논문명: Adversarial Training for Free!
저자: Ali Shafahi, Mahyar Najibi, Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S. Davis, Gavin Taylor, Tom Goldstein
게재지: NeurIPS 2019
서론
지금까지 여러 연구들이 반복적으로 확인해 온 것처럼, 적대적 훈련(Adversarial Training)은 강건한 분류기를 만드는 방법들 중 실제로 작동하는 거의 유일한 방어 기법입니다. Madry의 PGD 기반 적대적 훈련은 다양한 공격에 꾸준한 방어력을 유지해 왔고, Athalye 등이 여러 방어 기법을 무력화한 이후에도 살아남은 몇 안 되는 방법이었습니다.
하지만 이 강력함에는 큰 대가가 따릅니다. PGD 적대적 훈련은 일반 학습의 약 \(K+1\) 배에 달하는 계산 비용을 요구하는데, 여기서 \(K\) 는 적대적 예제를 만들 때 사용하는 PGD 반복 횟수입니다. 보통 \(K=7\) 정도가 쓰이므로, 같은 모델을 강건하게 만들려면 일반 학습보다 7~8배 더 오랜 시간을 투자해야 합니다. 이 때문에 ImageNet 같은 대규모 문제에서는 수십~수백 개의 GPU를 동원할 수 있는 극소수의 연구실만이 적대적 훈련을 시도할 수 있었습니다.
본 논문은 이 병목을 꽤 우아한 방식으로 돌파합니다. 저자들의 핵심 관찰은 단순합니다. 일반 학습에서 이미 수행하고 있는 역전파(Backpropagation) 한 번으로, 파라미터 업데이트용 기울기와 적대적 섭동용 기울기를 한꺼번에 얻어낼 수 있다는 것입니다. 이 관찰에 미니배치 반복(Minibatch Replay)이라는 소소한 장치 하나를 더해, 일반 학습과 거의 같은 비용으로 PGD 훈련에 필적하는 강건성을 얻는 “Free” 적대적 훈련을 제안합니다.
적대적 훈련의 비용 문제
PGD 적대적 훈련의 한 스텝은 크게 두 부분으로 나뉩니다. 안쪽에서는 현재 모델 파라미터를 고정한 채 PGD를 \(K\) 번 반복하여 적대적 예제를 생성하고, 바깥쪽에서는 그렇게 만들어진 적대적 예제에 대해 모델 파라미터를 업데이트합니다.
\[x^{t+1} = \Pi_{x+\mathcal{S}}\left(x^t + \alpha \cdot \mathrm{sgn}(\nabla_x L(\theta, x^t, y))\right)\]문제는 안쪽의 \(K\) 번 반복이 하나하나 값비싸다는 점입니다. PGD의 각 스텝은 적대적 예제를 갱신하기 위해 입력에 대한 손실의 기울기 \(\nabla_x L\) 를 계산해야 하고, 이 기울기를 얻으려면 네트워크 전체를 한 번씩 완전히 순전파-역전파해야 합니다. \(K\) 번의 완전한 순전파-역전파가 적대적 예제 생성에만 들어가고, 그 뒤에 실제로 모델 파라미터를 업데이트하기 위한 역전파가 한 번 더 필요합니다.
결과적으로 PGD-\(K\) 적대적 훈련의 계산 비용은 일반 학습의 약 \(K+1\) 배입니다. Madry의 CIFAR-10 기준 설정(\(K=7\))은 Titan X GPU 한 대로 약 4일이 걸리고, ImageNet의 경우 128개의 V100 GPU를 동원해야 했습니다. 이 정도의 비용은 대부분의 연구자들에게 사실상 접근 불가능한 벽이었습니다.
Free 적대적 훈련
기울기의 재활용
저자들의 출발점은 이런 관찰입니다. 일반 학습에서 모델 파라미터를 업데이트하려면 손실의 파라미터에 대한 기울기 \(\nabla_\theta L\) 가 필요한데, 이 기울기를 얻기 위한 역전파 과정에서 이미 입력에 대한 기울기 \(\nabla_x L\) 도 계산 그래프를 따라 함께 흐르고 있다는 점입니다.
즉 별도의 역전파 없이도 두 기울기를 한 번의 역전파로 동시에 뽑아낼 수 있습니다. 이를 이용하면 한 번의 순전파-역전파 안에서 모델 파라미터를 갱신하는 것과 적대적 섭동을 한 스텝 갱신하는 것을 동시에 수행할 수 있습니다.
하지만 이 방식에는 분명한 약점이 있습니다. 한 미니배치에 대해 단 한 번의 섭동 갱신밖에 할 수 없다는 점입니다. PGD-\(K\) 가 \(K\) 번 반복하여 강한 적대적 예제를 만들어내는 것과 달리, 1-스텝 갱신만으로는 충분히 강한 적대적 예제를 기대하기 어렵습니다. 앞선 연구들에서 FGSM 단독 학습이 PGD 공격 앞에서 무력했다는 사실도 이를 뒷받침합니다.
미니배치 반복이라는 묘수
저자들의 두 번째 아이디어는 이 약점을 놀랍도록 단순하게 보완합니다. 같은 미니배치를 \(m\) 번 연속으로 학습하는 것입니다.
핵심은 매 반복마다 직전의 섭동을 이어받아 한 스텝 더 갱신한다는 점입니다. 첫 번째 반복에서는 초기 섭동에서 한 스텝을 진행하고, 두 번째 반복에서는 첫 번째 반복에서 갱신된 섭동을 이어받아 다시 한 스텝을 더합니다. 이렇게 \(m\) 번 반복하면 사실상 \(m\)-스텝 PGD에 가까운 강한 섭동이 누적됩니다. 동시에 각 반복마다 모델 파라미터도 한 번씩 갱신되므로, 적대적 예제는 늘 최신 파라미터에 맞춰 조정됩니다.
여기에 한 가지 중요한 조정이 따라붙습니다. 같은 미니배치를 \(m\) 번 학습한다는 것은 전체 학습 반복 횟수를 \(m\) 배로 늘리겠다는 것이 아닙니다. 그 대신 총 학습 에폭 수를 \(1/m\) 로 줄여서, 전체 학습 반복 횟수는 일반 학습과 정확히 같게 맞춥니다. 그 결과 계산 비용은 일반 학습과 거의 동일해지는데, 이 과정에서 모델은 암묵적으로 \(m\)-스텝 PGD 적대적 훈련을 받게 되는 셈입니다.
마지막 소소한 장치로, 새로운 미니배치가 들어올 때 직전 미니배치에서 만들어진 섭동을 0으로 초기화하지 않고 그대로 warm-start 값으로 사용합니다. 연속된 미니배치 사이에서 섭동이 느슨하게나마 계속 진화할 수 있도록 해주는 장치입니다.
미니배치 반복이 일반화에 미치는 영향
같은 미니배치를 연속으로 반복 학습하는 것은 원래 학습 데이터의 순서를 왜곡시키므로, 일반화에 악영향을 줄 가능성이 있습니다. 특히 치명적 망각(Catastrophic Forgetting) 같은 현상이 우려될 수 있습니다.
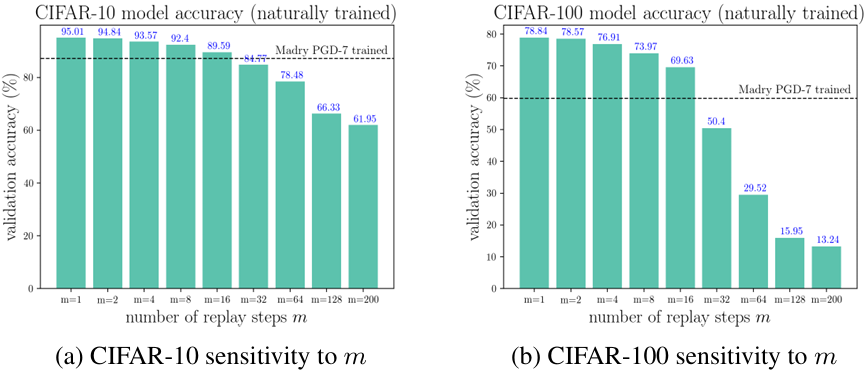
위 그림은 Free 훈련이 아닌 순수 자연 학습만 돌리면서 \(m\) 값을 바꿔 본 통제 실험입니다. \(m=1\) 은 일반 학습과 같고, \(m\) 이 아주 커지면 검증 정확도가 급격히 떨어집니다. 하지만 \(m\) 이 작을 때(대략 $m \le 10$ 범위)는 정확도 하락 폭이 놀라울 정도로 작습니다. 참고로 7-PGD 적대적 훈련을 거친 모델이 달성하는 자연 정확도(CIFAR-10에서 87.25%, CIFAR-100에서 59.87%)는 \(m=16\) 정도의 순수 자연 학습 정확도로도 이미 따라잡을 수 있습니다. 즉 작은 \(m\) 이 초래하는 일반화 손실은 적대적 훈련이 얻는 강건성에 비하면 충분히 감수할 만한 비용이라는 의미입니다.
CIFAR-10과 CIFAR-100 실험
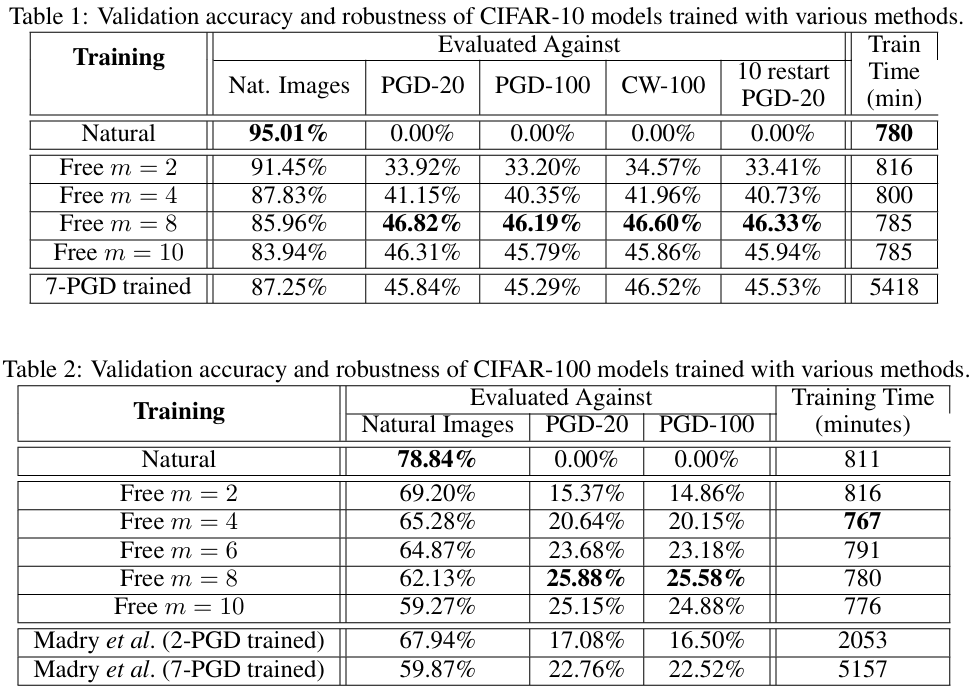
저자들은 CIFAR-10에서 Wide-ResNet 32-10을 사용하여 Free-\(m\) 훈련과 7-PGD 적대적 훈련의 결과를 정면으로 비교합니다. 결과는 상당히 인상적입니다. Free \(m=8\) 모델은 PGD-20, PGD-100, CW-100 공격 모두에 대해 46% 전후의 강건 정확도를 유지하며, 이는 Madry의 7-PGD 훈련 모델(45~46%)과 사실상 같은 수준입니다. 그러나 훈련 시간은 7-PGD 훈련이 약 5,400분인 데 비해 Free 훈련은 약 780분으로, 정확히 7배 가까이 빠릅니다.
CIFAR-100에서는 결과가 더 흥미롭습니다. Free \(m=8\) 모델은 PGD-20 공격에 대해 25.88%의 강건 정확도를 보이는데, 이는 훈련 비용이 약 7배인 7-PGD 훈련 모델(22.76%)을 오히려 앞서는 결과입니다. 자연 정확도와 강건 정확도 사이의 균형점을 훨씬 낮은 비용으로 얻을 수 있을 뿐 아니라, 어떤 설정에서는 기존 방식을 그대로 능가하기까지 합니다.
Free 적대적 훈련의 강건성에 관한 고찰
여기까지만 보면 “그저 값싼 대안이 있다”는 이야기 같지만, 한 가지 의심이 남습니다. Free 훈련이 공격을 실제로 막아내는 것이 아니라, 단지 기울기를 꼬아서 PGD 공격이 제대로 작동하지 못하게 만드는 것뿐이라면 어떻게 될까요? 즉 기울기 마스킹(Gradient Masking)에 의존하는 가짜 강건성일 가능성을 고려해야 합니다.
저자들은 이를 두 가지 진단으로 확인합니다.
해석 가능한 적대적 예제

위 그림은 \(\epsilon = 30\) 의 꽤 큰 섭동을 허용한 BIM 공격으로 만든 적대적 예제들입니다. 맨 윗줄이 원본 이미지, 가운데 줄이 7-PGD 훈련 모델, 맨 아랫줄이 Free \(m=8\) 훈련 모델에 대해 만들어진 공격 이미지입니다.
Tsipras 등이 먼저 보고했듯이, 제대로 된 적대적 훈련 모델의 적대적 예제는 단순한 노이즈가 아니라 타겟 클래스의 실제 시각적 특징을 띠게 됩니다. 예를 들어 “말”로 분류되도록 만든 공격 이미지에는 말의 윤곽과 털 질감 같은 요소가 실제로 나타납니다. Free 훈련 모델에서도 같은 패턴이 나타나며, 두 훈련 방식의 공격 이미지들이 질적으로 거의 구분되지 않을 정도로 비슷합니다. Free 훈련이 내부적으로 PGD 훈련과 유사한 표현을 학습하고 있다는 간접적인 증거입니다.
평평한 손실 지형
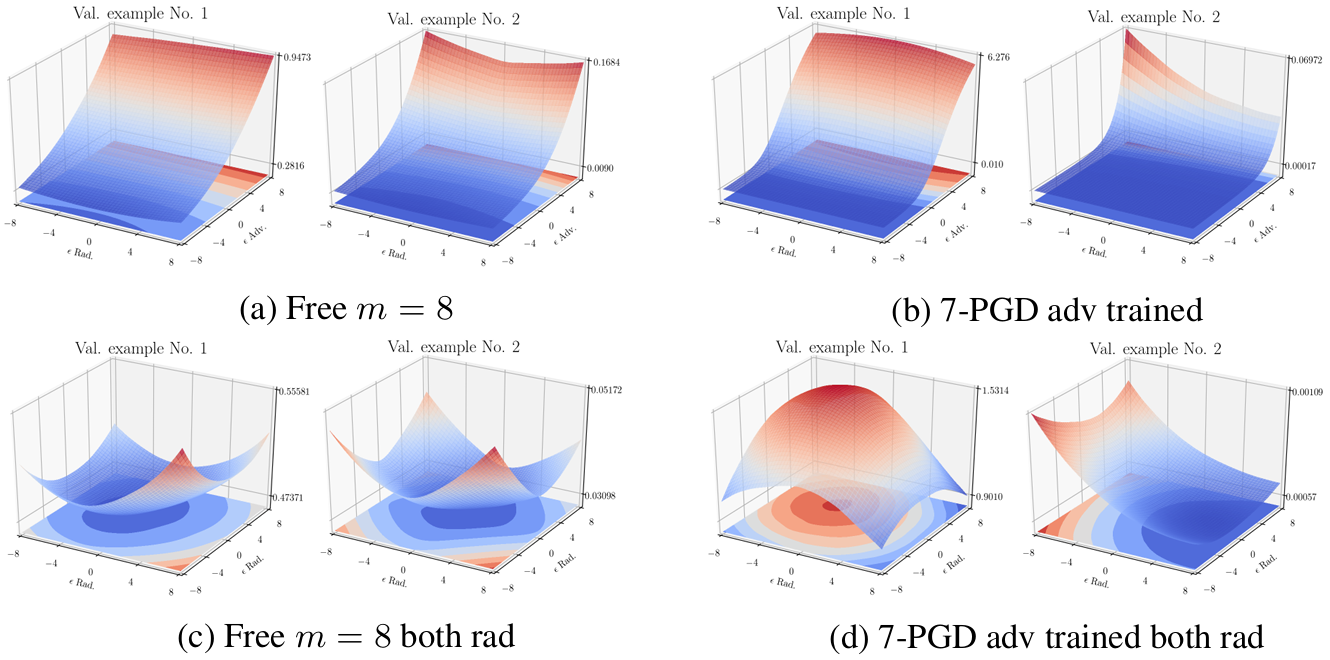
두 번째 진단은 손실 지형 자체를 들여다보는 것입니다. 위 그림은 CIFAR-10 검증 이미지 주변의 손실을 두 방향으로 절단해 그린 것으로, 위쪽 두 그림 \((a), (b)\) 는 적대적 방향과 무작위 방향을, 아래쪽 두 그림 \((c), (d)\) 는 무작위 방향 두 개를 따라 그린 것입니다.
만약 모델이 기울기 마스킹으로 작동한다면, 적대적 방향을 따라 봤을 때 손실이 평평하고 무작위 방향에서만 크게 변하는 이상한 모양이 나와야 합니다. 그러나 Free 훈련 모델 \((a)\) 과 7-PGD 훈련 모델 \((b)\) 모두에서 적대적 방향이 실제로 손실이 가장 크게 변하는 방향으로 나타나며, 지형 자체는 두 모델 모두에서 매끈하고 평평합니다. Free 훈련의 강건성은 기울기를 숨겨서 공격을 피하는 식이 아니라, 진짜로 손실 지형을 넓게 평평하게 만든 결과라는 해석입니다.
ImageNet으로의 확장
이 논문의 또 다른 큰 성과는 ImageNet 적대적 훈련을 현실적인 연구실 하드웨어 환경에서도 가능하게 했다는 점입니다. 이전의 ImageNet 적대적 훈련 연구들은 53개의 P100 또는 128개의 V100을 동원해야 했습니다. 그러나 Free 훈련은 4개의 P100으로 구성된 단일 워크스테이션에서 약 2일 만에 ResNet-50 강건 모델을 학습할 수 있습니다.
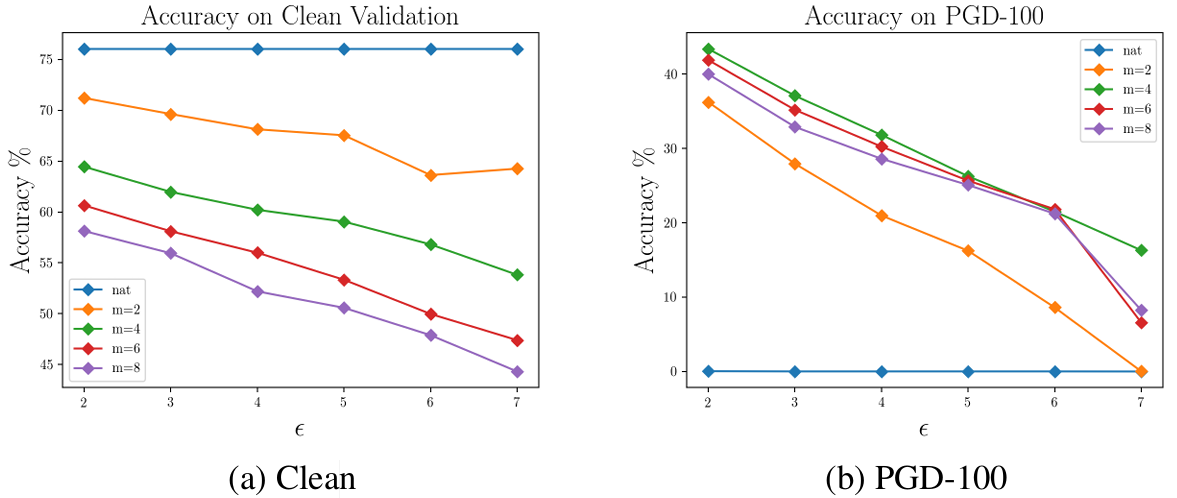
위 그림은 훈련 시 사용한 섭동 허용치 \(\epsilon\) 과 미니배치 반복 횟수 \(m\) 을 함께 바꿔 가며 측정한 자연 정확도와 PGD-100 공격에 대한 강건 정확도입니다. \(\epsilon = 2\) 일 때 Free \(m=4\) 모델은 PGD-100 공격에 대해 43.4%의 강건 정확도를 유지하는데, 이는 그 시점까지 발표된 비타겟 공격(Non-targeted Attack) 기준으로 ImageNet에서 처음으로 달성된 수준의 강건성이었습니다.
\(\epsilon\) 이 커질수록 강건성을 얻기는 급격히 어려워지는 경향이 관찰되지만, 이는 Free 훈련만의 한계가 아니라 이전 연구들에서도 공통적으로 보고된 ImageNet 고유의 어려움입니다. 그럼에도 Free 훈련이 ImageNet 강건 학습을 일부 기관의 전유물에서 일반 연구실이 시도할 만한 작업으로 끌어내렸다는 점은 분명합니다.
결론
본 논문의 기여는 개념적으로는 단순하지만 실용적인 파급력은 상당합니다. “모델 업데이트를 위한 역전파가 이미 입력 기울기까지 함께 계산하고 있다”는 관찰 하나로, \(K+1\) 배의 비용을 들여야 했던 PGD 적대적 훈련을 사실상 공짜로 수행하는 길을 열었습니다.
여기에 미니배치 반복과 섭동의 warm-start라는 두 가지 소소한 장치가 더해져, 1-스텝 FGSM 훈련처럼 쉽게 깨지는 모델이 아니라 다단계 PGD 훈련에 필적하는 강건성을 얻을 수 있게 되었습니다.
실험 결과 또한 인상적입니다. CIFAR-10과 CIFAR-100에서는 7배 낮은 비용으로 PGD 훈련에 필적하거나 오히려 앞서는 결과를 얻었고, 무엇보다 ImageNet 적대적 훈련을 단일 워크스테이션으로 끌어내렸습니다. 동시에 해석 가능한 기울기와 평평한 손실 지형이라는, 진짜 적대적 훈련의 특성들을 그대로 물려받는다는 점까지 확인되었습니다.
결국 이 논문이 던지는 메시지는 분명합니다. 적대적 훈련은 더 이상 대규모 GPU 클러스터를 가진 연구실의 전유물이 아니며, 합리적인 컴퓨팅 자원만으로도 실전에서 쓸 만한 강건 모델을 학습할 수 있다는 것입니다. 강건 학습이라는 연구 주제를 훨씬 더 넓은 연구자들에게 개방한 강력한 기여라 할 수 있습니다.