능 지표가 높았습니다.
그리고 대부분의 공격은 최종 모델이 최적 모델보다 RA가 낮습니다. 이는 Robust Overfitting 때문에 발생합니다. 반면에 BEST는 UE를 사용한 덕분에 최종 모델과 최적 모델의 RA 격차를 줄일 수 있었습니다.
또한 원본 모델이 로짓 벡터를 반환하면, 대부분의 공격이 (r)CA는 증가하지만, RA는 감소합니다. 로짓 벡터는 불확실한 예측 정보를 포함하기 때문에, 이를 학습에 사용한다면 강건성이 감소하기 때문입니다.
원본 모델이 하드 레이블만 반환하면, 강건한 증류 기법들의 CA와 RA는 모두 크게 감소했습니다. 하드 레이블 제약 조건이 강건한 증류의 필요 조건인 화이트 박스 가정을 위배하기 때문입니다.

위 실험은 대체 모델로 원본 모델(ResNet-AT)과 다른 아키텍처를 사용했을 때의 성능을 보여줍니다. VGG와 MobileNet의 성능이 ResNet과 WRN보다 약간 낮은데, 이는 아키텍처 자체의 성능 차이로 인한 것입니다.
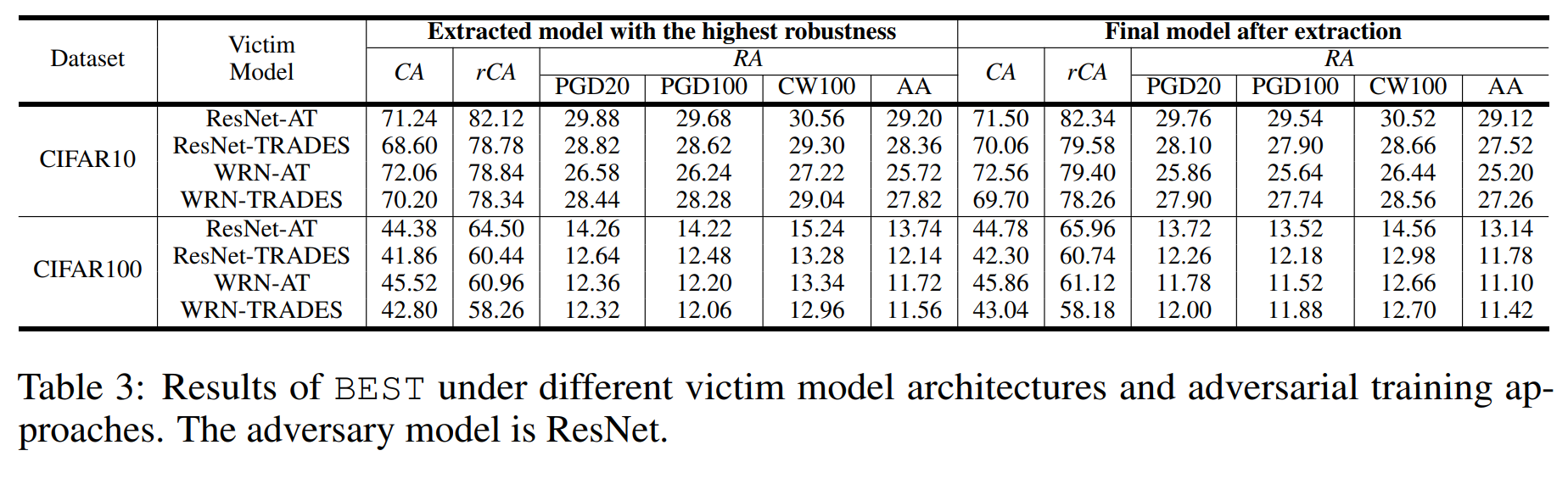
본 연구는 원본 모델이 적대적 학습을 거친다고 가정합니다. 위 실험은 원본 모델에 적용하는 적대적 학습 방식들에 따른 성능 차이를 보여줍니다. 결과를 보면, 큰 차이가 나지 않음을 알 수 있습니다.
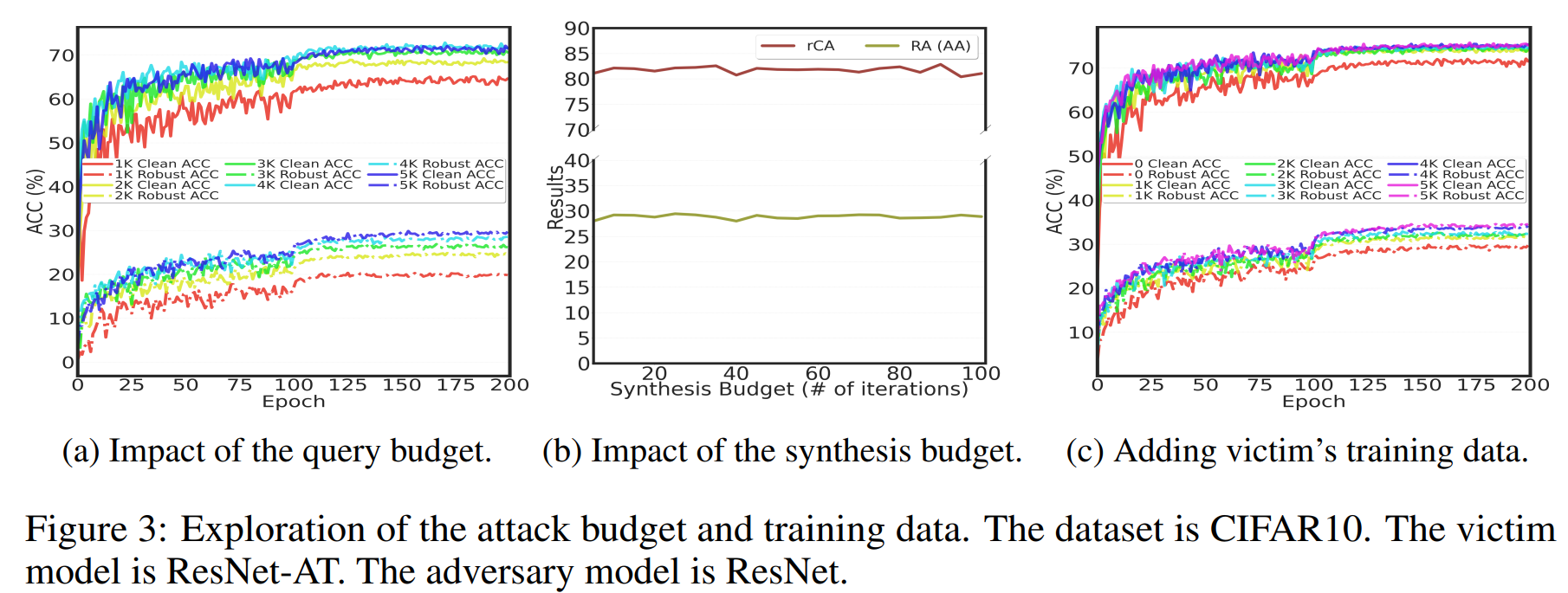
(a)는 UE 생성용 \(D_A\) 크기를 조절하며, 질의 예산이 BEST의 성능에 미치는 영향을 보여줍니다.
그 결과, 질의 예산이 클수록 CA와 RA 모두 향상됩니다. 그리고 질의 예산이 매우 작더라도 Robust Overfitting은 발생하지 않았습니다.
(b)는 합성 예산이 BEST의 성능에 미치는 영향을 보여줍니다. 그 결과, 매우 낮은 합성 예산만으로도 높은 공격 성능을 달성했습니다.
합성 예산을 늘려 최적화 단계를 더 많이 거쳐도 성능은 거의 향상되지 않았는데, 이는 BEST의 UE 생성 방식이 매우 효율적이어서 추가적인 비용 투자가 더 질 좋은(즉, \(\delta\) 가 더 작은) UE를 더 많이 만들어내는 데 큰 도움이 되지 않음을 의미합니다.
(c)는 원본 모델의 학습 데이터를 UE 생성용 \(D_A\) 에 추가했을 때, 공격 성능이 높아지는 모습을 보여줍니다.
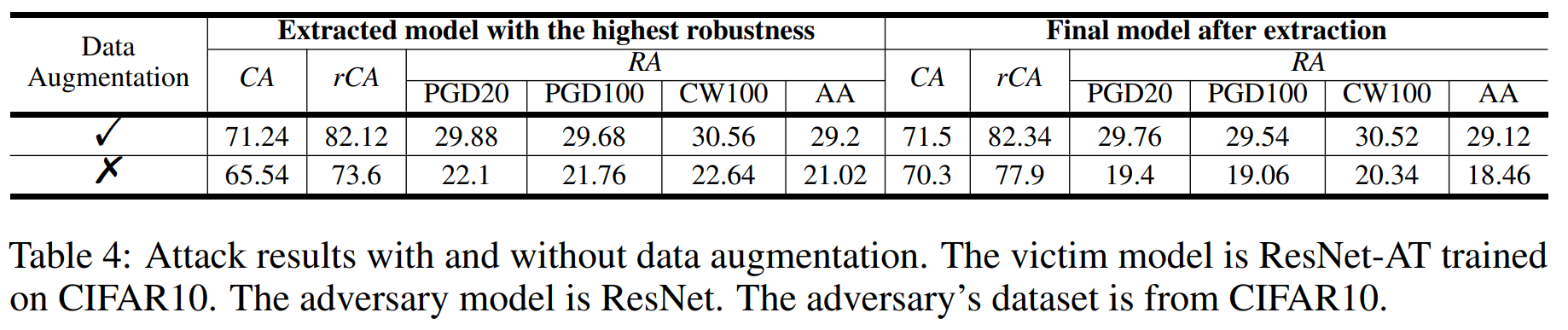
위 실험은 데이터 증강을 UE 합성에 결합했을 때의 결과를 보여줍니다. 그 결과, \(D_A\) 의 샘플을 증강시킨 후 UE로 합성하면, CA와 RA 모두 향상되는 모습을 확인할 수 있습니다.
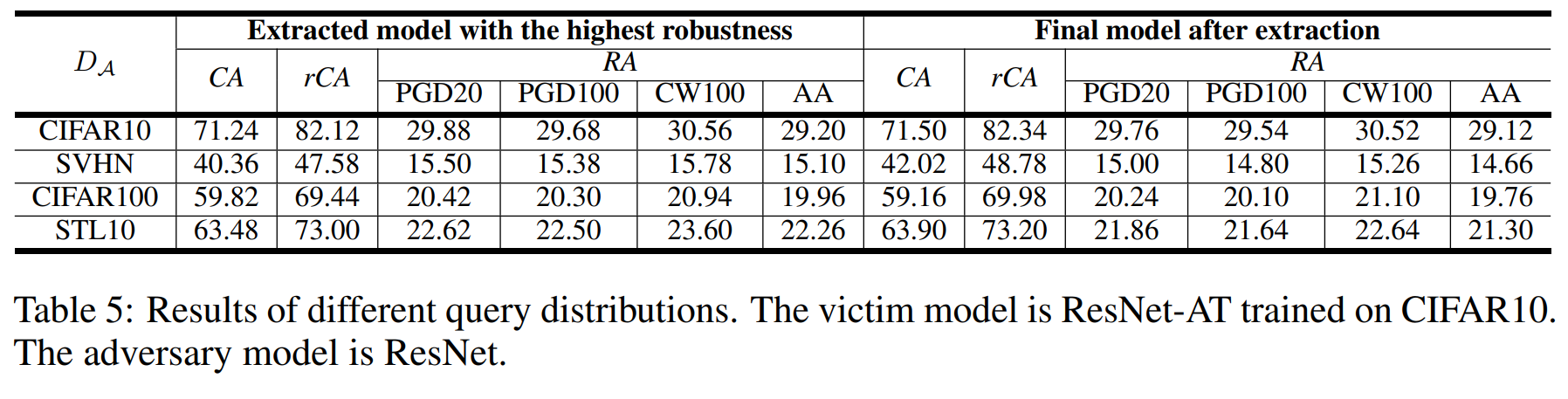
위 실험은 원본 모델(CIFAR10으로 학습)과 다른 분포의 데이터셋(SVHN, CIFAR100, STL10)을 \(D_A\) 로 사용했을 때의 추출 성능을 보여줍니다.
그 결과, 원본 모델의 학습 데이터 분포와 \(D_A\) 분포의 차이가 클수록, CA와 RA 모두 크게 하락했습니다.
따라서 공격 성능을 높이려면, 공격자는 원본 모델이 학습했을 데이터와 최대한 비슷한 분포의 데이터를 사용하는 것이 유리합니다.
기존 방어 전략 우회
BEST 공격은 아래의 모델 추출 방어 기법들을 우회할 수 있습니다.
-
로짓 벡터 교란: 모델의 최종 예측(하드 레이블)은 바꾸지 않고, 내부 예측값(로짓 벡터)에 노이즈를 섞는 방어 기법입니다. 하지만 BEST는 로짓 벡터가 아닌, 하드 레이블만으로 학습하기 때문에 이 방어에 전혀 영향을 받지 않습니다.
-
악성 질의 탐지
-
PRADA: 질의의 통계적 분포를 지표로 공격을 탐지하는 방어 기법입니다. 하지만 BEST가 데이터 증강을 적용한 후 UE를 생성하면, 질의 분포의 통계적 패턴이 변형됩니다. 그 결과, PRADA가 공격을 탐지하지 못하게 됩니다.
-
SEAT: 유사한 질의를 반복하는 계정을 차단하는 방어 기법입니다. 공격자는 여러 계정을 사용하여 질의를 분산함으로써 쉽게 우회할 수 있습니다.
-
결론
본 논문은 이제까지 연구된 적 없던 딥러닝 모델의 강건성 추출(Robustness Extraction) 에 대한 첫 번째 연구를 제시합니다.
이 연구는 원본 모델의 정확도와 강건성을 동시에 추출하기 위해, 불확실한 예제(Uncertain Example)를 합성하여 질의하는 새로운 공격 기법 BEST를 제안합니다.
실험 결과, BEST는 정확도나 충실도만을 목표로 하던 기존 공격들과 달리 모델의 강건성까지 성공적으로 추출해냈습니다.
이러한 결과는 모델의 강건성도 탈취 가능한 지적 자산이자 공격의 표적이 될 수 있음을 시사하며, 이에 대응할 방어 전략의 필요성을 강조합니다.