Paper: Prediction Poisoning: towards defenses against DNN model stealing attacks
Authors: Tribhuvanesh Orekondy, Bernt Schiele, Mario Fritz
Venue: 2020 The International Conference on Learning Representations (ICLR)
URL: Prediction Poisoning: towards defenses against DNN model stealing attacks
Introduction
Deep learning models are used in various real-world services such as voice assistants, autonomous driving, and cloud APIs, and their development requires enormous costs and time. Therefore, these models are core business assets, and defense against external theft is essential.
Model stealing is an attack where the attacker repeatedly sends queries to a model, collects responses, and uses them as training data to create a replica model. Recent studies have shown that even deep learning models can be replicated at low cost in a black-box environment.
Existing defense approaches fall broadly into two categories:
- Detecting the attacker’s query patterns
- Distorting parts of the model’s output probabilities to interfere
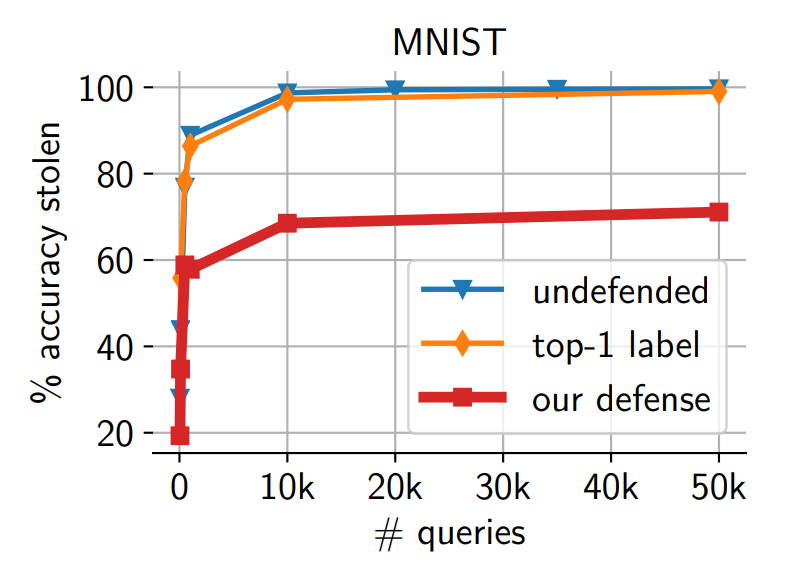
However, in practice, attacks are possible with Top-1 results alone, and existing approaches either fail to completely block attackers or cause significant accuracy losses.
This paper proposes a new defense strategy called Prediction Poisoning to overcome these limitations. The core idea is to perturb the prediction results that attackers use to train their replica models, so that normal users are unaffected while the attacker’s replica model undergoes incorrect training.
The proposed method can be easily applied to existing classification models with a simple structure and minimal resource consumption, and experimental results show it achieves greater defense effectiveness with less distortion compared to existing defenses:
Background
-
Jacobian-based attacks Attackers can effectively replicate the target model by generating attack samples using the gradient information of the replica model. Representative attacks in this category include:
- JBDA (Jacobian-Based Data Augmentation; Papernot et al. 2017) A technique that trains a replica model with a small amount of initially labeled data, then improves attack efficiency by generating and using synthetic data with perturbations added in the gradient direction.
- JB-self (Juuti et al. 2019) A method that generates synthetic data using only the target model’s Top-1 prediction as if it were the ground truth, enabling attacks without actual labels and suitable for fully black-box environments.
- JB-top3 (Juuti et al. 2019) A technique that generates gradient directions considering up to Top-3 predicted classes, reflecting richer class information to improve replica model performance.
-
Knockoff Nets (Orekondy et al. 2019) An attack technique that queries the target model with real images such as OpenImg and ILSVRC, samples a dataset based on the responses to train a replica model.
-
Existing defenses Existing defense approaches primarily attempt to hinder attacks by manipulating or adding noise to output probabilities (softmax posteriors). However, most have limitations in degrading attacker performance while maintaining accuracy.
- Top-k truncation Outputs only the top k softmax probabilities and removes the rest to minimize information leakage. (e.g., returning only top-1 argmax)
- Rounding Reduces the precision of softmax outputs by truncating decimal places. (e.g., 0.923 → 0.92)
- Reverse-sigmoid (Taesung Lee et al. 2018) A defense that nonlinearly transforms the softmax probability distribution, maintaining the top-1 result while introducing uncertainty to lower probability values.
- Random noise (John Duchi et al. 2008) Adds random noise to the output probability vector to make replica model training difficult. Larger noise levels also cause greater accuracy losses.
- DP-SGD (Martin Abdai et al. 2016) A defense that adds noise to gradients and applies clipping during the model training phase, introducing uncertainty to model parameters themselves to prevent training data leakage.
Main Content
Objective
The purpose of this defense is summarized in two points:
- Utility: The quality of predictions for normal users must be maintained.
- Non-replicability: Reduces the attacker’s ability to replicate the target model, degrading replica model performance.
Maximizing Angular Deviation (MAD)
This paper proposes a new defense technique, MAD (Maximizing Angular Deviation), which disrupts learning by perturbing the gradient direction that attackers use for training their replica models.
Below is a simple diagram illustrating the defense process:

-
Targeting first-order approximation
The attacker attempts to minimize the loss by adjusting the parameters \(w\) of the replica model \(F_A(x;w)\) to match the target model’s prediction \(y\). In this process, most optimization uses the gradient of the loss with respect to the parameters (first-order approximation): \(\begin{align} u = -\nabla_w\mathcal{L}(F(x;w),y) \end{align}\) The attacker trains the replica model following this gradient direction.
-
Core idea
MAD perturbs the target model’s output to \(\tilde{y}\) so that the attacker obtains the following gradient information: \(\begin{align} a = -\nabla_w\mathcal{L}(F(x;w),\tilde{y}) \end{align}\)
The perturbed gradient information \(a\) is then made to differ as much as possible from the original gradient information \(u\):
\[\begin{align} \max_{\hat{a}}{\lVert{\hat{a}-\hat{u}}\rVert}_2^2\quad (\hat{a}=a/\lVert{a}\rVert_2,\hat{u}=u/\lVert{u}\rVert_2) \end{align}\]This can be specifically expressed as a formula that maximizes the distance between normalized directions:
\[\begin{align} \max_\tilde{y} \left\| \frac{G^T\tilde{y}}{\|G^T\tilde{y}\|_2} - \frac{G^T y}{\|G^T y\|_2} \right\|_2^2 \quad (=H(\tilde{y})) \end{align}\]Here, \(G\) is the Jacobian of the log likelihood with respect to the parameter direction, expressed as: \(\begin{align} G = \nabla_w\log{F(x;w)}\quad (G\in\mathbb{R}^{K \times D}) \end{align}\)
Through \(G\), the gradient information \(u\) and \(a\) can be expressed as: \(\begin{align} u = G^Ty\quad a = G^T\tilde{y} \end{align}\)
-
Constraints The above optimization problem includes the following constraints:
- \(\tilde{y}\) must lie on the probability simplex:
2. Distortion must be limited to a level \(\epsilon\) or below (utility preservation):
\[\begin{align} \text{dist}(y,\tilde{y}) \le \epsilon \end{align}\quad \text{(Utility constraint)}\]-
Practical challenges and solutions
-
Estimating \(G\) Since the defender cannot know the attacker’s exact model \(F\) in advance, a surrogate model \(F_\text{SUR}\) is used to estimate \(G = \nabla_w\log{F_\text{SUR}(x;w)}\).
The surrogate model uses a randomly initialized, untrained CNN model.
-
Heuristic solution
Since the objective function \(H(\tilde{y})\) is non-convex, simple gradient ascent may get stuck in local optima.
Therefore, the paper uses the following two-step strategy:
-
Extreme point search
Among the vertices (one-hot vectors) \(y^*\) of the probability simplex, select the candidate that maximizes the objective \(H(\tilde{y})\).
-
Linear interpolation
Create the final \(\tilde{y}\) by linearly interpolating between the original probability distribution \(y\) and the selected \(y^*\): \(\begin{align} \tilde{y} = (1-\alpha)y+\alpha y^* \end{align}\)
Here, \(\alpha\) is adjusted to satisfy the distortion constraint \(dist(y,\tilde{y}) \le \epsilon\).
-
-
-
Variant: MAD-argmax
To preserve the top-1 accuracy, the following constraint can be added: \(\begin{align} \arg\max_k \tilde{y}_k = \arg\max_k y_k \end{align}\)
Experimental Setup
-
Attack strategies
The following four attacks are used to evaluate defense performance:
- JBDA
- JB-self
- JB-top3
- Knockoff Nets
The attacker performs 50,000 black-box queries to the target model \(F_V\), collects pseudo-labels, and trains the replica model \(F_A\) using the resulting transfer set.
-
Target model setup
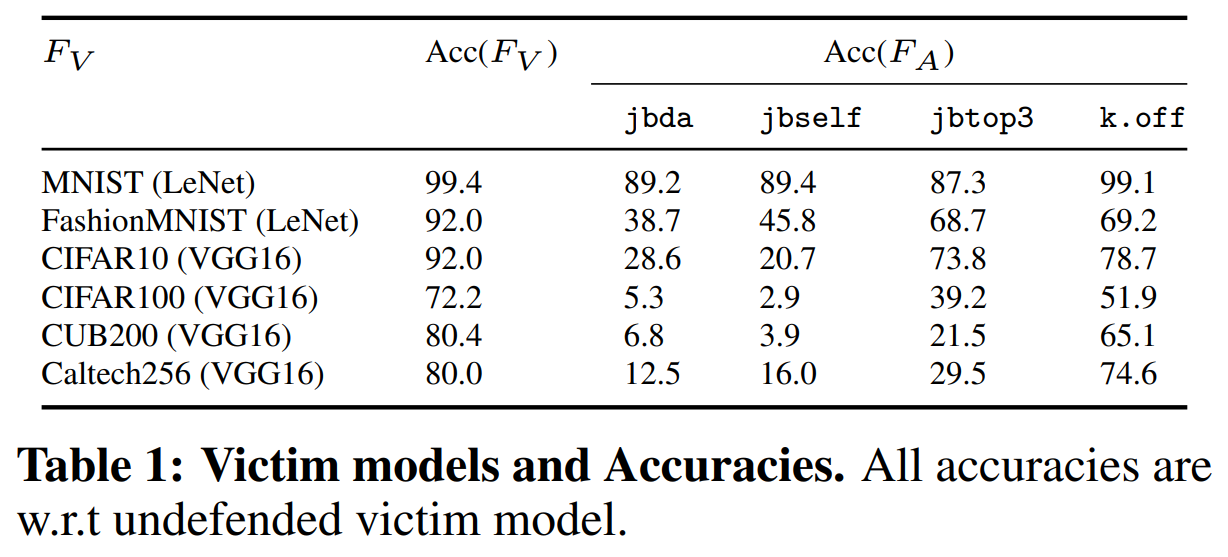
A total of six victim models were used, with LeNet and VGG16 architectures.
The following shows each model’s architecture, dataset used, and the accuracy of the original model and replica models by attack type:
-
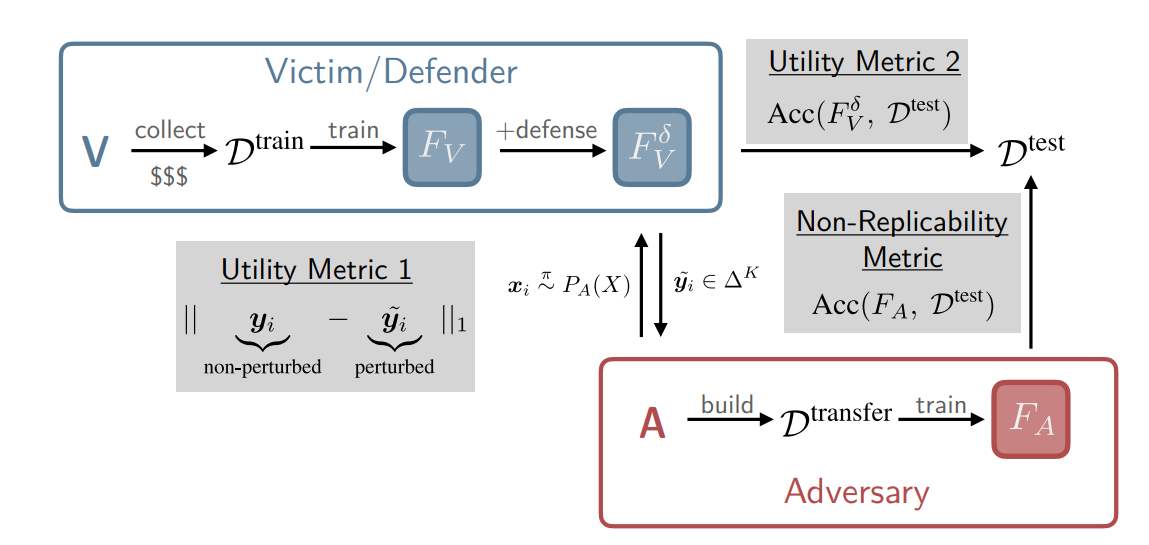
Evaluation metrics
The defense performance metrics are as follows:
- Non-replicability The accuracy achieved by the replica model \(F_A\) on the target model \(F_V\)’s test set \(D^{test}\)
-
Utility
- Accuracy The accuracy of the probability-perturbed target model \(F_V^\delta\) on the test set \(D^{test}\)
- Distortion magnitude The \(L_1\) distance between the original probability \(y\) and the perturbed \(\tilde{y}\): \(\left\|y-\tilde{y}\right\|_1\)
Each metric is positioned in the overall pipeline as follows:
-
Defense baselines
The baseline techniques for evaluating MAD’s defense performance are:
- Reverse-sigmoid
- Random noise
- DP-SGD
Experimental Results
- MAD vs. Attacks
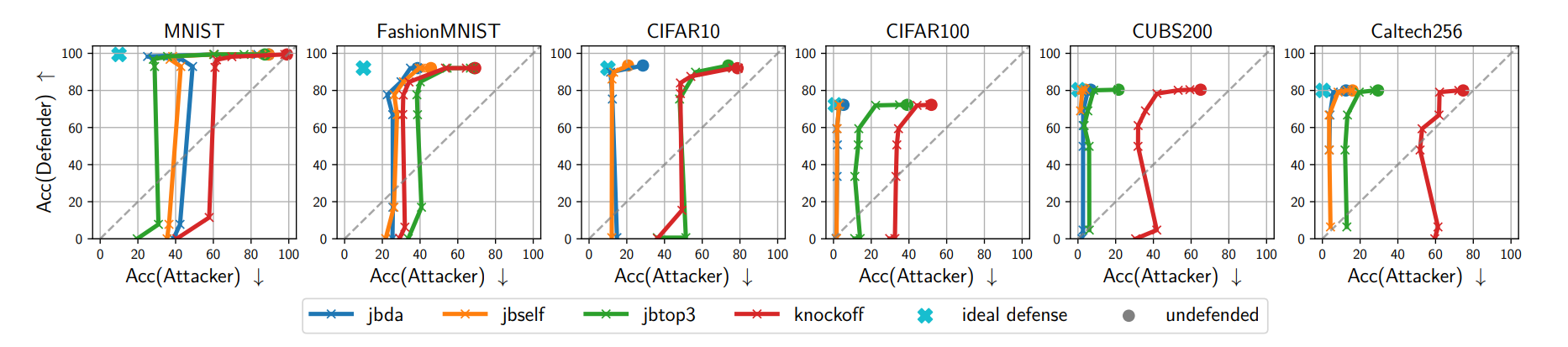
MAD and MAD-argmax significantly degrade the attacker’s performance across all attacks and datasets. Even small utility losses were sufficient to greatly impair the attacker’s replication ability.
-
MAD vs. baseline
The following shows MAD’s performance comparison against other defense techniques:
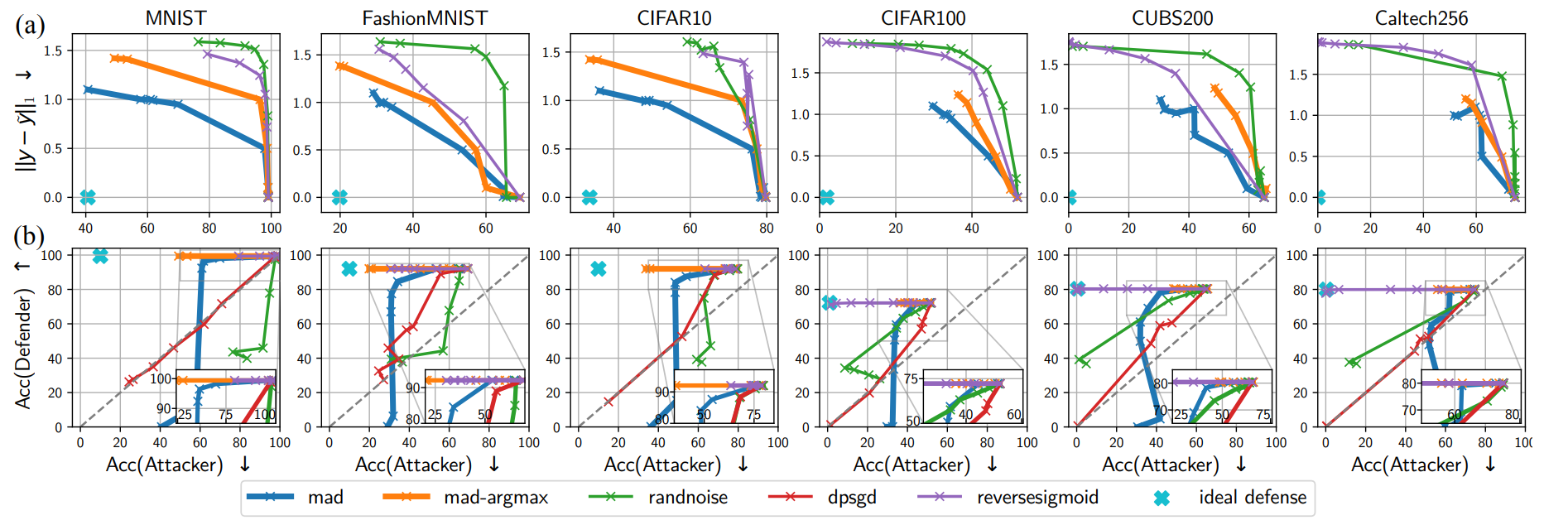
-
\(L_1\)-based comparison (a)
Reverse-sigmoid and random noise also weaken the attacker, but achieving the same level of non-replicability required much larger distortion. In contrast, MAD-family defenses demonstrated equal or better defense capability with smaller distortion.
-
Non-replicability vs. Utility (b)
MAD-argmax and reverse-sigmoid reduced attacker accuracy by over 20% while maintaining top-1. While DP-SGD and random noise also reduced attacker accuracy, the defended model’s accuracy suffered significantly, whereas MAD showed minimal accuracy loss at similar suppression levels.
-
Gradient direction distortion analysis
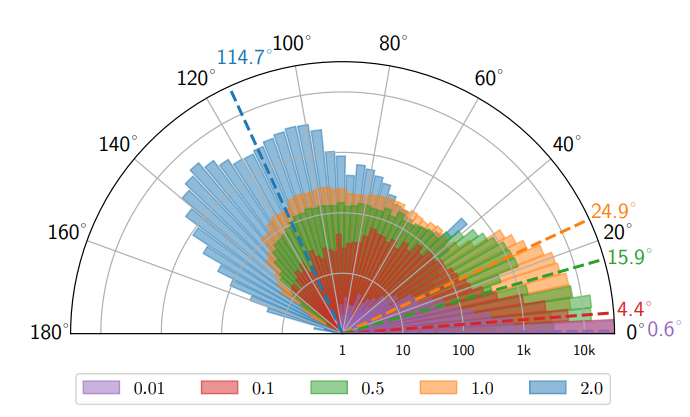
In experiments directly tracking gradient directions, it was confirmed that perturbations within the limited probability simplex could twist the gradient of high-dimensional models like VGG16 by an average of approximately 24.9 degrees. This slows the rate of loss decrease, degrading the replica model’s training efficiency:
- Ablation study analysis
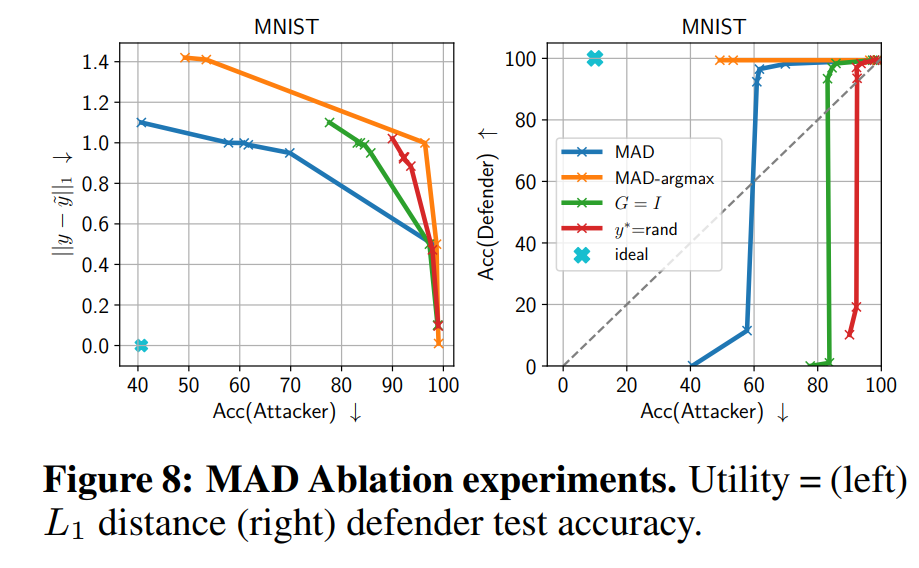
Compared to replacing the Jacobian with the identity matrix \(I\) or using random extreme points, MAD using actual gradient information showed the best performance. This supports that gradient-based design is the key to the defense.
- Evasion attempts
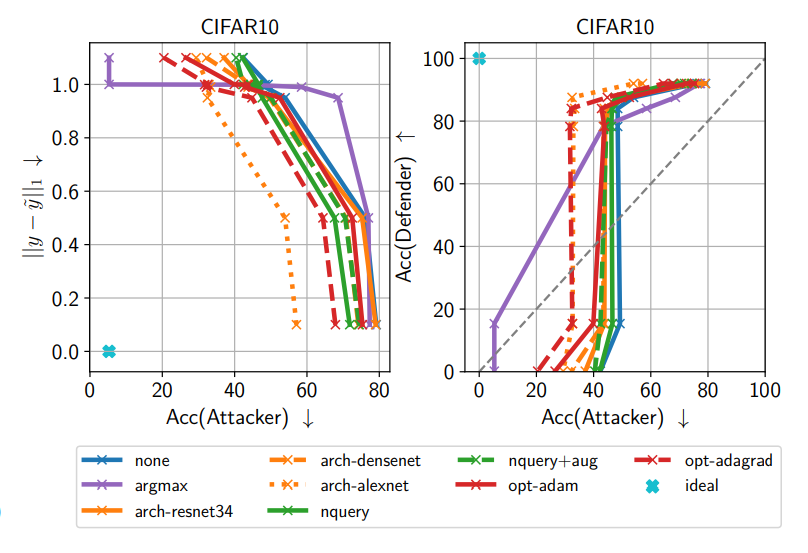
The attacker tried various evasion strategies including argmax-only, different architectures and optimizers, repeated queries, and data augmentation. Among these, the most threatening was argmax-only training using only top-1, but MAD was still able to reduce the attacker’s performance by approximately 9 percentage points.
Conclusion
This study proposed Prediction Poisoning, specifically MAD (Maximizing Angular Deviation), an active defense that disrupts the attacker’s learning objective itself. MAD showed consistent effectiveness across multiple models and various attack strategies, reducing the attacker’s accuracy by up to approximately 65% while maintaining the defended model’s accuracy with minimal utility loss.
These results demonstrate that strong defense is possible with small distortions against model stealing threats, and suggest future research directions including strengthening defense against top-1-based attacks and generalization to other domains.