논문명: Prediction Poisoning: towards defenses against DNN model stealing attacks
저자: Tribhuvanesh Orekondy, Bernt Schiele, Mario Fritz
게재지: 2020 The International Conference on Learning Representations (ICLR)
URL: Prediction Poisoning: towards defenses against DNN model stealing attacks
서론
딥러닝 모델은 음성 비서, 자율주행, 클라우드 API 등 다양한 실생활 서비스에 활용되며, 개발에는 막대한 비용과 시간이 소요됩니다. 따라서 이러한 모델은 기업의 핵심 자산이며, 외부 도난에 대한 방어가 필수적입니다.
모델 스틸링(model stealing)은 공격자가 모델에 반복적으로 쿼리를 보내 응답을 수집하고, 이를 학습에 활용해 복제 모델을 만드는 공격입니다. 최근 연구들은 딥러닝 모델조차도 블랙 박스 환경에서 저비용으로 복제될 수 있음을 보여주었습니다.
기존 방어 방식은 크게 두 가지입니다:
- 공격자의 쿼리 패턴을 감지
- 모델의 출력 확률을 일부 왜곡하여 방해
그러나 실제로는 Top-1 결과만으로도 충분히 공격이 가능하며, 기존 방식들은 공격자를 완전히 차단하지 못하거나 정상 정확도에 큰 손실을 초래합니다.
본 논문에서는 이러한 한계를 극복하기 위해, 예측 오염(Prediction Poisoning)이라는 새로운 방어 전략을 제안합니다. 핵심 아이디어는 공격자가 복제 모델을 학습할 때 사용하는 예측 결과 자체를 교란(pertubation)하여 정상 사용자는 영향받지 않으면서도 공격자의 복제 모델은 잘못된 학습을 하게 만드는 것입니다.
제안된 방법은 간단한 구조와 적은 자원 소모만으로 기존 분류 모델에 쉽게 적용 가능하며, 실험 결과 기존 방어 대비 더 적은 왜곡으로 더 큰 방어 효과를 달성했습니다:
사전지식
-
Jacobian-based attacks 공격자는 복제 모델의 기울기 정보를 이용해 공격용 샘플을 생성함으로써 목표 모델을 효과적으로 복제할 수 있습니다. 이 계열의 대표적인 공격은 다음과 같습니다:
- JBDA (Jacobian-Based Data Augmentation; Papernot et al. 2017) 초기 소량의 라벨링된 데이터로 복제 모델을 학습한 후, 기울기 방향으로 교란(perbutaion)을 추가한 합성 데이터를 생성·활용하여 공격 효율을 높이는 기법입니다.
- JB-self (Juuti et al. 2019) 목표 모델의 Top-1 예측 결과만을 정답처럼 사용하여 합성 데이터를 생성하는 방식으로 실제 라벨 없이도 공격이 가능하며, 완전한 black-box 환경에 적합합니다.
- JB-top3 (Juuti et al. 2019) Top-3 예측 클래스까지 고려하여 기울기 방향을 생성, 더 풍부한 클래스 정보를 반영하여 복제 모델의 성능을 향상시키는 기법입니다.
-
Knockoff Nets (Orekondy et al. 2019) OpenImg, ILSVRC와 같은 실제 이미지들을 목표 모델에 쿼리하여 얻은 응답을 기반으로 복제 모델을 학습할 데이터셋을 샘플링 후 학습하는 공격 기법입니다.
-
기존 방어기법 기존 방어 방식은 주로 출력 확률(softmax posterior)을 조작하거나 노이즈를 추가하여 공격을 방해하려 합니다. 하지만 대부분 정확도를 유지하면서 공격자 성능을 떨어뜨리는 데에는 한계가 있습니다.
- Top-k truncation 소프트맥스(softmax) 확률 중 상위 k개만 출력하고 나머지는 제거하여 정보 유출을 최소화합니다. (예: top-1 argmax만 반환)
- Rounding 소프트맥스 출력을 소수점 아래 자릿수를 줄여서 부정확하게 보여줍니다. (예: 0.923 → 0.92)
- Reverse-sigmoid (Taesung Lee et al. 2018) 소프트맥스 확률 분포를 비선형적으로 변형시켜, top-1 결과는 유지하되 낮은 확률 값들에 불확실성 부여하는 방어 기법입니다.
- Random noise (John Duchi et al. 2008) 출력 확률 벡터에 무작위 노이즈를 추가해 복제 모델의 학습이 어려워지게 합니다. 노이즈의 정도가 커질수록 정확도의 손실도 함께 발생합니다.
- DP-SGD (Martin Abdai et al. 2016) 모델 훈련 단계에서부터 기울기에 노이즈를 섞고 클리핑(clipping)하여 모델 파라미터 자체에 불확실성을 부여하여 학습 데이터의 유출을 막는 방어 기법입니다.
본론
목표
본 방어의 목적은 두 가지로 요약됩니다:
- 유틸리티(Utility): 정상 사용자에 대한 예측의 품질은 유지되어야 합니다.
- 복제 불가능성(Non0replicability): 공격자가 목표 모델을 복제할 수 있는 능력을 감소시켜 복제 모델의 성능을 떨어뜨립니다.
Maximizing Angular Deviation(MAD)
본 논문은 공격자가 복제 모델의 학습에 사용하는 기울기(gradient) 방향을 교란함으로써 학습을 방해하는 새로운 방어 기법, MAD(Maximazing Angular Deviation)을 제안합니다.
아래는 방어 과정을 표현하는 간단한 도식입니다:

-
1차 근사(First-order Approximation) 겨냥
공격자는 목표 모델의 예측 \(y\)를 목표로 복제 모델\(F_A(x;w)\)의 파라미터 \(w\)를 조정하여 손실을 최소화 하려합니다. 이 때, 대부분의 최적화는 아래와 같이 손실에 대한 파라미터의 기울기(1차 근사)를 이용합니다: \(\begin{align} u = -\nabla_w\mathcal{L}(F(x;w),y) \end{align}\) 공격자는 이 기울기 방향을 따라 복제 모델을 학습합니다.
-
핵심 아이디어
MAD는 목표 모델의 출력을 \(\tilde{y}\)로 교란하여 공격자가 다음과 같은 기울기 정보를 얻도록 합니다: \(\begin{align} a = -\nabla_w\mathcal{L}(F(x;w),\tilde{y}) \end{align}\)
그리고 이렇게 교란된 기울기의 정보 \(a\)가 기존의 기울기 정보 \(u\)와 최대한 달라지도록 만듭니다:
\[\begin{align} \max_{\hat{a}}{\lVert{\hat{a}-\hat{u}}\rVert}_2^2\quad (\hat{a}=a/\lVert{a}\rVert_2,\hat{u}=u/\lVert{u}\rVert_2) \end{align}\]이는 구체적으로 정규화된 방향 간의 거리를 최대화하는 수식으로 나타낼 수 있습니다:
\[\begin{align} \max_\tilde{y} \left\| \frac{G^T\tilde{y}}{\|G^T\tilde{y}\|_2} - \frac{G^T y}{\|G^T y\|_2} \right\|_2^2 \quad (=H(\tilde{y})) \end{align}\]이때 \(G\)는 로그 우도(likelihood)에 대한 파라미터 방향의 jacobian이며 다음과 같이 표현됩니다: \(\begin{align} G = \nabla_w\log{F(x;w)}\quad (G\in\mathbb{R}^{K \times D}) \end{align}\)
\(G\)를 통해 기울기 정보 \(u\)와 \(a\)는 다음과 같이 표현할 수 있습니다: \(\begin{align} u = G^Ty\quad a = G^T\tilde{y} \end{align}\)
-
제약 조건 위 최적화 문제는 다음과 같은 제약들을 포함합니다:
- \(\tilde{y}\)는 확률 simplex 위에 있어야 합니다:
2. 왜곡은 일정 수준 \(\epsilon\)이하로 제한되어야 합니다.(유틸리티 보존):
\[\begin{align} \text{dist}(y,\tilde{y}) \le \epsilon \end{align}\quad \text{(Utility constraint)}\]-
실제 적용의 어려움 및 해결
-
\(G\) 추정 방어자는 공격자의 정확한 모델\(F\) 를 사전에 알 수 없기에 대리(surrogate) 모델 \(F_\text{SUR}\)을 두고 이를 기반으로 \(G = \nabla_w\log{F_\text{SUR}(x;w)}\)을 추정합니다.
이때 대리 모델은 무작위로 초기화 후 학습되지않은 CNN모델을 활용합니다.
-
휴리스틱(Heuristic) 해결
목적 함수\(H(\tilde{y})\)가 비볼록(non-convex)이므로 단순 gradient ascent는 지역 최적해에 빠질 수 있습니다.
따라서 본 논문은 다음 두 단계 전략을 사용합니다:
-
극점(extream point) 탐색
확률 simplex의 정점(one-hot 벡터) \(y^*\) 중 목표 \(H(\tilde{y})\)를 최대화하는 후보를 선택합니다.
-
선형 보간(Interpolation)
기존 확률 분포 \(y\)와 선택한 \(y^*\)를 다음과 같이 선형 보간하여 최종 \(\tilde{y}\)를 만듭니다. \(\begin{align} \tilde{y} = (1-\alpha)y+\alpha y^* \end{align}\)
이때 \(\alpha\)는 위의 왜곡 제약 \(dist(y,\tilde{y}) \le \epsilon\)를 만족하도록 조정합니다.
-
-
-
변형: MAD-argmax
top-1 결과의 정확도를 보존하기 위해 다음과 같은 제약을 추가할 수 있습니다: \(\begin{align} \arg\max_k \tilde{y}_k = \arg\max_k y_k \end{align}\)
실험 설정
-
공격 전략
다음 네 가지 공격을 활용하여 방어의 성능을 평가합니다:
- JBDA
- JB-self
- JB-top3
- Knockoff Nets
공격자는 목표 모델 \(F_V\)에 대해 50,000개의 black-box 질의를 수행하여 pseudo-label을 수집하고, 그로부터 구성된 전이 데이터셋(transfer set)을 사용해 복제 모델 \(F_A\)를 학습합니다.
-
목표 모델 설정
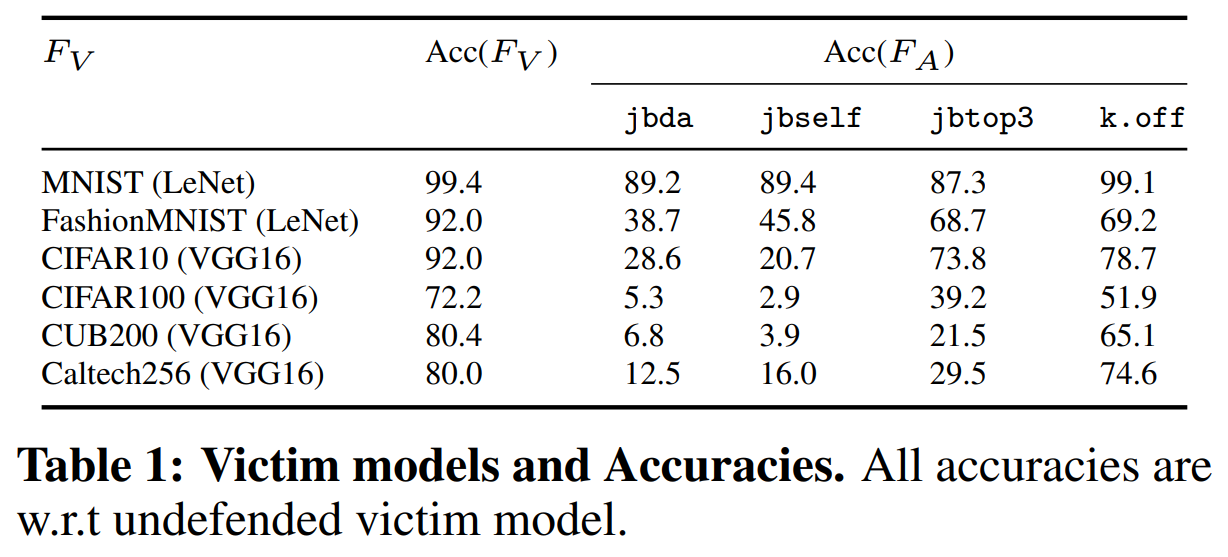
총 여섯 개의 피해 모델을 사용하였으며, LeNet과 VGG16구조를 사용합니다.
다음은 각 모델의 구조와 사용 데이터셋, 원본 모델과 공격 유형별 복제 모델의 정확도입니다.
-
평가 지표
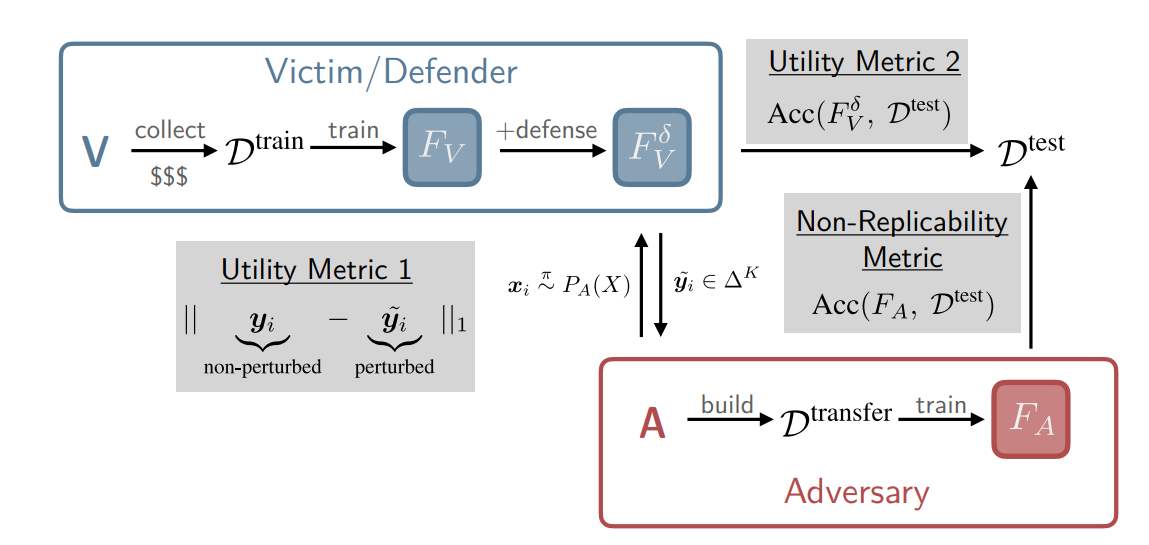
방어의 성능 평가 지표는 다음과 같습니다:
- 복제 불가능성(Non-replicability) 복제 모델 \(F_A\)가 목표 모델 \(F_V\)의 테스트셋\(D^{test}\)에서 달성하는 정확도
-
유틸리티(Utility)
- 정확도 확률 교란이 목표 모델 \(F_V^\delta\)의 테스트셋 \(D^{test}\)에 대한 정확도
- 왜곡 크기 기존 확률 \(y\)와 교란이 적용된 \(\tilde{y}\)의 \(L_1\)거리 \(\left\|y-\tilde{y}\right\|_1\)
각 지표는 전체 파이프라인에 다음과 같이 위치합니다:
-
방어 기준
MAD의 방어 성능 평가 기준이 되는 기법들은 다음과 같습니다:
- Reverse-sigmoid
- Random noise
- DP-SGD
실험 결과
- MAD vs. Attacks
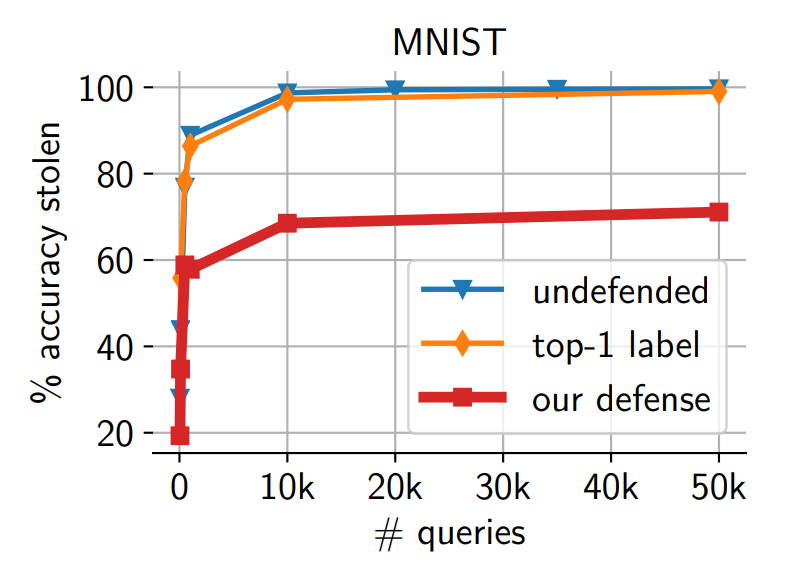
MAD와 MAD-argmax는 모든 공격과 데이터셋에 대해 공격자의 성능을 크게 떨어뜨립니다. 작은 유틸리티 손실만으로도 공격자의 복제력을 크게 저해할 수 있었습니다.
-
MAD vs. baseline
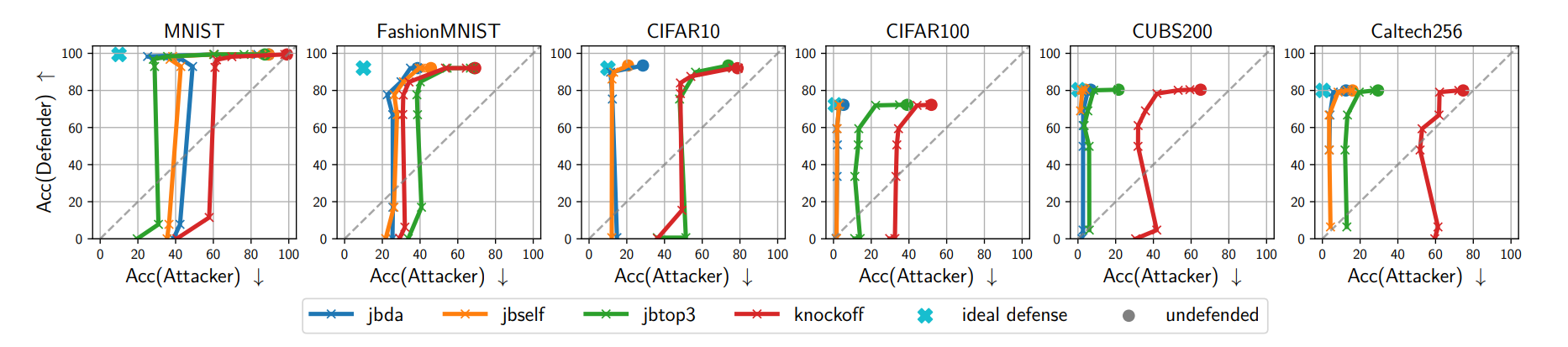
다음은 타 방어 기법 대비 MAD의 성능 비교 결과입니다:
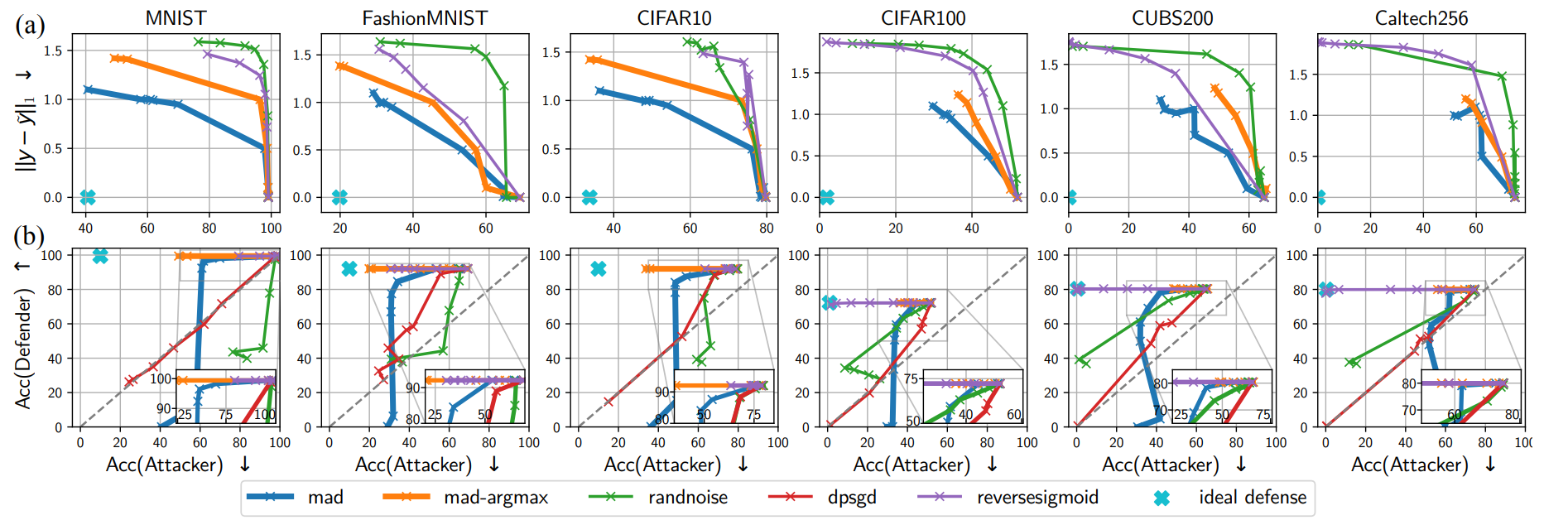
-
\(L_1\)기반 비교(a)
reverse-sigmoid와 random noise도 공격자를 약화시키지만, 동일한 수준의 복제 불가능성을 달성하려면 훨씬 큰 왜곡이 필요했습니다. 반면 MAD 계열 방어는 더 작은 왜곡으로도 동일하거나 더 나은 방어 능력을 보여주었습니다.
-
복제 불가능성 vs 유틸리티(b)
MAD-argmax와 reverse-sigmoid는 top-1을 유지하면서도 공격자 정확도를 20% 이상 떨어뜨렸습니다. DP-SGD나 random noise는 공격자 정확도를 낮추려면 방어 모델의 정확도도 크게 손실되는 반면, MAD는 유사한 억제 정도에서 방어 모델의 정확도 손실이 극히 작았습니다.
-
기울기 방향의 왜곡 분석
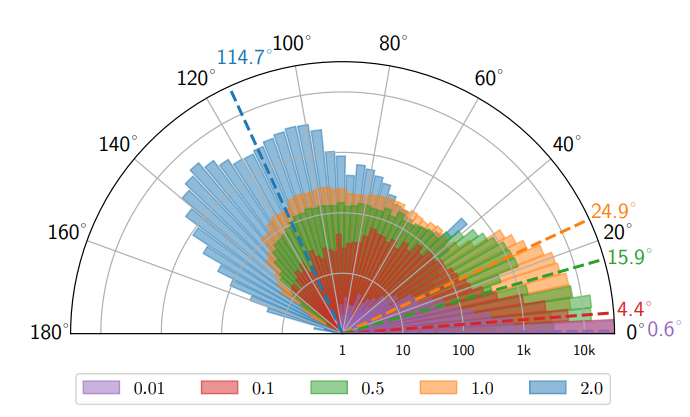
직접적인 기울기의 방향을 추적한 실험에서, 제한된 확률 simplex 내의 교란만으로도 VGG16과 같은 고차원 모델의 기울기를 평균적으로 약 24.9° 비틀 수 있음이 확인되었습니다. 이는 손실의 감소 속도를 늦추어 복제 모델의 학습 효율을 떨어뜨립니다:
- 요소 제거 실험 분석
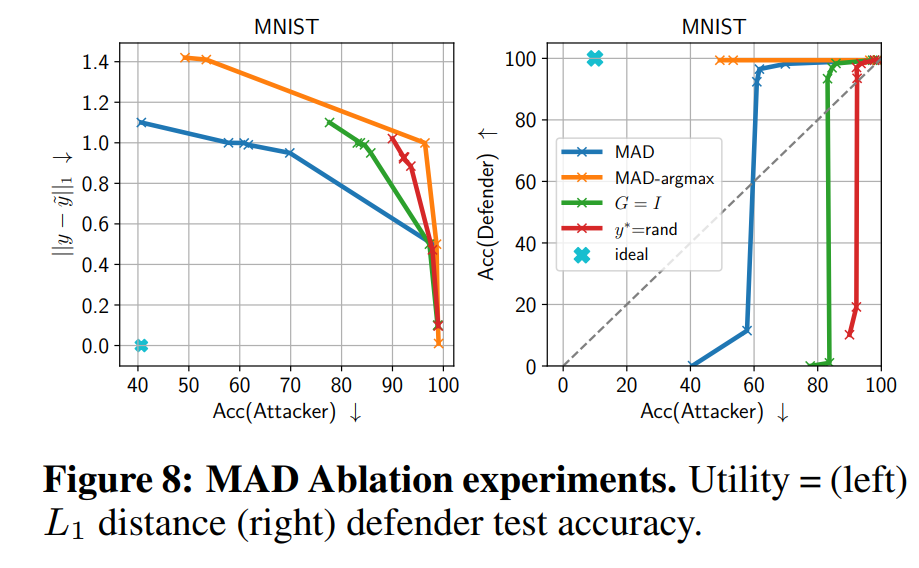
Jacobian을 단위행렬 \(I\)로 대체하거나 무작위 극점을 쓰는 방식과 비교한 결과, 실제 기울기 정보를 활용한 MAD가 가장 뛰어난 성능을 냈습니다. 이는 기울기 기반 설계가 방어의 핵심임을 뒷받침합니다.
- 우회 시도
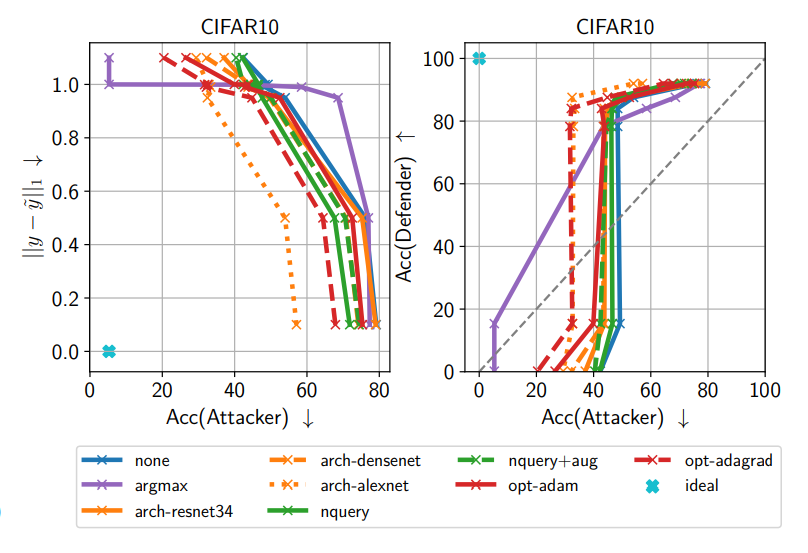
공격자는 argmax-only, 다른 아키텍처와 옵티마이저, 반복 쿼리, 데이터 증강 등 다양한 우회 전략을 시도했습니다. 이 중 가장 위협적인 것은 top-1만 사용하는 argmax-only 학습이었지만, MAD는 이 경우에도 공격자 성능을 원래보다 약 9%포인트 낮출 수 있었습니다.
결론
본 연구에서는 공격자의 학습 목적 자체를 교란하는 능동적 방어인 Prediction Poisoning, 그 중에서도 MAD(Maximizing Angular Deviation)를 제안했습니다. MAD는 여러 모델과 다양한 공격 전략에 대해 일관되게 효과를 보였으며, 공격자의 정확도를 최대 약 65%까지 감소시키는 동시에 방어 모델의 정확도는 거의 유지하여 유틸리티 손실을 최소화했습니다.
이러한 결과는 모델 스틸링 위협에 대해 작은 왜곡으로도 강력한 방어가 가능하다는 것을 보여주며, top-1 기반 공격에 대한 강화, 다른 도메인으로의 일반화 등의 향후 연구 과제를 제안합니다.