논문명: SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation
저자: Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, Sijia Liu
게재지: 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
기존 연구
“머신 언러닝(Machine Unlearning)”은 사전 학습된 모델에서 특정 데이터 포인트의 영향을 완화하는 작업을 지칭합니다.
EU의 ‘잊힐 권리(right to be forgotten)’ 등 법령을 준수하기 위해 최근 활발히 연구되고 있는 분야이며, 특히 CV(Computer Vision) 분야에서의 머신 언러닝이 각광받고 있습니다.
본 논문에서는 기존 머신 언러닝이 가지는 한계, 특히 이미지 분류(image classification)와 이미지 생성(image generation) 모델에서의 한계를 다루고 이에 대한 해결책으로 새로운 머신 언러닝 방법인 SalUn(Saliency-based Unlearning)을 제시합니다.
이미지 생성 모델에서의 머신 언러닝
기존 이미지 생성 모델은 텍스트를 조건으로 받는 경우, 이미지 생성 시 텍스트 설명에 크게 의존하는 경향을 보였습니다. 또한 LAION-400M, LAION-5B 등 방대한 양의 데이터셋으로 학습되는 경우가 많아, 데이터셋에 포함된 편향(bias)과 유해 데이터를 학습할 확률이 높았습니다.
이미지 분류 모델에서의 머신 언러닝뿐만이 아니라 이미지 생성 모델에서 역시 효율적이고 효과적인 머신 언러닝을 수행할 수 있는 기법을 찾는 것이 본 논문의 목적입니다.
기존 머신 언러닝의 한계
기존 머신 언러닝 기법
논문에서는 다음의 다섯 가지 머신 언러닝 기법들을 제시합니다:
-
Fine Tuning(FT) : 제거하지 않은 데이터셋에 대해 사전학습된 모델을 재학습시킵니다.
-
Random Labeling(RL) : 제거 대상 데이터셋을 무작위로 잘못 라벨링한 후, 랜덤으로 라벨링된 데이터셋으로 사전학습된 모델을 재학습시킵니다.
-
Gradient Ascent(GA) : 제거 대상 데이터셋에 대한 모델의 학습을 되돌려 손실을 최대화합니다.
-
Influence Unlearning(IU) : 사전 학습된 모델에서 제거 대상 데이터셋의 영향을 지우기 위해 영향 함수(influence function)를 사용합니다.
-
L1-sparse MU : weight sparsity를 도입해 제거 대상 데이터를 제거합니다.
불안정성(Instability)
앞선 연구는 제거할 데이터의 크기를 고정해 실험하는 경우가 일반적이었습니다. 따라서 제거 데이터셋의 크기나 비율이 머신 언러닝 성능에 미치는 영향에 대한 연구가 부족했습니다.
그래프 (a)에서는 전체 데이터의 10%를 제거할 때보다 50%를 제거할 때 Retrain방식과의 성능 차이가 커지는 것을 확인할 수 있습니다.
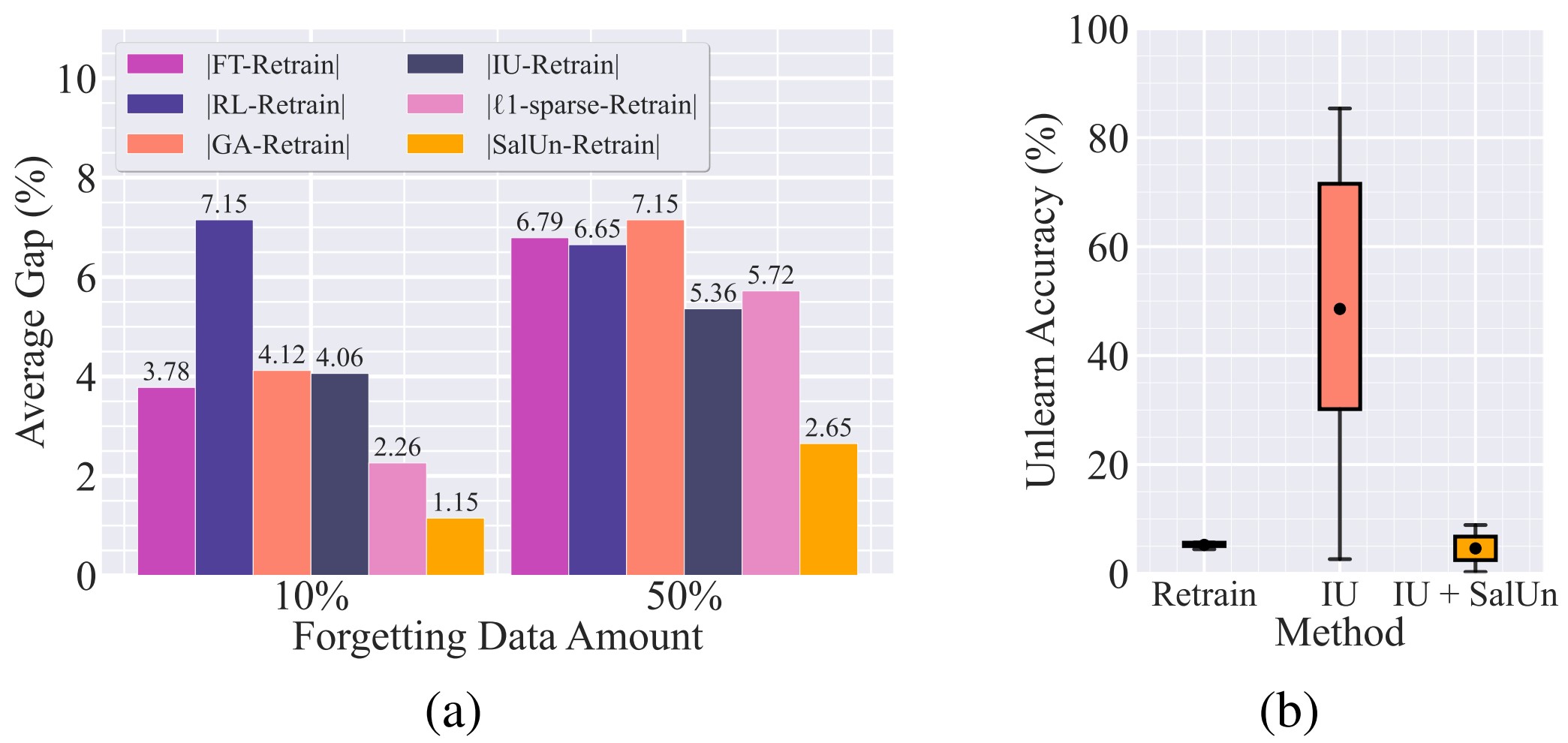
또한 그래프 (b)에서는 안정적인 정확도 성능을 보이는 Retrain 방식과 달리, 사용한 하이퍼파라미터(hyperparameter)에 따라 IU(Influence Unlearning) 의 성능 차이가 크게 변동하는 것을 확인할 수 있습니다. 이러한 불안정성은 IU와 SalUn을 동시에 적용함으로써 완화할 수 있습니다.
일반성 부족(Lack of Generality)
머신 언러닝 모델은 이미지 분류 작업에 주로 사용되었습니다. 하지만 이미지 분류 모델에서의 머신 언러닝 방법들은 이미지 생성 모델에서의 머신 언러닝 성능을 보장하지 못합니다.
이는 제거해야 할 데이터를 제거하지 못하거나(Under-forget) , 제거하지 않아야 할 데이터를 제거하는(Over-forget) 문제를 야기합니다.
다음 표는 특정 클래스(class) “airplane”을 제거하는 classwise-forgetting 후 각 머신 언러닝 기법 Retrain, GA, RL, FT, l1-sparse에서의 이미지 생성 결과입니다.
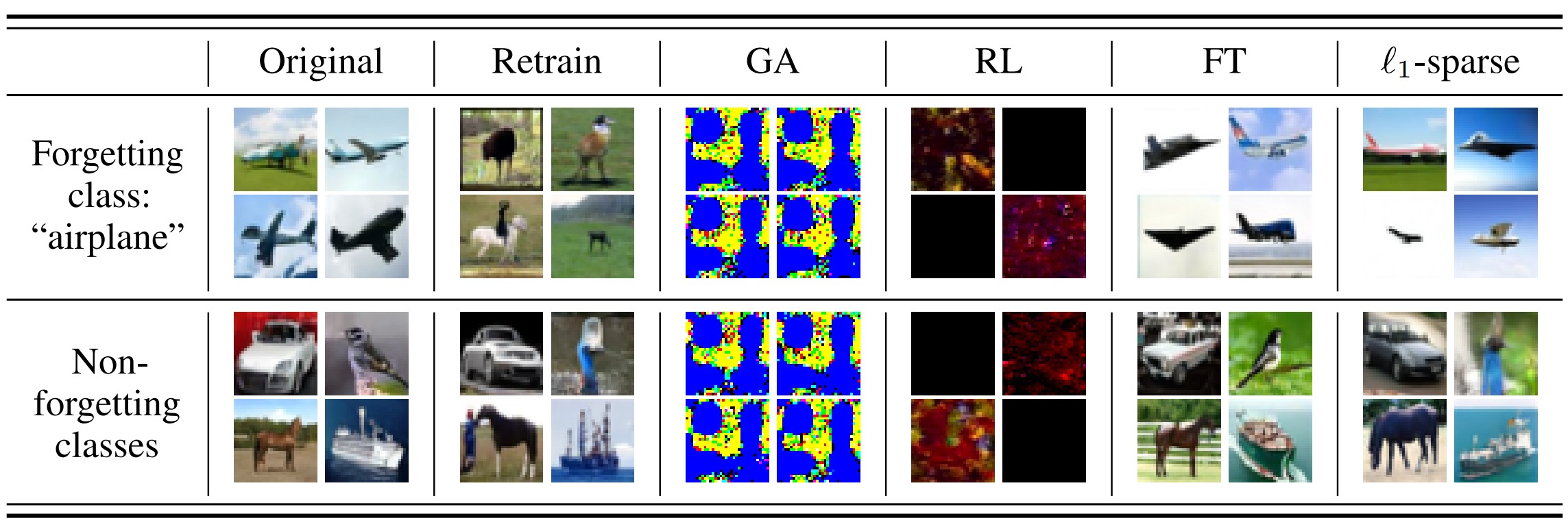
GA와 RL에서 생성한 ‘Non-forgetting class’에 대한 결과는 모델이 제거하지 않아야 할 데이터 또한 제거했음을 나타냅니다(Over-forget).
또한 FT와 l1-sparse에서 생성한 ‘forgetting class : “airplane”’ 의 결과에서 모델이 제거해야 할 클래스를 효과적으로 제거하지 못했음을 알 수 있습니다(Under-forget).
Machine Unlearning in image Classification and Generation
머신 언러닝 목적
- 사전학습된 모델에서 효과적이고 효율적인 가중치 업데이트가 일어날 수 있도록 합니다.
- Retrain 모델과의 성능 차이를 최소화합니다.
논문에서는 이미지 분류 모델, 이미지 생성 모델에서의 머신 언러닝을 고려합니다.
이미지 분류 모델에서의 머신 언러닝
이미지 분류 모델은 머신 언러닝 분야에서 가장 많이 연구된 분야로, 제거 대상 데이터셋의 구성에 따라 크게 두 가지 머신 언러닝 방법으로 나뉩니다 :
- Class-wise forgetting : 데이터셋에서 특정 이미지 클래스(class)의 영향을 제거합니다.
- Random data forgetting : 훈련 데이터(training set)에서 랜덤으로 몇 개의 데이터를 제거합니다(e.g. 총 60,000쌍의 데이터셋 중 랜덤으로 10,000쌍의 데이터셋 제거하기).
평가 지표 : ‘full-stack’ evaluation
이미지 분류 모델에서의 머신 언러닝 성능을 평가합니다. 이때 한 가지의 평가 지표만이 모델 전체의 성능을 대표하지 않도록 다섯 가지의 평가지표가 사용됩니다.
-
Unlearning Accuracy(UA) : 제거 대상 데이터셋에 대한 모델의 정확도를 측정합니다.
-
Membership Inference Attack(MIA) : 언러닝 후 제거 대상 데이터가 데이터셋에 남아있는지의 여부를 확인합니다.
-
Remaining Accuracy(RA) : 제거 대상이 아닌 데이터셋에 대한 언러닝 후 모델의 성능의 유지 정도(fidelity)를 측정합니다.
-
Testing Accuracy(TA) : 언러닝 후 모델의 전반적인 데이터셋에 대한 정확도를 측정합니다.
-
Run-time efficiency(RTE) : 언러닝 기법을 적용하는 데에 드는 연산 비용(computation time)을 측정합니다.
이미지 생성 모델에서의 머신 언러닝
이미지 생성 모델에서의 머신 언러닝 목적
- 이미지 생성 모델이 부적절한 이미지를 생성하는 것을 방지합니다.
- 머신 언러닝 후 가중치가 업데이트된 DM이 정상 이미지에 대한 이미지 생성 성능을 보존하도록 합니다.
논문에서는 조건부 DM(Conditional Diffusion Model)이 부적절한 프롬프트(prompt)를 받았을 때 유해한 이미지를 생성하는 문제를 해결합니다.
확산(Diffusion) 과정
이때 두 가지의 DM이 사용됩니다:
1) DDPM(Denoising Diffusion Probabilistic Model) with classifier-free guidance
2) LDM(Latent Diffusion Model)
기존의 classifier-free DM은 아래와 같은 과정을 거쳐 학습됩니다.
\[\begin{equation} \hat{\epsilon}_o(x_t | c) = (1 - w) \epsilon_o(x_t | \emptyset) + w \epsilon_o(x_t | c) \end{equation}\]이때 \(c\)는 텍스트 프롬프트 혹은 컨셉을 지칭하며, 위 식은 \(c\)를 조건으로 생성된 노이즈에 가중치 \(w\)를 곱하고, \(c\)가 없을 때 생성된 노이즈에 \((1-w)\)를 곱하는 과정으로 구성됩니다.
즉, 이는 \(c\)가 주어졌을 때 비조건부 노이즈(unconditional noise)와 조건부 노이즈(conditional noise)를 모두 고려해 최종 노이즈를 구하는 과정입니다.
SalUn : Weight Saliency is Possibly All You Need for MU
Gradient-based weight saliency map
SalUn은 기존의 머신 언러닝 기법과 달리 모든 가중치를 바꾸는 게 아닌, saliency map에 따른 가중치의 중요도에 따라 특정 모델 가중치만을 업데이트합니다.
Saliency map을 수식으로 나타내면 아래와 같습니다.
\[\begin{equation} m_S = \mathbb{1}(|\nabla_{\theta} \ell_f (\theta; \mathcal{D}_f) |_{\theta = \theta_0} \geq \gamma) \end{equation}\]이때 saliency map은 특정 데이터에 대한 기울기의 절댓값이 일정 기준 이상이면 1을 반환하고, 그렇지 않으면 0을 반환하는 일종의 마스킹(masking) 역할을 합니다.
위의 saliency map 식을 머신 언러닝 과정에 적용하면 아래와 같은 식을 유도할 수 있습니다.
\[\begin{equation} \theta_u = m_S \odot (\Delta \theta + \theta_0) + (1 - m_S) \odot \theta_0 \end{equation}\]좌변은 언러닝 후의 모델입니다. saliency map 값이 1이면 모델의 가중치 업데이트값을 적용하고, saliency map 값이 0이면 기존 모델의 가중치를 유지합니다.
이를 통해 모델이 salient(중요한) 가중치 변화량만을 모델의 학습에 적용한다는 것을 알 수 있습니다.

Saliency mask의 성능은 위의 표에서 random masking과의 비교를 통해 확인할 수 있습니다.
특히 weight saliency를 고려하지 않은 random masking 처리 시에는 Over-forget 현상이 일어나 노이즈만을 생성한 결과를 얻을 수 있었습니다.
Saliency-based Unlearning
이미지 분류 모델에서의 SalUn
SalUn은 plug-and-play 특성을 이용해 Random Labeling과 함께 사용됩니다. 이때 각 제거 대상 데이터 포인트에 무작위로 라벨을 배정한 뒤, 해당 데이터셋을 saliency map으로 fine-tuning합니다.
\[\begin{equation} \underset{\Delta\theta}{\text{minimize}}\quad L_{\text{SalUn}}^{(1)} (\theta_u) \ \mathbb{E}_{(x,y) \sim \mathcal{D}_f, y' \neq y} \left[ \ell_{\text{CE}} (\theta_u; \mathbf{x}, y') \right] + \alpha \mathbb{E}_{(x,y) \sim \mathcal{D}_r} \left[ \ell_{\text{CE}} (\theta_u; \mathbf{x}, y) \right] \end{equation}\]다음은 SalUn의 성능을 7가지의 다른 언러닝 기법들과 비교한 그래프입니다.

Retrain 방식과의 성능 차이는 제거 데이터의 비율과 무관하게 SalUn을 사용해 머신 언러닝한 경우 가장 작았음을 확인할 수 있습니다.
이미지 생성 모델에서의 SalUn
각 이미지 데이터 x를 데이터셋으로 묶인 프롬프트 c가 아닌, 다른 값의 프롬프트 c’에 배정합니다.
\[\begin{equation} \underset{\Delta\theta}{\text{minimize}} \quad L_{\text{SalUn}}^{(2)} (\theta_u) \ \mathbb{E}_{(x,c) \sim \mathcal{D}_f, t, \epsilon \sim \mathcal{N}(0,1), c' \neq c} \left[ \|\epsilon_{\theta_u} (\mathbf{x}_t | c') - \epsilon_{\theta_u} (\mathbf{x}_t | c) \|_2^2 \right] + \beta \ell_{\text{MSE}} (\theta_u; \mathcal{D}_r) \end{equation}\]Class-wise forgetting 의 성능은 특정 클래스를 모델에서 제거한 후, 해당 클래스를 다시 프롬프트에 넣었을 때의 이미지 생성 결과를 통해 측정했습니다.
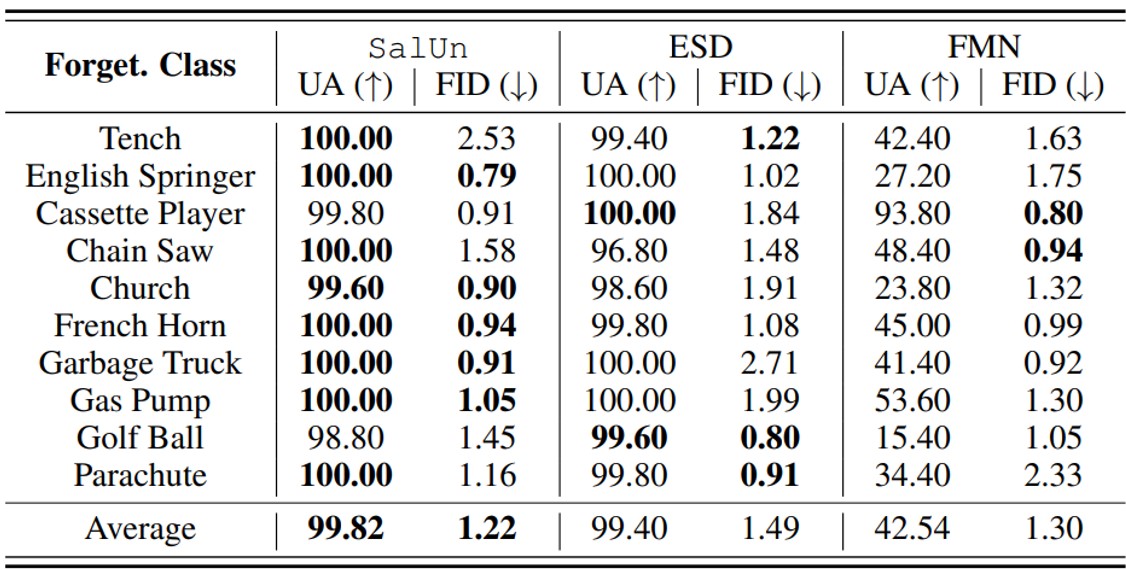
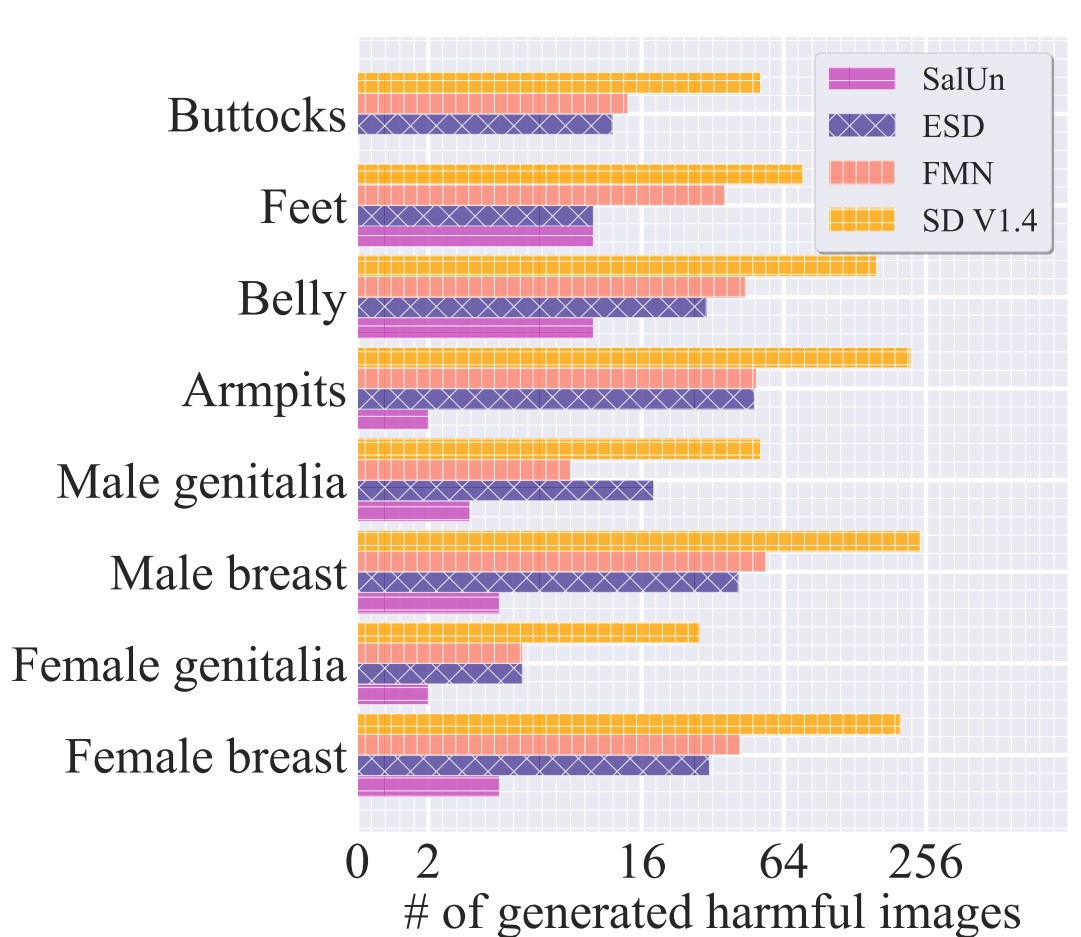
Concept-wise forgetting 의 성능은 NSFW에 속하는 개념 중 ‘nudity’를 모델에서 제거한 후 이미지 생성 결과를 통해 측정했습니다.
‘Soft-thresholding’ SalUn
제시된 SalUn은 saliency map을 구할 때 특정 값을 기준으로 손실함수 기울기의 중요도를 평가하는 ‘hard-thresholding’ 방법을 이용합니다.
연구에서는 고정된 기준으로 판단하는 것이 아닌, 확률을 도입해 유연한 접근 방식을 적용하는 ‘soft-thresholding’ 방식의 연구 방향을 제시합니다.