논문명: Robustness May Be at Odds with Accuracy
저자: Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, Aleksander Mądry
게재지: ICLR 2019
서론
딥러닝 모델은 컴퓨터 비전, 음성 인식 등 다양한 벤치마크에서 뛰어난 성능을 달성해 왔습니다. 하지만 이러한 모델들은 실제로는 매우 취약(brittle)하며, 사람이 인지할 수 없는 작은 변형(adversarial perturbations)만으로도 모델이 높은 확신을 가지고 잘못된 예측을 하도록 만들 수 있습니다.
이러한 적대적 예제(adversarial examples)를 방어하기 위해 ‘적대적 훈련(adversarial training)’과 같은 방어 기법이 활발히 연구되었습니다. 그러나 모델을 강건하게 만드는 데에는 여러 가지 ‘비용(Costs)’이 따릅니다. 모델 학습에 훨씬 더 많은 연산 시간과 막대한 훈련 데이터가 필요할 뿐만 아니라, 무엇보다 모델의 표준 정확도(standard accuracy)가 뚜렷하게 감소하는 현상이 지속적으로 관찰되었습니다.
과연 이 강건성과 정확도 사이의 상충 관계(trade-off)는 단순히 현재 훈련 방법론이나 최적화 기법의 한계일까요? 본 논문은 적대적 강건성과 표준 일반화(standard generalization)라는 두 가지 목표 사이에 근본적인 상충 관계가 존재할 수 있음을 단순한 데이터 분포를 통해 수학적, 실험적으로 증명합니다.
분류의 두 가지 목표
전통적인 머신러닝의 표준 분류 환경과 적대적 환경은 최적화하고자 하는 목표 함수가 근본적으로 다릅니다.
- 표준 정확도 (Standard Accuracy): 새로운 샘플에 대한 평균적인 예측 정확도를 극대화하기 위해 아래와 같이 기대 손실(population risk)을 최소화합니다.
- 적대적 강건성 (Adversarial Robustness): 공격자가 입력에 일정 크기 이하의 노이즈 $\delta$를 주입하더라도 정답을 유지하도록, 최악의 경우(worst-case)에 대한 손실을 최소화합니다. 주로 $l_{\infty}$ 노름(norm) 기반의 제약이 벤치마크로 사용됩니다.
적대적 훈련: 데이터 증강(Data Augmentation)의 한계
머신러닝 실무에서는 종종 적대적 훈련을 가장 강력한 형태의 ‘데이터 증강(Data Augmentation)’ 기법으로 간주합니다. 모델이 헷갈려 할 만한 최악의 노이즈를 데이터에 추가하여 학습시키기 때문입니다.
실제로 논문의 실험에 따르면, 훈련 데이터가 매우 부족한 환경(Low-data regime)에서는 적대적 훈련이 정규화(regularization) 효과를 주어 모델의 일반화를 돕고 오히려 표준 정확도를 높이는 데 기여합니다 (특히 MNIST 데이터셋에서 두드러짐).
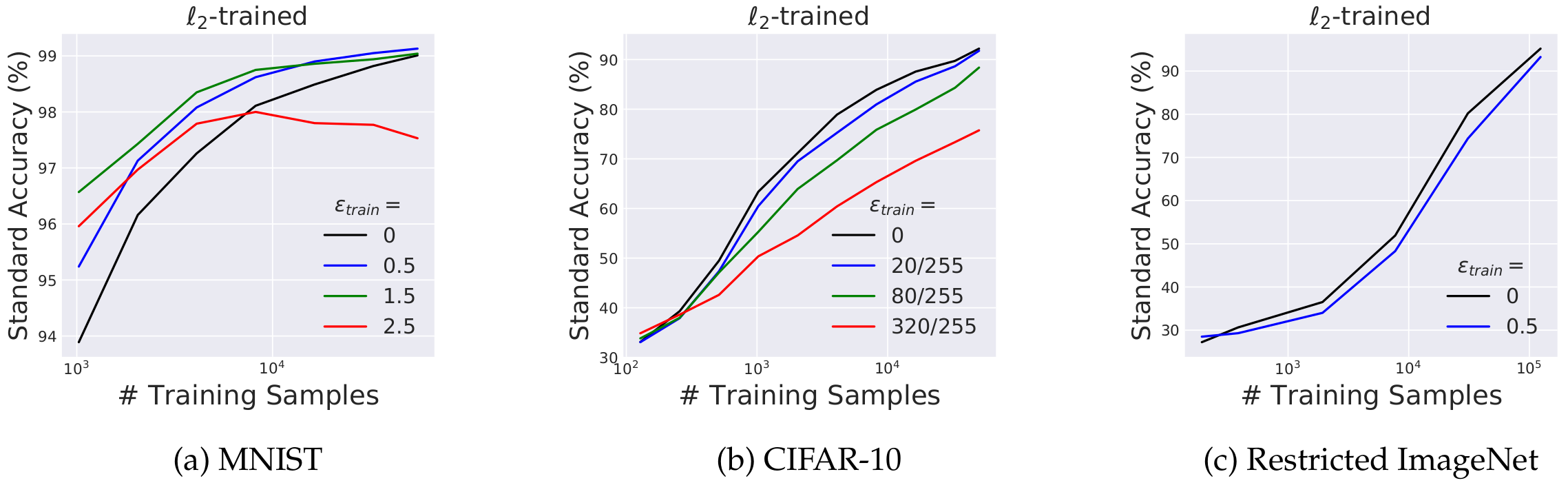
하지만 훈련 데이터가 충분히 제공될수록 이 긍정적인 효과는 점차 사라집니다. 데이터가 많아짐에 따라 표준 훈련 모델은 거의 완벽한 정확도로 수렴하지만, 적대적 훈련을 거친 강건한 모델은 결국 표준 모델의 정확도 아래로 역전되는 뚜렷한 상충 관계를 보입니다. CIFAR-10이나 ImageNet과 같이 복잡한 데이터셋에서는 특정 제약에 대한 불변성(invariance)이 표준 정확도 향상에 크게 기여하지 않기 때문에 이 현상이 더욱 빨리 나타납니다.
정확도와 강건성의 상충 관계: 수학적 유도
저자들은 이러한 상충 관계가 왜 ‘필연적’인지 증명하기 위해, 이진 분류(binary classification)를 위한 단순한 장난감 데이터셋(Toy Dataset) $\mathcal{D}$를 수학적으로 설계했습니다.
1. 강건한 특성 (Robust Feature, $x_1$) 정답 레이블 $y$와 강하게 상관(예: $p=0.95$)되어 있으나 완벽하지 않은 단일 특성입니다. 작은 수준의 공격으로는 이 특성의 부호를 뒤집을 수 없습니다.
2. 비강건한 특성 (Non-robust Features, $x_2, \dots, x_{d+1}$) 개별적으로는 정답과 아주 미약하게 상관되어 있는 수많은 특성들입니다. 각 특성은 $\mathcal{N}(\eta y, 1)$의 정규분포를 따르며, 여기서 $\eta$는 매우 작은 값입니다.
표준 분류기의 탐욕적 학습과 메타 특성의 형성
표준 모델의 유일한 목표는 ‘정확도 극대화’입니다. 따라서 정답을 부분적으로 맞추는 강건한 특성 $x_1$에만 만족하지 않고, 아주 미세한 정보량을 가진 수많은 비강건한 특성들을 모두 긁어모아 평균을 냅니다. 통계적으로 이 약한 신호들을 모두 합치면 강력한 확신을 갖는 ‘메타 특성(Meta-feature)’이 형성됩니다.
각 특성이 $x_i \sim \mathcal{N}(\eta y, 1)$를 따를 때, 이들의 평균인 $z$는 다음과 같은 분포를 가집니다.
\[z = \frac{1}{d}\sum_{i=2}^{d+1} x_i \sim \mathcal{N}\left(\eta y, \frac{1}{d}\right)\]특성의 개수 $d$가 커질수록 분산이 $0$에 수렴하므로, 모델은 아주 작은 신호만으로도 정답을 거의 확신하게 되며 이를 통해 완벽에 가까운 표준 정확도를 달성합니다.
적대적 공격과 정확도의 붕괴
하지만 이 ‘메타 특성’은 치명적인 약점이 있습니다. 적대적 환경에서 공격자가 각 특성에 아주 작은 노이즈를 정답의 반대 방향으로 주입하면, 메타 특성의 분포는 완전히 뒤집힙니다.
\[z_{adv} \sim \mathcal{N}\left(-\eta y, \frac{1}{d}\right)\]결과적으로 모델은 매우 높은 확신을 가지고 정답의 반대 방향을 선택하게 됩니다.
이로 인해 비강건한 특성에 의존하여 높은 정확도를 달성한 표준 분류기는 적대적 공격 하에서 정확도가 1% 미만으로 곤두박질칩니다. 논문은 적대적 손실을 최소화하는 훈련을 거치게 되면 모델이 스스로 비강건한 특성에 가중치 부여를 포기하고 강건한 특성 $x_1$에만 의존하게 됨을 수학적으로 증명했습니다. 즉, 강건성을 위해 정확도가 일부 떨어지는 것을 감수해야만 하는 구조적 한계가 존재합니다.
무한한 데이터로도 해결할 수 없는 근본적 한계
흔히 “훈련 데이터가 무한히 주어지면 모델이 완벽해져 강건성 문제도 자연스레 해결될 것”이라고 기대합니다. 하지만 이 환경에서는 데이터가 무한히 주어지더라도 상충 관계가 사라지지 않습니다. 분포의 모든 정보를 완벽하게 아는 ‘베이즈 최적 분류기(Bayes-optimal classifier)’조차 표준 정확도를 극대화하려면 필연적으로 비강건한 특성에 의존해야만 합니다. 즉, 이 상충 관계는 데이터 부족이나 최적화의 한계가 아니라, 데이터 분포 자체가 가진 근본적인 딜레마라는 점을 시사합니다.
경험적 검증과 전이성(Transferability)의 원인
이러한 수학적 현상은 이진 MNIST 데이터셋을 활용한 실험에서도 시각적으로 뚜렷하게 확인됩니다. 아래 그림을 살펴보면, 픽셀(특성)과 정답 레이블 간의 상관관계(Correlation)에 따라 모델이 가중치를 부여하는 방식에 극명한 차이가 발생합니다.
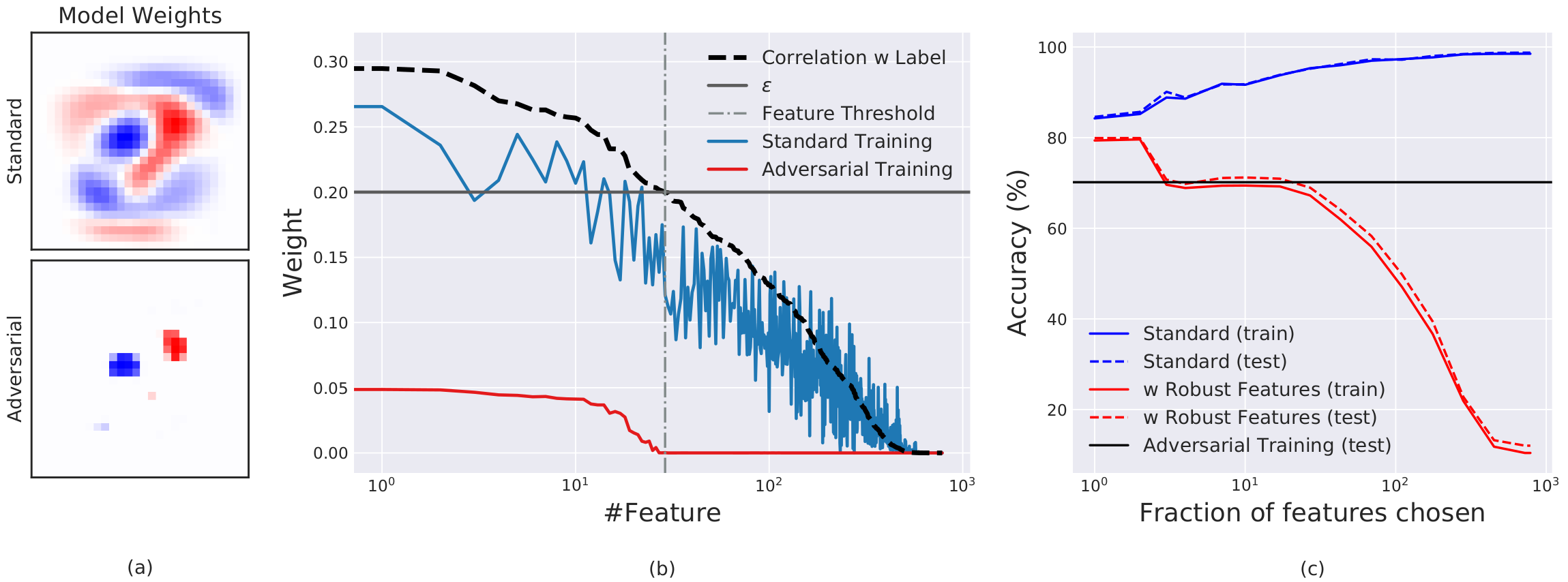
- 표준 모델의 가중치 분포: 그래프의 파란색 선을 보면, 표준 모델은 상관관계가 거의 없는 픽셀(단순 배경 노이즈)에까지 가중치를 부여합니다. 미세한 정확도라도 올릴 수 있다면 취약한 특성이라도 모두 사용하는 탐욕적 최적화의 결과입니다.
- 강건한 모델의 가중치 분포: 그래프의 빨간색 선을 보면, 강건한 모델은 적대자의 허용 강도에 대응하기 위해 일정 임계치(Threshold) 이상의 강력한 상관관계를 가진 핵심 픽셀에만 가중치를 할당합니다.
전이성(Transferability)은 왜 발생할까? 이 분석은 딥러닝에서 오랫동안 미해결 과제였던 ‘적대적 예제의 전이성(한 모델을 속인 예제가 다른 모델도 속이는 현상)’에 대한 강력한 단서를 제공합니다. 동일한 분포에서 훈련된 표준 모델들은 구조와 상관없이 결국 ‘동일한 비강건한 특성들’에 공통적으로 의존하도록 학습됩니다. 따라서 이 약한 특성들을 오염시키는 적대적 예제는 독립적으로 훈련된 다른 분류기에도 그대로 전이될 수밖에 없는 것입니다.
대안적 접근: 적대적 훈련 없는 강건성 확보
적대적 훈련은 연산 비용이 매우 높습니다. 저자들은 이 한계를 극복하기 위해, 모델이 학습할 때 상관관계가 높은 ‘강건한 특성’만 사용하도록 제한하고 일반적인 표준 훈련을 진행하는 실험을 수행했습니다. 위 그래프에서 보듯, 단순히 취약한 특성을 학습에서 배제한 것만으로도 복잡한 적대적 훈련을 거친 것과 유사한 수준의 방어력을 달성했습니다. 이는 올바른 특성 선택만으로도 강건한 모델을 설계할 수 있음을 시사합니다.
강건한 모델의 예상치 못한 이점
정확도의 하락이라는 뼈아픈 비용을 지불하지만, 비강건한 지름길(Shortcut)을 차단한 대가로 강건한 모델은 매우 직관적이고 인간과 유사한 능력을 얻게 됩니다.

1. 인간의 지각과 정렬된 모델 (Human-aligned Gradients)
입력 공간에서 모델 손실 함수의 기울기를 시각화해 보면 이 차이가 명확히 드러납니다. 과거에는 표준 네트워크에서 이런 의미 있는 시각화 정보를 뽑아내기 위해 복잡한 추가 기법들을 동원해야만 했습니다.
그러나 적대적 훈련을 거친 모델은 기본 상태에서도 기울기가 동물의 윤곽, 물체의 테두리 등 지각적으로 의미 있는 특성들과 완벽히 정렬됩니다. 이는 “인간은 작은 픽셀 변화에 둔감하다”는 인간의 시각 인지적 사전 지식(Prior)이 적대적 위협 모델을 통해 수학적으로 인코딩되었기 때문입니다.

2. 유의미한 특징 포착과 생성 모델과의 연관성
강건한 모델의 이러한 특성은 적대적 공격을 수행해 볼 때 더욱 극명하게 나타납니다. 위 사진처럼 모델을 속이기 위해 큰 적대적 변형($\epsilon$)을 허용하여 최적화(PGD)를 진행해 보았습니다.
표준 모델이 만들어낸 적대적 예제는 그저 지글거리는 무의미한 노이즈로 보입니다. 하지만 놀랍게도 강건한 모델의 적대적 예제는 타겟 클래스의 실제 특징적인 모습(예: 개의 털, 새의 부리 등)을 시각적으로 띄게 됩니다. 이는 방어 기법이 단순히 기울기를 꼬아버리는 것(gradient obfuscation)이 아니라, 모델이 데이터의 실제 ‘특징 분포’를 근본적으로 학습했음을 시사합니다.

심지어 원본 이미지와 이 강건한 모델의 적대적 예제 사이를 선형 보간(linear interpolation)해 보면, 위 그림과 같이 하나의 클래스가 다른 클래스로 매우 자연스럽게 변환되는(morphing) 현상이 나타납니다. 이는 전통적으로 GAN이나 VAE 같은 생성 모델(Generative Models)에서만 가능했던 특성으로, 분류기의 최적화 문제와 생성 모델 간에 매우 깊은 수학적 연관성이 존재함을 암시합니다.
결론 및 향후 연구 방향
본 논문은 적대적 강건성과 표준 일반화(정확도)가 단순히 훈련 기법의 한계가 아닌, 데이터의 구조적 특성상 근본적으로 상충할 수 있음을 입증했습니다.
흥미롭게도 특정 이미지 분류 벤치마크에서 인간이 최신 딥러닝 모델보다 정확도가 떨어지는 현상이 종종 관찰됩니다. 우리는 그 이유를 이 논문의 통찰에서 찾을 수 있습니다. 모델은 점수를 아주 조금이라도 높이기 위해 기계만이 볼 수 있는 미세하고 취약한 ‘비강건한 특성’까지 모조리 긁어모아 사용합니다. 반면 인간은 태생적으로 이러한 노이즈에 불변(invariant)하도록 진화해 왔기 때문에 오직 ‘강건한 특성’에만 의존하며, 그 결과 벤치마크 상의 단순 정확도는 모델보다 낮게 측정될 수 있는 것입니다.
결국 적대적 훈련 시 관찰되는 뚜렷한 정확도의 감소는 방어 기법의 결함이 아닙니다. 오히려 모델이 무의미한 통계적 지름길을 버리고, 보다 해석 가능(interpretable)하며 인간과 유사한 방식으로 데이터를 인지하는 방향으로 진화하기 위해 지불해야 하는 합리적이고 필연적인 비용이라는 중요한 통찰을 제공합니다.