논문명: Towards Deep Learning Models Resistant to Adversarial Attacks
저자: Aleksander Mądry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, Adrian Vladu
게재지: ICLR 2018
URL: Towards Deep Learning Models Resistant to Adversarial Attacks
서론
최근 딥러닝 모델은 자율주행, 얼굴 인식, 악성코드 탐지 등 보안이 필수적인 시스템에 점차 통합되고 있습니다. 하지만 이러한 심층 신경망(Deep Neural Networks)은 자연 데이터와 거의 구별할 수 없음에도 불구하고 모델이 오분류를 일으키도록 미세하게 조작된 적대적 예제(Adversarial Examples)에 매우 취약하다는 치명적인 약점이 존재합니다. 컴퓨터 비전 분야에서는 사람의 눈에 띄지 않는 아주 작은 픽셀 변화만으로도 최첨단 신경망을 높은 신뢰도로 속일 수 있습니다.
본 논문은 특정 공격만을 방어하는 기존의 휴리스틱한 접근을 넘어섭니다. 대신 강건한 최적화(Robust Optimization) 관점을 통해 적대적 강건성(Adversarial Robustness)을 수학적으로 엄밀하게 정의하고, 광범위한 1차 미분(First-order) 공격에 대해 보편적인 방어력을 갖춘 네트워크 학습 방법론을 제안합니다.
강건한 최적화 모델링 (Robust Optimization Modeling)
안장점 공식 (Saddle Point Formulation)
이 논문의 핵심은 적대적 방어 문제를 다음과 같은 자연스러운 안장점(Saddle Point) 공식으로 정의한 것입니다. 기존의 경험적 위험 최소화(Empirical Risk Minimization) 대신, 공격자가 허용된 섭동(Perturbation) 집합 $\mathcal{S}$ 내에서 데이터 $x$를 조작할 수 있도록 허용하고 그 최악의 상황에서의 손실을 최소화합니다.
\[\min_{\theta} \rho(\theta), \text{ where } \rho(\theta) = \mathbb{E}_{(x,y)\sim\mathcal{D}} \left[ \max_{\delta \in \mathcal{S}} L(\theta, x+\delta, y) \right]\]이 공식은 두 가지 명확한 최적화 문제로 나눌 수 있습니다:
- 내부 최대화 (Inner Maximization): 주어진 데이터 포인트에 대해 가장 높은 손실을 달성하는 적대적 예제($x+\delta$)를 찾는 과정으로, 신경망에 대한 ‘공격(Attack)’을 의미합니다.
- 외부 최소화 (Outer Minimization): 내부 공격 문제에서 얻어진 ‘적대적 손실’이 최소화되도록 모델 파라미터($\theta$)를 찾는 과정으로, 강건한 분류기를 학습하는 ‘방어(Defense)’를 의미합니다.
Danskin의 정리와 수식 유도 (Danskin’s Theorem and Formula Derivation)
위의 안장점 문제를 학습(최적화)하기 위해서는 파라미터 $\theta$에 대한 기울기(Gradient)를 계산해야 합니다. 논문은 최적화 이론의 고전적인 정리인 Danskin의 정리(Danskin’s Theorem)를 적용합니다. 이에 따라, 내부 함수를 최대화하는 최적의 적대적 섭동을 $\delta^*$라고 할 때, 기울기는 다음과 같이 계산됩니다.
\[\nabla_{\theta} \max_{\delta \in \mathcal{S}} L(\theta, x+\delta, y) = \nabla_{\theta} L(\theta, x+\delta^*, y)\]엄밀히 말해 ReLU를 사용하는 신경망은 연속적으로 미분 가능하지 않아 Danskin 정리의 가정을 완벽히 만족하지는 않습니다. 하지만 실험적으로 확률적 경사 하강법(SGD)을 적용했을 때 손실이 일관되게 감소함을 확인하여, 이 방법이 실증적으로 매우 신뢰할 수 있음을 보였습니다.
방어 메커니즘과 모델 특성 (Defense Mechanisms and Model Properties)
적대적 예제의 손실 지형 (The Landscape of Adversarial Examples)
이 논문의 가장 중요한 기여 중 하나는 비오목(Non-concave) 함수인 내부 최대화 문제의 손실 지형(Loss Landscape)을 실험적으로 분석한 것입니다.
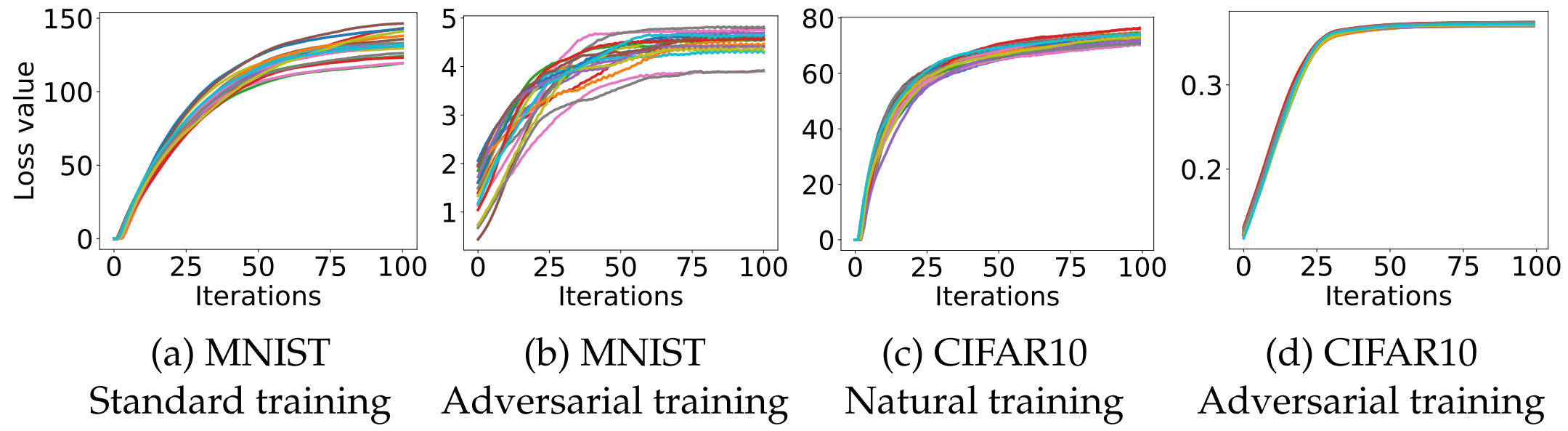
허용된 $l_\infty$-ball 내부의 수많은 무작위 시작점(Random Restarts)에서 PGD 연산을 수행한 결과, 손실 값이 매우 빠르게 정체기(Plateau)에 도달함을 관찰했습니다.
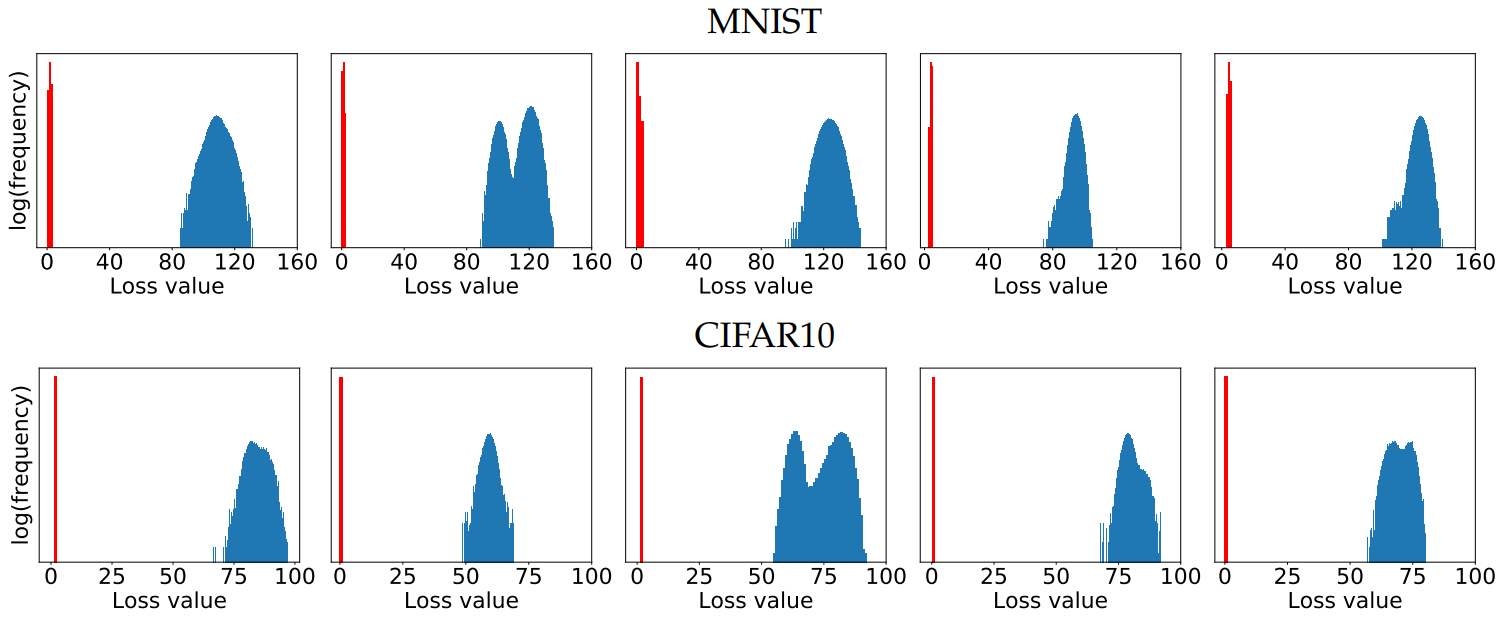
수많은 국소적 최대값(Local Maxima)들이 존재하지만, 위 히스토그램에서 볼 수 있듯 이 손실 값(Loss values)들은 극단적인 이상치 없이 놀라울 정도로 잘 집중(Concentrated)되어 있음을 확인했습니다. 이는 1차 미분(First-order) 방법만으로도 내부 최적화 문제를 충분히 잘 풀 수 있음을 시사합니다.
1차 미분 기반 공격과 PGD (First-Order Adversaries and PGD)
위의 발견에 따라 논문은 투영된 경사 하강법(Projected Gradient Descent, PGD)을 1차 미분 정보만을 활용하는 가장 강력하고 보편적인 공격자(Universal First-order Adversary)로 정의합니다. PGD 공격의 수식은 다음과 같습니다.
\[x^{t+1} = \Pi_{x+\mathcal{S}} \left( x^t + \alpha \text{ sgn}(\nabla_x L(\theta, x, y)) \right)\]모델이 이 PGD 공격을 방어할 수 있도록 훈련된다면, 유사한 1차 미분 정보를 활용하는 다른 모든 공격 방법론들(예: FGSM 등)에 대해서도 범용적인 방어력을 갖추게 됩니다.
네트워크 용량의 중요성 (Importance of Network Capacity)
안장점 문제를 PGD를 이용해 해결하는 것만으로는 완벽하지 않으며, 분류기 모델의 구조적 용량(Capacity)이 방어 성능에 결정적인 역할을 합니다.
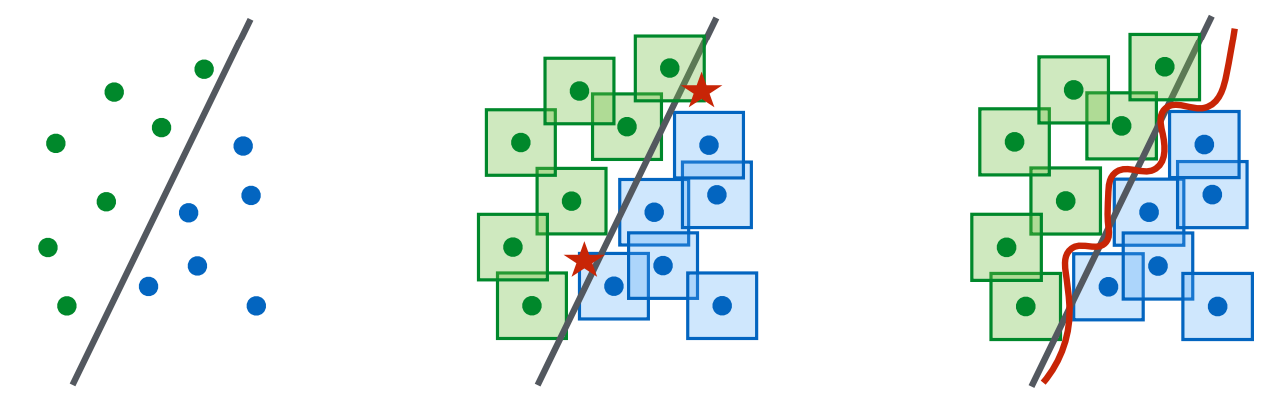
- 복잡한 결정 경계 요구: $\mathcal{S}$($l_\infty$-ball 등) 내부의 모든 조작된 적대적 예제를 방어하려면, 각 데이터 주변의 섭동 허용 영역이 교차하지 않도록 훨씬 더 복잡하고 정교한 결정 경계(Decision Boundary)가 요구됩니다. 따라서 적대적 공격을 견뎌내기 위해서는 훨씬 더 큰 파라미터 용량(Capacity)이 필요합니다.
- 약한 모델의 한계: 용량이 부족한 네트워크는 강력한 PGD 공격에 대해 훈련시킬 경우, 의미 있는 특징을 학습하지 못하고 무조건 고정된 특정 클래스만 예측하는 현상이 발생합니다.
- FGSM 학습의 레이블 누출(Label Leaking): 큰 $\epsilon$ 환경에서 단순히 1-step인 FGSM으로만 학습시키면, 모델이 FGSM이 만드는 매우 제한적인 형태의 적대적 예제에만 과적합(Overfitting)되어버리는 문제가 발생합니다.
적대적 예제의 전이성 (Transferability)
특정 모델(Source)을 겨냥해 생성된 적대적 예제가 전혀 다른 독립적인 타겟 모델(Target)에서도 오분류를 유발하는 전이성(Transferability) 현상 역시 깊이 있게 분석되었습니다.
- 강력한 공격자를 통한 학습: 단순한 FGSM이 아닌 강력한 PGD를 상대로 적대적 훈련(Adversarial Training)을 수행하면 전이 공격의 성공률이 크게 감소합니다.
- 네트워크 용량 증가: 모델의 용량(Capacity)을 늘릴수록 소스 모델과 전이 모델 간의 기울기(Gradient) 상관관계가 뚜렷하게 줄어들어 전이 공격 방어에 효과적입니다.
강건한 모델의 내부 분석 (MNIST Inspection)
논문은 부록(Appendix C)을 통해 적대적으로 학습된 모델이 내부에서 어떤 방식으로 방어력을 획득했는지 분석합니다.
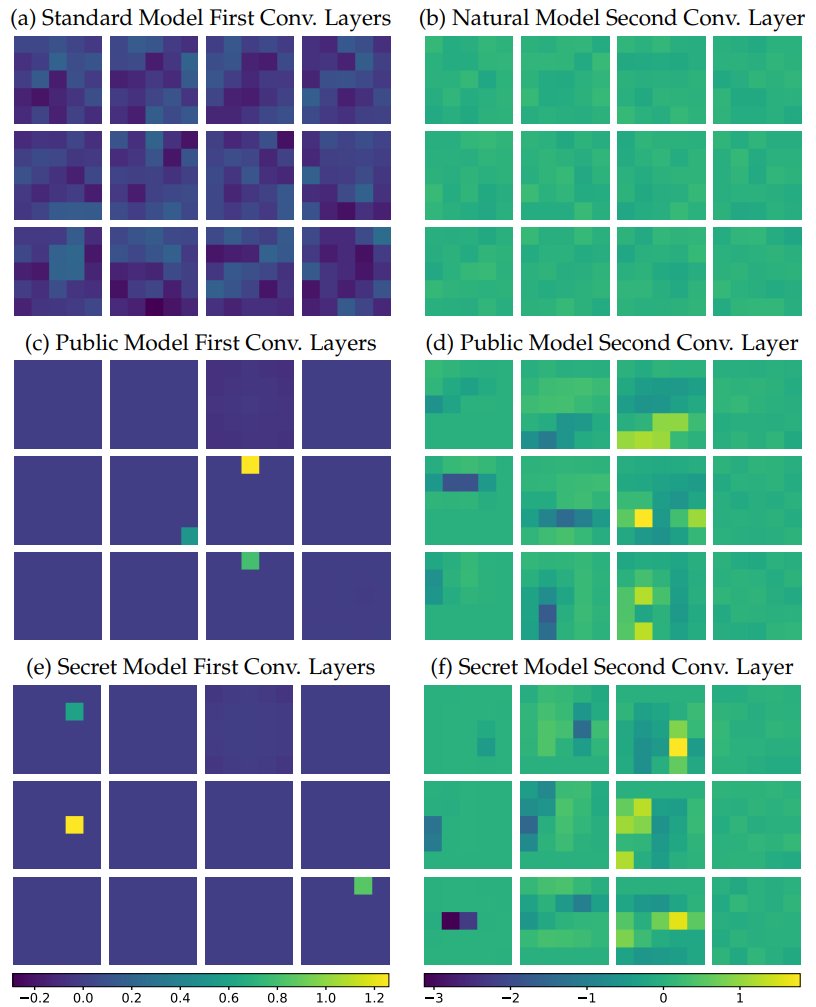
- 임계값 필터(Thresholding Filters)의 학습: 모델의 첫 번째 합성곱 층(그림의 왼쪽 열)의 가중치를 살펴보면, 적대적 학습 모델은 단 3개의 필터만 남고 가중치가 매우 희소(Sparse)해졌습니다. 이는 특정 픽셀 변화에는 반응하지 않는 임계값 필터 역할을 학습했음을 의미합니다.
- 보수적인 편향(Conservative Biases): 마지막 Softmax 층의 편향을 분석해보면, 적대적 섭동에 특히 취약한 특정 클래스들에 대해 예측을 주저하도록(Conservative) 편향 값을 불균일하게 스스로 조정했습니다.
실험 결과 및 한계점 (Experiments and Limitations)
연구진은 PGD 적대적 학습(Adversarial Training)을 수행한 후, 강력한 환경 지표 아래에서 성능을 평가했습니다.
- 성공적인 방어: 섭동 허용치 $\epsilon=0.3$으로 학습한 MNIST 데이터셋에서, 가장 강력한 화이트박스 공격에 대해서도 89.3% 이상의 방어력을 달성했습니다. $\epsilon=8$로 학습한 CIFAR10 모델 역시 블랙박스 전이 공격에 대해 64% 이상이라는 전례 없는 우수한 방어력을 확보했습니다. 이는 최적화 기반의 Carlini-Wagner (CW) 공격에 대해서도 유효했습니다.
기울기 마스킹과 방어의 한계 (Gradient Masking & Limitations)
하지만 논문은 스스로 이 방법론의 한계점도 명확히 밝힙니다. $l_\infty$ 노름(Norm) 제한 환경에서 훈련된 모델이 $l_2$ 노름 기반 공격에 직면했을 때, 초기에는 견고해 보였으나 이는 앞서 분석한 ‘임계값 필터’가 기울기 마스킹(Gradient Masking)을 유발하여 연산을 방해했기 때문이었습니다. 모델의 기울기를 사용하지 않는 결정 기반 공격(Decision-Based Attack)을 적용해본 결과 $l_2$ 공격에 대한 방어력은 상당히 취약함이 드러났습니다.
결론적으로, 본 논문은 무한해 보이는 적대적 공격의 탐색 공간이 실제로는 1차 미분 최적화 관점에서 통제 가능함을 밝혔으며, 강력한 PGD 공격자의 활용과 충분한 네트워크 용량의 결합이 딥러닝 모델의 근본적인 적대적 강건성을 확보하는 핵심 열쇠임을 입증하였습니다.