논문명: Adversarial Examples in the Physical World
저자: Alexey Kurakin, Ian J. Goodfellow, Samy Bengio
게재지: ICLR 2017 Workshop Track
서론
적대적 예제(adversarial example)는 사람이 거의 구분하지 못할 정도로 입력을 미세하게 변형했음에도, 딥러닝 모델의 예측을 의도적으로 바꾸는 입력입니다. 기존 연구들은 이러한 적대적 예제를 주로 디지털 환경에서 다뤘습니다. 즉, 공격자가 모델에 입력을 직접 주입할 수 있고 픽셀 단위의 정밀한 조작이 그대로 모델에 전달된다고 가정했습니다.
하지만 현실에서의 시스템은 이보다 훨씬 복잡합니다. 카메라 기반 이미지 분류, 자율주행 인식, 모바일 앱, 영상 감시 시스템처럼 많은 모델은 현실 세계의 물체를 센서를 통해 관측한 뒤 분류합니다. 이 경우 공격자가 만든 입력은 인쇄, 촬영, 조명 변화, 거리, 각도, 센서 노이즈, 압축 등의 과정을 거치며 원본과 달라집니다. 따라서 디지털 공간에서 만든 적대적 예제가 물리 세계에서도 살아남는지는 별도의 검증이 필요합니다.
본 논문은 ImageNet용 Inception v3 분류기를 대상으로 적대적 이미지를 생성한 뒤, 이를 실제로 출력해서 휴대폰 카메라로 다시 촬영하고, 그 결과가 여전히 오분류를 유발하는지를 실험합니다. 그리고 물리적 변환을 거친 뒤에도 상당수의 적대적 예제가 여전히 유효하다는 점을 밝힙니다.
또한 어떤 생성 방식이 물리 변환에 더 강한지 비교하고, 인쇄-촬영 과정을 밝기, 대비, 블러, 노이즈, JPEG 압축 같은 인공적인 변환으로 분석합니다. 이를 통해 adversarial attack이 물리 세계에서 위협 요소가 될 수 있음을 시사합니다.

사전지식
적대적 예제
적대적 예제는 정상 입력 \(X\)에 작은 섭동을 더해 만든 입력 \(X_{adv}\)입니다. 이는 사람에게는 거의 동일하게 보이지만, 모델은 이를 잘못 분류합니다.
본 논문은 픽셀 값이 크게 변하지 않도록 \(L_{\infty}\) 제약을 사용합니다. 즉, 각 픽셀의 변화량이 최대 \(\epsilon\)을 넘지 않도록 제한합니다. \(\epsilon\)이 작을수록 사람 눈에는 더 자연스럽지만, 공격 강도는 약해질 수 있습니다.
표기
| 기호 | 의미 |
|---|---|
| \(X\) | 원본 이미지 |
| \(y_{true}\) | 원본 이미지의 실제 정답 클래스 |
| \(J(X, y)\) | 입력 \(X\)와 클래스 \(y\)에 대한 cross-entropy loss |
| \(X_{adv}\) | 적대적 이미지 |
| \(\epsilon\) | 허용되는 최대 픽셀 섭동 크기 |
| \(Clip_{X,\epsilon}\{X'\}\) | \(X'\)를 원본 \(X\)의 \(L_{\infty}\)-반경 \(\epsilon\) 안으로 clip하는 연산 |
적대적 예제 생성 방법
논문은 세 가지 생성 방식을 비교합니다.
| 방법 | 핵심 아이디어 | 특징 |
|---|---|---|
| Fast method | 손실을 한 번에 크게 증가시키는 방향으로 한 단계 이동 | 빠르지만 섭동이 거칠다 |
| Basic iterative method | 작은 스텝으로 여러 번 반복 이동 | 더 정교한 섭동 생성 |
| Iterative least-likely class method | 모델이 가장 가능성 낮다고 보는 클래스로 유도 | targeted 성격이 강하고 더 극적인 오분류 유도 |
Fast method
Fast method는 손실 함수를 입력 근방에서 선형 근사한 뒤, 손실을 가장 크게 증가시키는 부호 방향으로 한 번 이동하는 방식입니다. 이는 FGSM의 형태와 같습니다.
\[X_{adv} = X + \epsilon \cdot \operatorname{sign}(\nabla_X J(X, y_{true}))\]이 방법은 한 번의 역전파만으로 공격 샘플을 만들 수 있어 계산 비용이 매우 낮습니다. 대신 섭동이 상대적으로 거칠고, 반복 기반 방법보다 디지털 공간에서는 공격력이 약할 수 있습니다.
Basic iterative method
Basic iterative method는 fast method를 작은 step size로 여러 번 반복 적용한 방식입니다.
\[X^{adv}_{0} = X\] \[X^{adv}_{N+1} = Clip_{X,\epsilon} \left\{ X^{adv}_{N} + \alpha \cdot \operatorname{sign}(\nabla_X J(X^{adv}_{N}, y_{true})) \right\}\]논문에서는 \(\alpha = 1\)을 사용하여 각 스텝에서 각 픽셀의 값을 1만큼만 변경합니다. 반복 횟수는 경험적으로 정합니다. 이 방식은 더 미세한 섭동으로 분류 경계를 공략할 수 있어 디지털 환경에서는 더 강력한 공격을 만드는 경우가 많습니다.
Iterative least-likely class method
앞의 두 방법은 단순히 정답 클래스를 무너뜨리는 non-targeted 공격입니다. 반면 이 방법은 모델이 가장 가능성이 낮다고 판단한 클래스 \(y_{LL}\) (Least Likely class)를 목표 클래스로 삼아, 입력을 그 방향으로 밀어붙이는 targeted iterative attack입니다.
\[y_{LL} = \arg\min_{y} p(y|X)\] \[X^{adv}_{N+1} = Clip_{X,\epsilon} \left\{ X^{adv}_{N} - \alpha \cdot \operatorname{sign}(\nabla_X J(X^{adv}_{N}, y_{LL})) \right\}\]이 방식은 예를 들어 개를 비행기로 분류하게 만드는 식의 더 극적인 오분류를 유도할 수 있습니다. 다만 이런 정교한 섭동은 물리 변환에 더 취약할 수도 있습니다.
적대적 예제 생성 실험
목표
물리 세계 실험에 앞서, 세 가지 공격 방법이 디지털 환경에서 얼마나 효과적인지 비교합니다. 이 단계의 목적은 어떤 공격이 원래 모델을 얼마나 잘 속이는지, 그리고 어느 정도의 \(\epsilon\) 범위가 ‘작은 노이즈’ 수준에서 실질적인 공격력을 보이는지 확인하는 것입니다.
실험 설정
- 데이터셋: ImageNet validation set 50,000장
- 모델: pre-trained Inception v3
- 공격 방식: fast, basic iterative, iterative least-likely class
- 섭동 크기: \(\epsilon = 2 \sim 128\)
- 평가 지표: top-1 accuracy, top-5 accuracy
정상 이미지의 정확도를 기준선으로 두고, 각 공격 방법과 \(\epsilon\) 조합에 대해 adversarial image의 정확도를 측정합니다. top-1 accuracy는 모델의 최상위 예측이 정답과 일치하는 비율을 의미하고, top-5 accuracy는 정답 클래스가 상위 5개 예측 안에 포함되는 비율을 나타냅니다.
실험 결과
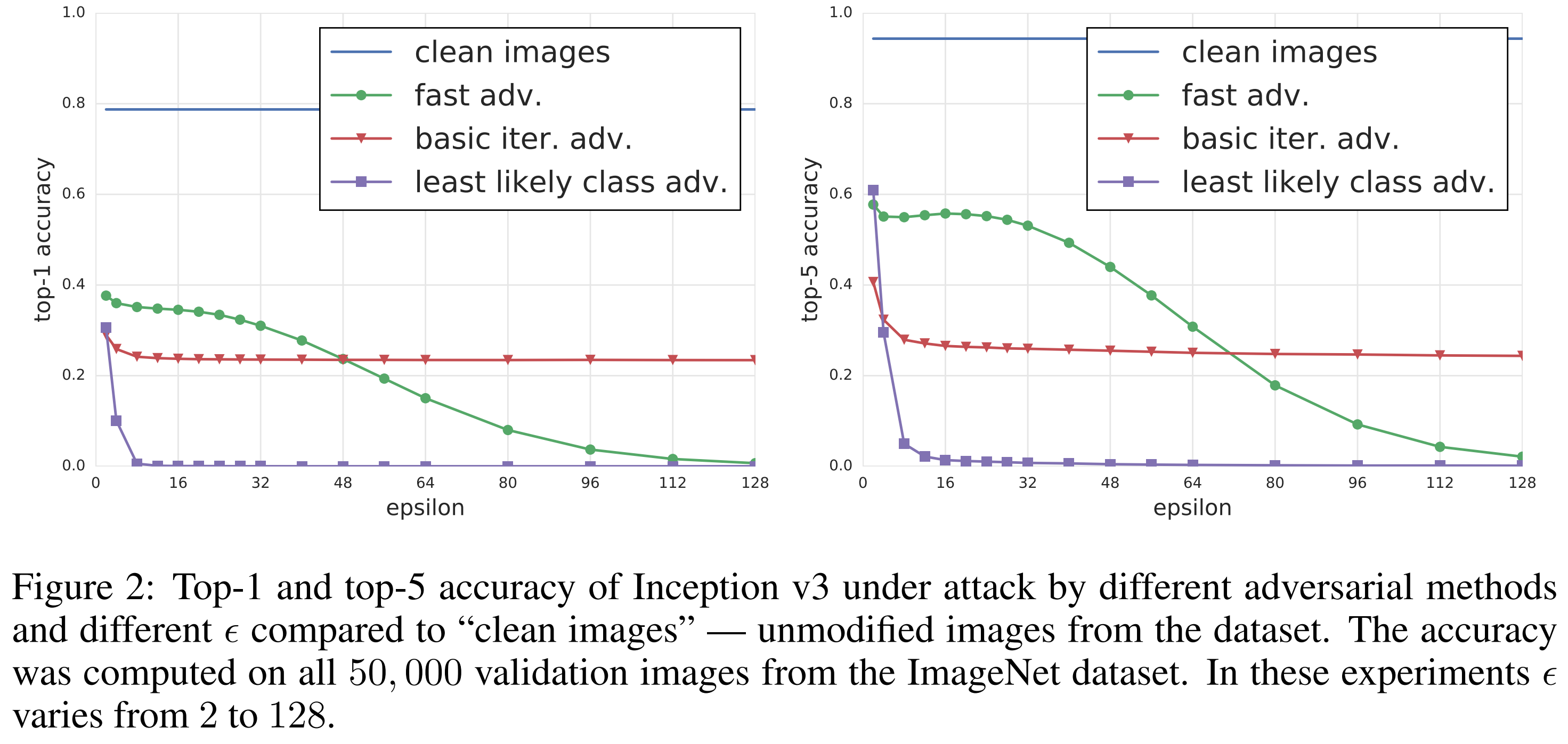
실험 결과, 세 공격 방식 모두 ImageNet 분류 성능을 유의미하게 떨어뜨렸습니다.
우선 fast method는 가장 단순한 방식임에도 작은 \(\epsilon\)에서 이미 강한 효과를 보였습니다. 논문에 따르면 가장 작은 \(\epsilon\)에서도 top-1 accuracy를 대략 절반 수준으로 떨어뜨리고, top-5 accuracy도 약 40% 감소시켰습니다. 다만 \(\epsilon\)이 너무 커지면 이미지 자체가 사람이 보기에도 훼손되기 시작합니다.

반면 iterative 계열은 더 세밀한 섭동을 사용하기 때문에, 이미지 내용을 비교적 유지하면서 더 높은 오분류율을 유도할 수 있었습니다. 특히 least-likely class 방식은 더 작은 \(\epsilon\)에서도 효과적으로 오분류를 일으키는 모습을 발견할 수 있습니다.

논문은 이후의 모든 물리 세계 실험을 \(\epsilon \le 16\)으로 제한합니다. 그 이유는 이 범위의 섭동이 사람에게는 여전히 작은 잡음처럼 보이면서도, 분류기를 충분히 혼동시킬 수 있기 때문입니다. 즉, 이 논문이 물리 실험에서 보여주는 공격은 ‘눈에 띄게 망가진 이미지’가 아니라, ‘상대적으로 자연스러운 이미지에서도 공격이 가능하다’는 점이 중요합니다.
물리 세계 실험
Destruction rate
논문은 적대적 예제가 물리 변환을 거친 뒤에도 얼마나 공격성을 유지하는지 평가하기 위해 Destruction rate \((d)\) 라는 지표를 정의합니다. 이는 디지털 상태에서는 성공했던 적대적 예제 중에서 변환 후에는 더 이상 공격에 성공하지 못하는 비율입니다. destruction rate가 낮을수록 적대적 예제가 변환 후에도 잘 살아남는다는 의미이며, 높을수록 물리 변환이 공격을 잘 무력화한다는 의미입니다.
\[d = \frac{ \sum_{k=1}^{n} C(X_k, y_k^{true}) \overline{C}(X_k^{adv}, y_k^{true}) C(T(X_k^{adv}), y_k^{true}) }{ \sum_{k=1}^{n} C(X_k, y_k^{true}) \overline{C}(X_k^{adv}, y_k^{true}) }\]| 기호 및 수식 | 설명 |
|---|---|
| $T(\cdot)$ | 인쇄 및 재촬영 등 물리적 환경에서 발생하는 변환 |
| $C(X,y)$ | 이미지 $X$가 클래스 $y$로 정분류되면 1, 오분류되면 0을 반환하는 함수 |
| $\overline{C}(X, y) = 1 - C(X, y)$ | 모델의 오분류 여부를 나타내는 지시 함수 |
실험 설정
물리 세계 실험의 파이프라인은 다음과 같습니다.
- 디지털 clean image와 adversarial image를 출력한다.
- 출력물을 휴대폰 카메라로 촬영한다.
- 촬영 이미지에서 원본 예제를 자동으로 crop 및 warp한다.
- 다시 분류기에 넣어 정확도와 destruction rate를 측정한다.

세부 설정은 다음과 같습니다.
- 출력 장치: Ricoh MP C5503 사무용 프린터, 600dpi
- 촬영 장치: Nexus 5x 휴대폰 카메라
- 전처리: 출력물 모서리에 QR 코드를 넣어 자동 검출 및 crop 수행
- 사진 환경: 실내 일반 조명, 카메라 각도와 거리의 엄격한 통제는 없음
이때 저자들은 오히려 조명, 거리, 각도 등을 완전히 통제하지 않았습니다. 이는 현실적인 nuisance variability를 일부 남겨 두기 위함입니다. 즉, 실제 환경에서 발생하는 변형이 adversarial perturbation을 얼마나 깨뜨리는지 보기 위한 설계입니다.
Average case와 Prefiltered case
논문은 물리 공격을 두 가지 시나리오로 나누어 봅니다.
- Average case: 무작위로 선택한 102개 이미지에 대해 적대적 예제를 생성하고 공격을 수행합니다.
- Prefiltered case: 더 공격적인 적대적 예제에 대한 실험을 수행하기 위해 다음 기준으로 이미지를 선별합니다. 디지털 환경에서 clean image는 정확히 분류되고 adversarial image는 top-1, top-5 모두 틀리도록, 그리고 예측 confidence가 0.8 이상이 되게 하는 102개 이미지를 선별하고 공격을 수행합니다.
Average case는 “현실에서 임의의 입력에 대해 공격하면 얼마나 먹히는가”를 보고, Prefiltered case는 “공격자가 유리한 샘플을 골라 공격하면 얼마나 강해지는가”를 보는 설정입니다.
물리 세계 실험 결과
실험 결과, 인쇄하고 촬영한 뒤에도 상당수 adversarial image가 여전히 오분류를 유발했습니다. 즉, 물리 변환은 공격을 약화시키지만 완전히 무력화하지는 못했습니다.
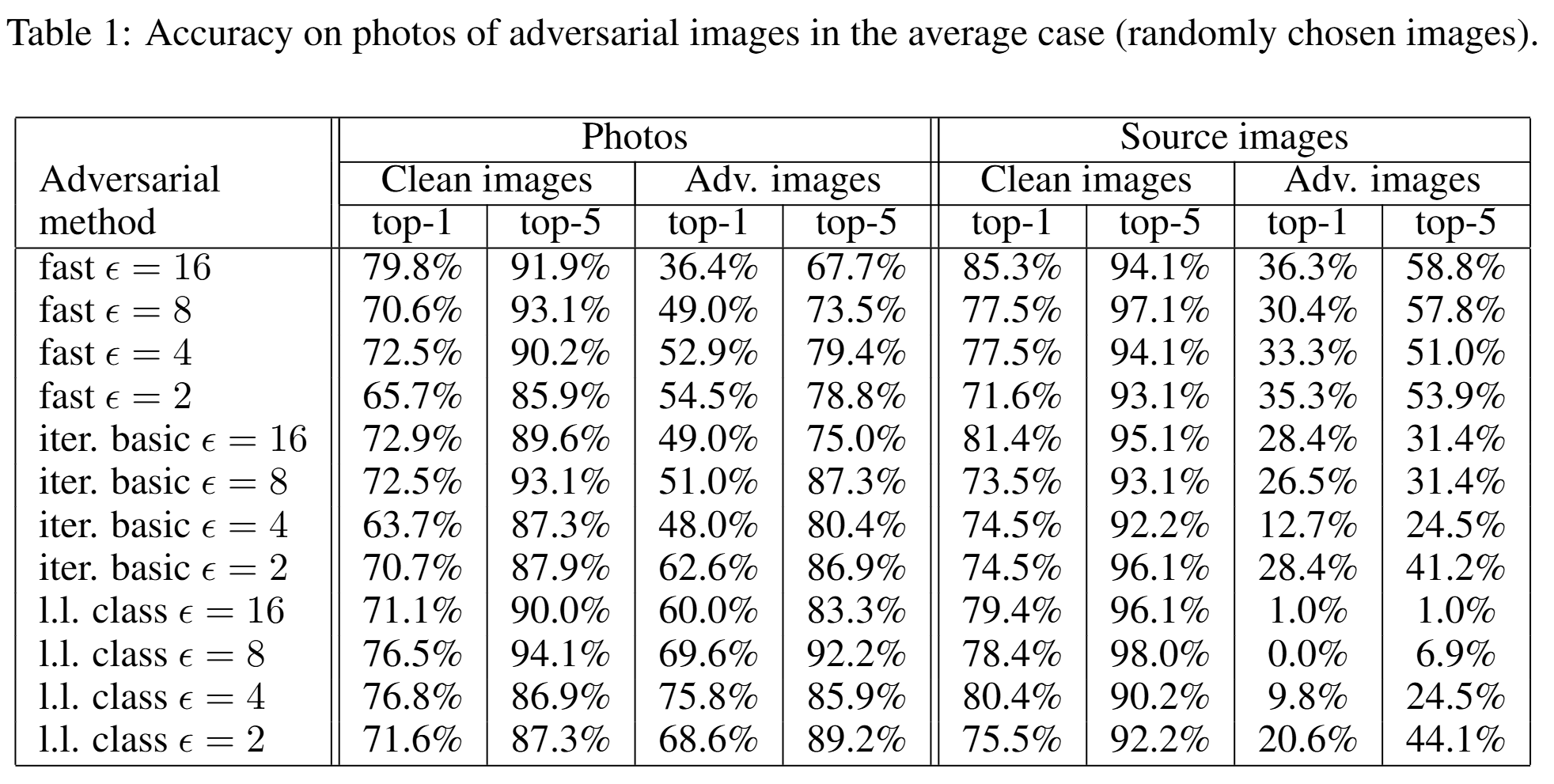
위 표는 average case에서 정확도를 보여줍니다. fast method, \(\epsilon = 16\)의 경우, 촬영된 adversarial image의 top-1 accuracy는 36.4\%였습니다. 이는 뒤집어 말하면 약 63.6\%가 여전히 top-1 오분류를 일으켰다는 뜻입니다. top-5 accuracy는 67.7%였으므로, 약 32.3%는 top-5 기준으로도 여전히 공격이 유지됐습니다.
흥미로운 점은 fast method가 iterative 계열보다 물리 변환에 더 강건했다는 점입니다. average case의 top-1 destruction rate는 다음과 같습니다.
| 공격 기법 | 비율 |
|---|---|
| fast $\epsilon = 16$ | 12.5% |
| basic iterative $\epsilon = 16$ | 40.4% |
| least-likely class $\epsilon = 16$ | 72.2% |
즉, 디지털 공간에서 더 강력해 보이던 iterative 공격이, 실제 인쇄-촬영 과정에서는 오히려 더 잘 깨졌습니다. 논문은 이를 iterative 방법이 더 미세하고 섬세한 co-adaptation에 의존하기 때문이라고 해석합니다. 정교한 perturbation일수록 오히려 현실 세계의 작은 변형에 더 쉽게 손상된다는 뜻입니다.
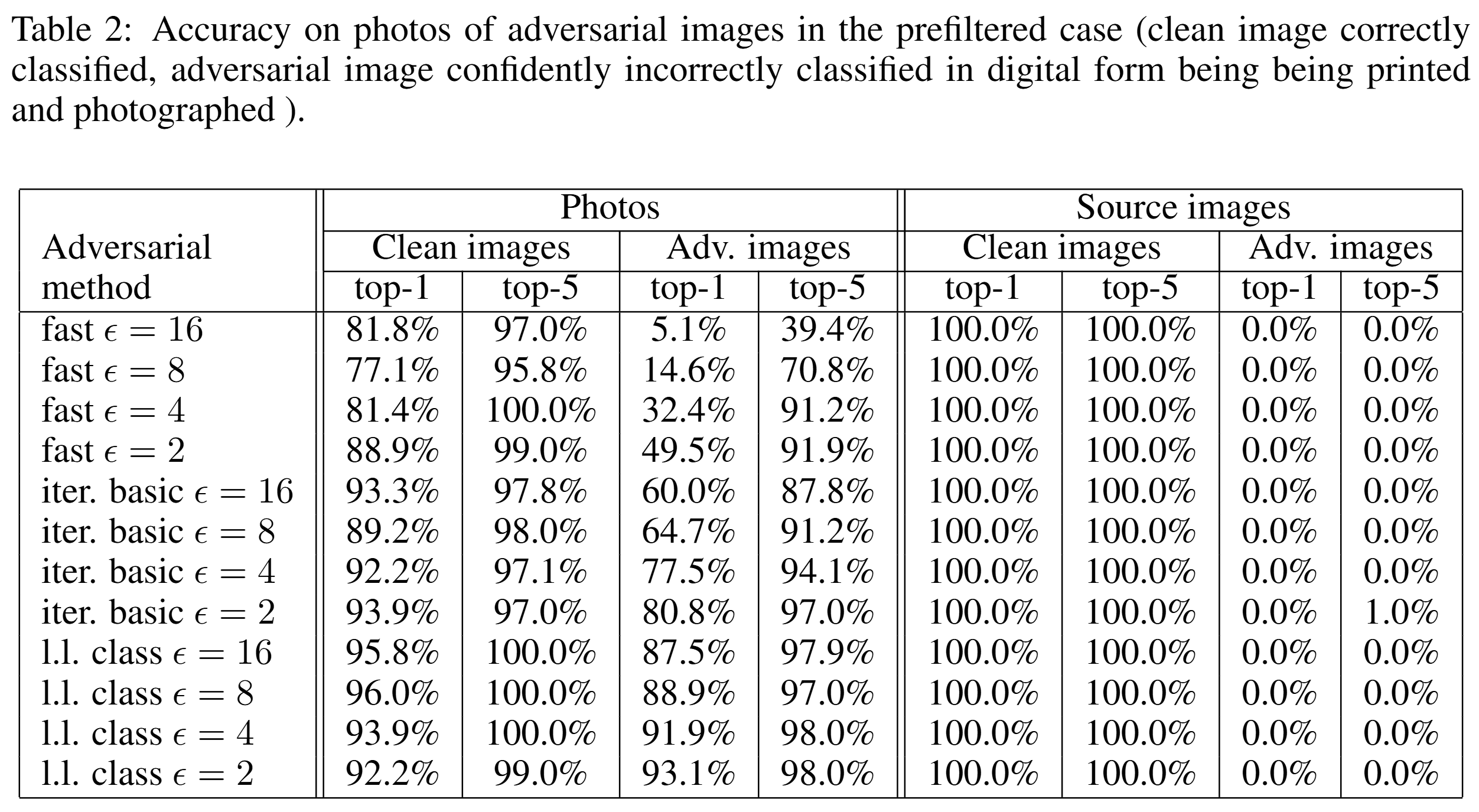
위 표는 prefiltered case에서의 정확도이며, average case와 비슷한 경향이 관찰됩니다. 처음부터 공격이 잘 되는 샘플만 선별하여 공격하더라도, 물리 변환은 iterative 공격에 상당한 타격을 주었습니다.
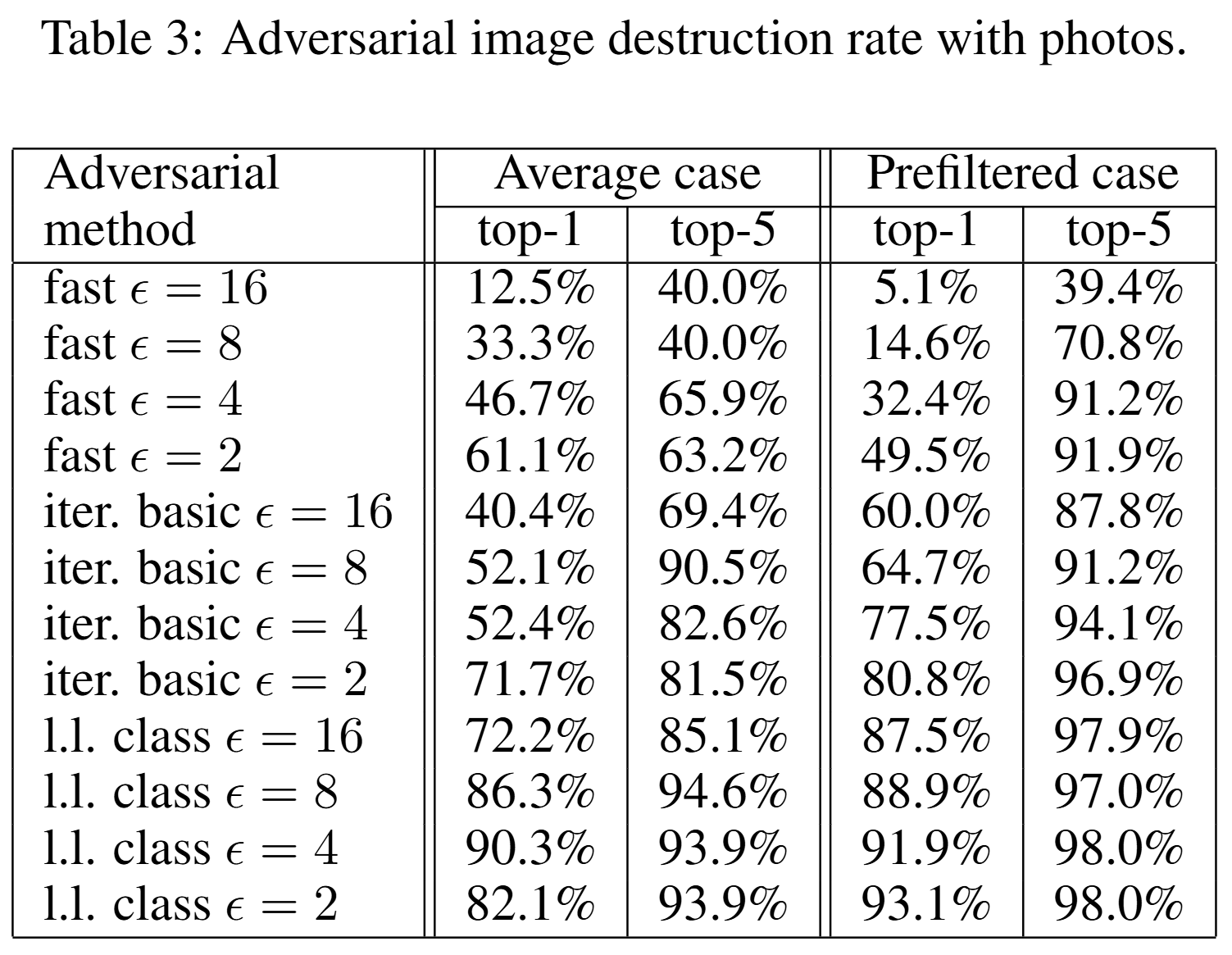
위 표는 두 가지 case에서의 destruction rate 결과입니다. 이는 디지털 환경에서 생성된 적대적 예제가 물리 세계에서 공격 효과가 사라졌는지를 의미합니다. Prefiltered case의 destruction rate가 average case보다 더 높은 결과도 존재하는데, 이는 디지털 환경에서 지나치게 잘 맞춘 공격이 현실 변환에는 더 취약할 수 있음을 시사합니다. 정리하면, 물리 세계에서의 adversarial attack은 분명히 가능하지만, 어떤 공격이 더 위협적인지는 디지털 성능만으로 판단할 수 없습니다.
물리 세계 블랙 박스 공격
논문은 본 실험 자체는 화이트박스 설정에서 수행했지만, 별도로 물리 세계에서의 블랙박스 공격도 보여줍니다. 저자들은 Inception v3를 기준으로 만든 adversarial printout을 모바일용 TensorFlow Camera Demo 앱에 보여 주었고, clean image는 정상 분류되지만 adversarial image는 잘못 분류되는 현상을 관찰했습니다. 이 결과는 물리 세계에서도 적대적 예제의 전이성(Transferability)이 의미 있게 작동할 수 있음을 보여 주는 정성적 증거입니다. 즉, 공격자가 대상 모델의 내부를 몰라도, 대체 모델에서 만든 적대적 예제가 실제 카메라 기반 시스템에 전달될 가능성이 있음을 시사합니다.
인공 이미지 변환 실험
목표
인쇄-촬영 과정은 매우 복합적인 변환입니다. 논문은 이 복합 변환을 더 잘 이해하기 위해, 사진 촬영 과정을 통제 가능한 몇 가지 단순한 인공 변환(Artificial Transformations)으로 분해해 적대적 예제가 어떻게 파괴되는지 분석합니다. 즉, 현실의 복잡한 왜곡을 밝기, 대비, 노이즈, 압축과 같은 개별 요소로 쪼개어, 각 요소가 적대적 예제의 공격성을 파괴하는 데 얼마나 기여하는지 측정했습니다.
실험 설정
- 데이터: ImageNet validation set에서 무작위로 뽑은 1,000장
- 변환 종류: brightness/contrast 변화, Gaussian blur, Gaussian noise, JPEG encoding
- 방식: adversarial image를 만든 뒤 변환을 적용하고 destruction rate 측정
실험 결과
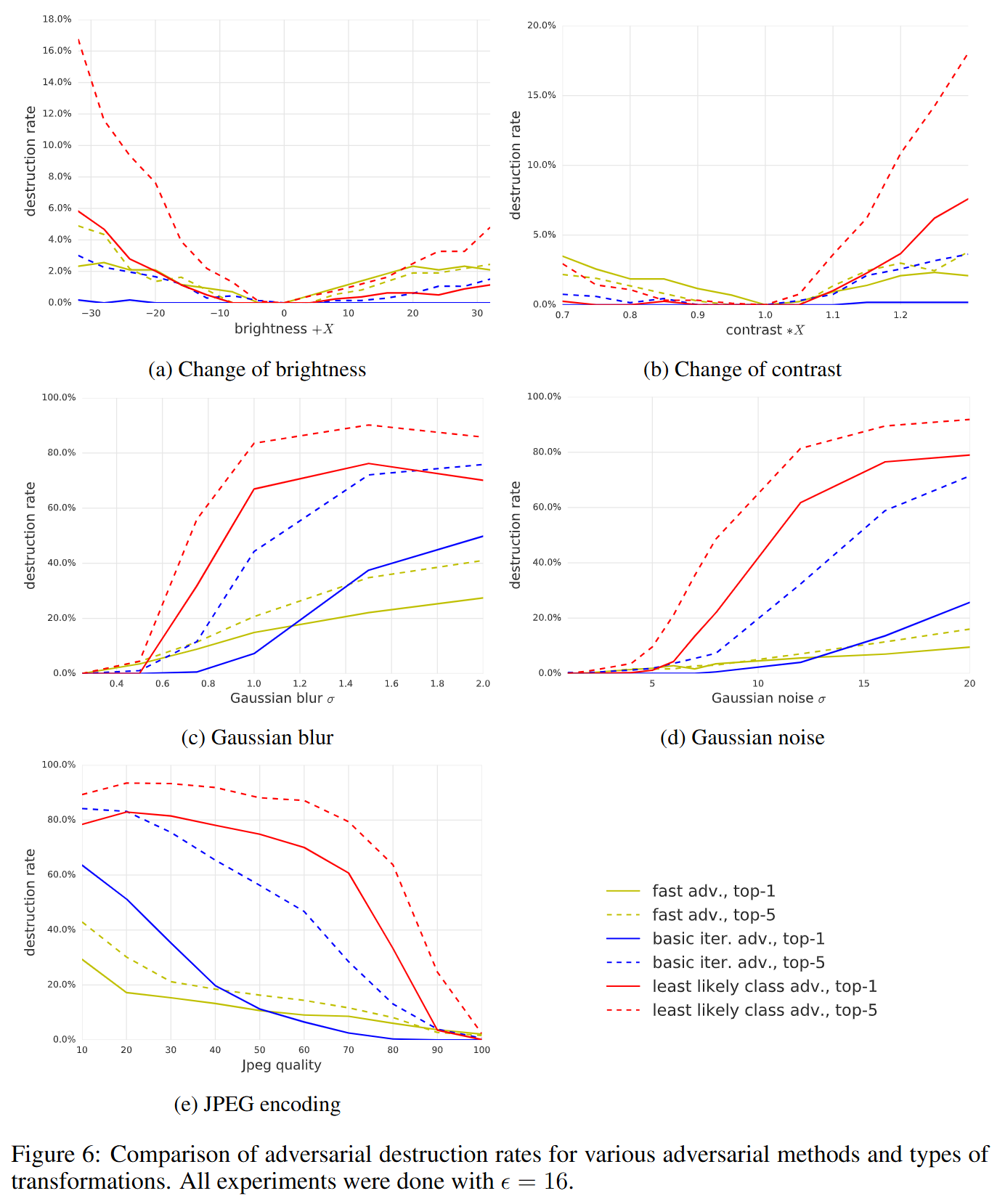
위 그래프에 따르면, 적대적 예제에 대한 인공 변환의 영향은 다음과 같습니다.
-
(a) Change of brightness & (b) Change of contrast
- 밝기나 대비의 변화는 파괴율이 매우 낮습니다 (대체로 20% 미만).
- 이는 적대적 예제가 단순히 밝기가 변하는 정도로는 쉽게 무력화되지 않음을 의미합니다.
-
(c) Gaussian blur & (d) Gaussian noise
- 이미지를 흐리게 하거나 노이즈를 추가하면 파괴율이 급격히 상승합니다.
- 특히 least-likely class와 같은 정교한 반복 공격 방식은 미세한 픽셀 조정을 이용하기 때문에, 블러나 노이즈 같은 거친 변환에 매우 취약합니다 (파괴율 80~90% 도달).
-
(e) JPEG encoding
- JPEG 압축 강도가 높아질수록(Quality 값이 낮아질수록) 파괴율이 높아집니다.
- 손실 압축 과정에서 적대적 공격을 위해 심어둔 미세한 신호들이 제거되기 때문입니다.
결론
본 논문은 적대적 예제(Adversarial Examples)가 단지 디지털 공간의 수학적·인공적 현상에 머물지 않고, 물리 세계에서도 실제로 유효한 위협임을 실험적으로 입증한 선구적인 연구입니다. 논문의 핵심 메시지는 다음 세 가지로 요약할 수 있습니다.
- 물리적 환경에서의 위협 유지: 디지털 환경에서 생성한 적대적 이미지는 인쇄 및 카메라 촬영이라는 물리적 변환을 거친 후에도 상당한 확률로 모델의 오분류를 유발합니다.
- 공격 기법의 강도와 물리적 견고성의 역설: 디지털 공간에서 가장 정교하고 강력한 공격(예: least-likely class)이 물리 세계에서도 항상 치명적인 것은 아닙니다. 오히려 fast method와 같이 단일 단계로 이루어진 상대적으로 단순한 공격이 물리적 변환에 더 강한 내성을 보입니다.
- 단순 변환을 통한 방어의 한계: 밝기나 대비 같은 단순한 변화만으로는 적대적 공격을 무력화하기 어렵습니다. Blur, Noise, JPEG 압축 등의 거친 변환이 공격 성공률을 다소 낮출 수는 있지만, 방어 기법으로서 위협을 완전히 차단하지는 못합니다.
결론적으로 이 연구의 가장 큰 의의는, 모델의 적대적 강건성(Adversarial Robustness)을 평가할 때 모델 내부의 알고리즘적 취약성뿐만 아니라 센서, 인쇄, 촬영, 압축 등 물리적 전달 경로 전체를 포괄적으로 고려해야 한다는 패러다임을 제시했다는 데 있습니다.