논문명: Stealing Machine Learning Models via Prediction APIs
저자: Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
게재지: USENIX Security Symposium, Austin, TX, USA, 2016.
서론
Machine Learning as a service(이하 ML-as-a-service, MLaaS)가 부상하며, 내부에서 보호받던 머신 러닝 모델들이 이제는 API를 통해 외부와 상호작용할 수 있게 되었습니다. 모델 소유자가 모델 질의(query)를 다른 사용자에게 유료로 제공하는 새로운 수익 모델의 등장에 따라 모델 추출(model extraction)이라는 새로운 위협이 대두되었습니다.
아래와 같은 구조로 공격자는 머신 러닝 모델에 대한 질의를 통해 모델을 추출해 낼 수 있습니다:
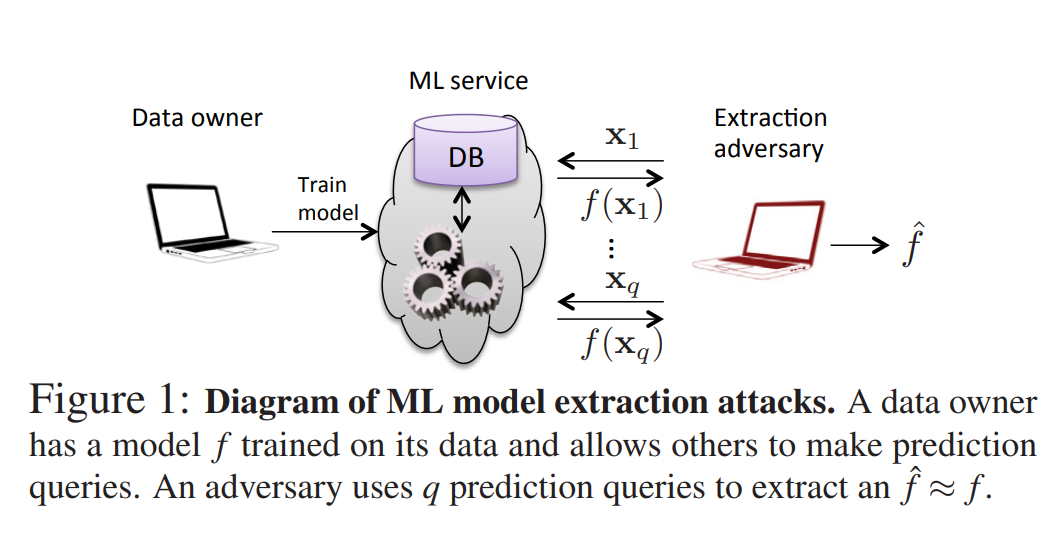
본 논문은 다양한 모델 유형에 대한 모델 추출 공격 기법을 제안하고, 이러한 공격이 실제 서비스에 적용 가능한지와 그에 대한 방어책을 함께 고찰합니다.
결정트리, 로지스틱 회귀, 심층 신경망, SVM(Support-Vector Machine) 등을 포함한 다양한 모델 환경 및 Amazon, BigML 등의 MLaaS 제공 업체에 대한 모델 추출 공격을 시연하며, 대부분의 경우에서, 목표 모델(target model)과 기능적으로 유사한 모델을 생성할 수 있었습니다.
사전지식
본 논문에서 입력에 대한 클래스(class)의 확률을 비교할 때는 총 변동 거리(total variation distance)를 사용합니다:
\[\begin{align} d(y,y') = \frac1 2 \sum\vert y[i]-y'[i]\vert \end{align}\]그리고 실험의 평가 지표는 다음과 같이 정의합니다:
\[\begin{align} R_{\text{test}}(f, \hat{f}) = \frac{1}{|D|} \sum_{(x, y) \in D} d(f(x), \hat{f}(x)), \quad \text{where } D \text{ is the test set}.\\ R_{\text{unif}}(f, \hat{f}) = \frac{1}{|U|} \sum_{x \in U} d(f(x), \hat{f}(x)), \quad \text{where } U \text{ is a set of uniformly sampled inputs from } \mathcal{X}. \end{align}\]각 지표는 목표 모델(target model)과 추출 모델(extracted model)에 대하여 테스트 데이터의 일치도와 전체 공간의 정확도를 평가합니다.
모델에 사용되는 시그모이드(sigmoid) 함수와 소프트맥스(softmax) 함수는 다음과 같이 정의됩니다:
\[\begin{align} \sigma(t) = \frac1 {1+e^t}\quad softmax(z_i)=\frac{e^{z_i}} {\sum_j e^{z_i}} \end{align}\]One-vs-Rest(OvR)는 다중 클래스 분류 문제에서 사용되는 전략 중 하나로, 이진 분류기를 여러 개 조합하는 방법입니다. OvR은 다중 클래스 분류 모델에서 소프트맥스를 사용하는 모델과 구분됩니다.
OvR 방식에서는 총 c개의 클래스가 있을 때, 각 클래스마다 다음과 같은 이진 분류 문제를 정의합니다:
- 해당 클래스 vs. 나머지 모든 클래스 → 즉, 클래스 3에 대해 “이 샘플은 클래스 3인가, 아닌가?”를 판단하는 이진 분류기를 학습합니다.
총 c개의 이진 분류기를 학습하게 되며, 예측 시에는 각 분류기에서 얻은 출력값 중 가장 높은 값을 반환하는 클래스를 최종 예측으로 선택합니다.
비선형 활성화 함수인 ReLU(Rectified Linear Unit) 와 tanh(hyperbolic tangent)함수의 개형은 다음과 같습니다:
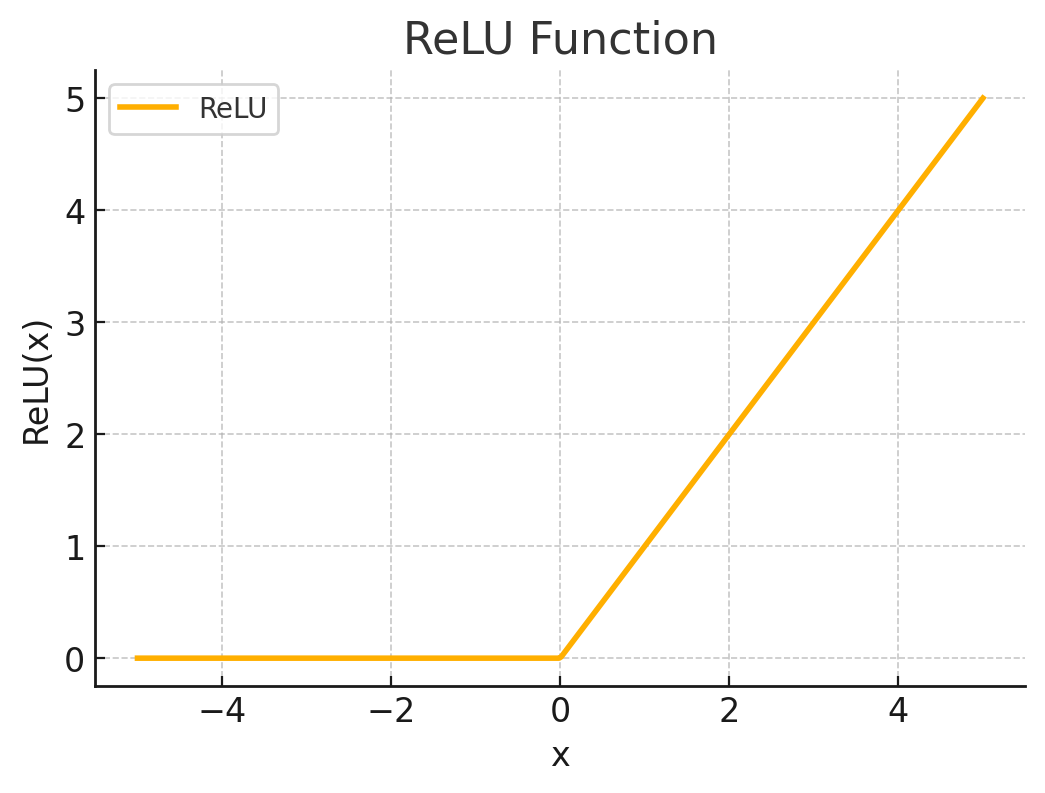
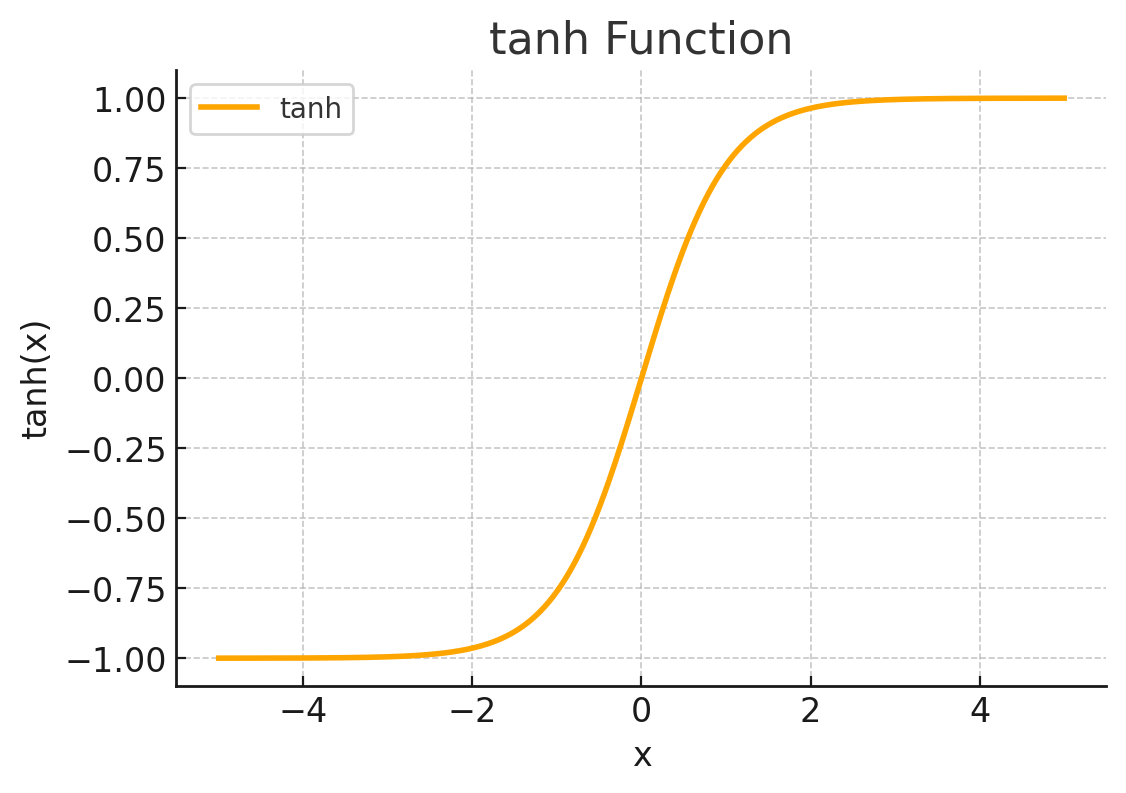
본론
Equation Solving Attack
Equation Solving Attack은 목표 모델의 출력 확률값을 활용해, 목표 모델 내부의 가중치(weight)와 편향(bias) 등 매개변수(parameter)를 직접 계산하려는 모델 추출 기법입니다. 이는 이진 로지스틱 회귀 모델, 다중 분류 로직스틱 회귀 모델, 다층 퍼셉트론 모델에 적용할 수 있습니다.
-
이진 로지스틱 회귀(Binary Logistic Regression, BLR) 모델
BLR 모델은 일반적으로 다음과 같이 정의됩니다:
\[\begin{align} f(x) = \sigma(w^\top x + \beta), \quad w \in \mathbb{R}^d,\ x \in \mathbb{R}^d,\ \beta \in \mathbb{R} \end{align}\]그리고 출력값으로 부터 다음과 같은 식을 유도할 수 있습니다:
\[\begin{align} \sum_{j=1}^{d} w_j x_j + \beta = \sigma^{-1}(f(x)) = \log\left( \frac{f(x)}{1 - f(x)} \right) \end{align}\]이 식으로부터 가중치와 편향값을 복원하려면 다음 조건이 필요합니다:
\[\begin{align} \text{Unknowns: } w \in \mathbb{R}^d,\ \beta \in \mathbb{R} \Rightarrow (d + 1)\ \text{unknowns} \end{align}\] \[\begin{align} \text{Need } (d + 1)\ \text{linearly independent inputs } x_{(1)},\dots,x_{(d+1)} \end{align}\]각 샘플 x_i 로부터 아래와 같은 선형방정식을 얻습니다:
\[\begin{align} \sum_{j=1}^{d} w_j x^{(i)}_j + \beta = \log\left( \frac{f(x^{(i)})}{1 - f(x^{(i)})} \right) \end{align}\]위 d+1개의 식을 아래와 같이 연립하여 풀면 가중치와 편향 값을 정확히 복원할 수 있습니다:
\[\begin{align} \sum_{j=1}^{d} w_j x^{(1)}_j + \beta = \log\left( \frac{f(x^{(1)})}{1 - f(x^{(1)})} \right) \\\\ \sum_{j=1}^{d} w_j x^{(2)}_j + \beta = \log\left( \frac{f(x^{(2)})}{1 - f(x^{(2)})} \right) \\\\ \vdots \\\\ \sum_{j=1}^{d} w_j x^{(d+1)}_j + \beta = \log\left( \frac{f(x^{(d+1)})}{1 - f(x^{(d+1)})} \right) \end{align}\] -
다중 분류 로지스틱 회귀(Multiclass Logistic Regression, MLR) 모델
- MLR 모델은 일반적으로 다음과 같이 정의됩니다:
MLR 모델은 소프트맥스 함수를 사용하므로, 비선형 방정식 시스템을 형성하게 됩니다. 따라서 BLR 모델처럼 해석적으로 가중치와 편향을 구하는 것이 불가능합니다.
이러한 비선형 방정식 시스템에 대해서는 손실 함수(Loss Function)을 최소화하여 목표 모델 f와 유사한 예측을 하는 추출 모델을 구성할 수 있습니다. 일반적으로 다중 분류 모델에서 사용할 수 있는 Cross-Entropy Loss 손실 함수는 다음과 같습니다:
\[\begin{align} \mathcal{L}(W, \beta) = - \sum_{k=1}^{n} \sum_{i=1}^{c} f_i(x^{(k)}) \cdot \log \hat{f}_i(x^{(k)}) \end{align}\]여기에 정규화 항 (예: L2)을 추가하면, 전체 손실 함수가 strongly convex가 되어 global minimum을 갖게 됩니다.
이 때의 추출 모델은 모든 가능한 입력 샘플에 대해 목표 모델과 동일한 출력(소프트맥스 확률)을 가질 수 있지만, 내부적으로는 매개변수가 목표 모델과 정확히 같다는 것을 보장하지는 않으며, 결국 동작이 동일한 근사 모델이라고 볼 수 있습니다.
-
다층 퍼셉트론(Multi-Layer Perceptron, MLP) 모델
MLP 모델은 앞선 모델들과 다르게 은닉층이 추가되며 비선형 활성화함수(예를 들어 ReLU, tanh 등)가 적용되는 모델입니다. 따라서 모델이 상대적으로 복잡하고 매개변수가 많으며, 비선형 모델이기 때문에 정규화 항을 추가하여도 손실 함수의 stronly convex를 보장할 수 없습니다.
MLR 모델에 대한 Equation Solving Attack은 앞선 MLR과 같은 방식으로 진행할 수 있으나, 더 많은 질의 요청을 필요로 합니다. 또한 추출 모델이 완전히 동일하게 동작하는 것을 보장할 수는 없습니다.
- 실험 결과
아래 테이블은 논문에서 실시한 equation solving attack의 결과를 나타냅니다:
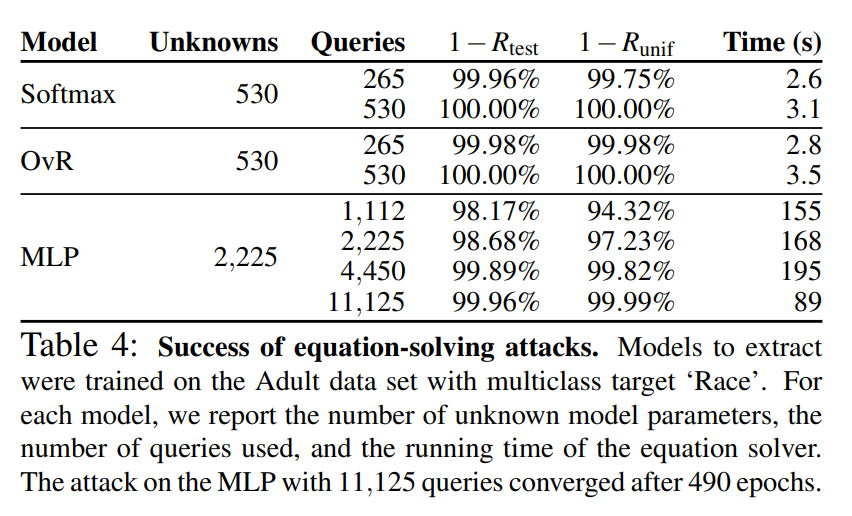
학습에 사용된 데이터는 인종으로 구분되는 성인의 데이터입니다.
MLR 모델은 논문에서 주로 설명한 소프트맥스 모델 OvR모델을 사용하였습니다. 530개의 매개변수를 가진 모델들에 대하여 265번의 질의로 거의 유사한 모델을 추출하는데에 성공하였으며, 530번의 질의로 기능적으로 완전히 동일한 모델을 추출할 수 있었습니다.
MLP 모델은 더 많은 매개변수를 가지고 있으며 더 많은 질의와 시간을 필요로 했지만 역시 거의 유사한 모델을 추출할 수 있었습니다.
Decision Tree Path Finding Attack
Decision Tree Path Finding Attack은 조건부 분기(branch condition)에 따라 예측 결과를 제공하는 결정 트리(Decision Tree)의 경로를 역추적하여 전체 트리를 재구성하는 모델 추출 기법입니다.
결정 트리는 각 내부 노드에서 특정 특징 x에 대해 임계값을 기준으로 분기합니다. 간단한 예시로 다음과 같은 분기 기준이 있습니다:
\[\begin{align} x_i<θ \text{ ⇒왼쪽 자식 노드,}\quad x_i≥θ \text{ ⇒오른쪽 자식 노드} \end{align}\]아래 도식은 간단한 결정 트리의 예시입니다:
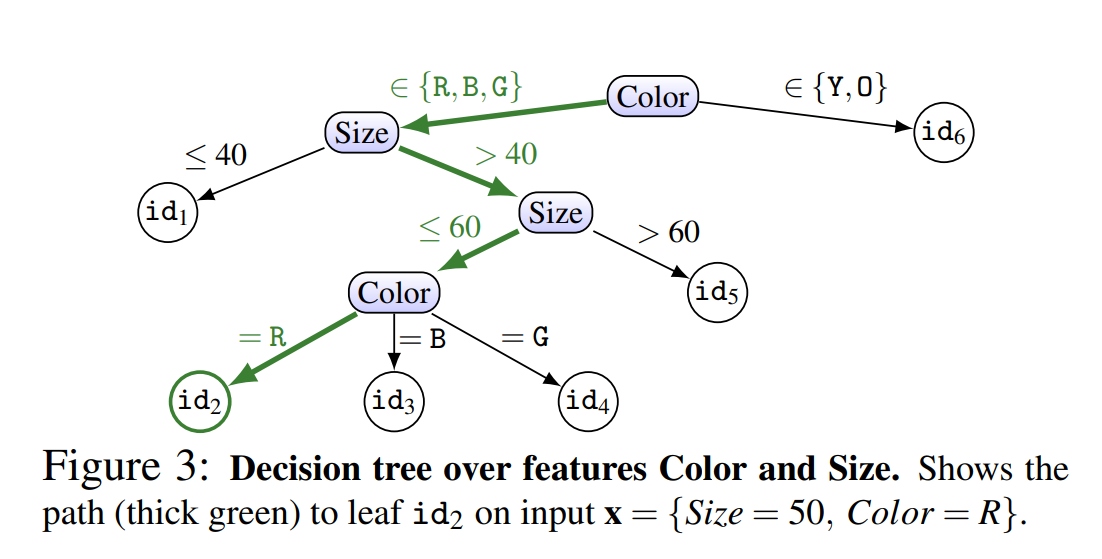
논문에서 제안하는 방식은 path-finding algorithm에 기반한 path-finding과 top-down approach 두가지 입니다.
-
경로 분석(Path Finding): 경로 분석의 목표는 각 리프 노드에 도달하는 입력 조건을 찾는 것입니다.
- 입력 x의 한 특징을 변화시키며 모델의 출력 변화를 탐색합니다.
- 출력이 바뀌는 지점을 기준으로 분할 조건을 추정합니다.
이 기법의 기반이 되는 알고리즘은 다음과 같습니다:

위 알고리즘에서는 입력의 각 특징 별 분기 조건을 탐색하여 트리를 재구성하고 있습니다.
-
A top-down approach: Top-down approach에서는 트리의 깊이와 분기 수를 탐색하여 모든 경로를 파악합니다.
- 모든 특징을 미지정으로 설정한 빈 입력을 질의하여 루트 노드의 ID를 확인합니다.
- 다음으로 모든 특징을 하나씩만 설정한 입력을 만들어 루트에 어떤 특징이 영향을 주는지 확인합니다.
- 분기 기준이 되는 특징에 대해서 경계 값을 탐색해 노드의 분기 기준을 추정합니다.
- 하위 노드에 대해 재귀적으로 반복하여 트리를 재구성합니다.
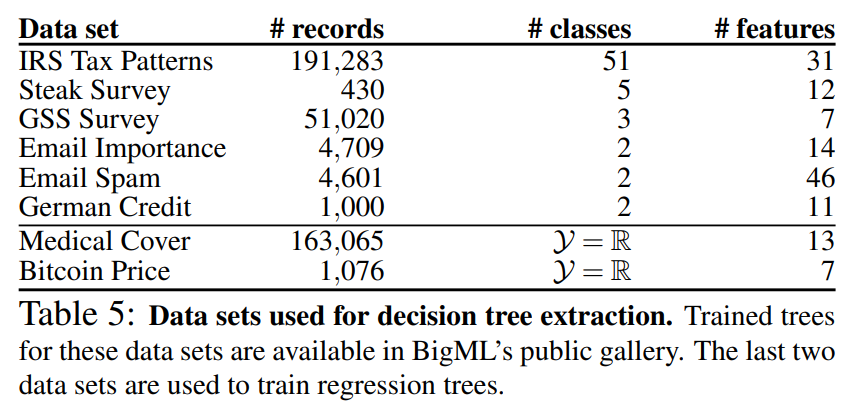
아래는 실험에서 사용된 결정트리의 학습 데이터입니다. BigML에서 사용할 수 있는 데이터이며 각 데이터의 행, 클래스, 특징의 갯수가 명시되어있습니다:
아래 테이블은 논문에서 실시한 결정 트리 모델 추출 공격 결과를 나타냅니다:
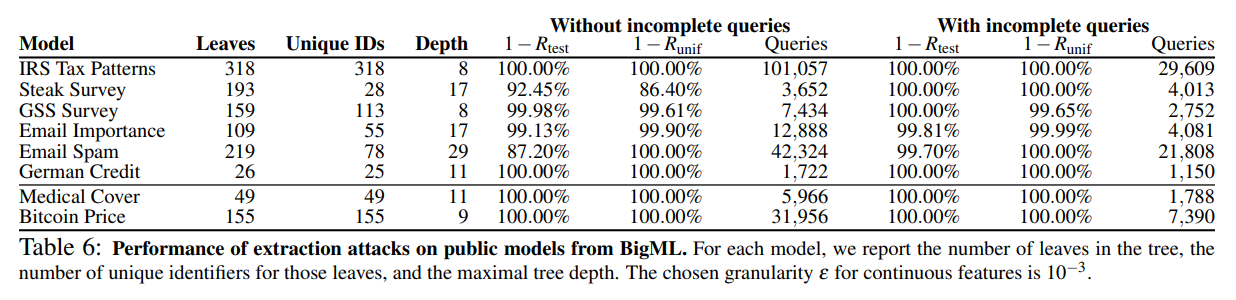
공격 결과, 불완전한 입력을 질의하는(With incomplete queries) Top-down approach가 대체적으로 적은 질의 횟수와 높은 정확도를 달성하였습니다.
The Lowd-Meek attack
Lowd, Meek. 2005에서 제안된 Lowd-Meek attack은 단순히 클래스 라벨만 제공되는 환경에서 모델을 추출할 수 있도록 고안된 경계 기반 모델 추출(boundary-based model extraction) 기법 입니다.
모델은 결정 경계를 기준으로 두 클래스를 분리합니다. 공격자는 출력 클래스가 다른 임의의 점 쌍 (x1, x2)에 대하여 이분 탐색을 통해 그 지점을 좁혀나가며 결정 경계를 추정합니다. 이렇게 수집한 데이터를 통해 모델의 파라미터를 재구성합니다.
간단한 예제는 다음과 같습니다:
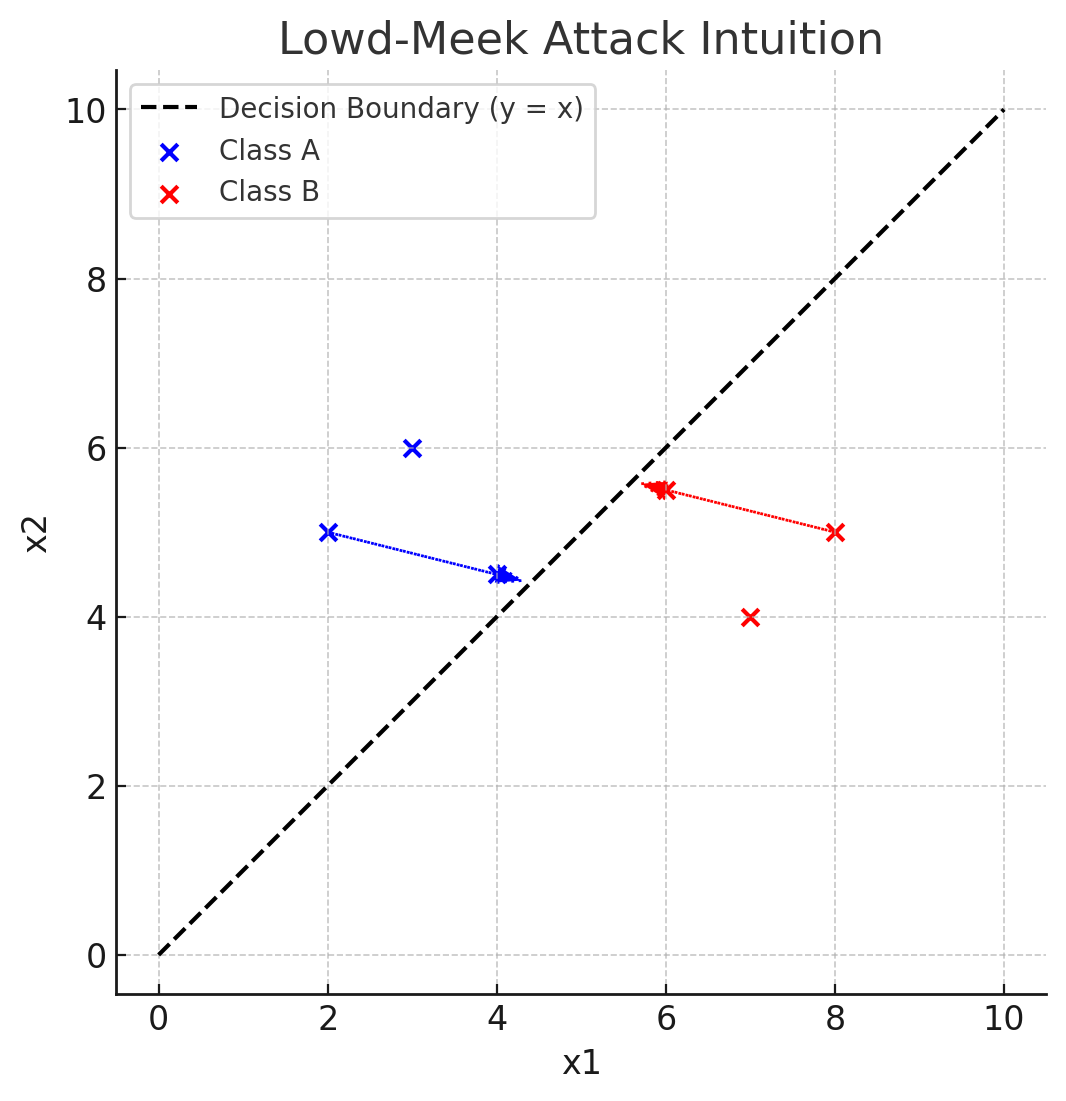
Retraining Attack
Retraining Attack은 공격자가 목표 모델의 출력을 활용해 추출 모델을 직접 학습하는 방식입니다. API가 출력하는 소프트맥스 확률값 또는 클래스 라벨을 학습 대상으로 삼아, 목표 모델과 기능적으로 유사한 모델을 추출합니다.
Retraining 방식은 세 가지로 나뉩니다:
-
Uniform Retraining
- 입력 공간(pool) 내에서 무작위로 입력 x를 샘플링 후, oracle의 출력을 수집하여 추정 모델을 학습합니다.
-
Line-Search Retraining
- 목표 모델의 결정경계에 가까운 sample을 찾아 추출 모델을 훈련합니다.
-
Adaptive Retraining
- 무작위 샘플링 된 x에 대한 oracle의 출력을 바탕으로 추출 모델을 훈련합니다.
- 이후 추출 모델의 결정 경계 근처에 위치한 새로운 points를 바탕으로 다시 목표 모델에 질의 합니다.
- 이 결과를 바탕으로 추출 모델을 재학습합니다.
아래는 각 방식과 Lowd-Meek attack에 대한 실험 결과입니다:
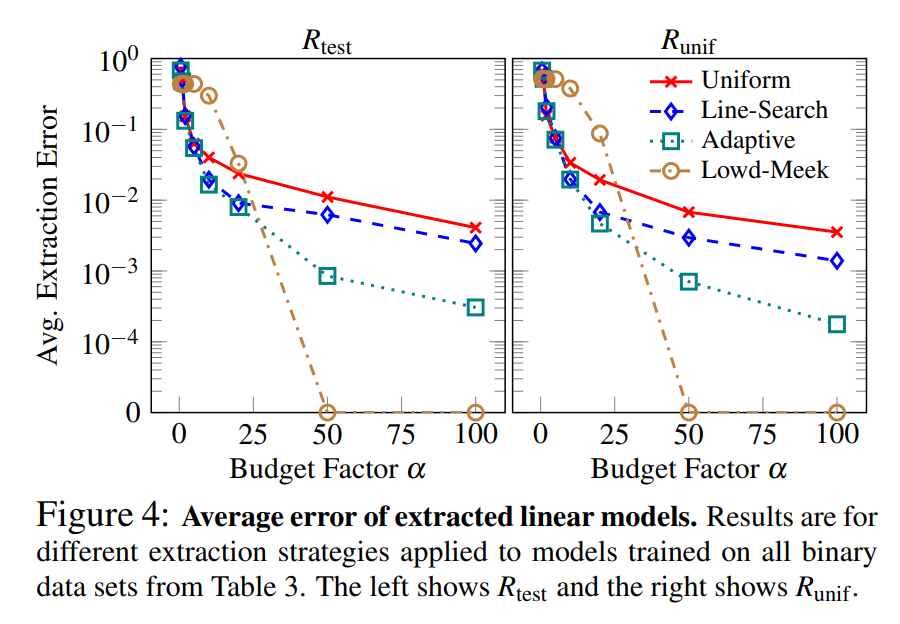
선형 모델에 대해서는 Uniform Retraining보다 결정경계 근처의 점을 찾는 Line-Search Retraining이 명확하게 우수한 성능을 보였으며, Adaptive Retraining이 세가지 방식중 가장 효율적이었습니다.
Lowd-Meek attack은 충분한 질의 요청이 가능할 때에는 높은 성능을 보여주었습니다.
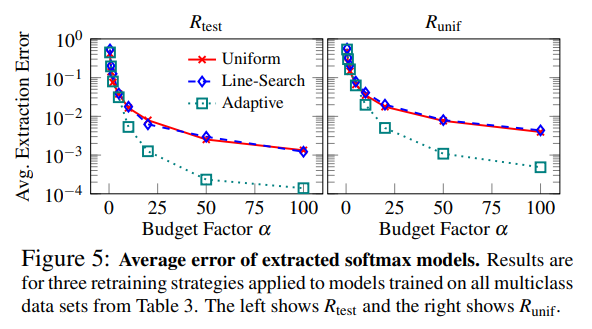
소프트맥스 모델의 경우, Adaptive Retraining은 다른 방식보다 높은 성능을 보였으며, Uniform 및 Line-Search 방식 간에는 큰 성능 차이가 관찰되지 않았습니다.
Kernel Support-vertor machines(kernel SVM)은 입력받은 데이터를 고차원 공간으로 매핑한 후, 각 클래스를 최대한 분리하는 초평면을 찾습니다. 다항식 커널을 갖춘 SVM은 Lowd-Meek 공격을 통해 모델 추출을 시도할 수 있지만, 라디얼 기반 함수 (radial-basis function) 커널의 경우에는 변환된 공간이 무한 차원이기 때문에 적용할 수 없습니다. 또한 SVM은 정확도 점수를 제공하지 않기 때문에 적용가능한 유일한 공격 기법은 retraining 뿐입니다.
라디얼 기반 함수 커널을 갖춘 SVM에 대한 실험 결과는 다음과 같습니다:
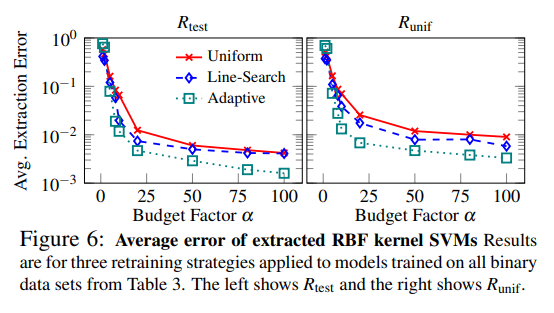
Adaptive retraining이 가장 효율적임을 확인할 수 있었으며 허용가능한 질의 요청 횟수 내에서 99% 이상의 정확도를 가진 모델을 추출할 수 있었습니다.
Model Inversion Attack
Model Inversion Attack은 모델로부터 특정 클래스의 특징을 복원하는 공격입니다.
최적의 샘플 x는 다음과 같은 수식으로 표현됩니다. \(x_{opt} = argmax_{x∈X}f_i(x)\) 위 표현을 바탕으로 임의의 샘플 x에 대하여 특정 클래스에 속할 확률이 최대가 되는 입력을 찾습니다. 이 때는 모델의 확률 점수가 가장 높아지는 입력을 경사 상승법을 통해 찾게 됩니다.
Fredrikson et al. 2015에서 제안되었던 Model Inversion Attack은 목표 모델이 얼굴 인식 모델일 때, 훈련에 사용된 데이터 구성원의 얼굴을 인식 가능한 이미지로 복원할 수 있음을 보여주었습니다.
이는 목표 모델과 매개변수를 알고있는 white-box 환경에서는 잘 동작하였습니다. 반면 그렇지 않은 black-box 환경에서는 성공적이었지만 더욱 많은 질의 요청을 필요로 하며 상대적으로 효율성이 떨어졌습니다.
따라서 본 논문에서는 앞선 공격들을 바탕으로 하는 모델 추출과, 추출 모델을 활용한 white-box 환경 inversion attack을 결합하는 방법을 제시하였습니다.
Training Data Leakage for Kernal Logistic Regression
커널 기반 로지스틱 회귀(Kernal Logistic Regression, KLR)는 입력 데이터를 고차원 특성 공간으로 매핑한 후 선형 모델을 학습하는 모델입니다.
KLR 모델은 소프트맥스 모델로, 기존 선형구조를 다음과 같이 매핑으로 대체하여 입력 샘플과 훈련 샘플 간의 유사도를 활용해 출력을 계산합니다:
\[\begin{align} w_i·x + \beta_i ⇒ ∑_{r=1}^{s} α_{i,r}⋅K(x,x_r)+β_i\\ ~이때,~K(x,x_r)는~\text{커널 함수,}\quad x_r\text{는 클래스에 대한 대표 샘플} \end{align}\]그리고 모델의 출력은 다음과 같이 정의됩니다:
\[\begin{align} f_i(x)= \frac{exp(∑_{r=1}^s α_{i,r}K(x,x_r)+β_j)} {\sum _{j=1}^c exp(∑_{r=1}^sα_{j,r}K(x,x_r)+\beta_i)} \end{align}\]공격자가 목표 모델의 소프트맥스 출력을 사용할 수 있다면, 각 질의 x에 대해 다음과 같은 식을 구성할 수 있습니다:
\[\begin{align} ∑_{r=1}^{s} α_{i,r}⋅K(x,x_r)+β_i=σ^{−1}(f(x)) \end{align}\]공격자는 목표 모델로부터 획득한 각 샘플 (x,f(x))을 사용해 매개변수와 대표 샘플에 대한 c개의 비선형 방정식을 얻게됩니다. 이 방정식 시스템을 풀음으로써 모델 파라미터 뿐만 아니라 실제 훈련 데이터 x_r을 복원할 수 있게 됩니다.
Countermesure
공격에서 더 나아가 이를 방어하기 위한 대응법을 연구할 필요가 있습니다.
앞선 공격 기법들은 기본적으로 더 적은 정보를 제공할 수록 공격이 어려워지고 더 많은 질의 요청을 필요로 합니다. 하지만 제한된 정보 제공은 동시에 모델의 실용성과 활용 가능성을 저하시킬 수 있습니다. 따라서 방어 효과와 모델 유용성 간의 균형을 고려하여, 적절한 정보 제공 수준을 탐색하는 것이 중요합니다.
본 논문에서는 대응법으로 rounding confidence와 Differential privacy, Ensemble methods를 제안하고있습니다.
-
Rounding confidences
예측 모델을 활용한 응용 프로그램은 신뢰도가 필요할 수 있지만, 일반적으로 낮은 세부 수준을 필요로 합니다. 따라서 가능한 방어책은 신뢰도 점수를 특정 고정 정밀도로 반올림하는 것입니다.
이를 통해 equation solving attack의 결과로 정확한 해가 아닌 목표모델의 잘린 부분(truncated version)에 해당하는 해를 얻게될 수 있습니다. 결정트리에 대한 공격에서는 노드ID의 충돌 가능성이 증가하며, 공격의 성공률이 감소하게 됩니다.
아래는 소프트맥스 모델에 대한 반올림 적용 결과입니다:
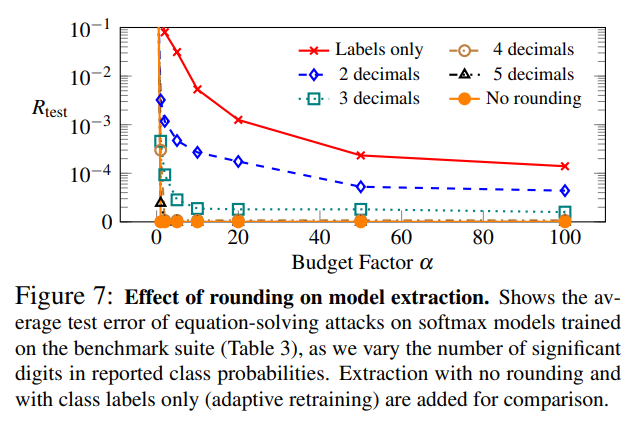
소프트맥스 모델들에 대한 공격 결과에서도 출력 값을 소수점 이하 2~3자리로 반올림할 경우 공격 효율이 약화된 것을 확인할 수 있었습니다
-
Differential privacy
Springer et al. 2006에서 제안된 Differential privacy(DP)란 개별 데이터 항목이 포함되었는지 여부에 관계없이 통계적 분석 결과가 거의 동일하게 나오는 것을 보장하는 개인정보 보호 프레임워크입니다. 일반적으로 DP의 적용 대상은 훈련 데이터입니다. 그러나 훈련 데이터에 DP를 적용하는 것으로는 모델 추출 공격을 막을 수는 없습니다.
따라서 본 논문에서는 모델의 매개변수에 DP를 직접 적용하는 것이 적절한 전략이 될 것이라고 제안하며, 구체적인 작동이나 구현 방법에 대해서는 향후 연구 과제로 남기고 있습니다.
-
Ensemble methods
Random forests와 같은 Ensemble methods는 여러 개별 모델의 예측을 기반으로 예측이 이루어집니다. 본 논문에서는 이 방법을 목표로 공격을 실험해보지는 않았지만, 모델 추출 공격에 대해 더욱 탄력적일 수 있다고 추정합니다. 공격자는 목표 모델의 부정확한(coarse) 근사치만을 얻을 수 있을 것입니다. 하지만 model evasion과 같은 공격에는 역시 취약할 수 있음을 남겼습니다.
결론
본 논문에서는 아마존, BigML과 같은 MLaaS 제공 업체가 제공하는 머신러닝 기반 예측 API가 모델 추출 공격에 취약할 수 있음을 언급하며, 이는 모델의 수익화 방해와 훈련 데이터 침해, 모델 회피를 용이하게 할 수 있음을 보여주었습니다.
그리고 로컬 환경에서의 실험과 업체를 대상으로하는 온라인 공격을 통해 공격의 적용 가능성과 효율성을 시연하였습니다.
모델 추출 공격 방법으로 로지스틱 출력층을 가진 모델(BLR 모델, MLP 모델 등)에 대한 equation solving attack, 결정 트리 모델에 대한 path finding attack을 제시하였으며, 기존 연구(Lowd-Meek attack, Activce learning 등)를 바탕으로 재구성한 다양한 retraining 기법을 제안 후 각 공격 기법을 적용해보았습니다.
이러한 공격들에 대한 대응 조치를 추가로 탐구했으며, 가장 분명한 방법은 API가 제공하는 정보를 제한하는 것입니다.
마지막으로는 이러한 공격 및 대응 기법들을 실제 상용 머신러닝 서비스에 적용하여 평가하는 것이 후속 연구로 제안됩니다.