논문명: Adversarial Retain-free Unlearning for Bearing Prognostics and Health Management
저자: Chaewon Yoon, Jiyoung Lee, Hoki Kim
게재지: IEEE Transactions on Industrial Informatics
서론
제4차 산업혁명의 도래로 산업 현장에서 센서 데이터와 인공지능을 기반으로 한 PHM(Prognostics and Health Management) 기술이 적극적으로 사용되고 있습니다. 특히 베어링 결함 진단과 같은 핵심 설비 관리 분야에서 딥러닝 모델이 높은 정확도를 보이며 산업 경쟁력을 좌우하는 주요 기술로 자리 잡았습니다.
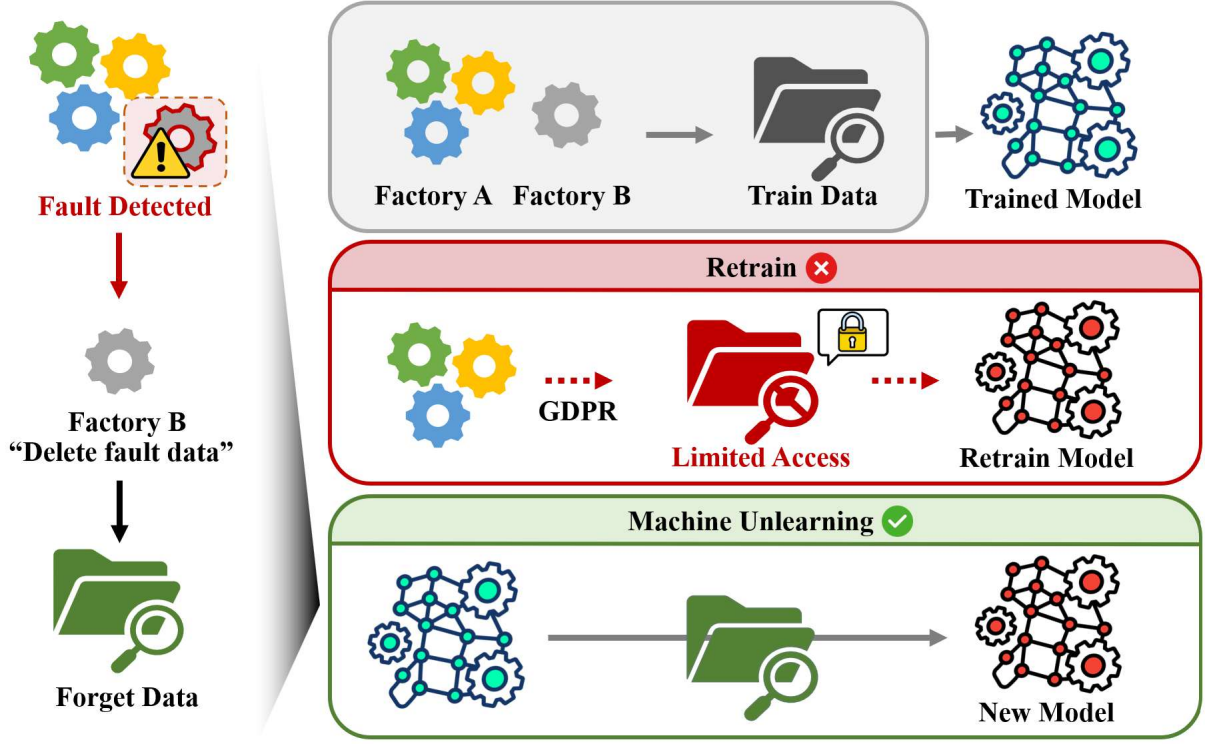
머신 언러닝(Machine Unlearning) 기술은 주요 데이터 법령인 GDPR에서 명시하는 “잊혀질 권리(Right To Be Forgotten)”처럼, 모델이 학습한 데이터 중 일부를 나중에 삭제해야 하는 상황에서 유용하게 쓰입니다.
본 연구실의 논문 “Adversarial Retain-free Unlearning for Bearing Prognostics and Health Management” [Paper]은 공정 환경의 현실적인 제약 조건을 고려해, 삭제 대상 데이터와 이미 학습된 모델만으로 머신 언러닝을 수행할 수 있는 새로운 프레임워크를 제안합니다.
이 글에서는 제조 공정 환경에서 기존 머신 언러닝 방식이 갖는 한계와 제안된 ARU 방법을 함께 살펴보겠습니다.
사전 지식
적대적 예제
적대적 예제(Adversarial Attack)는 특정 샘플에 적대적 공격으로 아주 작은 교란(\(\epsilon\))을 추가해 모델이 샘플을 완전히 다른 클래스로 분류하도록 유도합니다.
대표적인 적대적 공격 방법으로는 FGSM과 PGD가 있습니다 :
1. FGSM(Fast Gradient Sign Method) : 한 번의 gradient 계산으로 교란을 추가합니다.
\[\begin{equation} \delta = \epsilon \cdot \operatorname{sign} (\nabla_{x}\mathcal{L} (f_{\theta} (x)), y), \end{equation}\]2. PGD(Projected Gradient Descent) : FGSM을 여러 단계로 확장해 더 강력한 공격을 수행합니다.
\[\begin{equation} x^{t+1} = \Pi_{\lVert \delta \rVert_{\infty}\le \epsilon} \left (x^t + \alpha \cdot \operatorname{sign} (\nabla_{x^t}\mathcal{L} (f_{\theta} (x^t), y)) \right), \end{equation}\]머신 언러닝
모델이 학습한 전체 데이터를 \(\mathcal{D}\) 라고 할 때, 삭제 여부에 따라 데이터를 아래와 같이 두 가지로 나눌 수 있습니다 :
1. 삭제 대상 데이터 (Forget data) = \(\mathcal{D_F}\)
2. 유지 대상 데이터 (Retain data) = \(\mathcal{D_R}\)
머신 언러닝은 모델이 \(\mathcal{D_R}\)로만 학습한 모델을 이상적인 상태로 가정합니다. 이 글에서는 이러한 이상적인 학습 방법을 Retrain이라고 지칭합니다. 하지만 모델을 처음부터 재학습하는 Retrain은 시간, 비용적인 부담이 큽니다. 따라서 이미 학습된 모델을 특정 알고리즘으로 학습해 삭제 대상 데이터를 제거하는 머신 언러닝 기술이 필요합니다.
머신 언러닝은 모델이 \(\mathcal{D_F}\)의 정보를 잊는 동시에, \(\mathcal{D_R}\)의 정보를 유지하도록 유도해, Retrain 상태와 비슷해지는 것을 목표로 합니다.
retain-free 언러닝
기존 연구에서 제안된 retain-free 언러닝 방법론을 소개합니다. 모델의 가중치를 \(\theta\)라고 할 때, 각 방법은 다음과 같이 업데이트합니다 :
1. Gradient Ascent (GA) : \(\mathcal{D_F}\)에 대한 손실을 최대화해 언러닝합니다. \(\begin{equation} \theta \leftarrow \theta + \eta\cdot \nabla_{\theta} \mathcal{L} (f_{\theta} (x_f), y_f) \text{ where } (x_f, y_f) \in \mathcal{D_F} \end{equation}\)
2. Random Labeling (RL) : \(\mathcal{D_F}\) 샘플에 랜덤 라벨을 붙여 언러닝합니다. \(\begin{equation} \theta \leftarrow \theta - \eta \cdot \nabla_{\theta}\,\mathcal{L}\big(f_{\theta}(x_f), \tilde{y}\big) \end{equation}\)
3. Adversarial Machine UNlearning (AMUN) : \(\mathcal{D_F}\)에 최소한의 교란(\(\epsilon^{\star}\))을 가해 적대적 예제 \(\mathcal{D_A}\)를 얻고, \(\mathcal{D_F} \cup \mathcal{D_A}\)으로 모델(\(\theta\))을 재학습합니다.
적대적 예제 \(\mathcal{D_A} = (x_f^{adv}, y_f^{adv})\)는 다음과 같이 구성합니다 :
먼저 적대적 공격 알고리즘 \(A\)에 대해 \(\mathcal{D_F}\)를 오분류하는 최소 교란 크기인 \(\epsilon^{\star}\)를 구합니다. \(\begin{equation} \epsilon^\star = \min \{\epsilon : \arg\max_i f_{\theta} (A (x_f, \epsilon))_i \neq y_f \} \end{equation}\)
다음으로, 최소 교란 크기 \(\epsilon^{\star}\)를 적용한 적대적 예제인 \(\mathcal{D_A} = $(x_f^{adv}, y_f^{adv})\)를 구합니다. \(\begin{equation} x_f^{adv} = A(x_f, \epsilon^{star}), y_f^{adv} = arg \max_i f_{\theta}(x_f^{adv})_i \end{equation}\)
마지막으로 모델을 \(\mathcal{D_F}\cup\mathcal{D_A}\)로 재학습합니다. \(\begin{equation} \theta \leftarrow \theta - \eta \sum_{ (x,y)\in \mathcal{D_F} \cup \mathcal{D_A}} \nabla_{\theta}\mathcal{L} (f_{\theta} (x),y) \end{equation}\)
본론
기존 retain-free 언러닝 알고리즘은 모델의 구조를 심하게 무너뜨리는 경우가 많았습니다. 또한 공정 데이터로 실험 시 모델의 분류 능력 또한 저하되는 문제를 보였습니다.
본 논문은 전체 데이터에 대한 접근이 제한된 환경에서 기존 retain-free 언러닝 알고리즘의 모델 붕괴 문제를 정량화해 확인하고, 이를 해결하는 ARU 프레임워크를 제안합니다.
Adversarial Retain-free Unlearning (ARU)는 2가지 단계로 이루어집니다 :
1.적대적 예제 생성 : \(\mathcal{D_F}\)를 이용해 모델이 기억하는 범위 내에서 \(\mathcal{D_R}\)로 인지하는 적대적 예제 (\(\mathcal{\tilde{D}_R}\))를 생성합니다
2.모델 재학습 : 손실함수 \(\mathcal{l}_{\texttt{SDA}}\)를 이용해, 학습 데이터가 \(\mathcal{D_F}\)과는 멀어지도록, \(\mathcal{\tilde{D}_R}\)와는 가까워지도록 유도합니다
모델의 구조 정량화
본 논문은 Structural Similarity Correlation (SSC)를 통해 기존 연구된 retain-free 언러닝 방법들이 모델의 구조를 얼마나 보존하는지 정량화합니다.
SSC는 다음과 같은 절차로 계산됩니다 :
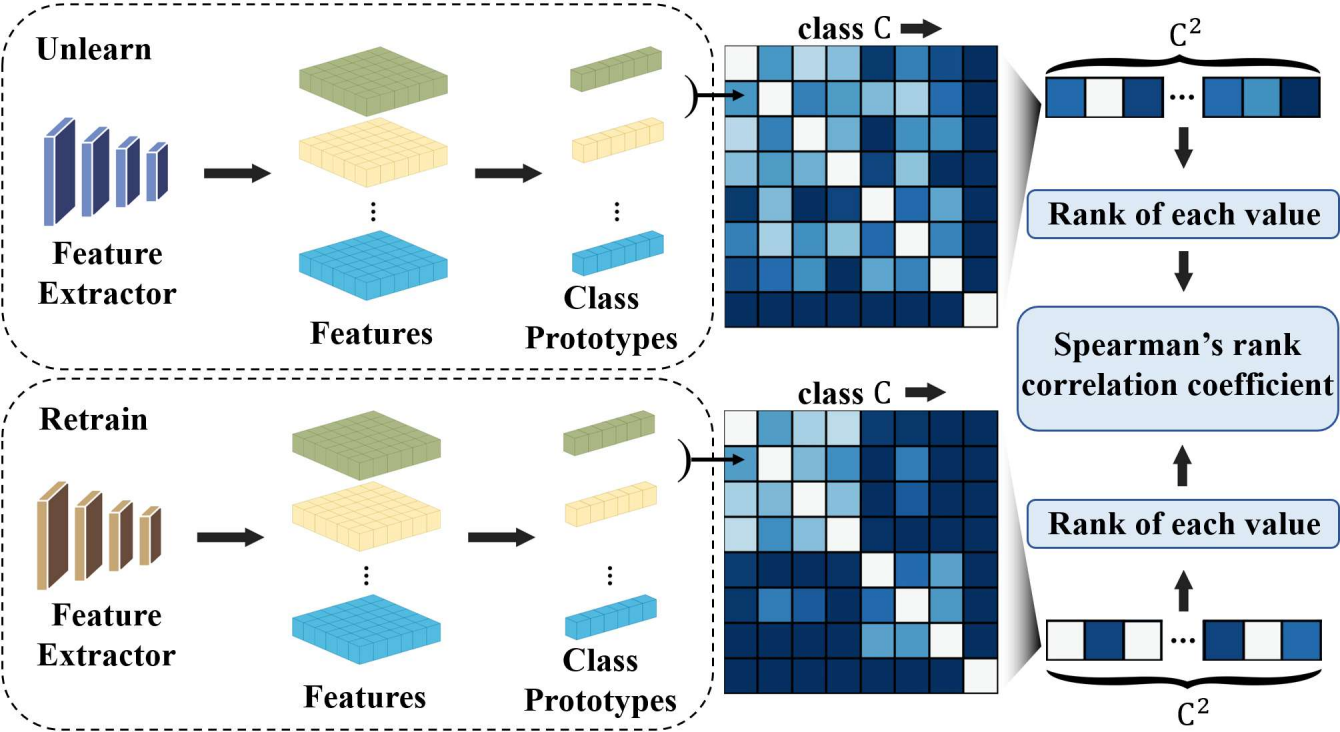
1. 각 retain 클래스의 prototype 벡터 계산
데이터셋의 클래스 \(C\)에 대해, \(k\in C\)인 \(k\)에 대해 prototype 벡터 \(p_k\)는 다음과 같이 계산합니다 :
\[\begin{equation} p_k = \frac{1}{|S_k|} \sum_{x \in S_k} f (x), \end{equation}\]2. 클래스 간 유사도 matrix 구성
\(i,j \in C\)인 \(i,j\)에 대해서 클래스 prototype 벡터 간 코사인 거리로 클래스 간 유사도를 측정합니다.
클래스 \(i,j\)간 유사도를 기반으로 Representational Dissimilarity Matrix(RDM) \(M_{i,j}\)을 구성합니다.
\[\begin{equation} M_{ij} = 1 - \frac{p_i \cdot p_j}{\|p_i\| \|p_j\|} \end{equation}\]3. Retrain의 RDM과 언러닝 후 모델의 RDM 사이의 유사도 측정
해당 단계는 두 클래스의 구조 사이의 정량적인 유사도가 아닌, 구조적 유사도를 측정하기 위한 단계입니다. 따라서 두 RDM 사이의 유사도를 측정할 때, Spearman’s rank correlation을 이용해 두 행렬의 유사도인 SSC를 계산합니다.
\[\begin{equation} SSC = 1 - {6\cdot \sum d_i^2 \over n(n^2-1)} \end{equation}\]SSC값이 높을수록, 언러닝 후 모델과 Retrain 모델의 구조가 유사함을 의미합니다.
적대적 예제 생성
retain-free 환경에서는 \(\mathcal{D_R}\)에 접근할 수 없습니다. 따라서 사전학습된 모델 \(f\)와 forget 데이터 \(\mathcal{D_F}\)만으로 retain 데이터와 비슷한 \(\mathcal{\tilde{D}_R}\)를 생성해야 합니다.
기존 retain-free 언러닝 알고리즘 중 AMUN은 \(\mathcal{D_F}\)에 대해 untargeted adversarial attack을 수행해 오분류가 발생할 때까지 임의의 방향으로 노이즈의 반경을 증가시킵니다.
그러나 PHM 도메인에서 이 방식으로 언러닝을 수행할 경우, 모델이 특정 클래스 방향으로 붕괴되는 embedding collapse 현상이 발생합니다.
본 논문은 이를 해결하기 위해 targeted adversarial attack을 수행합니다.
먼저, forget 샘플 \((x_f, y_f)\in\mathcal{D_F}\)에 대해 원래 클래스 \(y_f\)를 제외한 클래스 중 softmax 확률이 가장 높은 클래스 \(\tilde{y}\)를 다음과 같이 정의합니다 :
\[\begin{equation} \tilde{y} = \arg\max_{f (x_f)_k \neq y_f} f (x_f)_k, \end{equation}\]이는 모델이 해당 샘플을 가장 혼동하는 클래스 방향을 의미합니다. 즉, 임의의 방향이 아닌 모델이 가장 혼동하는 클래스 방향으로의 targeted update를 수행합니다.
이후, \(\mathcal{\tilde{D}_R}\)는 PGD를 변형한 다음과 같은 반복된 업데이트를 통해 생성됩니다 :
\[\begin{equation} x^{t+1} = \Pi_{\mathcal{B}_\epsilon} \Big( (x^t + \zeta^t) + \alpha \cdot \operatorname{sign}\Big( \nabla_{x^t + \zeta^t} \big[ \mathcal{L}(f(x^t + \zeta^t; \theta), \tilde{y}) \big] \Big) \Big), \end{equation}\]여기서 \(t\)는 공격의 반복 단계, \(\Pi_{\mathcal{B}_\epsilon}\)는 노이즈가 반경 \(\epsilon\)을 넘지 않도록 \(\mathcal{l}_{\inf}\)-ball으로 투영하는 연산, 그리고 \(\zeta^t\)는 각 공격 단계마다 주입되는 작은 확률적 노이즈입니다.
핵심은 per-step stochasticity입니다. 각 단계마다 작은 노이즈를 추가해 국소 손실 지형을 부드럽게 만들고, 단일 방향으로의 과도한 수렴을 방지합니다.
결과적으로 생성된 \((\tilde{x}, \tilde{y})\)는 언러닝 전 모델의 manifold 근처에 위치하면서도 retain 클래스의 기하학적 구조와 정렬된 retain-like 샘플로서 작동합니다.
모델 구조 보존을 위한 언러닝 알고리즘
ARU의 목표는 retain 데이터에 직접 접근하지 않고도 모델의 구조를 보존하며 forget 데이터의 정보를 제거하는 것입니다. 이를 다음과 같이 공식화할 수 있습니다 :
\[\begin{equation} \mathcal{L}_{ARU}(x_f, \tilde{x}, y;\alpha) = \mathcal{L}_\texttt{SDA}(x_f, \tilde{x};\alpha) + \mathcal{L}_\texttt{CE}(\tilde{x}, y) \end{equation}\]위 손실함수는 두 가지 구성 요소를 가집니다 :
1. 언러닝 항 : \(\mathcal{L}_\texttt{SDA}\)는 forget 샘플 \(x_f\)를 기존 forget 클래스 중심에서 멀어지게 하고, retain-like 데이터의 중심 방향으로 이동하도록 유도합니다.
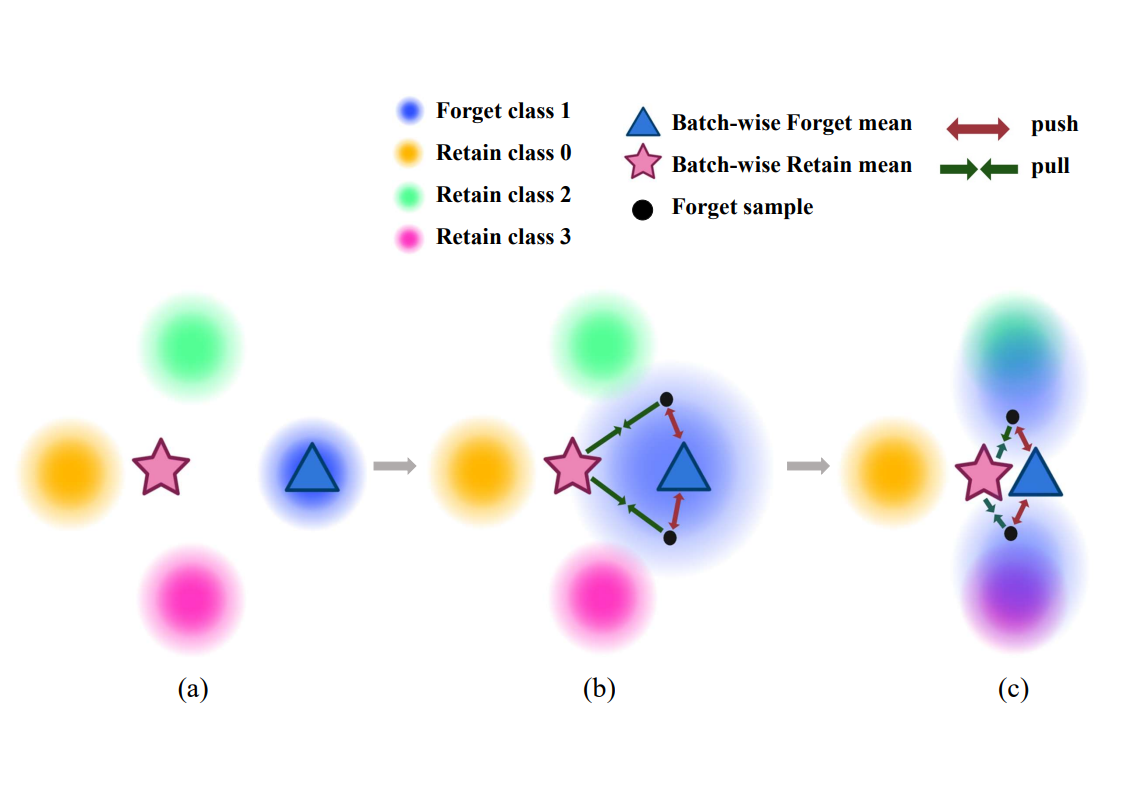
2. 모델 구조 보존 항 : \(\mathcal{L}_\texttt{CE}\)는 retain-like 데이터 \(\mathcal{\tilde{D}_R}\)로 재학습해 모델의 구조를 보존합니다.
즉, 두 항을 결합함으로써 \(\mathcal{L}_\texttt{SDA}\)를 통한 forget 데이터 분리와 \(\mathcal{L}_\texttt{CE}\)를 통한 모델의 구조 보존을 동시에 달성합니다.
embedding space에서의 성능
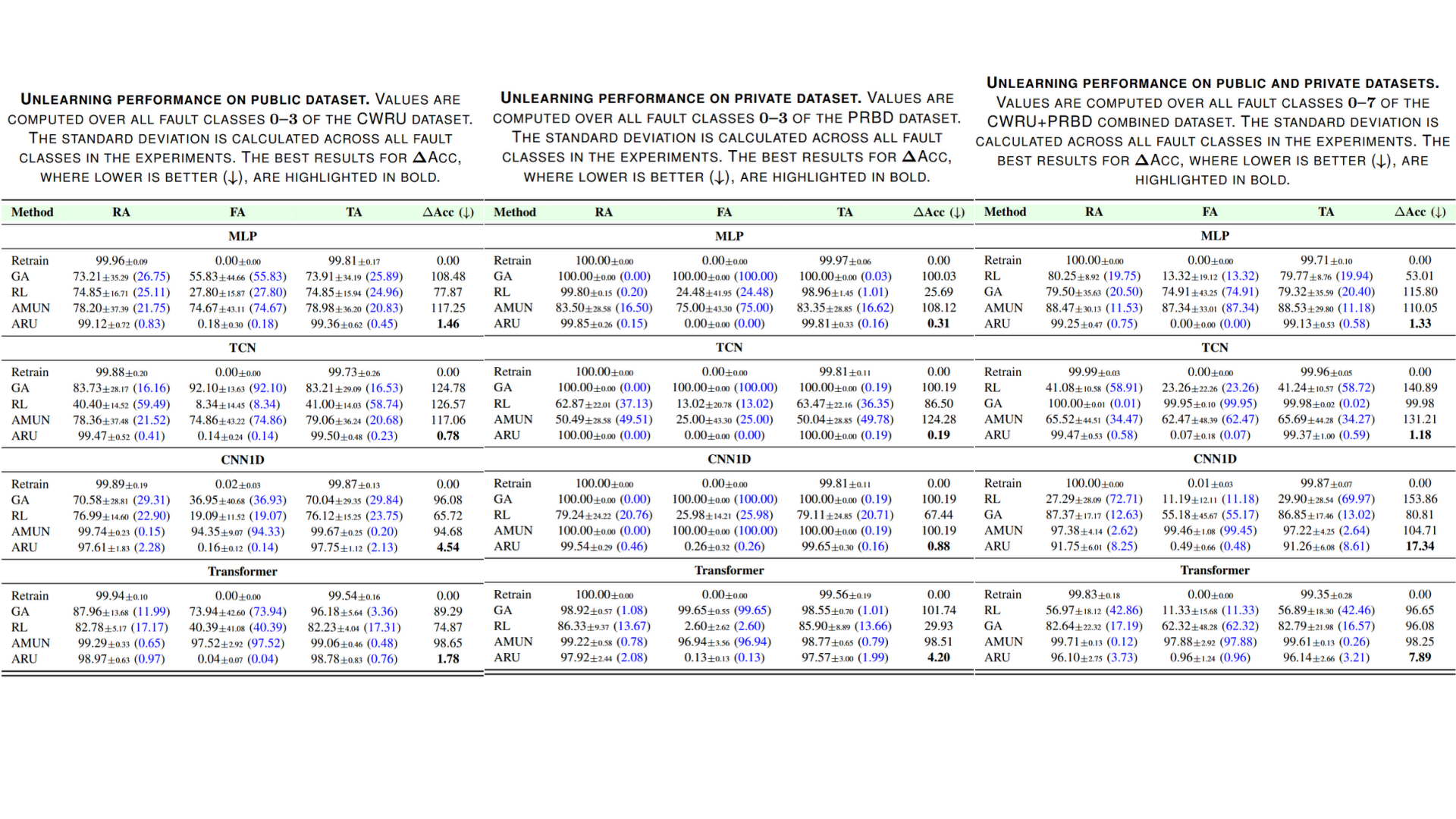
ARU를 세 가지 공정 데이터셋에서 평가했습니다 :
1. CWRU 데이터셋 : 베어링 결함 탐지에서 널리 사용되는 데이터셋입니다. CWRU 데이터셋은 결함 부위에 따라 정상, 볼 결함, 내륜 결함, 외륜 결함의 네 가지 상태로 나뉘며, 각 상태의 공정 주파수를 샘플로 수집한 데이터셋입니다.
2. PRivate Bearing Dataset(PRBD) 데이터셋 : 본 연구에서 직접 구축한 베어링 결함 진단 데이터셋입니다. CWRU 데이터셋과 마찬가지로 네 가지의 결함 상태를 가집니다.
3. CWRU + PRBD 데이터셋 : 공개된 데이터셋과 공개되지 않은 데이터셋을 동시에 사용해 현실적인 retain-free 환경을 가정했습니다.
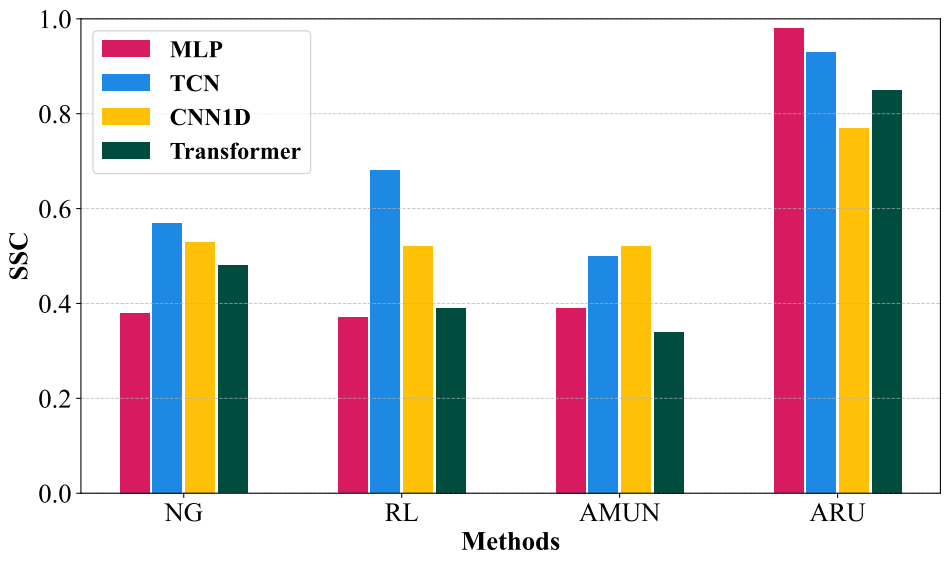
또한 MLP, TCN, CNN1D, Transformer의 네 가지 딥러닝 모델을 사용해 다양한 PHM 환경을 구현했습니다.
세 가지 데이터셋에 대해 실험한 결과, ARU는 모든 데이터셋에서 가장 낮은 \(\Delta\)Acc를 달성하며 Retrain과 가장 비슷한 정확도를 기록했습니다.
결론
산업 현장에서는 인공지능을 활용한 모델 진단 시스템이 널리 활용되고 있습니다. 이때 법적, 보안적 이유로 특정 데이터를 모델에서 삭제해야 하는 상황에서 모델이 해당 데이터를 “잊도록” 만들어야 합니다. 특히 실제 산업 현장에서는 전체 학습 데이터에 다시 접근하기 어려운 경우가 많아, 이를 해결할 수 있는 새로운 머신 언러닝 접근법이 요구됩니다.
본 논문에서는 이러한 문제를 해결하기 위해 Adversarial Retain-free Unlearning(ARU) 프레임워크를 제안합니다. ARU는 모델이 학습한 전체 데이터 대신, 삭제할 데이터만을 이용해 필요한 정보는 유지하면서도 삭제할 데이터를 효과적으로 제거합니다. 다양한 데이터셋을 이용해 ARU가 모델의 구조와 정확도를 유지하면서도 특정 클래스를 안정적으로 분리해냄을 확인했습니다.
머신 언러닝은 앞으로 프라이버시 보호와 산업 규제 준수를 위해 더욱 중요해질 기술입니다. 본 연구가 실제 PHM 환경에서 적용 가능한 언러닝 기술에 기여하기를 바랍니다.
연구실 관련 논문들
- Unlearning-Aware Minimization [NeurIPS 2025] | [Paper] | [Article]| [Code]
- Evaluating practical adversarial robustness of fault diagnosis systems via spectrogram-aware ensemble method [EAAI] | [Paper] | [Article]
- Black-box adversarial examples via frequency distortion against fault diagnosis systems [EAAI] | [Paper]
- Generating transferable adversarial examples for speech classification [Pattern Recognition] | [Paper]