논문명: Explaining and Harnessing Adversarial Examples
저자: Ian J. Goodfellow, Jonathon Shlens & Christian Szegedy
게재지: In International Conference on Learning Representations (ICLR), 2015
서론 (Introduction)
적대적 예제(Adversarial Examples)의 미스터리
여러 머신러닝(Machine Learning) 모델과 최첨단 신경망들은 적대적 예제(Adversarial Examples)에 매우 취약하다는 치명적인 약점을 가지고 있습니다. 적대적 예제란, 원래의 데이터 분포에서 추출한 올바른 입력값에 인간의 눈으로는 인식할 수 없을 만큼 작지만 의도적으로 최악의 상황을 가정하여 계산된 섭동(Perturbation)을 가한 데이터를 말합니다. 놀랍게도 모델들은 이러한 미세한 변화만으로도 완전히 잘못된 정답을 매우 높은 신뢰도(Confidence)로 출력하게 됩니다.
초기 연구자들은 이 현상의 원인을 심층 신경망(Deep Neural Networks)이 가지는 극단적인 비선형성(Nonlinearity)과 지도 학습(Supervised Learning)의 불충분한 정규화(Regularization)로 인한 과적합(Overfitting) 때문이라고 추측했습니다.
하지만 본 논문은 이러한 추측이 틀렸음을 증명합니다. 오히려 신경망이 적대적 섭동에 취약한 근본적인 이유는 모델들이 너무 선형적(Linear)이기 때문이라고 주장합니다. 이 선형적 관점은 적대적 예제가 왜 다양한 아키텍처와 훈련 데이터셋을 넘나들며 일반화(Generalize)되는지 완벽하게 설명해줍니다.
적대적 예제의 선형적 원인 (The Linear Explanation)
고차원 공간에서의 선형성 (Linearity in High-Dimensional Spaces)
디지털 이미지는 픽셀당 8비트(Bits)를 사용하는 경우가 많아 동적 범위(Dynamic range)의 1/255 미만의 정보는 버려지게 됩니다. 모델의 입력 특징(Features)이 가지는 정밀도(Precision)에는 한계가 있으므로, 만약 섭동(Perturbation)의 모든 원소가 특징의 정밀도보다 작다면 분류기(Classifier)는 원래 입력과 적대적 입력에 대해 다르게 반응해서는 안 됩니다.
선형 모델을 예로 들어, 가중치 벡터(Weight vector) $w$와 적대적 예제 $\tilde{x}$의 내적(Dot product)을 생각해보면 다음과 같습니다.
\[w^{\top}\tilde{x} = w^{\top}x + w^{\top}\eta\]적대적 섭동은 활성화(Activation) 수치를 $w^{\top}\eta$ 만큼 증가시킵니다. 만약 최대 노름(Max-norm) 제약 조건 하에서 이 증가량을 극대화하려면 $\eta = sign(w)$로 설정하면 됩니다. 고차원 문제에서는 각 입력 차원마다 아주 작은 변화를 주더라도, 이것이 가중치 차원을 따라 선형적으로 누적되면서 출력에는 하나의 거대한 변화를 만들어냅니다. 이는 비선형성이 아니라 선형적 동작이 적대적 예제를 만들어내기에 충분함을 보여줍니다.
빠르고 효율적인 공격: FGSM (Fast Gradient Sign Method)
비선형 모델에 대한 선형적 섭동(Perturbation)
LSTM, ReLU, Maxout 등의 최신 신경망 구조들은 최적화(Optimization)를 쉽게 하기 위해 의도적으로 선형적으로 동작하도록 설계되었습니다. 심지어 시그모이드(Sigmoid) 네트워크와 같은 비선형 모델조차도 포화(Saturate)되지 않는 선형적 영역에서 주로 동작하도록 조정됩니다.
이러한 특성 때문에 선형 모델을 타격하는 저렴하고 분석적인 섭동 방법이 신경망에도 똑같이 심각한 손상을 입힐 수 있습니다. 저자들은 현재 파라미터 주변에서 비용 함수(Cost function)를 선형화하여 최적의 적대적 섭동을 계산하는 Fast Gradient Sign Method (FGSM)를 제안합니다.
\[\eta = \epsilon sign(\nabla_{x}J(\theta,x,y))\]필요한 기울기(Gradient)는 역전파(Backpropagation)를 이용해 매우 효율적으로 계산할 수 있습니다.

실제로 이 방법을 사용해 특정 크기의 섭동을 적용했을 때, 얕은 소프트맥스 분류기(Softmax classifier)는 MNIST 테스트 셋에서 99.9%의 에러율을 기록했으며, Maxout 네트워크는 89.4%의 에러율을 보였습니다.
모델의 견고함 향상: 적대적 훈련 (Adversarial Training)
새로운 정규화(Regularization) 기법
얕은 선형 모델과 달리 깊은 신경망(Deep networks)은 적어도 적대적 섭동에 저항할 수 있는 함수를 표현할 수 있는 능력(Capacity)을 갖추고 있습니다. 보편적 근사 정리(Universal approximator theorem)에 따르면 충분한 은닉 유닛(Hidden units)을 가진 네트워크는 어떤 함수든 근사할 수 있기 때문입니다. 문제는 표준적인 지도 학습(Supervised training) 방식이 적대적 예제에 대한 저항성을 스스로 학습하도록 유도하지 못한다는 점입니다.
따라서 FGSM을 기반으로 한 적대적 목적 함수를 훈련 과정에 직접 통합하는 방법이 제시되었습니다.
\[\tilde{J}(\theta,x,y) = \alpha J(\theta, x, y) + (1-\alpha)J(\theta, x + \epsilon sign(\nabla_{x}J(\theta,x,y)))\]논문의 실험에서는 $\alpha=0.5$를 사용했습니다. 이 방식을 통해 적대적 예제의 공급을 지속적으로 업데이트하면서 모델을 훈련시킨 결과, 드롭아웃(Dropout)이 적용된 Maxout 네트워크의 에러율을 0.94%에서 0.84%로 성공적으로 낮추었으며 뛰어난 정규화 효과를 입증했습니다. 적대적 예제에 대한 모델의 에러율 역시 89.4%에서 17.9%로 극적으로 떨어졌습니다.
왜 적대적 예제는 일반화(Generalize)되는가?
모델 간의 전이성 (Transferability)
적대적 예제의 가장 흥미로운 특성 중 하나는, 특정 모델을 속이기 위해 만들어진 예제가 아키텍처나 훈련 데이터가 완전히 다른 다른 모델들까지도 속일 수 있다는 점입니다. 게다가 잘못 예측하는 클래스조차 서로 일치하는 경우가 많습니다. 만약 극단적인 비선형성이나 과적합이 원인이라면, 서로 다른 모델이 같은 예제에 대해 동일한 오답을 내놓는 현상을 설명할 수 없습니다.
선형적 관점에서는 적대적 예제가 유리수처럼 공간에 촘촘히 흩어진 좁은 공간(Fine pockets)에 존재하는 것이 아니라, 넓은 부분 공간(Broad subspaces)에 걸쳐 발생한다고 설명합니다. 즉, 비용 함수의 기울기와 양의 내적(Positive dot product)을 가지는 올바른 ‘방향’으로 섭동의 크기를 충분히 키우기만 하면 안정적으로 적대적 예제를 만들어낼 수 있습니다. 머신러닝 알고리즘들이 같은 데이터셋을 기반으로 일반화(Generalize)를 수행하면서 비슷한 분류 가중치를 학습하기 때문에, 가중치의 안정성이 곧 적대적 예제의 안정성(전이성)으로 이어집니다.
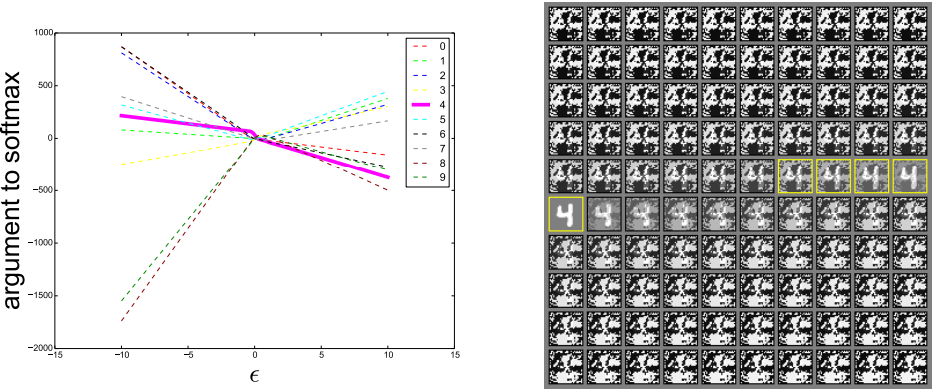
결론 (Conclusion)
핵심 요약 및 최적화의 역설
본 논문을 관통하는 주요 결과는 다음과 같습니다:
- 적대적 예제는 고차원 내적(Dot products)의 특성이며, 비선형성이 아닌 선형성 때문에 발생합니다.
- 다양한 모델에서 적대적 예제가 일반화되는 이유는 섭동이 모델의 가중치 벡터와 강하게 정렬되어 있고, 서로 다른 모델들이 유사한 함수를 학습하기 때문입니다.
- 공간의 특정한 점이 아니라 섭동을 가하는 방향(Direction)이 가장 중요합니다.
- 최적화하기 쉬운 모델일수록 교란하기도 쉽습니다(Models that are easy to optimize are easy to perturb).
결과적으로 최신 AI 모델들은 훈련 데이터를 완벽히 분류해낼 수 있지만, 데이터 분포를 벗어난 영역에서는 지나치게 높은 신뢰도로 잘못된 예측을 내놓는 심각한 결함을 지니고 있습니다. 딥러닝이 채택한 ‘최적화의 용이성’은 ‘쉽게 오도될 수 있는 모델’이라는 대가를 치르고 얻어진 것입니다.
이 연구는 적대적 훈련(Adversarial Training)을 통해 이러한 결함을 부분적으로 완화할 수 있음을 입증했으며, 향후 국소적으로 더 안정적인 동작을 보장할 수 있는 강력한 최적화 기법의 개발이 필요하다는 중요한 시사점을 던져줍니다.