논문명: Theoretically Principled Trade-off between Robustness and Accuracy
저자: Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric P. Xing, Laurent El Ghaoui, Michael I. Jordan
게재지: International Conference on Machine Learning (ICML 2019)
URL: Theoretically Principled Trade-off between Robustness and Accuracy
서론
미세한 적대적 섭동(Adversarial perturbation)에 의해 예측을 완전히 뒤바꿀 수 있는 적대적 공격에 강건한 모델을 만들기 위해, 기존의 연구들은 여러 방어 기법들을 제안해왔습니다. 하지만, 적대적 공격에 강건하게 만들 수록 자연 예제(Natural example)에 대한 정확도가 하락하는 현상이 관찰되었습니다.
이 논문은 이러한 Trade-off 관계를 단순한 현상이 아닌 이론적인 원리로 규명하고, 이를 조절할 수 있는 최적의 방어 프레임워크인 TRADES를 제안합니다. 이 방법론은 NeurIPS 2018 Adversarial Vision Challenge에서 약 2,000개의 제출물 중 1위를 차지하며 실효성을 입증하였습니다.
본론
적대적 예제는 자연 예제(Natural example)에 인간이 인지하기 어려운 미세한 섭동을 추가함으로써, 모델의 예측 결과를 바꾸도록 설계된 예제입니다. 어떤 모델이 적대적 공격에 얼마나 취약한지를 측정하기 위해, 이 논문에서는 강건한 오류(Robust error)를 다음과 같이 정의합니다.
\[\mathcal{R}_{\text{rob}}(f) := \mathbb{E}_{(\mathbf{X},Y)\sim\mathcal{D}} \mathbf{1}\{\exists X' \in \mathbb{B}(\mathbf{X}, \epsilon) \text{ s.t. } f(X')Y \leq 0\}\]- $f : \mathcal{X} \to \mathbb{R}$ : 실수값을 출력하는 이진 분류기
- $Y \in {+1, -1}$ : 샘플의 실제 레이블
- $\mathbb{B}(\mathbf{X}, \epsilon)$ : 자연 예제 $\mathbf{X}$ 주변 $\epsilon$-ball (허용된 섭동 범위)
위 수식은 자연 분포 $\mathcal{D}$에서 샘플링된 $(X, Y)$에 대해, 허용된 섭동 범위 안에 모델을 오분류시키는 $X’$이 단 하나라도 존재할 확률을 나타냅니다. 즉 worst-case 관점을 취하여, 섭동 범위 안에서 단 하나의 공격이라도 성공하면 해당 샘플은 robust error로 간주됩니다.
강건한 오류(Robust error)의 분해
이 논문에서는 강건한 오류를 자연 오류와 경계 오류로 분해합니다. 쉬운 이해를 위하여, 수식과 그림으로 표현해 보겠습니다. \(\mathcal{R}_{rob}(f) = \mathcal{R}_{nat}(f) + \mathcal{R}_{bdy}(f)\)
\[\mathcal{R}_{\text{nat}}(f) := \mathbb{E}_{(X,Y)\sim\mathcal{D}} \mathbf{1}\{f(X)Y \leq 0\} \\ \mathcal{R}_{\text{bdy}}(f) := \mathbb{E}_{(X,Y)\sim\mathcal{D}} \mathbf{1}\{X \in \mathbb{B}(\text{DB}(f), \epsilon),\ f(X)Y > 0\}\]- $\mathcal{R}_{nat}$ : 모델이 자연 예제 자체를 틀리게 예측하는 오류 (자연 오류)
- $\mathcal{R}_{bdy}$ : 자연 예제는 맞혔지만, $\epsilon$-ball 안에 결정 경계를 넘어가는 섭동이 존재하는 오류 (경계 오류)
강건한 오류를 위와 같이 분해한 수식은, 모델의 강건성을 높이려면 단순히 분류 성능을 높이는 것뿐만 아니라, 결정 경계를 데이터로부터 멀리 밀어내어 경계 오류를 줄여야 함을 시사합니다.
직관적으로 이해하면 다음과 같습니다. 각 샘플 주변에는 허용된 섭동 범위($\epsilon$-ball)가 존재하는데, 만약 결정 경계가 $\epsilon$-ball을 잘라내지 않는다면 그 샘플은 자연 정확도뿐 아니라 강건 정확도도 확보됩니다. 반면 $\epsilon$-ball이 결정 경계를 넘어가는 샘플은 미세한 섭동만으로도 오분류가 발생할 수 있으며, 이것이 경계 오류 ($\mathcal{R}_{bdy}$)에 해당합니다. 적대적 훈련(Adversarial training)을 통해 결정 경계를 데이터로부터 밀어내면 경계 근처 샘플의 경계 오류를 줄일 수 있습니다.
대리 손실 함수(Surrogate loss)의 도입
결정 경계를 조정하는 학습을 하기 위해서는 손실 함수의 기울기를 계산해야 합니다. 그러나 오류인 경우 +1, 정답일 경우 0이 나오는 loss 측정 방식을 사용하면 값이 이산적(discrete)이어서 미분이 불가능합니다. 따라서 이 논문은 0-1 loss를 대체하는 대리 손실(Surrogate loss) $\phi$를 사용하여 최적화를 수행합니다.
이때 확인해야 할 점은, “대리 손실을 줄이는 것이 실제로 0-1 loss를 줄이는 것과 일치하는가?” 입니다. 저자들은 이를 보장하기 위해 “대리 손실 함수 $\phi$은 Classification-calibrated 하다”조건을 도입합니다. 이는 대리 손실 $\phi$를 최소화하는 방향이 궁극적으로 0-1 loss를 최소화하는 이론적 최적 분류기(Bayes optimal classifier)와 동일한 결정을 내리는 방향과 일치함을 보장하는 조건입니다.
좀 더 구체적으로 이해하기 위해, 이진 분류 세팅에서 손실 함수가 어떻게 정의되는지 예시로 살펴보겠습니다.
어떤 함수 $f$와 데이터 분포 $(x, y) \sim \mathcal{D}$, $y \in {-1, +1}$가 있고, 이 모델의 출력값 $f(x) = \alpha$라 할 때, 다음과 같은 예측을 하는 분류기가 있다고 가정합니다.
- $\alpha > 0$이면 $y = +1$로 예측
- $\alpha < 0$이면 $y = -1$로 예측
이 때, $\alpha y > 0$이면 정답, $\alpha y < 0$이면 오답이 됩니다. 좋은 손실 함수라면 정답일 때는 작은 값을, 오답일 때는 큰 값을 반환해야 합니다. 즉, $\alpha y$의 부호와 크기가 손실을 결정하는 핵심 정보가 된다는 뜻입니다. 이 손실을 계산하는 함수가 $\phi(\alpha y)$입니다.
함수값이 $\alpha$일 때,
- $\eta$ : 이 $\alpha$의 정답이 $y = +1$일 확률
- $1 - \eta$ : 이 $\alpha$의 정답이 $y = -1$일 확률
이라고 할 때, $\eta$를 알면 자동으로 최적의 분류기가 결정됩니다.
- $\eta > 0.5 \rightarrow y = +1$일 가능성이 높으므로 $\alpha > 0$ 출력
- $\eta < 0.5 \rightarrow y = -1$일 가능성이 높으므로 $\alpha < 0$ 출력
이처럼 각 $x$에서 더 확률이 높은 클래스를 고르는 최적의 분류기를 Bayes optimal classifier라고 합니다.
이 때의 기대 손실을 $C_\eta(\alpha)$라고 하고, $\alpha$를 실수 전체 범위에서 조절했을 때 $C_\eta(\alpha)$가 가장 작아지는 순간의 값을 $H(\eta)$라고 정의합니다. 이를 수식으로 표현하면 다음과 같습니다.
\[H(\eta) := \inf_{\alpha \in \mathbb{R}} C_\eta(\alpha) := \inf_{\alpha \in \mathbb{R}} \left( \eta\phi(\alpha) + (1-\eta)\phi(-\alpha) \right)\]$H(\eta)$이 $\alpha$를 자유롭게 골랐을 때 $C_\eta(\alpha)$의 최솟값이라면, $\alpha$를 자유롭게 고르는 것이 아니라, Bayes optimal과 반대 방향으로 강제했을 때의 최솟값을 $H^-(\eta)$라고 정의합니다.
\[H^-(\eta) := \inf_{\alpha:\,(2\eta-1)\alpha \leq 0} C_\eta(\alpha)\]$H^-(\eta)$은 분류기가 틀린 값을 내놓도록 강제하였을 때 loss의 최솟값이므로, $H^-(\eta) \geq H(\eta)$가 항상 성립합니다. 이때 모든 $\eta \neq 1/2$에서 $H^-(\eta) > H(\eta)$가 성립하면, $\phi$를 Classification-calibrated loss라고 합니다. 그리고 $H^-(\eta)-H(\eta)$가 클수록 대리 손실 함수 $\phi$가 분류기를 Bayes optimal 방향으로 강하게 유도하게 됩니다. 이를 수치화한 함수가 $\tilde{\psi}$ 함수입니다.
\[\tilde{\psi}(\theta) = H^-\!\left(\frac{1+\theta}{2}\right) - H\!\left(\frac{1+\theta}{2}\right)\]하지만 $\tilde{\psi}$ 함수 자체는 수학적으로 볼록(convex)하다는 보장이 없으므로, 이후의 상한선/하한선 증명을 전개하기 위해 여기에 이중 켤레(bi-conjugate) 연산을 취하여 새로운 함수 $\psi = \tilde{\psi}^{}$를 정의합니다. 이를 통해 만들어진 $\psi(\theta)$는 원래 함수인 $\tilde{\psi}$ 아래에 그려질 수 있는 **가장 큰 볼록 하한선(largest convex lower bound)이 되며, 볼록 함수의 성질을 보장받게 됩니다.
이러한 분류 보정 조건을 만족하는 대리 손실 함수 $\phi$를 채택함으로써, 저자들은 대리 손실 위험도와 0-1 손실 기반의 진짜 오류 사이의 수학적 관계를 $\psi$ 변환을 통해 정의할 수 있게 됩니다.
Upper bound와 Lower bound를 이용한 tightness 증명
이 논문에서 최소화하려는 것은 모델의 강건한 오류와 최적 자연 오류의 차이로, $\mathcal{R}{rob}(f) - \mathcal{R}^*{nat}$로 표현할 수 있습니다.
또한 이전 연구(Bartlett et al., 2006)에서, 대리 손실 함수 $\phi$가 classification-calibrated 조건을 만족할 때, 다음과 같은 부등식이 성립함을 증명하였습니다.
\[\mathcal{R}_{nat}(f) - \mathcal{R}^*_{nat} \leq \psi^{-1}(\mathcal{R}_\phi(f) - \mathcal{R}^*_\phi)\]이를 이전에 이 논문에서 정의한 식들과 결합하면 다음과 같은 식으로 $\mathcal{R}{rob}(f) - \mathcal{R}^*{nat}$의 상한을 구할 수 있습니다.
\[\mathcal{R}_{rob}(f) - \mathcal{R}^*_{nat} \leq \psi^{-1}(\mathcal{R}_\phi(f) - \mathcal{R}^*_\phi) + \mathcal{R}_{bdy}(f)\] \[\mathcal{R}_{rob}(f) - \mathcal{R}^*_{nat} \leq \psi^{-1}(\mathcal{R}_\phi(f) - \mathcal{R}^*_\phi) + \Pr[X \in \mathbb{B}(\text{DB}(f), \epsilon), f(X)Y > 0]\leq \psi^{-1}(\mathcal{R}_\phi(f) - \mathcal{R}^*_\phi) + \mathbb{E} \max_{X' \in \mathbb{B}(X, \epsilon)} \phi(f(X')f(X)/\lambda)\]이 부등식은 “우리가 컴퓨터로 계산할 수 있는 대리 손실 수식을 줄이면, 실제 계산이 불가능한 적대적 오류 역시 이 상한에 눌려 함께 줄어든다” 는 것을 수학적으로 보장합니다.
이후, 저자들이 도출한 이 상한선 공식이 얼마나 tight한지 확인하기 위해 저자들은 반대 방향인 하한선(Lower bound)을 증명합니다.
저자들은 극단적인 최악의 조건을 가정하더라도 우리가 계산할 대리 손실 수식이 앞서 구한 상한선 공식 밑으로는 절대 내려갈 수 없음을 입증하였습니다.
이 Tightness를 증명한 실험은 이후 실험 파트에서 자세히 소개하겠습니다.
TRADES 알고리즘
지금까지 우리는 적대적 오류의 상한선(Upper bound)을 어떻게 수학적으로 증명하였는지 확인하였습니다. 저자들은 이론적인 상한선 공식을 다음과 같은 최적화 목적 함수로 변환합니다.
이론 파트에서 도출했던 상한선의 우변(대리 손실 + 미분 가능한 경계 오류)을 바탕으로, 저자들은 다음과 같은 최종 학습 목표 식을 제안합니다.
\[\min_f \mathbb{E}\left\{ \underbrace{\phi(f(X)Y)}_{\text{for accuracy}} + \underbrace{\max_{X' \in \mathbb{B}(X,\epsilon)} \phi(f(X)f(X')/\lambda)}_{\text{regularization for robustness}} \right\}\]구현의 단순화를 위해 복잡한 역함수 \(ψ^{−1}\)은 제거하고, 대신 매개변수 \(λ\)를 사용하여 두 항의 밸런스를 조절합니다.
-
첫 번째 항: 모델의 예측 \(f(X)\)와 실제 정답 레이블 \(Y\) 사이의 차이를 최소화하여 자연 정확도(natural accuracy)를 극대화하는 역할을 수행합니다.
-
두 번째 항: 원본 입력 \(X\)와 적대적 섭동이 가해진 입력 \(X′\) 사이의 출력 분포가 달라지지 않도록 강제하여 결정 경계를 데이터로부터 멀리 밀어내는 정규화(regularizer) 역할을 합니다.
저자들은 지금까지 정립한 이진 분류 기반의 이론적 체계를 실제 딥러닝 환경인 다중 클래스 이미지 분류 문제로 확장도 진행합니다. 이를 위해 앞서 소개한 surrogate loss \(\phi\)를 multiclass calibrated loss인 cross-entropy loss \(L(\cdot,\cdot)\)로 대체하여, 아래의 최종 수식으로 TRADES 알고리즘을 구현합니다. \(\min_{f} \mathbb{E} \left\{ \mathcal{L}(f(\mathbf{X}), \mathbf{Y}) + \max_{\mathbf{X}' \in B(\mathbf{X}, \epsilon)} \mathcal{L}(f(\mathbf{X}), f(\mathbf{X}'))/\lambda \right\}\)

위 알고리즘에서 핵심적으로 볼 줄은 line 7, 9, 12입니다.
-
line 7: 각 샘플 \(x_i\)에 작은 가우시안 노이즈를 더해 \(x'_i\)를 초기화합니다. 이는 inner objective인 \(g(x')=\mathcal{L}(f_\theta(x_i), f_\theta(x'))\)가 \(x'=x_i\)에서 최소값을 가지며 gradient도 0이 되기 때문에, 최적화가 시작부터 멈추는 것을 피하기 위한 random start입니다.
-
line 9: 고정된 파라미터 \(\theta\)에서 \(x'_i\)를 projected gradient ascent로 \(K\)번 갱신하여, \(\max_{x'_i \in B(x_i,\epsilon)} \mathcal{L}(f_\theta(x_i), f_\theta(x'_i))\)를 근사적으로 풉니다. 중요한 점은 여기서 증가시키고자 하는 loss가 일반 adversarial training의 \(\mathcal{L}(f_\theta(x'_i), y_i)\)가 아니라, 원본 입력과 perturbed 입력의 예측 차이를 측정하는 \(\mathcal{L}(f_\theta(x_i), f_\theta(x'_i))\)라는 점입니다. 매 step마다 \(x'_i\)를 그 증가 방향으로 이동시킨 뒤, projection으로 항상 \(B(x_i,\epsilon)\) 안에 머물게 합니다.
-
line 12: line 9에서 얻은 \(x'_i\)를 사용해 모델 파라미터 \(\theta\)를 업데이트합니다. 첫 번째 항 \(\mathcal{L}(f_\theta(x_i), y_i)\)는 clean sample의 정확도를 유지하게 하고, 두 번째 항 \(\mathcal{L}(f_\theta(x_i), f_\theta(x'_i))/\lambda\)는 주변 섭동에 대해 예측이 급격히 변하지 않도록 만들어 decision boundary를 데이터에서 멀어지게 합니다. 따라서 \(\lambda\)는 자연 정확도와 강건성 사이의 균형을 조절하는 역할을 합니다.
실험
논문은 실험을 통해 (1) 이론적 상한선의 tightness, (2) 정규화 계수 \(\lambda\)가 만드는 robustness-accuracy trade-off, (3) 다양한 공격 하에서의 실제 방어 성능, (4) 실제 대회 환경에서의 효과를 검증합니다.
Tightness 검증
저자들은 자신들이 제안한 Upper bound가 실제로 얼마나 tight한지 검증합니다. 다시 말해, worst-case 적대적 예제에 대해 Upper bound 수식의 좌변 값 \(\Delta_{\mathrm{LHS}}\)와 상한선인 우변 값 \(\Delta_{\mathrm{RHS}}\)가 얼마나 가까운지 확인합니다. \(\Delta_{\mathrm{LHS}} = \mathcal{R}_{\mathrm{rob}}(f) - \mathcal{R}^*_{\mathrm{nat}}.\)
\[\Delta_{\text{RHS}} = (\mathcal{R}_{\phi}(f) - \mathcal{R}_{\phi}^{*}) + \mathbb{E} \max_{X' \in \mathcal{B}(X, \epsilon)} \phi((f(\mathbf{X}')f(\mathbf{X})/\lambda)).\]이를 위해 저자들은 MNIST에서 숫자 1과 3만 사용한 이진 분류 문제를 구성하고, 2개의 convolution layer와 2개의 fully-connected layer로 이루어진 CNN을 사용합니다. Surrogate loss로는 hinge loss를 사용하는데, 이 경우 \(\psi(\theta)=\theta\)이므로 우변이 위와 같이 단순화됩니다. 실험에서는 perturbation budget을 \(\epsilon = 0.1\)로 두고, TRADES의 inner maximization을 \(K = 20\) step으로 수행합니다. 또한 분포 \(\mathcal{D}\)를 직접 알 수 없기 때문에 기대값들은 test set으로 근사하며, \(\Delta_{\mathrm{RHS}}\)의 두 번째 항에 필요한 worst-case perturbed sample \(X'\)는 20-step FGSMk(PGD) 공격으로 근사합니다.
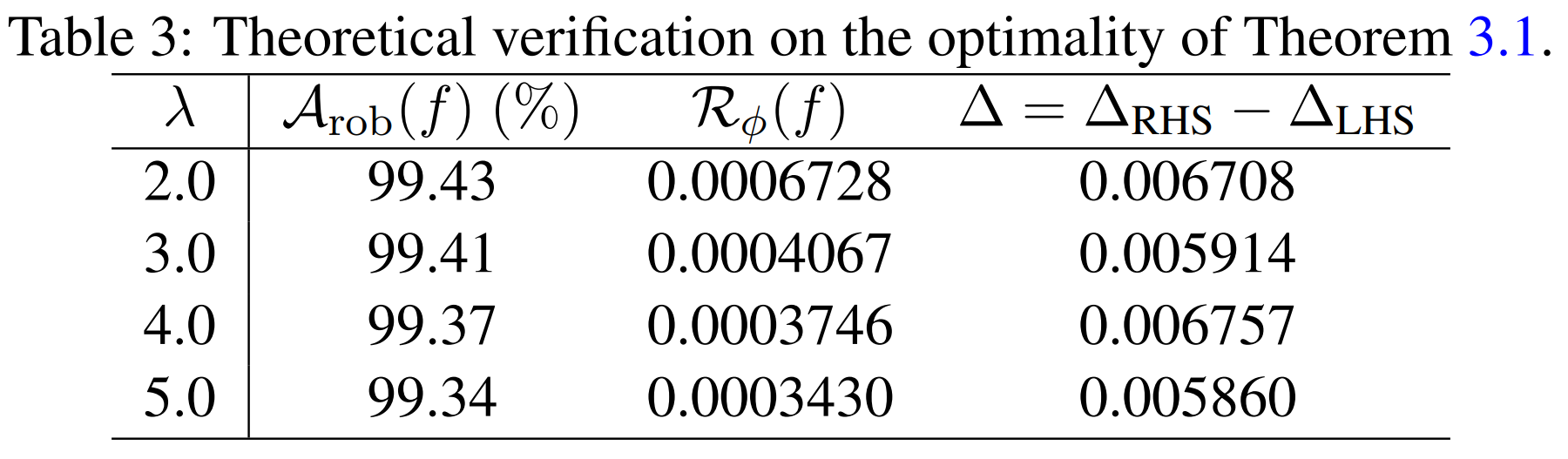
그 결과, 위 표에서 \(\Delta = \Delta_{RHS} - \Delta_{LHS}\)가 약 0.0059~0.0068 수준으로 매우 작게 나타납니다. 즉, 이론에서 유도한 upper bound가 실제 robust error를 지나치게 느슨하게 감싸는 것이 아니라, 실험적으로도 꽤 정확하게 추적하고 있음을 확인할 수 있습니다.
정규화 계수 \(\lambda\)의 영향
다음 실험에서는 multi-class 분류로 넘어가 cross-entropy 기반 TRADES를 MNIST와 CIFAR10에 적용합니다. MNIST에서는 소형 CNN, CIFAR10에서는 ResNet-18을 사용하였고, 두 데이터셋 모두에서 \(\frac{1}{\lambda}\)를 변화시키며 natural accuracy \(A_{nat}\)와 robust accuracy \(A_{rob}\)의 변화를 관찰합니다.
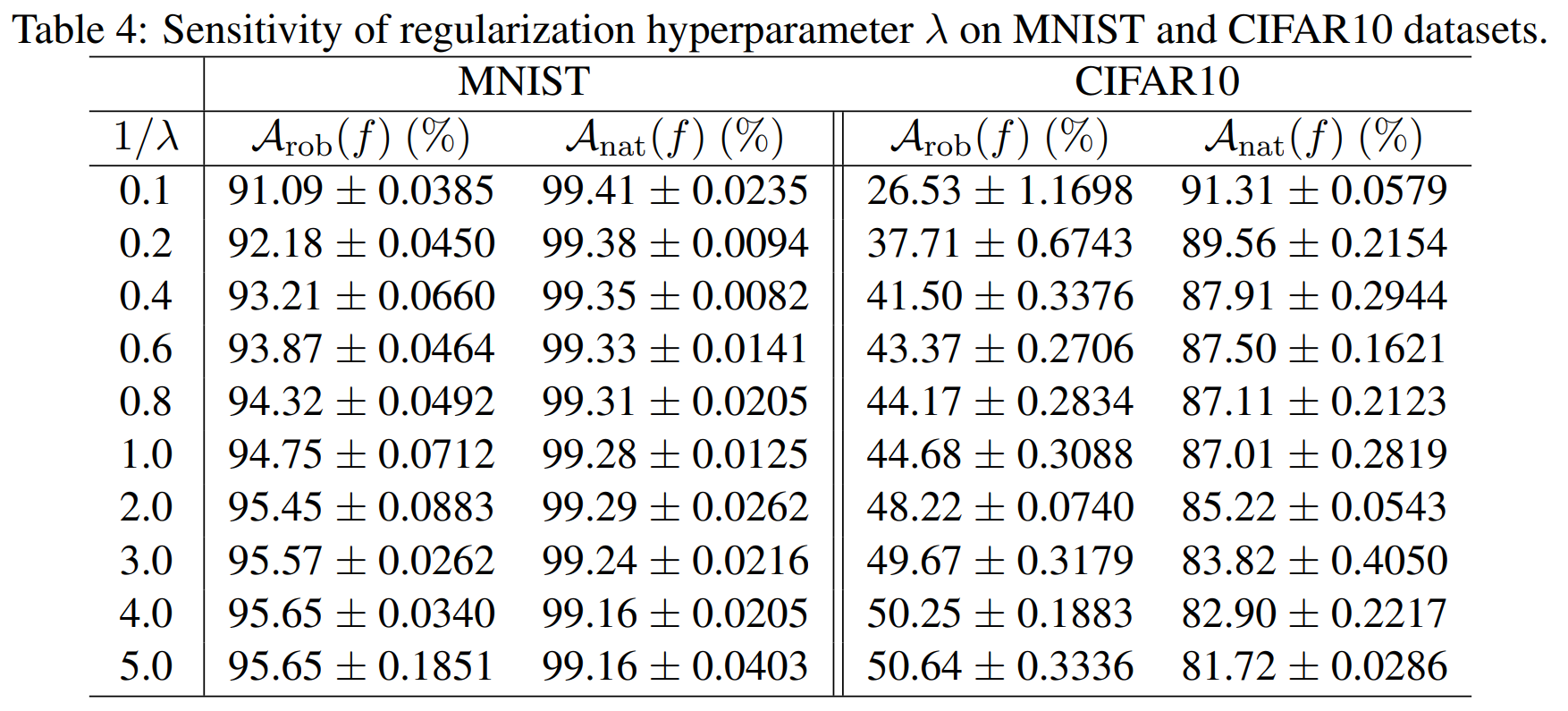
위 표는 TRADES의 핵심 메시지를 그대로 보여줍니다. \(\frac{1}{\lambda}\)가 커질수록 regularization이 강해져 decision boundary가 데이터에서 더 멀어지고, 그 대가로 자연 정확도는 다소 감소하지만 강건 정확도는 상승합니다.
MNIST를 분류하는 task는 CIFAR10보다 더 쉽기 때문에 natural accuracy 감소폭은 상대적으로 작습니다. 저자들은 이를 통해 robustness와 accuracy 사이의 trade-off가 이론뿐 아니라 실제 데이터셋에서도 관찰된다고 주장합니다.
다양한 공격에서의 방어 성능
본 논문은 White-box와 Black-box 공격 모두에서 기존 방어 기법과 TRADES를 비교합니다.
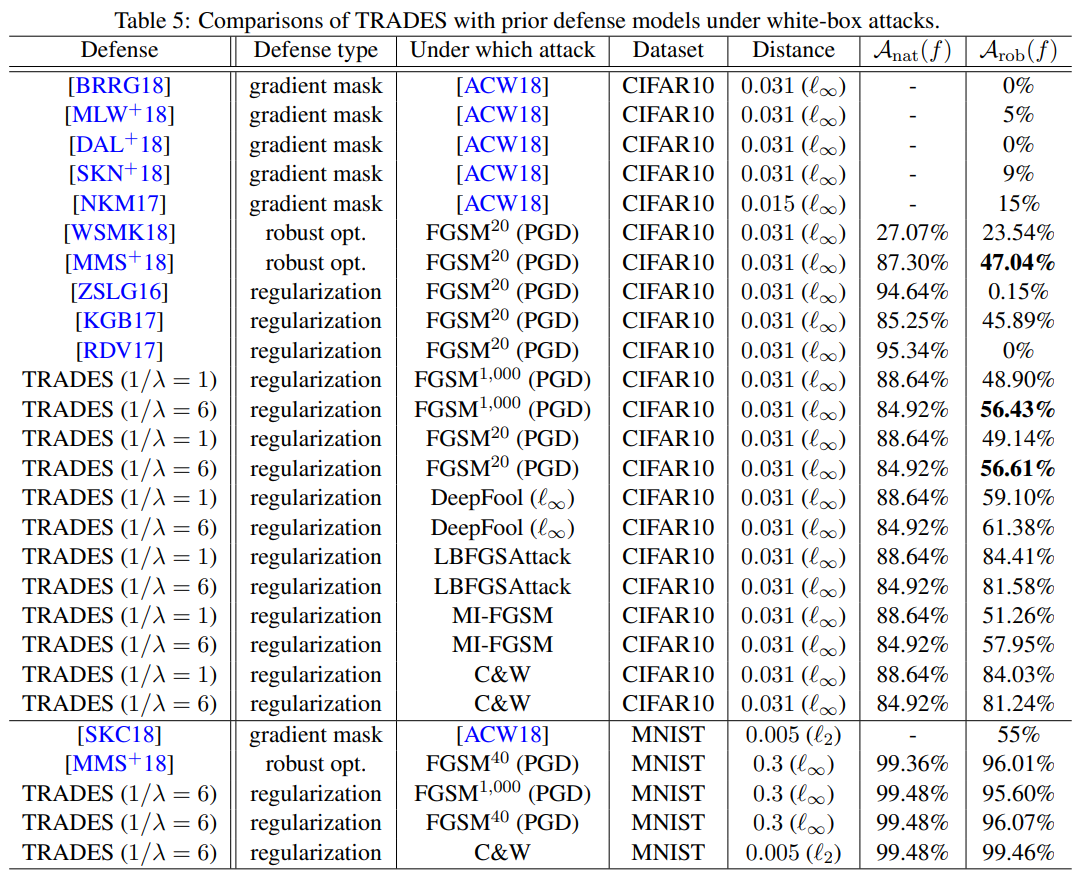
위 표는 White-box attack에 대한 방어 결과입니다. White-box 공격 실험은 데이터셋별로 서로 다른 모델과 공격 설정을 사용합니다. MNIST에서는 [CW17]의 CNN 구조를 사용하고, perturbation budget은 \(\epsilon=0.3\), step size는 \(\eta_1=0.01\), inner iteration 수는 \(K=40\)으로 설정합니다. CIFAR10에서는 Madry et al. [MMS+18]와 동일한 WRN-34-10을 사용하며, \(\epsilon=0.031\), \(\eta_1=0.007\), \(K=10\)으로 설정합니다.
이 설정에서 TRADES는 기존 방어 기법과 비교해 더 높은 robust accuracy를 보입니다. 예를 들어 CIFAR10의 PGD 20-step 공격에서는 Madry 모델의 47.04%보다 높은 56.61%를 기록했으며, DeepFool, MI-FGSM, C\&W 등 다른 white-box 공격에서도 일관되게 높은 성능을 보입니다.
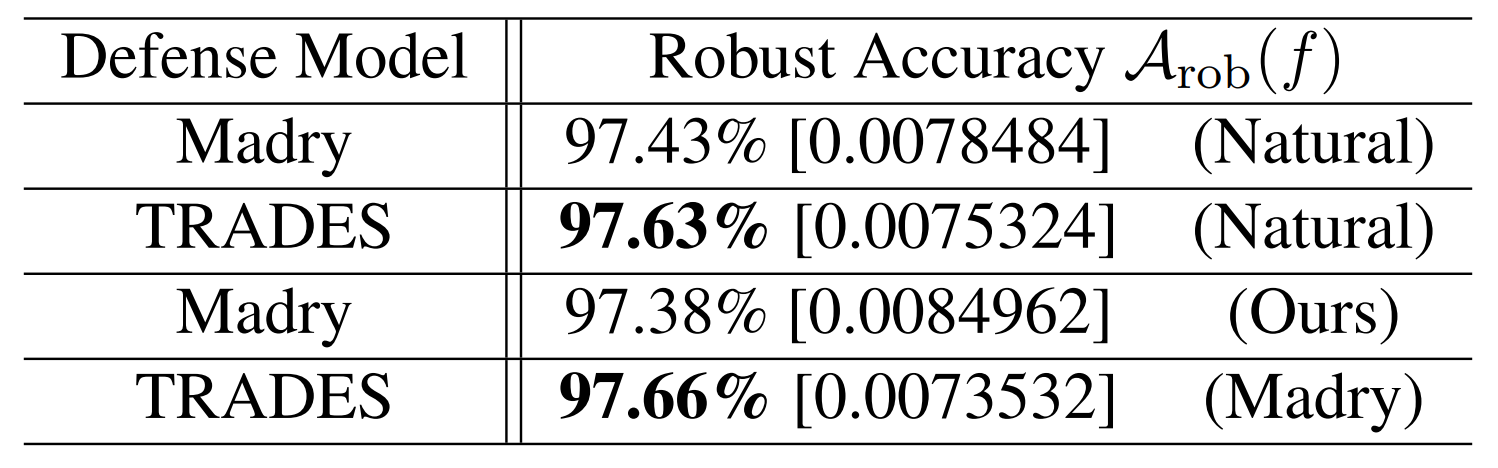
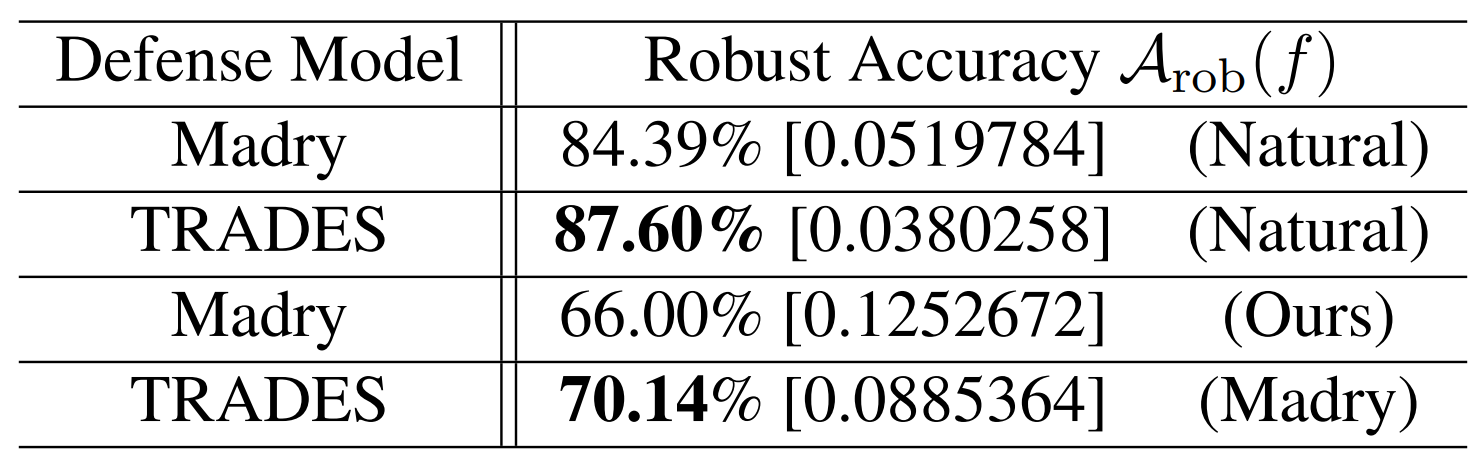
위 두 가지 표는 Black-box attack에 대한 방어 결과입니다. 괄호 내부는 공격용 적대적 예제를 생성하는 Source model, 대괄호 내부는 그 예제를 입력받았을 때 Defense model의 average loss입니다.
실험 결과, TRADES는 MNIST와 CIFAR10 모두에서 전이 공격(transfer attack)에 대해 Madry 모델보다 높은 robust accuracy를 기록합니다. 예를 들어 MNIST에서는 Natural 모델을 source model로 사용할 때 TRADES가 97.63%, Madry가 97.43%이고, CIFAR10에서는 동일한 설정에서 TRADES가 87.60%, Madry가 84.39%입니다.
즉, TRADES는 White-box에서만 강한 것이 아니라 Black-box 공격에도 비교적 안정적인 방어 성능을 보입니다.
결론
이 논문은 adversarial robustness와 natural accuracy 사이의 trade-off를 이론적으로 설명하고, 이를 정교하게 제어할 수 있는 TRADES라는 새로운 adversarial training 목적함수를 제안합니다.
저자들은 robust error를 natural error와 boundary error로 분해하고, classification-calibrated surrogate loss를 이용해 수학적으로 가장 tight한 robust error의 상한선을 도출해냈습니다.
또한 실험을 통해 정규화 계수 \(\lambda\)가 robustness와 accuracy 사이의 균형을 실제로 조절함을 입증하였고, 다양한 공격 환경에서 TRADES가 기존 방어 기법들의 성능을 뛰어넘음을 확인했습니다.
결론적으로 이 논문의 핵심은 robustness-accuracy trade-off를 단순한 경험적 현상이 아니라 수학적 원칙(Theoretically Principled)에 기반한 알고리즘 체계로 승화시켰다는 데 있습니다.