논문명: Obfuscated Gradients Give a False Sense of Security
저자: Anish Athalye, Nicholas Carlini, David Wagner
게재지: Proceedings of the 35th International Conference on Machine Learning (ICML 2018)
서론
이 논문은 기존의 적대적 예제(Adversarial Examples)에 대한 방어 기법들이 실질적인 방어를 제공하지 못한다는 점을 지적하며, 각 방어 기법을 우회하는 공격 방법들을 제시합니다.
기존 방어 기법들은 기울기를 불분명하게 만드는 Obfuscated Gradient 현상에 의존하여 방어에 성공한 것처럼 보이지만, 저자들은 이것이 근본적인 방어가 될 수 없음을 주장합니다.
저자들은 Obfuscated Gradient가 발생하는 3가지 유형을 분류하고, 각 유형에 대한 우회 공격 기법을 제안합니다. 또한 ICLR 2018에 게재된 9가지 방어 기법을 대상으로 검증을 수행하여, 그 중 7가지가 Obfuscated Gradient에 의존하고 있음을 밝혀냈습니다.
본론
기존의 적대적 공격 기법들은 기울기를 활용한 반복적인 최적화를 통해 효과적인 적대적 예제를 생성해왔습니다. 후속 연구들은 이를 방어하기 위한 다양한 기법들을 제시하며 그 효과를 주장하였지만, 이 논문의 저자들은 해당 방어 기법들이 기울기를 불분명하게 만드는 Obfuscated Gradient 현상에 의존하고 있을 뿐, 실질적인 방어 기법이 아니라고 주장합니다.
Obfuscated Gradients
Obfuscated Gradient는 다음의 3가지 유형으로 분류됩니다.
1. Shattered Gradient Shattered Gradient는 방어 기법이 적대적 예제를 생성하는 최적화 과정에서 기울기를 구할 수 없게 만들거나(미분 불가능하도록) 부정확하게 만드는 현상을 가리킵니다. 이 현상은 방어 기법이 미분 가능한 수식만을 사용하더라도 의도치 않게 발생할 수 있으며, 이러한 경우 기울기 기반 공격이 분류 손실(Classification Loss)을 전역 최댓값으로 끌어올리지 못하는 경우에 나타납니다.
2. Stochastic Gradient Stochastic Gradient는 랜덤화된 방어 기법으로 인해 기울기가 확률적으로 변동하는 현상을 가리킵니다. 일부 방어 기법들은 신경망 구조에 무작위성을 주입하거나 입력 이미지를 무작위로 변형(Transform)하는 방식을 사용하는데, 이로 인해 공격자가 역전파로 기울기를 계산할 때 그 값 역시 무작위하게 변하게 됩니다. 결과적으로 적대적 예제 생성에 필요한 실제 기울기를 정확히 추정하기 어렵게 만듭니다.
3. Vanishing/Exploding Gradient Vanishing/Exploding Gradient는 방어 기법이 신경망 연산을 반복적으로 수행하는 구조를 가질 때 발생합니다. 공격자가 이러한 모델에서 기울기를 계산하려면 반복적인 연산 루프를 펼쳐서 계산해야 하는데, 이는 매우 깊은 신경망의 기울기를 계산하는 것과 동일한 상황이 됩니다. 이 과정에서 기울기 값이 연속적으로 곱해지면서 0으로 수렴하거나 극단적으로 커지는 현상이 발생합니다.
Identifying Obfuscated Gradients
그렇다면 특정한 방어 기법이 이러한 Obfuscated Gradient 현상에 의해 방어가 성공한 것처럼 보이게 하는지 어떻게 구분할 수 있을까요? 논문에서는 Obfuscated Gradient 현상을 이용한 방어 기법의 5가지 특징들을 제시합니다.
- 단일 스텝의 공격이 반복적인 최적화를 거치는 공격보다 더 성능이 좋은 경우
- Black-box 공격이 white-box 공격보다 성능이 더 좋은 경우
- 노이즈에 대한 제약이 없을 때, 공격이 100%의 성공률을 달성하지 못하는 경우
- 무작위로 샘플링된 노이즈가 적대적 예제로 발견되는 경우
- 노이즈에 대한 제약을 약화했을 때, 공격 성공률 향상이 없는 경우
이 중 하나라도 해당된다면, 해당하는 방어 기법이 Obfuscated Gradient 현상을 유발하고 있을 가능성이 매우 높다고 판단해야 합니다.
Attack Techniques
저자들은 3가지의 Obfuscated gradients 현상이 나타나는 방어기법들을 각각 우회하는 공격 기법을 제안합니다.
Backward Pass Differentiable Approximation Shattered Gradient 현상, 즉 미분 불가능한 연산을 사용해 기울기를 쉽게 구할 수 없도록 만드는 방어 기법을 우회하기 위해서, 저자들은 Backward Pass Differentiable Approximation(BPDA)라는 방법을 제안합니다. 이 방식은 신경망 내부에 미분이 불가능한 특정 계층 \(f^i(\cdot)\)가 존재할 때, 기울기값을 계산하기 위해 \(f^i(\cdot)\)와 결과값이 비슷하게 나오면서도 미분 가능한 근사 함수 \(g(x)\)를 구합니다 (\(g(x) \approx f^i(x)\)). 여기서 근사 함수는 공격 기법마다 다르게 알맞는 근사 함수를 찾아야 합니다. 근사 함수를 찾은 뒤, 순전파는 원래의 함수인 \(f^i(\cdot)\)로 진행하고, 역전파 시에만 근사함수를 사용하여 기울기를 계산합니다.
Expectation over Transformation 입력값을 무작위로 변형하거나, 신경망 구조에 무작위성을 주입하여 생기는 현상인 Stochastic gradients 현상을 우회하기 위해, 저자들은 Expectation over Transformation(EOT)이라는 방법을 제안합니다. 이 방식의 핵심 아이디어는, 가능한 여러 무작위 변환들의 기댓값을 구하여 최적화하자는 것입니다. 수학적으로 살펴보면, 모델 \(f(x)\)에 대한 변환 분포 \(T\)에서 뽑은 무작위 변환 \(t(x)\)가 적용될 때, EOT는 전체 변환에 대한 기댓값인 \(\mathbb{E}_{t \sim T} f(t(x))\)를 최적화합니다. 이 기댓값의 미분은, 미분 값들과 수학적으로 동일합니다. 수식으로 표현하면 다음과 같습니다. \(\nabla \mathbb{E}_{t \sim T} f(t(x)) = \mathbb{E}_{t \sim T} \nabla f(t(x))\)
즉, 무작위 변환이 적용된 각각의 상태에서 기울기를 개별적으로 먼저 구한 뒤 그것들의 평균(기댓값)을 내면 정확한 기울기 방향을 알아낼 수 있다는 뜻입니다.
Reparameterization
입력값을 정제하기 위해 내부적으로 여러 번의 최적화 루프를 도는 방어 함수 \(g(\cdot)\)을 포함한 모델은 \(f(g(x))\)로 표현할 수 있습니다.
\(g(\cdot)\)는 입력값을 정제해 원하는 형태로 만드는데, 적대적 예제 생성을 위해 \(f(g(x))\)의 기울기를 역전파해서 계산하면 기울기가 소실되거나 폭발하게 되는 현상이 나타납니다.
이러한 방어 기법을 우회하기 위해, 저자들은 Reparameterization이라는 방법을 제안합니다.
저자들은 \(g(x)\)를 미분하는 대신, \(x = h(z)\)라는 새로운 미분 가능한 변환 함수 \(h(\cdot)\)를 구합니다. 이 함수는 다음 조건을 만족하도록 설계됩니다.
\[g(h(z)) = h(z)\]이 수식이 의미하는 바는, 함수 \(g(\cdot)\)가 입력값을 특정 매니폴드로 투영할 때, \(h(z)\)는 처음부터 그 매니폴드 위의 값을 출력하도록 설계된다는 것입니다. 이를 통해 \(f(h(x))\)를 미분하여 역전파 시 최적의 기울기를 찾을 수 있게 만들어, 방어 기법을 우회합니다.
Case study
앞서 제안한 방법들로, 저자들은 ICLR 2018에 게재된 9개의 최신 방어 기법들에 대한 우회를 시도하였습니다. 그 결과는 다음 표와 같습니다.
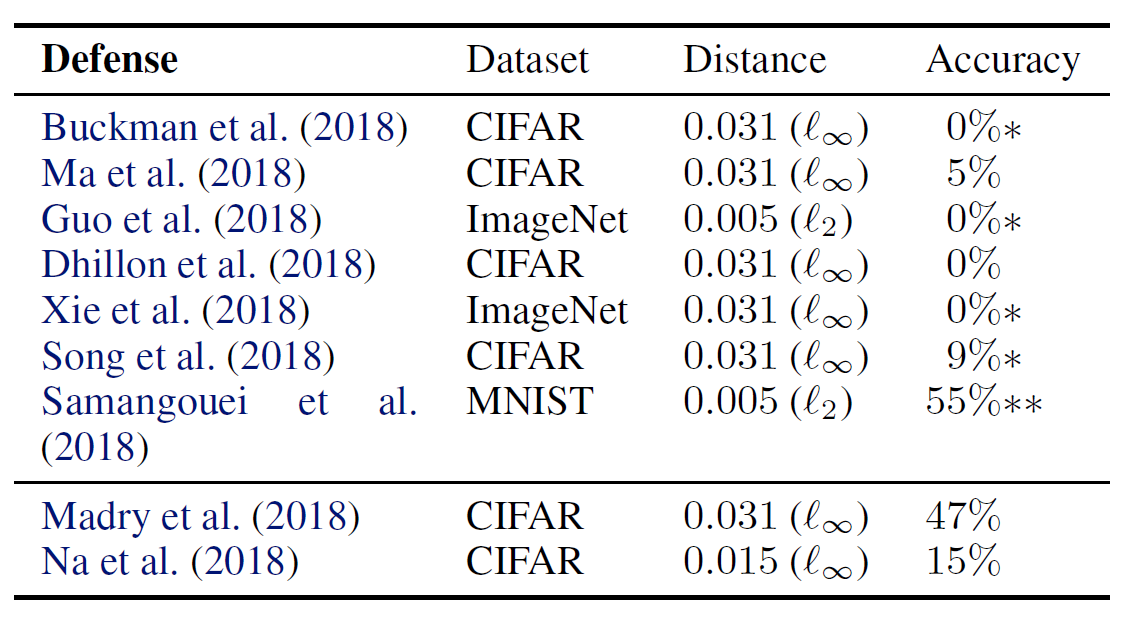
- 표의 가장 우측에 있는 Accuracy는 우회 공격 후 해당 방어 모델이 정답을 맞힌 비율, 즉 최종적으로 살아남은 방어율을 의미합니다.
- 별표 1개(* ) :해당 방어 기법들은 원본 논문에서 적대적 훈련(Adversarial Training)과 결합하여 사용할 것을 제안했으나, 이 표에서는 다른 요소를 배제하고 해당 방어 기법 단독의 방어력만을 평가했음을 의미합니다
- 별표 2개(**): 기법의 근본적인 원리상으로는 정확도가 0%로 완전히 뚫려야 맞지만, 실제 공격 시 최적화 과정의 불완전성(imperfections) 때문에 이론적으로 완벽한 공격이 실패하여 일부 방어 정확도가 남았음을 의미합니다.
표를 보면 9개의 공격 방법 중 7개 방법이 Obfuscated Gradient 현상을 이용하였고, 방어 우회 기법으로 방어가 완벽하게 파훼되었음을 알 수 있습니다.
Non-obfuscated Gradients 표 기준으로 아래 두 개의 방어 기법은 Obfuscated Gradient 현상을 이용하지 않은 방어 방법들, 즉 방어 우회 기법이 실패한 기법들입니다.
먼저 Madry et al. (2018)이 제안한 방어 방식은 가장 위협적인 적대적 예제를 생성하도록 최적화하는 동시에, 모델은 그 가장 위협적인 적대적 예제에 대해 손실을 최소화하는 min-max 게임 형식의 적대적 훈련(Adversarial Training) 방식입니다. 이 방식은 Obfuscated Gradient 현상을 사용한 방어 기법이 아니기 때문에, 이 논문에서 제안하는 공격 기법으로 방어를 뚫어내지 못하였습니다.
Na et al.의 기법은, 먼저 첫 번째 모델을 훈련시킨 뒤 반복적 공격을 통해 적대적 예제들을 만들어 훈련 데이터셋에 추가하고, 이 확장된 데이터셋을 바탕으로 두 번째 모델을 훈련시킵니다. 이때 원본 이미지와 적대적 예제의 결과값(Logit)이 서로 비슷해지도록 강제하는 통합 임베딩 기술을 적용합니다.
이 방식도 Obfuscated Gradient 현상을 사용한 방어 기법이 아니지만, 원저자들이 이미 강력한 최적화 기반 공격을 상대로 방어의 정확도를 보수적으로 측정했기 때문에 저자들의 우회 공격으로도 원래 주장했던 방어력 밑으로 떨어지지 않았습니다.
이 두 가지 방법을 제외한 7가지 방어기법은 이 논문에서 완벽하게 파훼하였습니다. 논문에서는 이 7가지 방어 기법을 모두 뚫어내는 자세한 방법을 모두 서술하고 있지만, 이 글에서는 기울기 난독화의 3가지 유형별로 한가지 사례씩 방어 기법의 원리와 파훼 방법에 대해 살펴보겠습니다.
Gradient Shattering 이 현상이 발생하는 공격의 대표적인 예시는, Thermometer encoding을 이용한 방어 방법입니다. 모델이 디지털 이미지를 처리할 때에, 픽셀의 색상 값을 0과 1 사이의 연속적인 실수로 처리합니다. 이전 연구에서, 이러한 선형적인 특성이 적대적 공격에 모델을 취약하게 만든다고 밝혔고, 이 방어 기법을 사용하는 저자들은 0부터 1 사이의 실수를 이산적인 형태의 \(l\)-차원 벡터로 쪼개어 변환합니다.
예를 들어, 0.66이라는 픽셀 값이 들어오면 이를 10 칸짜리 눈금으로 “1111110000”와 같은 이산적인 형태의 벡터로 변환합니다. 이 방식을 사용하면, 내림 연산을 사용하여 부드럽게 이어지지 않고 값이 끊기게 되어 수식이 수학적으로 미분이 불가능해집니다. 따라서 Gradient shattering 현상이 일어나게 되며, 적대적 공격에 대한 방어가 성공한 것 처럼 보입니다.
이 논문에서 Gradient shattering 현상을 해결하기 위해, 전에 소개했던 방식인 BPDA 방식을 이용하여 역전파 시 미분이 가능한 근사함수를 만들어 기울기를 구해내어, 적대적 예제에 대한 정확도를 0%까지 떨어뜨리며 해당 방어 기법을 무력화했습니다.
Stochastic Gradients 인공지능 모델 내부에 무작위성을 부여하여 적대적 공격에 대한 방어를 시도한 기법 중 하나는 SAP(Dhillon et al.) 방식을 활용한 방어기법입니다. 해당 논문의 저자들은, 추론 단계에서 각 계층의 뉴런의 값을 확률적으로 0으로 떨어뜨려 비활성화시키면, 적대적 공격을 생성 할 때 최적화하는 과정에서 매번 기울기가 다르게 나오게됩니다.
이러한 Stochastic Gradients 현상을 막기 위해, 이 논문에서는 변환에 대한 기댓값(Expectation of Transformation)을 계산하여 기울기를 추정하였습니다. 경사 하강법(gradient descent)의 반복 단계에서, 단일 기울기 방향으로 한 걸음 이동하지 않고, 기댓값의 방향으로 이동합니다. 이 방법을 사용한 결과, 최대 허용 노이즈 \(\epsilon = 0.031\)인 환경에서 적대적 예제에 대한 정확도를 0 %까지 떨어뜨렸습니다.
Vanishing & Exploding Gradients Defense-GAN(Samangouei et al., 2018)은 GAN을 활용한 방어 기법입니다. 핵심 아이디어는 이미지를 분류기에 입력하기 전에, 먼저 깨끗한 이미지들의 공간(manifold) 위로 투영한 뒤 분류기에 전달하는 것입니다. 적대적 예제는 이 공간을 살짝 벗어난 곳에 위치하기 때문에, 매니폴드 위로 다시 투영하면 적대적 perturbation이 제거될 것이라는 아이디어입니다. Defense-GAN은 GAN의 Generator를 이용해 이 manifold를 정의합니다. 입력 이미지가 주어지면, 최적화 문제를 풀어 manifold 위의 가장 가까운 점을 찾습니다. 이 과정에서 반복적인 최적화 루프를 돌기 때문에, 공격자가 적대적 예제를 생성하기 위해 기울기 계산을 시도하면, 기울기가 0으로 수렴하거나 폭발하게 되는 상황이 발생했습니다.
이 논문의 저자들은 이 깊은 최적화 루프를 우회하기 위해, 원본 이미지를 잠재 공간 \(z\)로 치환하는 매개변수 재설정(Reparameterization) 기법을 사용했습니다. 즉, 애초에 manifold 위에 존재하는 적대적 예제를 만든 것입니다. 즉, \(x′=G(z)\) 의 형태로 표현되지만 \(c(x)≠c(x′)\)를 만족하는 적대적 예제를 직접 구성하였습니다. 이러한 예제는 이미 manifold 위에 존재하므로 투영 과정을 거쳐도 수정되지 않고 분류기에 전달됩니다.
또한 Defense-GAN이 이미지를 투영하기 위해 사용하는 경사 하강법 기반의 최적화 과정이 불완전하여 manifold 위의 점을 완벽하게 보존하지 못한다는 문제가 있었습니다. 이에, 저자들은 복잡한 투영 과정을 단순한 근사 함수로 대체하는 BPDA 기법을 추가로 사용했습니다.
결과적으로 저자들은 Defense-GAN을 상대로 45%의 공격 성공률을 달성했으며 방어 기법 자체의 불완전한 구현 덕분에 방어가 0%로 완전히 붕괴되지 않았다고 서술하고 있습니다.
결론
이 논문은 기존에 제안된 여러 적대적 예제에 대한 방어 기법들이, 사실은 방어에 성공한 것처럼 보이게 하는 Obfuscated Gradients 현상에 의존하고 있었으며, 그러한 취약한 방어 방식을 사용하는 케이스들을 분석하여 무력화하는 기법들을 제시하였습니다. 나아가 앞으로 방어 기법들이 갖추어야 할 요건들에 대한 가이드라인을 제공합니다.
첫째, 방어자는 현실적이고 명확한 위협 모델을 설정하고 공격자가 어떤 정보를 알고 있는지 정확히 명시해야합니다. 둘째, 방어 기법이 구체적이며 실험을 통해 검증 가능해야합니다. 셋째, 방어 기법을 우회할 수 있는 적응형 공격을 고안하고 그것을 사용해서 방어 기법 우회를 시도해봐야 합니다.
이러한 조건들을 다 갖추어야만 적대적 공격을 방어할 수 있는 방어 기법이라고 할 수 있으며, Obfuscated Gradients 현상에 의존하면 안 된다고 주장하며 논문을 마무리합니다.