논문명: Adversarial Examples Are Not Bugs, They Are Features
저자: Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, Aleksander Madry
게재지: NeurIPS 2019
서론
적대적 예제(adversarial example)는 사람이 보기에는 원본과 거의 구분되지 않지만, 딥러닝 모델의 예측은 왜곡시키는 입력 데이터입니다. 기존 연구들은 이 현상의 원인을 주로 모델의 취약성, 고차원 입력 공간의 특성, 과적합, 학습 데이터 부족, 또는 결정 경계 주변의 이상 현상으로 보았습니다. 즉, 적대적 예제는 모델이 정상적으로 학습하지 못해 발생하는 일종의 버그(bug) 처럼 이해되는 경우가 많았습니다.
하지만 본 논문은 적대적 예제가 단순한 버그가 아니라, 모델이 실제로 학습한 특징(feature) 의 결과라고 주장합니다. 학습 데이터 안에는 사람 눈에는 거의 보이지 않지만 정답 예측에는 도움이 되는 특징들이 존재하고, 모델은 정확도를 높이기 위해 해당 특징들을 학습합니다. 그러나 그중 일부 특징은 작은 섭동(perturbation)만으로도 예측 결과가 쉽게 뒤집히는데, 논문은 기존 학습 방식이 이 특징들을 학습에 활용하기 때문에 모델이 적대적 예제에 속는다고 설명합니다.
Features 정의
용어 정리
| 용어 | 의미 |
|---|---|
| Feature | 입력 데이터로부터 추출된 정보 |
| Useful feature | 정답 라벨과 상관관계가 있어 분류에 도움이 되는 특징 |
| Robust feature | 작은 섭동이 더해져도 정답 라벨과의 관계가 유지되는 특징 |
| Non-robust feature | 평소에는 분류에 도움이 되지만 작은 섭동으로 쉽게 뒤집히는 특징 |
| Standard training | 일반 정확도를 높이도록 loss를 최소화하는 학습 |
| Robust training | 공격자가 섭동을 더한 최악의 경우까지 고려하는 학습 |
| Transferability | 한 모델을 속이기 위해 만든 적대적 예제가 다른 모델에도 통하는 현상 |
-
적대적 예제
적대적 예제는 정상 입력 \(x\)에 작은 섭동 \(\delta\)를 더해 만든 입력 \(x + \delta\)입니다. 이때 \(\delta\)는 사람 눈에 안 보이는 작은 범위 안에서 모델의 loss을 크게 만들거나 특정 클래스로 예측을 유도하도록 설계됩니다.
이처럼 일반적인 적대적 공격은 다음과 같은 형태로 이해할 수 있습니다.
\[x_{adv} = x + \delta\] -
Feature
논문은 feature를 입력 공간에서 실수값으로 가는 함수로 정의합니다.
\[f: X \rightarrow \mathbb{R}\]즉, feature는 이미지에서 추출해낸 어떤 측정 결과입니다. 예를 들어 ‘강아지의 귀’처럼 익숙한 특징일 수도 있고, 사람이 거의 인식하지 못하는 픽셀 수준의 통계적 패턴일 수도 있습니다. 중요한 점은 모델 입장에서 이들은 본질적으로 다르지 않으며, 정답을 맞히는 데 도움이 되면 모델은 이들을 사용합니다.
-
Useful feature
어떤 feature \(f\)가 라벨 \(y\)와 평균적으로 양의 상관관계를 가지면, 논문은 이를 useful feature라고 부릅니다. 다시 말해, 어떤 feature를 보고 정답을 더 잘 맞힐 수 있다면 useful feature입니다. 아래 수식에서 \(\rho\)는 feature가 라벨과 관련 있는 정도를 의미합니다.
\[\mathbb{E}_{(x,y)\sim D}[y \cdot f(x)] \geq \rho\] -
Robust feature
어떤 useful feature가 공격자가 작은 섭동을 더해도 여전히 라벨과 같은 방향을 유지하면 robust feature입니다. 아래 수식에서 \(\Delta(x)\)는 공격자에게 허용된 섭동의 범위입니다. 즉, 공격자가 가장 나쁜 방향으로 입력을 바꾸더라도 그 useful feature가 여전히 정답 예측에 도움이 되면 robust하다고 볼 수 있습니다.
\[\mathbb{E}_{(x,y)\sim D} \left[ \inf_{\delta \in \Delta(x)} y \cdot f(x+\delta) \right] \geq \gamma\] -
Non-robust feature
Non-robust feature가 이 논문의 핵심 개념입니다. 이는 평상시에는 정답 예측에 도움이 되지만 (useful feature), 작은 섭동만으로도 라벨과의 관계가 쉽게 깨지거나 반대로 뒤집히는 feature를 의미합니다.
예를 들어 강아지 이미지 안에 사람 눈에는 거의 보이지 않는 미세한 패턴이 있고, 그 패턴이 강아지 라벨과 통계적으로 연결되어 있다고 가정합니다. 모델은 이 패턴을 학습하면 정확도가 올라갑니다. 하지만 공격자가 그 패턴을 조금만 바꾸면 모델은 이미지를 고양이로 예측할 수 있습니다. 이때 해당 패턴은 useful하지만 non-robust한 feature입니다.
학습 방식
-
Standard training
일반적인 지도 학습의 목표는 훈련 데이터의 loss를 줄이고, 테스트 데이터 정확도를 높이는 것입니다. 이 과정에서 모델은 어떤 feature가 자연스러운지, 또는 공격에 안정적인지 따지지 않습니다. 중요한 것은 그 feature가 정답률을 올리는가입니다. 논문은 이를 다음과 같이 설명합니다.
\[C(x) = \operatorname{sgn} \left( b + \sum_{f \in F} w_f \cdot f(x) \right)\]분류기 \(C\)는 여러 feature의 가중합을 기반으로 결과를 예측합니다. 어떤 feature가 라벨 예측에 도움이 되면, 모델은 그 feature의 가중치를 활용해 loss를 줄입니다. 이때 feature가 robust한지 non-robust한지는 이 목적함수 안에서 구분되지 않습니다. 다시 말해, standard training은 정답을 맞히는 데 도움이 되는 feature를 모두 사용합니다. 그 결과, non-robust feature도 학습됩니다. Non-robust feature는 공격에는 취약하지만, 평상시 정확도에는 실제로 도움이 되기 때문입니다.
-
Robust training
Robust training은 공격자가 입력을 왜곡한 상황까지 고려합니다. 일반 학습이 원래 입력 \(x\)에 대한 loss를 줄인다면, robust training은 허용된 섭동 \(\delta\) 중에서 loss가 가장 커지는 최악의 경우를 고려합니다.
\[\mathbb{E}_{(x,y)\sim D} \left[ \max_{\delta \in \Delta(x)} L_\theta(x+\delta, y) \right]\]이 학습 방식에서는 non-robust feature의 사용이 위험합니다. 공격자가 해당 feature를 쉽게 뒤집을 수 있기 때문입니다. 따라서 robust training은 모델이 useful하지만 non-robust한 feature 조합에 과도하게 의존하지 못하도록 만드는 과정으로 이해할 수 있습니다.
이를 정리하면 다음과 같습니다.
| 학습 방식 | 모델이 배우는 경향 |
|---|---|
| Standard training | 정답률에 도움이 되는 모든 feature를 사용 |
| Robust training | 공격자가 조작하기 어려운 feature를 더 선호 |
Robust feature, Non-robust feature 분리 실험
목표
본 실험에서는 robust feature와 non-robust feature의 분리를 시도합니다. 이는 적대적 학습 대신, robust feature에 대한 standard training만으로도 강건한 모델을 만들 수 있는지 확인하기 위함입니다.
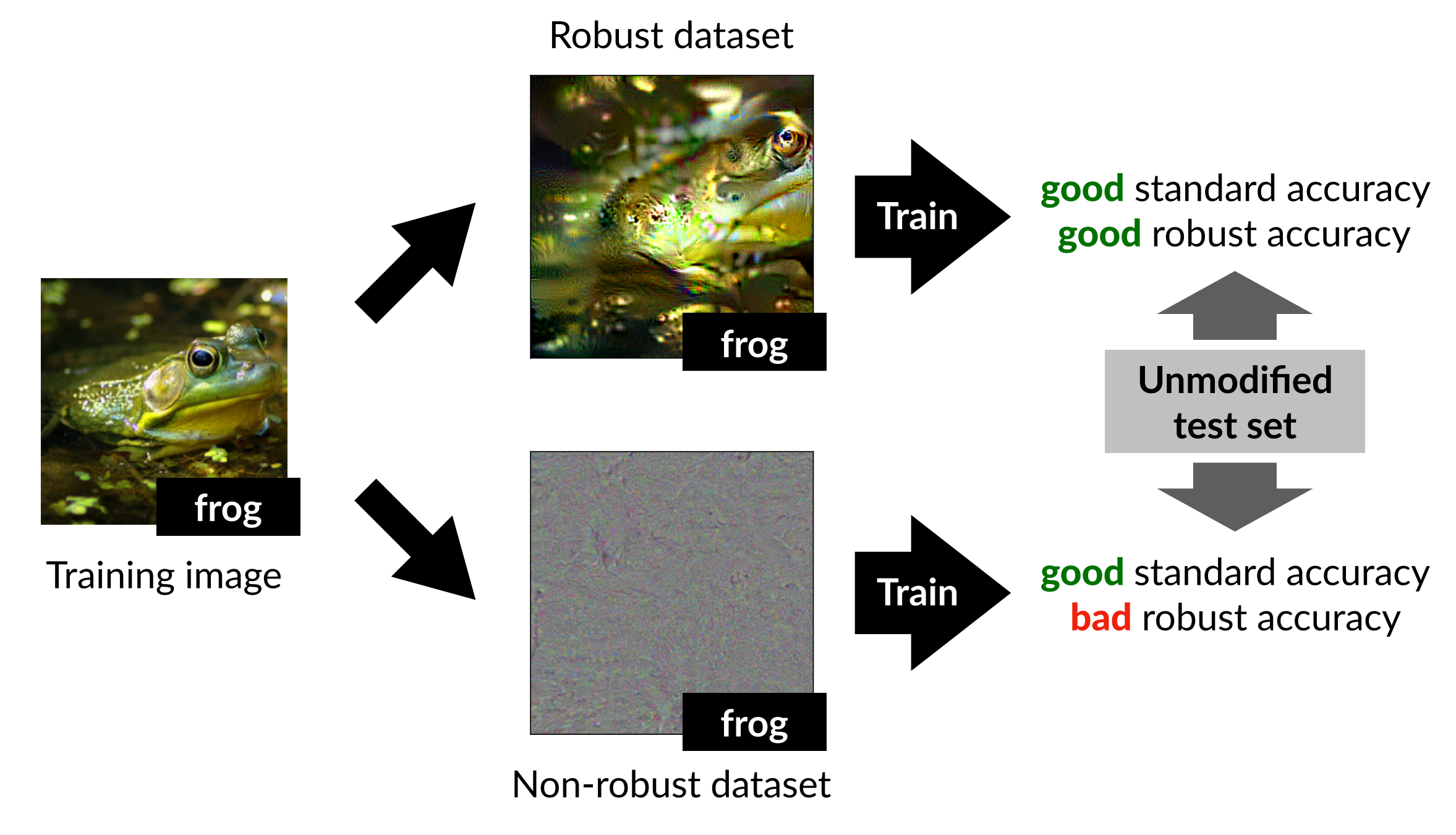
Robustified dataset
먼저 학습 데이터 \(D\)로부터 non-robust feature를 제거한 robustified dataset을 구축해야 합니다. 이를 위해, 미리 adversarial training으로 학습된 robust model을 사용합니다. 이 모델의 마지막 linear classifier 직전의 representation layer는 해당 robust model이 분류에 사용하는 feature들의 집합으로 볼 수 있습니다. 따라서 원본 이미지 \(x\)와 새로운 이미지 \(x_r\)이 robust model 내부에서 비슷한 representation을 갖도록 \(x_r\)를 만들면, \(x_r\)에는 robust model이 사용하는 feature가 보존된다고 볼 수 있습니다. 이를 최적화 문제로 표현하면 다음과 같습니다.
\[\min_{x_r} \|g(x_r) - g(x)\|_2\]이때 \(g(x)\)는 입력 \(x\)를 robust model의 representation layer까지 통과시켰을 때의 결과입니다. \(x_r\)는 경사하강법을 거쳐 최적화되는데, 저자들은 새로운 이미지 \(x_r\)를 만들 때 원본 이미지에서 출발하지 않고, 라벨과 무관하게 선택된 다른 이미지 또는 노이즈에서 출발합니다. 그 이유는 robust model이 사용하지 않는 다른 feature들이 원래 라벨과 상관관계를 갖지 않게 하기 위함입니다.
이 방식으로 만들어진 데이터셋을 robustified dataset \(\hat{D}_R\)으로 사용합니다. robustified dataset은 사람 눈에 완전히 자연스럽지는 않을 수 있지만, robust model의 representation layer에서는 원본 이미지와 유사한 활성화값(activation value)를 갖도록 만들어집니다.
\[\mathbb{E}_{(x,y)\sim \hat{D}_R}[f(x)\cdot y] = \begin{cases} \mathbb{E}_{(x,y)\sim D}[f(x)\cdot y], & f \in F_C \\ 0, & \text{otherwise} \end{cases}\]위 수식은 새로 만든 \(\hat{D}_R\)에서 feature \(f\)가 정답 라벨 \(y\)와 얼마나 상관관계가 있는지 정의해주는 수식입니다. 이때 \(F_C\)는 robust classifier \(C\)가 사용하는 feature 집합입니다. 즉, robust model이 실제로 사용하는 feature는 원래 데이터셋에서와 같은 예측력을 유지하되, 나머지 feature는 라벨과 상관관계를 갖지 않도록 만듭니다.
Non-robust dataset
Non-robust dataset \(\hat{D}_{NR}\)은 동일한 최적화 방식을 사용해 만들되, robust model 대신에 일반 모델을 사용합니다. 일반 모델은 robsut feature와 non-robust feature를 모두 사용하지만, 적대적 학습을 거쳐 만든 모델이 아니기 때문에 robust가 낮아 non-robust feature에 집중하는 모델로 간주하기 때문입니다.
실험 결과
\(D\)로부터 \(\hat{D}_{R}\)와 \(\hat{D}_{NR}\)를 분리한 후, 각 데이터셋을 학습 데이터셋으로 사용했을 때의 accuracy와 robustness를 평가합니다.
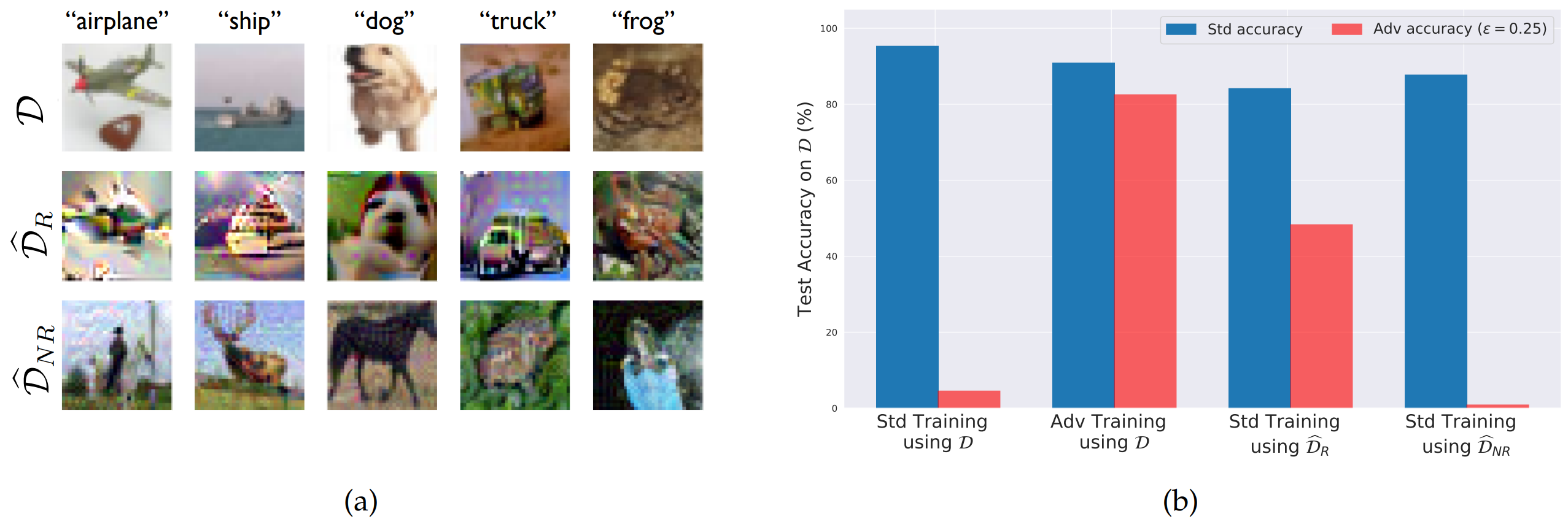
실험 결과, \(\hat{D}_{R}\)으로 standard training을 수행한 모델 (세 번째 그래프)은 원래 테스트셋에 대해 높은 standard accuracy와 의미 있는 robust accuracy를 보였습니다. 즉 adversarial training을 직접 수행하지 않아도, 학습 데이터셋에서 non-robust feature를 줄여 robust한 모델을 만들 수 있었습니다.
반대로 \(\hat{D}_{NR}\)으로 standard training을 수행하면 (네 번째 그래프), standard accuracy는 유지되지만 robust accuracy는 낮게 나타났습니다. 이는 일반 모델이 사용하는 feature 중 상당수가 적대적 공격에 취약한 non-robust feature임을 시사합니다.
즉, Robustness는 학습 알고리즘만의 문제가 아니라, 학습 데이터셋 안에 어떤 feature가 존재하는지의 문제이기도 합니다.
Non-robust feature 일반화 실험
목표
두 번째 실험의 목적은 non-robust feature가 단순한 노이즈가 아니라, 그 자체만으로도 일반화 가능한 분류 정보인지 확인하는 것입니다.
이를 위해 저자들은 사람 눈에는 라벨이 잘못 붙은 것처럼 보이는 데이터셋을 만듭니다. 즉, 이미지의 시각적 의미는 원래 클래스에 가깝게 유지하되, 모델이 민감하게 반응하는 미세한 non-robust feature만 target class와 맞도록 조작합니다.
만약 이런 데이터셋으로 학습한 모델이 원래의 정상 테스트셋에서도 성능을 낸다면, 이는 non-robust feature가 훈련 데이터에만 우연히 존재하는 잡음이 아니라, 테스트셋까지 이어지는 일반화 가능하다는 뜻입니다.
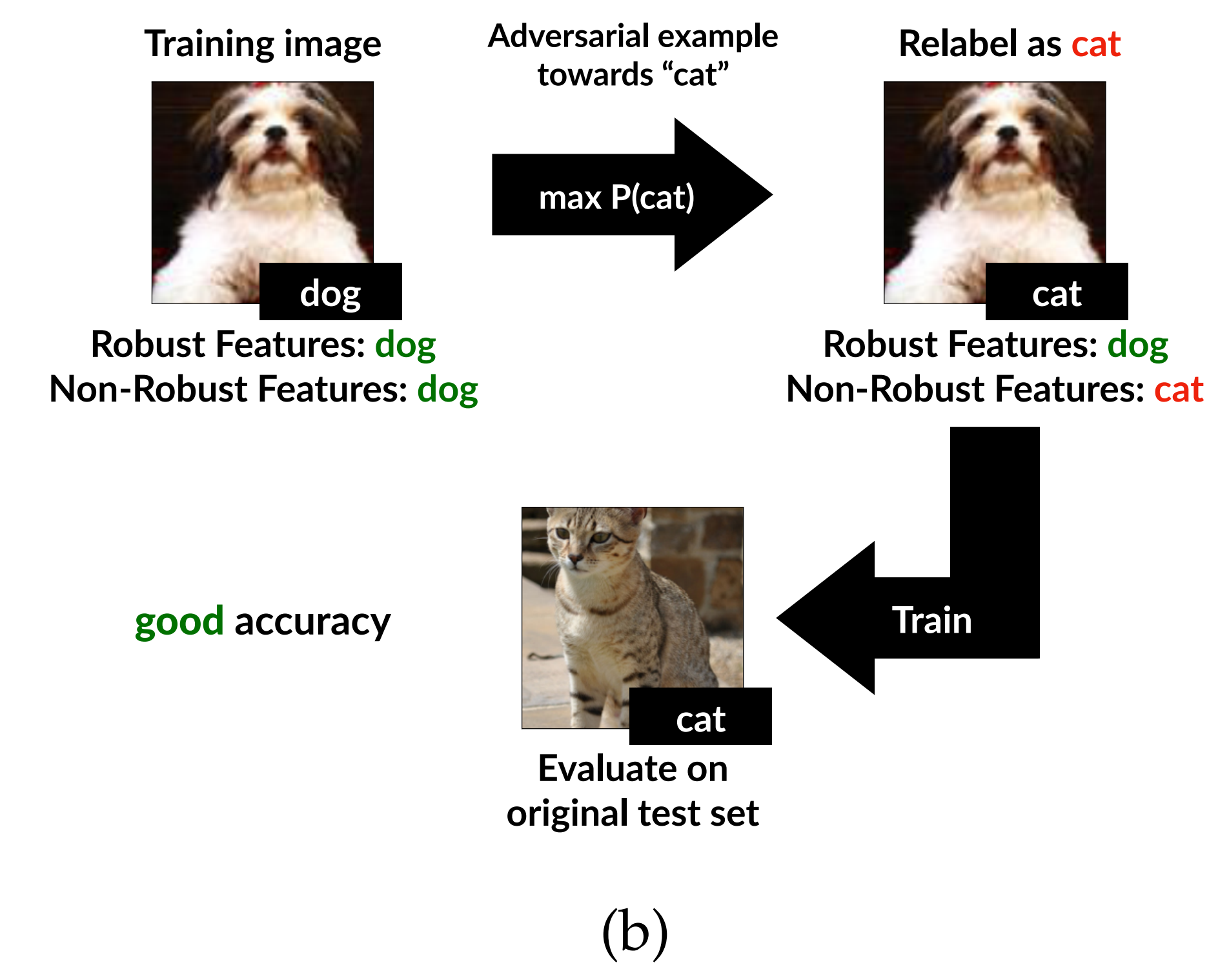
Non-robust dataset 생성
저자들은 원래 이미지 \(x\)와 정답 라벨 \(y\)가 주어졌을 때, 먼저 새로운 target class \(t\)를 정합니다. 이후 \(x\)에 아주 작은 perturbation을 추가하여, 사람 눈에는 원래 이미지와 거의 같아 보이지만 standard model \(C\)는 이를 class \(t\)로 분류하도록 만드는 \(x_{adv}\)를 생성합니다.
이 과정은 다음 최적화 문제로 표현할 수 있습니다.
\[x_{adv} = \arg\min_{\|x' - x\| \le \epsilon} L_C(x', t)\]이처럼 원래 이미지 \(x\)에서 \(\epsilon\) 이내로만 변형할 수 있다는 제약 아래, standard model \(C\)가 후보 이미지 \(x'\)를 target class \(t\)로 판단할 때의 loss가 가장 작아지는 이미지를 찾습니다.
정리하면 다음과 같습니다.
| 데이터 | 눈으로 본 의미 | 모델이 민감하게 보는 non-robust feature | 붙이는 라벨 |
|---|---|---|---|
| \(x\) | \(y\) | \(y\) | \(y\) |
| \(x_{adv}\) | \(y\) | \(t\) | \(t\) |
저자들은 이 이미지에 실제로 \(t\)라는 라벨을 붙여 새로운 훈련 데이터셋을 구성하는데, target label 선택 방식에 따라 데이터셋의 의미가 달라집니다.
| target label 설정 | 의미 | 데이터셋 |
|---|---|---|
| target class를 무작위로 선택 | robust feature는 라벨과 평균적으로 무관 | \(\hat{D}_{rand}\) |
| 원래 class에 따라 고정된 다른 class로 변환 | robust feature가 잘못된 방향을 강하게 가리킴 | \(\hat{D}_{det}\) |
\(\hat{D}_{rand}\)에서는 사람 눈에 보이는 robust feature가 새 라벨과 거의 무관합니다. 반면 \(\hat{D}_{det}\)에서는 더 강하게, 사람 눈에 보이는 robust feature가 새 라벨과 반대 방향으로 작동합니다. 따라서 \(\hat{D}_{det}\)에서 모델이 원래 테스트셋에 일반화한다면, 이는 모델이 정말로 non-robust feature를 학습했다는 강한 증거가 됩니다.
실험 결과
논문은 CIFAR-10과 Restricted ImageNet 계열 데이터셋에서 이 실험을 수행합니다. 결과는 다음과 같습니다.
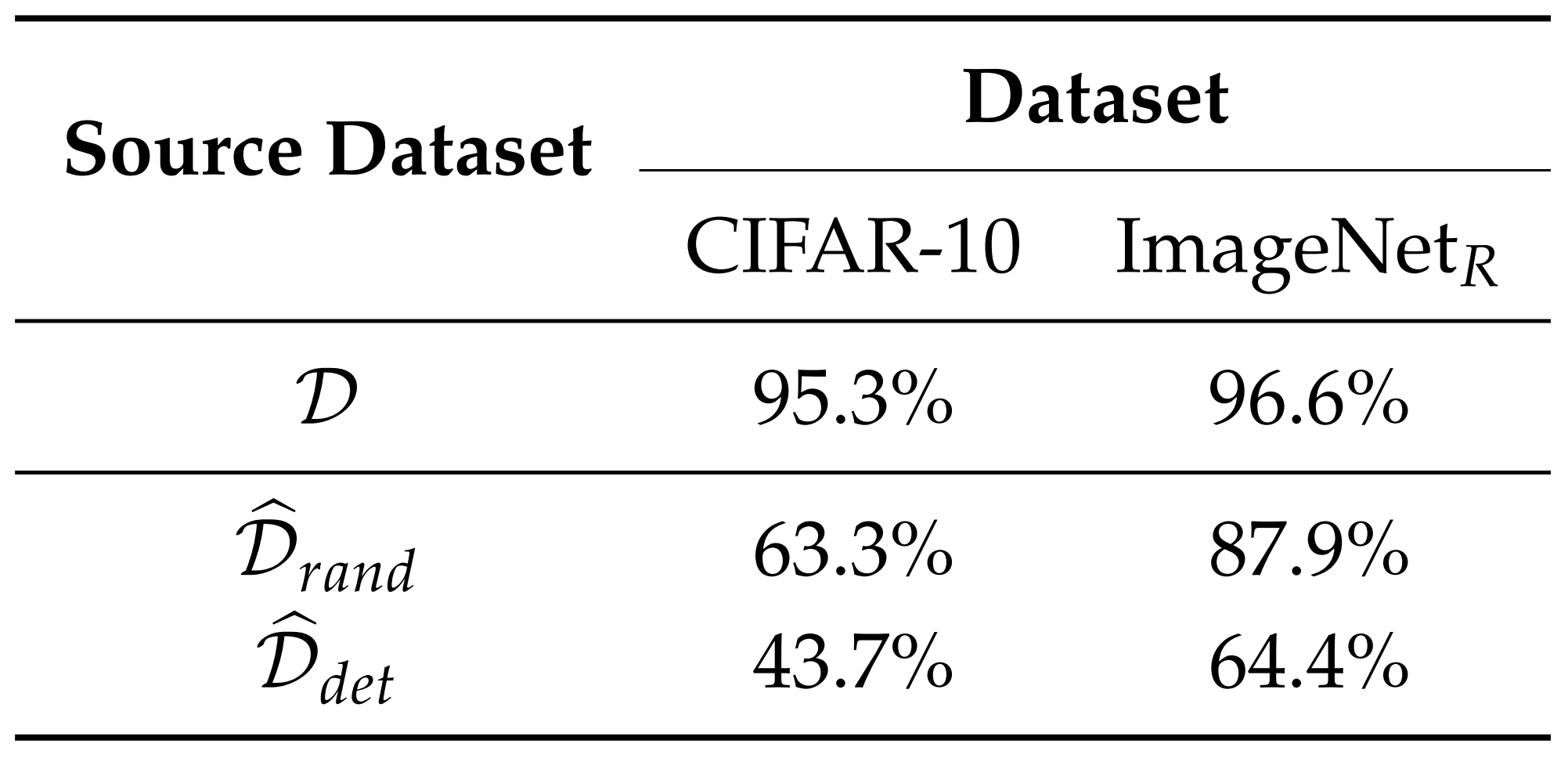
위 결과에 따르면 사람 눈에는 잘못 라벨링된 데이터셋처럼 보이지만, 모델은 그 안에 있는 non-robust feature를 학습해 원래 테스트셋에서 상당한 정확도를 달성합니다. 이처럼 Non-robust feature만으로도 표준 분류 성능을 얻을 수 있습니다. 따라서 적대적 perturbation은 단순한 오류가 아니라, 모델이 실제로 사용하는 feature를 조작한 결과라고 주장합니다.
Transferability 해석
문제의식
적대적 예제의 중요한 성질 중 하나는 전이성(transferability) 입니다. 이는 한 모델을 속이기 위해 만든 adversarial example이 다른 모델에도 통하는 현상을 말합니다. 예를 들어 ResNet을 대상으로 만든 adversarial perturbation이 VGG, DenseNet, Inception 같은 다른 구조의 모델에도 영향을 줄 수 있습니다.
기존에는 이 현상이 왜 발생하는지 명확하게 설명하기 어려웠습니다. 하지만 이 논문의 non-robust feature 관점에서는 비교적 자연스럽게 설명됩니다.
Non-robust feature와 adversarial transferability
같은 데이터셋으로 학습한 모델들은 서로 다른 architecture를 갖더라도, 비슷한 예측 정보를 학습할 가능성이 있습니다. 특히 데이터 분포 안에 실제로 존재하는 non-robust feature라면, 여러 모델이 이를 공유할 수 있습니다. 따라서 한 모델의 non-robust feature를 조작하는 perturbation은 다른 모델에도 적대적 섭동으로써 작동하는 adversarial transferability가 발생할 수 있습니다.
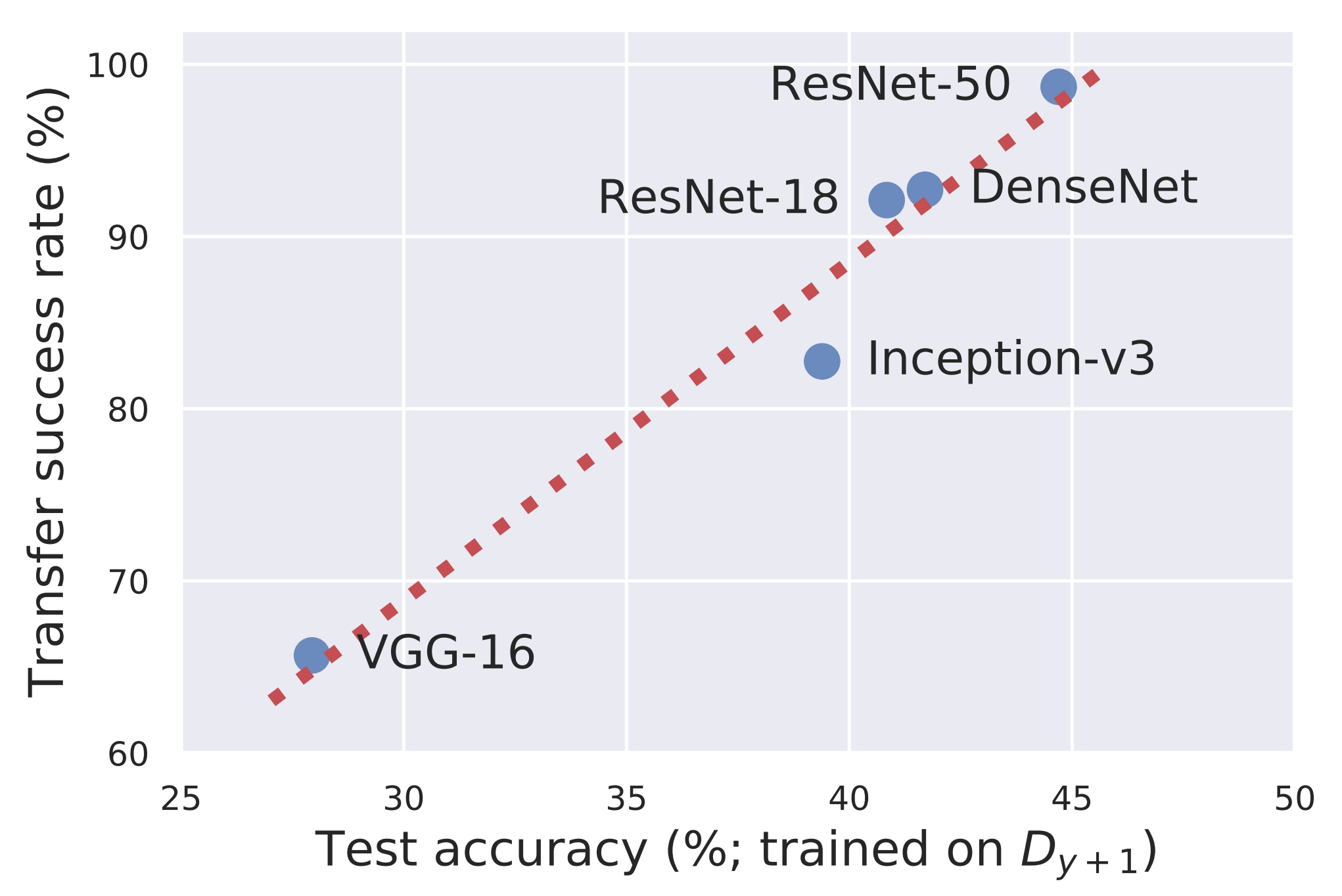
위 결과는 ResNet-50으로 만든 non-robust dataset을 여러 architecture에 학습시켰을 때의 성능입니다. non-robust dataset에서 더 잘 학습하는 architecture일수록 ResNet-50에서 만든 adversarial example에도 더 잘 속이는 경향이 나타났습니다.
이는 서로 다른 architecture라도 같은 데이터셋에서 학습하면 유사한 non-robust feature를 공유할 수 있고, 이 feature를 조작하는 perturbation은 여러 모델에 동시에 통할 수 있음을 보여줍니다.
이론적 분석
목표
앞의 실험들은 실제 이미지 데이터셋에서 non-robust feature가 존재하고, 모델이 이를 학습한다는 점을 보여줍니다. 간단한 수학적 상황에서의 분석을 위해, 저자들은 두 개의 Gaussian distribution을 분류하는 문제를 사용합니다.
Gaussian 분류 문제
라벨 \(y\)는 \(+1\) 또는 \(-1\) 중 하나로 선택되고, 입력 \(x\)는 라벨에 따라 평균이 달라지는 Gaussian distribution에서 샘플링됩니다.
\[y \sim \{-1, +1\}\] \[x \sim \mathcal{N}(y \cdot \mu^*, \Sigma^*)\]즉 \(y=+1\)이면 평균이 \(+\mu^*\)인 분포에서 나오고, \(y=-1\)이면 평균이 \(-\mu^*\)인 분포에서 나옵니다. 모델은 평균 \(\mu\)와 covariance \(\Sigma\)를 학습하여 새 입력이 어느 클래스에 속하는지 판단합니다.
이 모델에서 분류는 likelihood test로 수행되며, 다음과 같은 선형 결정 규칙으로 표현할 수 있습니다.
\[\hat{y} = \operatorname{sign} \left( x^\top \Sigma^{-1}\mu \right)\]따라서 \(\Sigma\)는 단순한 분산 추정값이 아니라, 입력 공간의 어떤 방향을 더 민감하게 볼지 정하는 metric의 역할을 합니다.
Metric misalignment
이 이론 분석의 핵심은 metric misalignment입니다. 여기서 metric은 거리 기준입니다.
공격자는 보통 \(L_2\) 또는 \(L_\infty\) 같은 사람이 정한 거리 기준 안에서 입력을 조금 바꿉니다. 사람도 이 기준으로 “이미지가 거의 바뀌지 않았다”고 판단합니다. 하지만 모델이 학습한 feature space에서는 그 작은 변화가 매우 큰 의미 변화일 수 있습니다.
Gaussian setting에서 모델의 파라미터 \(\Sigma\)는 Mahalanobis distance라는 데이터 의존적 거리 기준을 만듭니다. 이 거리 기준은 데이터가 어떤 방향으로 얼마나 퍼져 있는지를 반영합니다.
이를 정리하면 다음과 같습니다.
| 기준 | 의미 |
|---|---|
| \(L_2\) metric | 사람이 정한 입력 공간의 거리 |
| Mahalanobis metric | 모델이 데이터 분포를 통해 학습한 거리 |
| Misalignment | 두 거리 기준이 서로 어긋난 상태 |
만약 어떤 방향에서는 \(L_2\) 기준으로 아주 조금만 움직였는데, 모델의 feature 기준으로는 큰 변화가 된다면 그 방향은 adversarial attack에 취약한 방향이 됩니다. 논문은 이 불일치를 non-robust feature의 이론적 원인으로 봅니다.
Robust training의 역할
Robust training은 모델이 데이터 metric만 따르지 않도록 만듭니다. 공격자가 사용하는 \(L_2\) metric도 함께 고려하게 만듭니다. 논문은 robust learning이 데이터 고유의 metric과 adversary의 metric을 섞은 형태를 학습한다고 설명합니다.
논문의 이론 분석에서는 robust하게 학습된 covariance가 다음과 같은 형태로 나타납니다.
\[\Sigma_{r} = \frac{1}{2}\Sigma^{*} + \frac{1}{\lambda}I + \sqrt{\frac{1}{\lambda}\Sigma^{*} + \frac{1}{4}{\Sigma^{*}}^{2}}\]세부적인 \(\lambda\)의 범위보다 중요한 직관은, robust training을 하면 원래 데이터 covariance \(\Sigma^*\)에 identity matrix \(I\) 성분이 섞인다는 점입니다. 이는 모델이 데이터 분포에서만 유용한 좁고 취약한 방향에 과도하게 민감해지는 것을 줄이는 효과로 해석할 수 있습니다.
즉 standard training과 robust training은 다음과 같이 비교할 수 있습니다.
| 학습 방식 | 거리 기준 |
|---|---|
| Standard training | 데이터 분포가 주는 metric을 그대로 활용 |
| Robust training | 데이터 metric과 공격자 metric을 절충 |
공격자가 허용되는 perturbation budget \(\epsilon\)이 커질수록, 모델은 공격자가 쉽게 조작할 수 있는 방향의 feature를 덜 신뢰하게 됩니다. 이는 robust training에서 covariance가 identity matrix 쪽으로 섞이는 현상으로 시각화됩니다.
Gradient interpretability
논문은 robust model의 gradient가 더 해석 가능해 보이는 이유도 이 관점에서 설명합니다. 일반 모델은 non-robust feature에 민감하기 때문에 gradient가 사람 눈에는 노이즈처럼 보일 수 있습니다. 반면 robust model은 공격자가 쉽게 조작할 수 있는 feature를 덜 사용하므로, gradient가 클래스 사이의 의미 있는 방향과 더 잘 정렬될 수 있습니다.
즉 robust model의 gradient가 더 사람에게 의미 있어 보이는 것은 단순한 시각적 우연이 아니라, 모델이 사용하는 feature 자체가 더 robust한 방향으로 바뀌었기 때문이라고 볼 수 있습니다.
논문의 의의와 한계
의의
본 논문의 가장 큰 의의는 적대적 예제를 단순한 모델 결함이 아니라 데이터 안의 예측 신호와 학습 목표가 만들어낸 자연스러운 결과로 해석했다는 점입니다.
특히 다음 세 가지 점에서 중요합니다.
- Adversarial example의 원인 재해석: 적대적 예제는 모델이 의미 없는 잡음에 속는 현상이 아니라, 모델이 실제로 유용한 non-robust feature를 학습했기 때문에 발생할 수 있습니다.
- Accuracy와 robustness의 관계 설명: non-robust feature는 표준 정확도에는 도움이 됩니다. 따라서 이를 제거하거나 덜 사용하게 만들면 robust accuracy는 올라갈 수 있지만 standard accuracy는 낮아질 수 있습니다.
- Interpretability와 robustness의 연결: 모델이 사람 눈에 안 보이는 non-robust feature를 사용한다면, 학습 후 설명만 사람에게 보기 좋게 만드는 것은 충실한 설명이 아닐 수 있습니다. 해석 가능성을 높이려면 학습 과정에서부터 어떤 feature를 사용하게 할지 제어해야 합니다.
한계
다만 이 논문이 모든 adversarial example을 non-robust feature만으로 설명한다고 볼 수는 없습니다. 저자들도 non-robust feature가 적대적 취약성의 중요한 원인임을 보였지만, 다른 원인들이 존재할 가능성을 배제하지는 않습니다.
또한 robust feature와 non-robust feature를 직접 관찰한 것이 아니라, robust model과 standard model이 사용하는 representation을 통해 간접적으로 분리합니다. 따라서 실험은 매우 강력한 증거를 제공하지만, 실제 데이터셋의 모든 feature를 완전히 분해했다고 보기는 어렵습니다.
마지막으로, “robust하다”는 기준 자체가 사람이 정한 perturbation set에 의존합니다. 예를 들어 \(L_2\) 기준에서 robust한 모델이 모든 현실적 변환에 robust하다는 뜻은 아닙니다. 따라서 robustness는 항상 어떤 위협 모델(threat model)을 기준으로 정의되어야 합니다.
결론
본 논문은 적대적 예제를 바라보는 관점을 바꿉니다. 기존에는 적대적 예제를 모델의 이상한 오작동, 즉 버그처럼 이해하는 경우가 많았습니다. 하지만 이 논문은 적대적 예제가 모델이 실제로 학습한 feature의 결과일 수 있다고 주장합니다.
논문의 핵심 메시지는 다음 세 가지로 요약할 수 있습니다.
- Non-robust feature는 실제로 존재한다: 표준 이미지 데이터셋 안에는 사람 눈에는 잘 보이지 않지만 라벨 예측에 도움이 되는 미세한 feature가 존재합니다.
- 모델은 정확도를 위해 이를 학습한다: standard training은 robust feature와 non-robust feature를 구분하지 않고, 정답률을 올리는 데 도움이 되면 모두 사용합니다.
- 적대적 공격은 이 feature를 조작한다: adversarial perturbation은 무의미한 잡음이 아니라, 모델이 사용하는 non-robust feature를 반대 방향으로 뒤집는 과정으로 이해할 수 있습니다.
결론적으로 이 연구의 가장 큰 의의는 adversarial robustness를 단순한 방어 기법의 문제가 아니라, 모델이 어떤 feature를 학습하도록 만들 것인가의 문제로 재정의했다는 점에 있습니다.
즉, 딥러닝 모델은 멍청해서 속는 것이 아닙니다. 오히려 데이터 안의 예측 신호를 너무 적극적으로 활용합니다. 문제는 그 신호 중 일부가 사람에게는 보이지 않고, 작은 섭동에 매우 취약하다는 것입니다.
따라서 robust하고 interpretable한 모델을 만들기 위해서는 학습 후 방어 기법이나 설명 도구만 추가하는 것으로는 충분하지 않습니다. 처음부터 모델이 인간이 의미 있다고 여기는 안정적인 feature를 사용하도록 학습 과정에 적절한 prior와 제약을 반영해야 합니다.