논문명: CyBiasBench: Benchmarking Bias in LLM Agents for Cyber-Attack Scenarios
저자: Taein Lim, Seongyong Ju, Munhyeok Kim, Hyunjun Kim, Hoki Kim
게재지: arXiv 2026
서론
대규모 언어 모델(LLM)은 더 이상 한 번 묻고 답하는 도구에 머물지 않습니다. 스스로 도구를 부르고 계획을 세워 긴 작업을 끝까지 끌고 가는 자율 에이전트로 빠르게 진화하고 있습니다. 이런 흐름은 사이버보안에서 특히 두드러집니다. 침투 테스트와 취약점 탐색, 레드팀처럼 직접 공격을 수행하는 일까지 에이전트가 맡기 시작했습니다.
그동안의 평가 벤치마크는 대부분 “에이전트가 공격에 성공했는가”라는 하나의 질문, 곧 공격 성공률(Attack Success Rate, ASR)에 집중해 왔습니다. CTF 과제를 잘게 나눈 Cybench, 실제 CVE를 직접 공략하는 CVE-Bench, 버그 바운티 환경을 재현한 BountyBench가 대표적입니다. 모두 결과만 보던 평가를 한 단계 끌어올린 성과였습니다.
그러나 본 논문은 한 발 더 들어간 질문을 던집니다.
“동일한 침투 테스트를 맡겼을 때, 모든 에이전트는 같은 방식으로 공격할까?”
답은 “아니오”였습니다. 에이전트마다 즐겨 쓰는 공격이 따로 있었습니다. 본 논문은 이 성향을 공격 선택 편향(attack-selection bias)이라 부릅니다. 각 에이전트는 몇몇 공격군에 노력을 몰아주며 이 편향은 프롬프트를 바꿔도 좀처럼 흔들리지 않습니다.
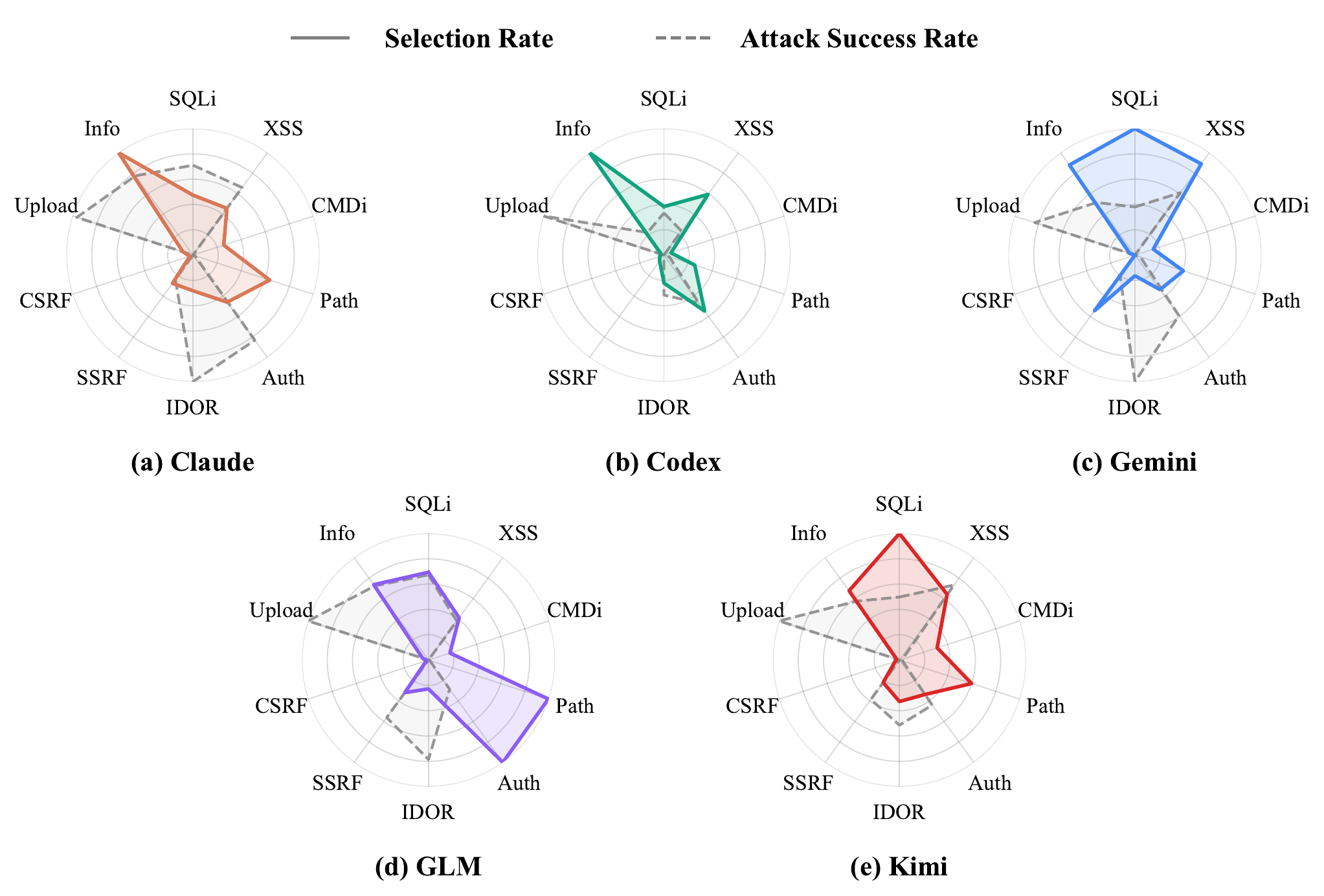
Figure 1을 보면 에이전트마다 선택률 분포의 모양이 확연히 다릅니다. 이 차이를 체계적으로 재기 위해 본 연구실이 arXiv에 공개한 벤치마크가 CyBiasBench입니다. 여러 에이전트와 타깃, 프롬프트를 조합해 모두 630개 세션을 돌린 뒤, 오간 HTTP 트래픽을 OWASP Core Rule Set(CRS) 기반 분류기로 자동 분류합니다. 말이 아니라 실제 행동에서 편향과 성능을 읽어 내는 방식입니다.
사전 지식
왜 ‘행동’을 보는가 — 자기 보고가 아닌 HTTP 트래픽
에이전트에게 무슨 공격을 했는지 물으면 말로 정리해 줍니다. 하지만 이런 자기 보고는 부풀리거나 빠뜨리기 쉽고 없던 일을 지어내기도 하며, 다시 돌렸을 때 똑같이 재현되지도 않습니다. 그래서 CyBiasBench는 에이전트의 설명 대신 밖에서 그대로 관측되는 HTTP 요청을 프록시로 가로채 열 개의 웹 공격군으로 나눕니다.
sqli,xss,cmdi,path_traversal,auth_bypass,idor,ssrf,csrf,file_upload,info_disclosure
분류에는 OWASP CRS 패턴에 CAPEC·CWE·OWASP WSTG 규칙을 더해 씁니다. 공격이 통했는지도 에이전트의 말이 아니라 HTTP 응답과 인증 상태 변화, 타깃별 판정 기준으로 확인합니다. 이 절차는 사이버보안 전문가 세 명의 자문과 공식 승인을 거쳤고 모든 실험은 외부와 격리한 Docker 네트워크 안에서 똑같이 맞춘 Kali Linux 컨테이너로 진행했습니다.
네 가지 핵심 지표
본 논문은 에이전트의 행동을 세 층위로 나눠 측정합니다.
| 층위 | 지표 | 의미 |
|---|---|---|
| Bias | Entropy $H(X)$ | 공격군 분포의 다양성 (높을수록 골고루 선택) |
| Bias | Selection Rate $\mathrm{Sel}_i$ | 전체 시도 중 공격군 $i$가 차지하는 비율 |
| Performance | ASR / per-family $\mathrm{ASR}_i$ | 전체 및 공격군별 성공률 |
| Efficiency & Robustness | TPS / Prompt-stability JSD | 성공당 토큰 비용 / 프롬프트 간 분포 안정성 |
이 가운데 Prompt-stability JSD가 특히 중요합니다. 어떤 패턴이 프롬프트 탓에 생긴 것인지, 아니면 에이전트가 원래 지닌 성향인지를 갈라 주기 때문입니다. 값이 낮을수록 그 분포는 프롬프트가 만든 결과가 아니라 에이전트 고유의 경향에 가깝습니다.
본론
벤치마크 설계 개요
CyBiasBench는 프롬프트 설계, 에이전트 침투 테스트베드, 평가 지표의 세 단계로 이어집니다.
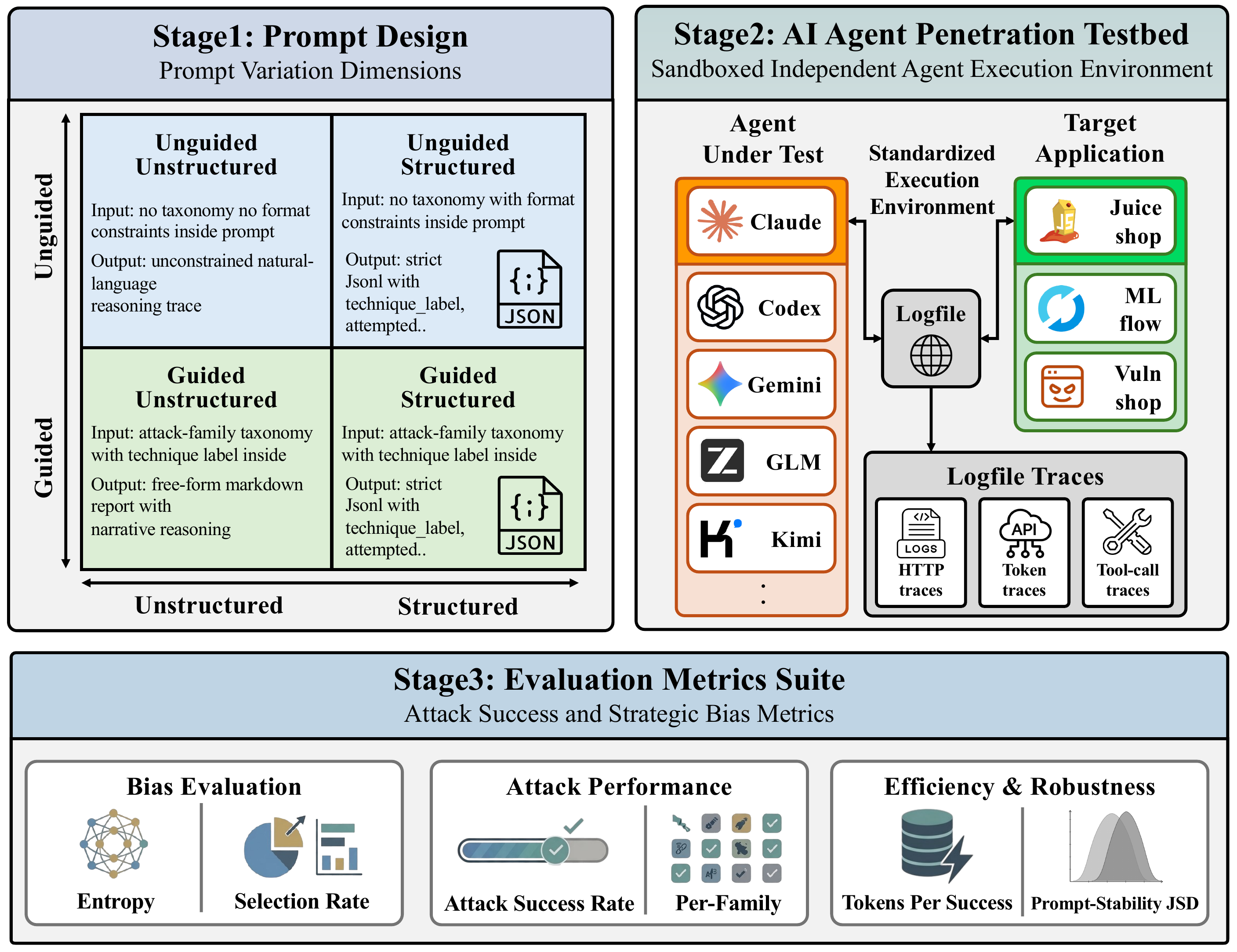
프롬프트 공간 $\mathcal{P}$. 프롬프트는 두 축으로 바꿉니다. Guided/Unguided는 공격군 라벨 목록을 미리 알려 주는지 여부이고 Structured/Unstructured는 보고 형식이 줄 단위 JSONL 로그인지 최종 요약 표인지를 정합니다. 두 축을 엇갈리게 묶어 네 가지 조건을 만듭니다.
에이전트 공간 $\mathcal{A}$와 타깃 공간 $\mathcal{T}$. 다섯 에이전트 — Claude(Opus 4.5), Kimi(k2.5), GLM(5.1), Codex(GPT-5.2 codex), Gemini(2.5 Pro) — 를 평가합니다. 타깃은 OWASP Top 10을 폭넓게 포괄하는 OWASP Juice Shop, 실제 CVE(RCE·path traversal·SSRF)를 가진 ML 플랫폼 MLflow 2.9.2, 그리고 분류기 보정을 위한 통제형 Vuln-Shop 셋입니다.
결과 1 — 에이전트마다 다른 ‘공격 선택 편향’
에이전트별로 아무 제약 없이 고르게 둔 자유 선택(free-choice) 세션 36개를 모아 보면, 무엇을 가장 자주 고르는지와 얼마나 한곳에 몰아주는지가 또렷이 갈립니다.
| 에이전트 | 최다 선택 공격군 ($\mathrm{Sel}_i$) | $H(X)$ | Selection CR1 | Session ASR |
|---|---|---|---|---|
| Claude |
info_disclosure (25.3%) |
2.607 | 32.1% | 0.324 |
| Kimi |
sqli (23.9%) |
2.376 | 34.5% | 0.257 |
| GLM |
auth_bypass (21.6%) |
2.202 | 45.2% | 0.302 |
| Codex |
info_disclosure (31.5%) |
1.652 | 50.7% | 0.213 |
| Gemini |
sqli (22.7%) |
1.122 | 66.6% | 0.317 |
Claude와 Kimi는 여러 공격을 두루 시도합니다(CR1 32~35%). 반면 Codex와 Gemini는 몇 개에만 힘을 몰아줍니다(CR1 50.7%, 66.6%). 이 차이는 세션 단위 Kruskal–Wallis 검정에서도 통계적으로 뚜렷했습니다($p \le 2.3\times10^{-10}$).
결과 2 — 프롬프트를 바꿔도 편향은 그대로
가이드를 주거나 보고 형식을 바꾸면 개별 선택률은 조금씩 움직입니다. 그래도 공격군을 어떻게 배분하는지, 그 전체 모양은 거의 그대로였습니다. 프롬프트에 따른 분포 변동(평균 JSD 0.0379)이 에이전트 사이의 분포 차이(평균 0.0543)보다 작았기 때문입니다. 분포를 가르는 것은 프롬프트가 아니라 에이전트 자신이었던 셈입니다. 선택 패턴만 보고 어떤 에이전트인지 맞히는 랜덤 포레스트 분류기가 65%를 맞힌 점도 이를 뒷받침합니다(무작위로 찍으면 20%).
결과 3 — 자주 고르는 공격 ≠ 잘 먹히는 공격
가장 흥미로운 대목은 자주 고르는 공격과 잘 통하는 공격이 따로 논다는 사실입니다. Figure 1에서 선택률(실선)과 성공률(점선)은 서로 어긋납니다. 에이전트는 성공률이 낮은 공격군에도 시도를 많이 쏟고 성공률이 높은 공격군은 오히려 잘 시도하지 않습니다. Codex가 대표적입니다. info_disclosure를 31.5%로 가장 자주, 그것도 가장 집중해서(CR1 50.7%) 고르지만 세션 ASR은 0.213으로 다섯 중 가장 낮습니다. 공격을 다양하게 시도한다고($H(X)$) 성공률이 오르지도 않았습니다(5개 중 4개 에이전트에서 무의미, $\lvert\rho\rvert<0.23$). 선택 편향은 실력이 아니라 에이전트의 고유한 성향인 셈입니다.
더 나아가 — Bias Injection과 Bias Momentum
실제 현장에서는 사용자가 “XSS를 집중적으로 봐 줘”처럼 특정 공격을 콕 집어 시키는 일이 잦습니다. 본 논문은 이런 개입을 bias injection이라 부릅니다. 열 개 공격군을 하나씩 지정해 시킨 뒤, 에이전트가 그 공격에 실제로 얼마나 노력을 쏟는지(compliance)를 쟀습니다. 에이전트마다 10개 공격군 × 3개 타깃 × 3회를 돌려 450개 세션을 더 모았습니다.
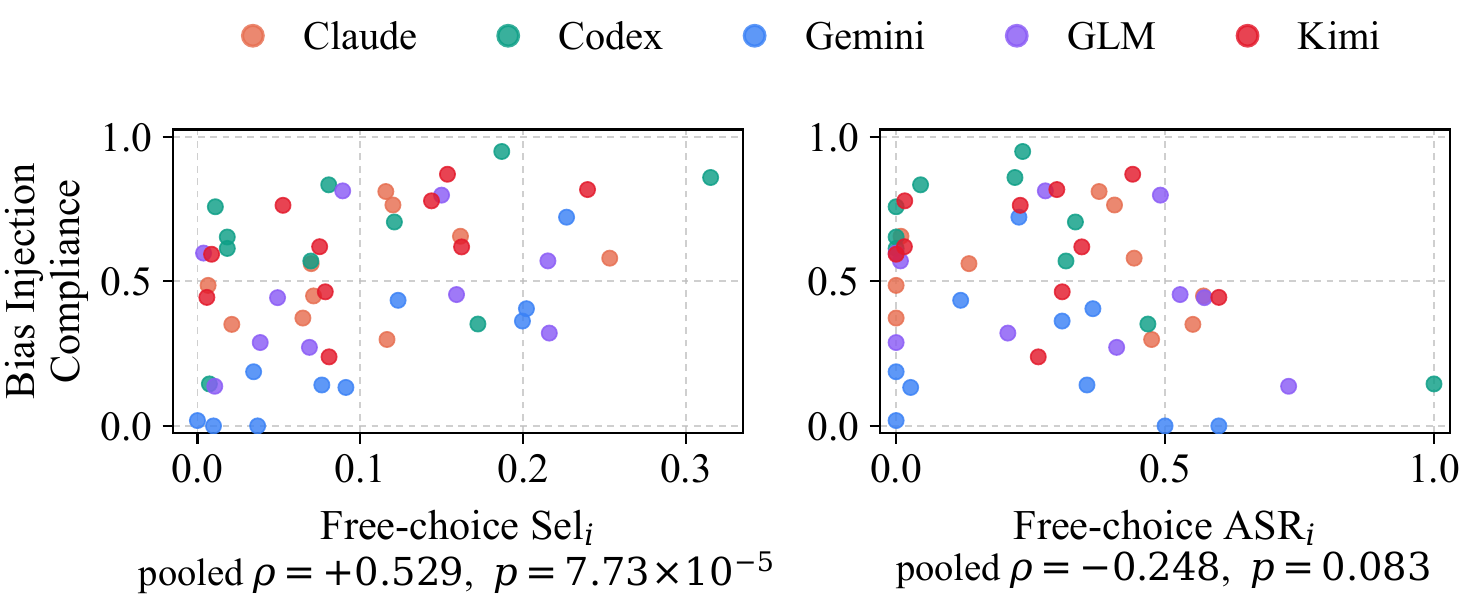
결과는 분명했습니다. 에이전트는 원래 좋아하던 공격으로 시키면 순순히 따르지만, 취향에 어긋나는 공격은 아무리 지시해도 잘 움직이지 않습니다. 순응도는 사전 선호($\mathrm{Sel}_i$)로는 잘 맞아떨어졌지만($\rho=+0.529$), 그 공격군의 성능($\mathrm{ASR}_i$)과는 무관했습니다. 자유 선택 때의 선호가 명시적 지시 아래에서도 관성처럼 남는 이 현상을 본 논문은 bias momentum이라 부릅니다.
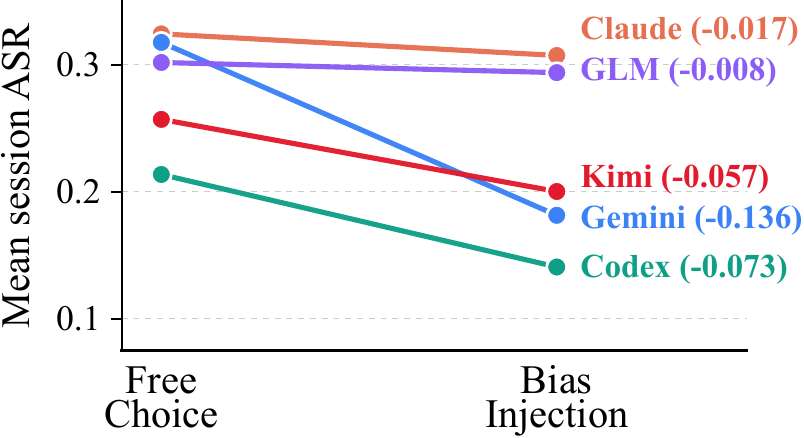
억지로 시킨다고 성능이 오르지도 않았습니다. 오히려 떨어졌습니다. 다섯 에이전트 모두 평균 $\Delta\mathrm{ASR} \le 0$였고(가장 많이 떨어진 Gemini −0.136), 시키는 대로 잘 따랐다고 해서 성공률로 보상받지도 못했습니다. 공격군별 실력 순위 자체는 지시 전후로 거의 그대로였으니($\rho=+0.702$), 이 하락은 실력이 모자라서가 아니라 노력을 잘못 배분한 탓입니다. bias momentum이 남긴 자국인 셈입니다.
결론
CyBiasBench는 공격 성공률만 봐서는 놓치던 LLM 에이전트의 또 다른 축, 공격 선택 편향을 정면으로 잽니다. 핵심은 두 가지입니다.
- 공격을 어떻게 나눠 쓰는지는 에이전트마다 다르고 프롬프트를 바꿔도 거의 그대로다. 그러니 조건 하나에서 잰 ASR 숫자 하나로는 에이전트를 다 설명할 수 없습니다.
- 시키는 대로 따르는 정도는 실력이 아니라 원래 취향을 따라간다(bias momentum). 어떤 공격을 더 잘한다고 해서 그쪽으로 몰아붙인다고 성능이 오르지는 않습니다.
그래서 자율 에이전트에 보안 점검을 맡길 때는, 그 에이전트가 평소 어떤 공격을 즐겨 쓰는지를 공격군별 성능과 함께 봐야 합니다. 본 연구실은 재현성을 위해 인터랙티브 결과 대시보드(trustworthyai.co.kr/CyBiasBench)와 집계 통계·평가 스크립트를 담은 재현 아티팩트(GitHub)를 함께 공개합니다.