논문명: Towards Unbounded Machine Unlearning
저자: Meghdad Kuramanji, Peter Triantafillou, Jamie Hayes, Eleni Triantafillou
게재지: 37th Conference on Neural Information Processing Systems (NeurIPS 2023)
서론
머신 언러닝은 프라이버시 보호 및 다양한 특성의 데이터를 제거하기 위해 고안된 기술입니다.최근 딥러닝 기술이 컴퓨터 비전, 헬스케어, 자연어 처리 등 다양한 도메인이 활용됨에 따라 GDPR의 ‘잊힐 권리’의 범위가 증대되고 있습니다. 언러닝은 개인정보보호법 상 보관기간이 지난 데이터, 모델의 최신성을 유지하기 위해 유통기한이 지난 데이터를 제거하기 위해 활용되기도 하며 모델에 치명적인 편향된 데이터 및 노이즈가 추가된 데이터를 제거하기 위해 활용되기도 합니다.
해당 논문이 발표되기 전 많은 연구들은 다양한 시나리오 및 언러닝의 목적성을 고려하지 않았습니다. 프라이버시를 보호하거나 편향된 데이터를 제거하는 언러닝은 데이터를 지우는 것이 최우선이므로 모델의 성능을 일부 포기하더라도 forget quality를 높게 하는 것이 중요합니다. 이에 반해 모델의 최신성을 유지하기 위해 유통기한이 지난 데이터를 삭제하는 언러닝의 경우 모델의 성능(utility)을 유지하는 것이 더 중요합니다. 따라서 다양한 시나리오 및 언러닝의 목적을 모두 고려하여 모든 상황에서 일정한 성능을 낼 수 있는 언러닝 알고리즘이 필요하다고 본 논문은 주장하고 있습니다.
본론
SCRUB에 대해
SCRUB는 기본적으로 teacher-student 프레임워크 형태를 띄고 있습니다. SCRUB의 목적은 모델의 성능을 유지하며 언러닝을 효과적으로 하는 것입니다. SCRUB는 크게 두 가지 과정으로 나눌 수 있습니다.
첫 번째 과정은 forget-error을 최대화하는 과정이며 두 번째 과정은 rewind단계로 너무 높은 forget-error를 완화하는 과정입니다. 따라서 언러닝의 목적에 따라 사용자는 첫 번째 과정까지 적용할지 두 번째 과정까지 모두 적용할지 결정할 수 있습니다. 만약 편향된 데이터를 제거하거나 레이블이 잘못 할당된 데이터를 제거하기 위해서는 첫 번째 과정까지 SCRUB를 학습하고 프라이버시 보호를 위한 언러닝의 경우는 두 번째 과정까지 SCRUB를 학습합니다.
프라이버시 보호를 위해서 forget-error를 너무 높게 해서는 안되는 이유는 멤버십 추론 공격에 취약해질 수 있기 때문입니다. 모델의 과대적합과 같은 원리로 공격자 입장에서 굉장히 높은 forget-error를 통해 해당 데이터가 새로운 데이터인지 기존에 모델에 있었지만 삭제된 데이터인지 구별할 수 있게 됩니다.
SCRUB & Teacher-Student 모델
SCRUB에서 teacher-student 모델의 핵심 아이디어는 retain data에 대해서는 학생 모델이 선생 모델을 따르며 forget data에 대해서는 학생 모델이 선생 모델과 멀어지게 하는 것입니다.
\[\begin{equation} d(x; w_u) = D_{KL} \big( p(f(x; w_o)) \parallel p(f(x; w_u)) \big) \end{equation}\]학생 모델과 선생 모델의 거리는 다음 수식과 같이 KL-Divergence를 통해 표현할 수 있습니다. 해당 수식은 교사 모델과 학생 모델의 출력 확률 분포 간의 KL-Divergence를 측정한 것으로 KL-Divergence 값은 학생 모델의 가중치에 따라 변화하며 교사 모델의 가중치는 상수값입니다. 따라서 forget data에 대해서 학생 모델의 가중치는 교사 모델과의 KL-Divergence 값이 최대가 되도록 업데이트가 되며 retain data에 대해서는 교사 모델과의 KL-Divergence 값이 최소가 되도록 업데이트를 하게 됩니다.
SCRUB Training Process
최초에 학생 모델의 가중치를 교사 모델의 가중치로 초기화시킵니다.
\[\begin{equation} \min_{w^u} -\frac{1}{N_f} \sum_{x_f \in D_f} d(x_f; w^u) \end{equation}\]그 후 다음 수식과 같이 forget data에 대해 학생 모델과 선생 모델의 KL-Divergence가 최대가 되도록 학생 모델의 가중치를 업데이트합니다. 하지만 해당 수식만 존재하게 될 경우 retain data에 대한 성능이 감소할 수 있으므로 모델의 성능을 유지하기 위해 다음과 같은 추가적인 과정이 필요합니다.
\[\begin{equation} \min_{w_u} \frac{1}{N_r} \sum_{x_r \in D_r} d(x_r; w_u) + \lambda \frac{1}{N_r} \sum_{(x_r, y_r) \in D_r} l(f(x_r; w_u), y_r) - \alpha \frac{1}{N_f} \sum_{x_f \in D_f} d(x_f; w_u) \end{equation}\]해당 과정은 전 과정에서 retain data에 대해 교사 모델과 학생 모델의 KL-Divergence를 최소화하는 과정과 retain data에 대한 cross-entropy loss 즉 손실함수를 최소화하는 과정을 추가하여 모델의 성능을 유지하기 위한 단계입니다.
하지만 이 단계는 서로 다른 두 가지 목표가 상충하는 문제점으로 인해 학습 과정에서 손실값이 크게 진동(oscillation)하는 문제가 발생하게 됩니다. 해당 문제를 해결하기 위해 본 논문은 iterative alternative training 방식을 도입합니다. 총 3단계를 교대로 반복하여 앞서 발생했던 문제를 해결하며 모델의 성능을 유지하고자 합니다. 첫 번째 단계는 max-step으로 표현되며 forget data에 대한 업데이트, 두 번째 단계는 min-step으로 표현되며 retain data에 대한 업데이트를 수행합니다. 이때 min-step과 max-step의 반복으로 인해 retain data에 대한 성능이 저하될 위험이 있어 3단계인 추가적인 min-step을 수행하여 retain-data에 대한 성능을 복구하는 과정을 포함합니다.
SCRUB + Rewind
Rewind라는 추가적인 과정이 필요한 이유는 forget data에 대한 너무 높은 언러닝 성능은 멤버십 추론 공격에 취약해질 수 있기 때문입니다. 따라서 프라이버시 보호라는 목적을 달성하기 위해서는 rewind라는 과정을 통해 forget error를 약화시킬 필요가 있습니다. Rewind의 핵심 개념은 적당한 수준의 언러닝 성능을 유지하는 것입니다.
Rewind는 forget data에 대한 에러 값을 포함하고 있는 특정 체크포인트를 설정한 후 설정한 에러보다 높은 에러가 발생하게 되는 경우 설정했던 체크포인트로 돌아가는 방법을 의미합니다. Rewind의 과정은 다음과 같습니다.
첫 번째로 forget data와 같은 분포를 가지고 있는 검증 데이터를 생성합니다. 예를 들어 forget data의 클래스가 전부 0이라면 검증 데이터 역시 데이터의 클래스가 모두 0이어야 합니다. 검증 데이터를 생성한 후 SCRUB를 통해 훈련하며 각 에포크마다 forget data의 에러 값을 포함하고 있는 체크포인트를 저장합니다. 다음 사용자가 허용 가능한 에러 값을 설정한 후 해당 단계에 해당되는 체크포인트의 모델에 검증 데이터를 input으로 하여 에러 값을 측정하고 이 에러 값을 reference point 즉, 한계점으로 설정합니다. 만약 훈련 중 reference point보다 높은 에러 값이 측정된다면 reference point에 가장 가까운 체크포인트로 rewind하는 것이 최종 단계입니다.
Experiment
Scenario & Setting
해당 논문은 세 가지 시나리오를 토대로 SCRUB의 성능을 평가하고 있습니다. 첫 번째 시나리오는 편향된 데이터를 제거하는 것이 목표인 시나리오입니다. 해당 시나리오는 forget data에 대해서 최대한 가장 높은 에러를 달성하는 것이 목표입니다. 두 번째 시나리오는 잘못된 레이블이 할당된 데이터를 제거하는 것이 목표인 시나리오입니다. 해당 시나리오도 첫 번째와 마찬가지로 forget data에 대해서 최대한 가장 높은 에러를 달성하는 것이 목표입니다. 마지막 시나리오는 프라이버시 보호가 목표인 시나리오이며 앞 두 시나리오와 다르게 멤버십 추론 공격에 취약하지 않은 적당한 수준의 에러를 달성하는 것이 목표입니다. 즉 공격자가 forget data에 속한 예제와 전혀 새로운 데이터를 구별하지 못하는 수준까지 언러닝하는 것이 목표입니다. 해당 논문은 지금까지 발표되었던 논문과 다르게 small-scale을 가정하지 않고 small-scale과 large-scale 상황을 모두 실험하였습니다.
Results
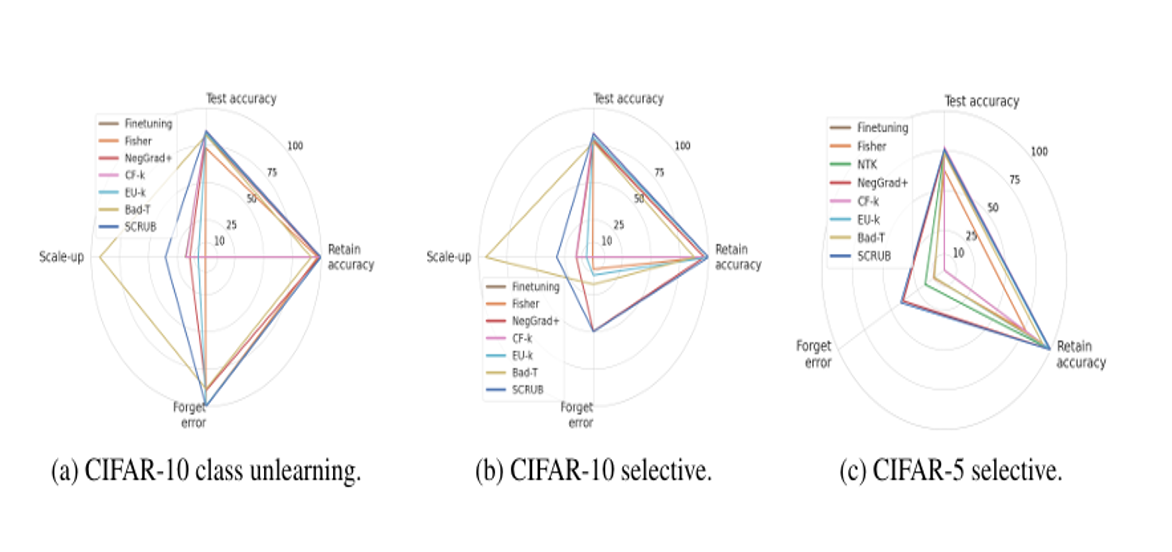
해당 그래프를 통해 SCRUB가 지금까지 연구되었던 다른 모델들에 비해 편향된 데이터를 제거하는 상황에서 가장 모델의 성능을 가장 잘 유지하는 것을 확인할 수 있습니다.
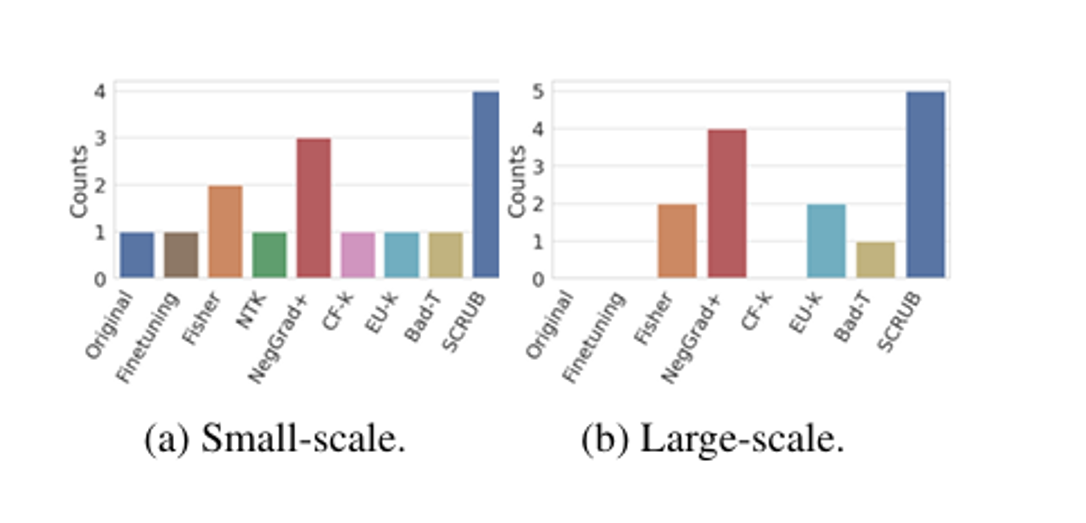
또한 다음 그래프를 통해 SCRUB가 다양한 상황, 가정 속에서 가장 높은 forget quality를 보이고 있습니다. 두 가지 그래프를 통해 SCRUB가 모델의 성능과 언러닝의 관점에서 가장 좋은 성능을 보이고 있습니다. 하지만 NegGrad+ 역시 좋은 성능을 보이고 있다는 것을 알 수 있고 NegGrad+가 SCRUB보다 적은 계산 비용을 필요로 하기 때문에 이에 대한 사용자의 결정이 필요할 것으로 보입니다.
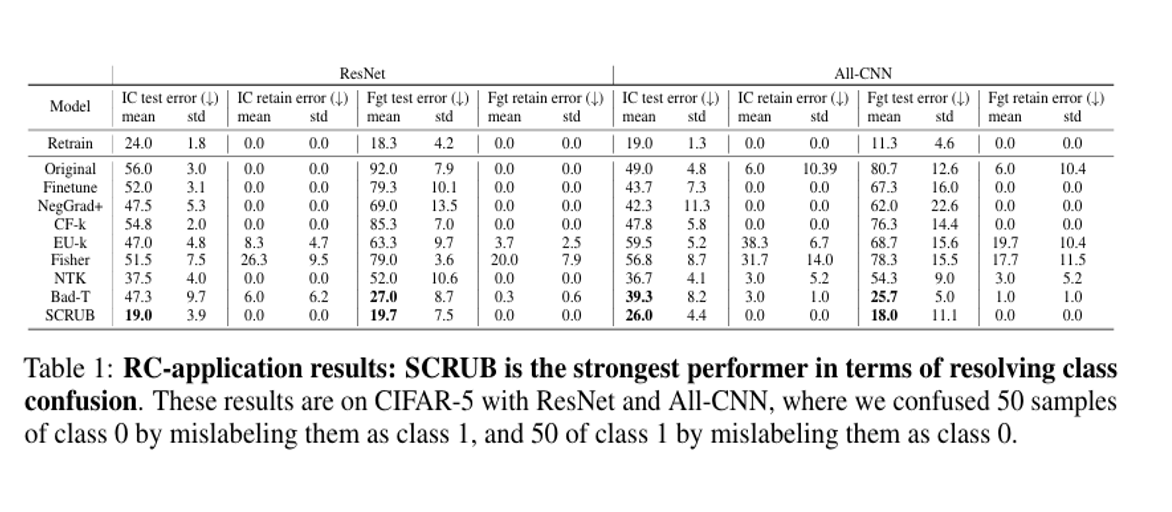
다음은 SCRUB가 잘못된 레이블에 대한 언러닝 실험입니다. 실험에 사용된 IC-ERR 지표는 혼동된 두 클래스의 예제가 다른 클래스로 잘못 분류된 횟수를 측정한 지표이며 FGT-ERR 지표는 혼동된 두 클래스 간의 직접적인 오분류를 측정한 지표입니다. 따라서 두 값 모두 낮을수록 모델의 성능이 좋다는 의미이며 다음 실험을 통해서 SCRUB가 잘못된 레이블이 할당된 데이터를 언러닝 한 후 모델의 성능을 가장 잘 유지하는 것을 알 수 있습니다.
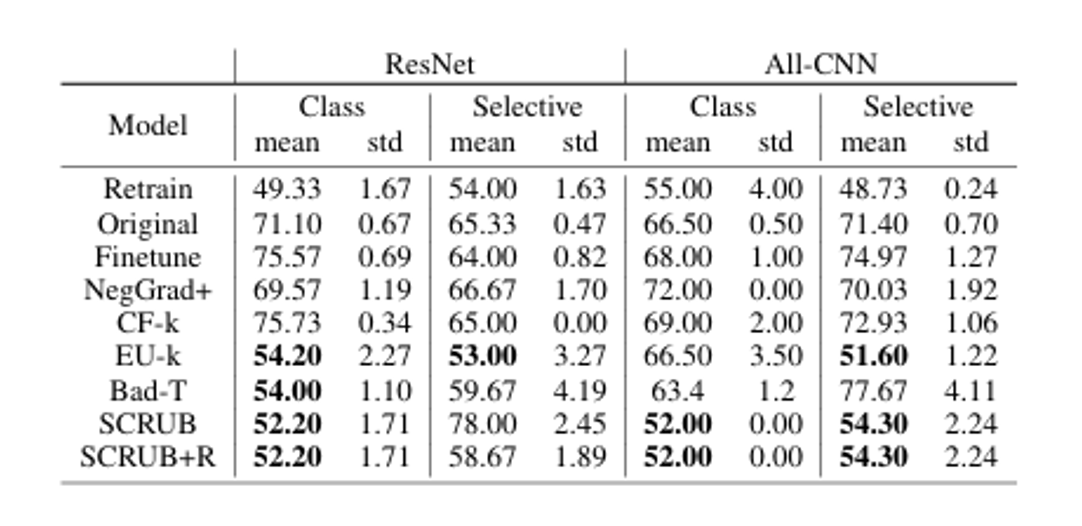
다음 SCRUB가 프라이버시 보호에 대한 언러닝 실험입니다. 다음 표를 볼 수 있듯이 SCRUB는 retrain과 멤버십 추론 공격에 대한 방어 측면에서 가장 유사한 성능을 보이고 있으며 Rewind를 추가하게 될 경우 selective unlearning에서 유의미한 방어 성능의 차이를 보이고 있습니다. 하지만 해당 표의 경우 selective unlearning 경우를 제외하고 나머지 상황에서 Rewind를 추가한다고 해서 유의미한 성과가 보이지 않아 계산 비용의 측면에서 유리하다고 보기 어렵습니다.
결론
본 논문은 SCRUB를 통해서 다양한 상황 및 언러닝의 목적에 따라 일정한 성능을 보일 수 있다는 것을 강조합니다. 교사-선생 프레임워크로 forget data에 대해서는 두 모델의 차이를 극대화시키고 retain data에 대해서는 두 모델의 차이를 최소화하여 모델의 성능과 forget quality를 모두 높은 수준으로 유지합니다. 또한 너무 높은 forget error는 프라이버시 측면에서 멤버십 추론 공격에 취약하게 되므로 rewind의 과정을 통해 완화시키고자 합니다. 하지만 SCRUB는 높은 계산 비용이 들며 사용자가 직접 결정해야 하는 하이퍼파라미터가 많은 측면에서 단점도 존재하며 SCRUB과 비슷한 성능을 보이며 낮은 계산 비용이 드는 NegGrad+가 더 유리할 수 있다라는 부분도 추가적으로 생각해야하는 부분입니다.