Paper: Adversarial Training for Free!
Authors: Ali Shafahi, Mahyar Najibi, Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S. Davis, Gavin Taylor, Tom Goldstein
Venue: NeurIPS 2019
Introduction
As repeatedly confirmed by a long line of prior work, adversarial training is almost the only defense technique that actually works when it comes to building robust classifiers. Madry’s PGD-based adversarial training has consistently held up against a wide variety of attacks, and it remained one of the few methods left standing even after Athalye et al. dismantled many other defenses.
But this strength comes at a steep price. PGD adversarial training requires roughly \(K+1\) times the computational cost of standard training, where \(K\) is the number of PGD iterations used to craft adversarial examples. Since \(K=7\) is a typical choice, making the same model robust requires investing 7–8 times more wall-clock time than standard training. As a result, on large-scale problems like ImageNet only a handful of labs with dozens to hundreds of GPUs at their disposal have been able to attempt adversarial training.
This paper breaks through that bottleneck in a rather elegant way. The authors’ key observation is simple: in a single backward pass already performed during standard training, we can simultaneously obtain both the gradient used to update the parameters and the gradient used to update the adversarial perturbation. Adding one small device on top of this observation — a minibatch replay — they propose a “Free” adversarial training that achieves robustness rivaling PGD training at essentially the same cost as standard training.
The Cost Problem of Adversarial Training
A single step of PGD adversarial training breaks down into two parts. On the inside, the model parameters are held fixed and PGD is iterated \(K\) times to generate an adversarial example; on the outside, the model parameters are updated using that adversarial example.
\[x^{t+1} = \Pi_{x+\mathcal{S}}\left(x^t + \alpha \cdot \mathrm{sgn}(\nabla_x L(\theta, x^t, y))\right)\]The problem is that each of those \(K\) inner iterations is individually expensive. Every PGD step has to compute the gradient of the loss with respect to the input \(\nabla_x L\) in order to update the adversarial example, and obtaining this gradient requires one full forward-backward pass through the entire network. So \(K\) full forward-backward passes go solely into adversarial example generation, and one more backward pass is then needed to actually update the model parameters.
As a result, the computational cost of PGD-\(K\) adversarial training is roughly \(K+1\) times that of standard training. Madry’s CIFAR-10 reference setting (\(K=7\)) takes about 4 days on a single Titan X GPU, and the ImageNet case required 128 V100 GPUs. For most researchers, this level of cost was effectively an impassable wall.
Free Adversarial Training
Reusing the Gradient
The authors’ starting point is the following observation. To update the model parameters in standard training, we need the gradient of the loss with respect to the parameters \(\nabla_\theta L\), but in the very backward pass that produces this gradient, the gradient with respect to the input \(\nabla_x L\) is already flowing through the computation graph alongside it.
In other words, both gradients can be extracted from a single backward pass without any additional backpropagation. Using this fact, within one forward-backward pass we can simultaneously update the model parameters and take one step of the adversarial perturbation update.
This approach has an obvious weakness, however. Only a single perturbation update can be applied per minibatch. Unlike PGD-\(K\), which iterates \(K\) times to produce a strong adversarial example, a single 1-step update is unlikely to yield a sufficiently strong adversarial example. Earlier work showing that pure FGSM training collapses under PGD attacks supports this concern.
The Minibatch Replay Trick
The authors’ second idea fills this gap in a remarkably simple way: train on the same minibatch \(m\) consecutive times.
The key point is that at every iteration the perturbation from the previous iteration is inherited and updated by one more step. The first iteration takes one step from the initial perturbation; the second iteration inherits the perturbation updated in the first iteration and adds another step. Repeated \(m\) times, this effectively accumulates a strong perturbation that approaches an \(m\)-step PGD attack. At the same time, the model parameters are also updated once per iteration, so the adversarial example is always tuned to the latest parameters.
One important adjustment accompanies this. Training on the same minibatch \(m\) times does not mean increasing the total number of training iterations by a factor of \(m\). Instead, the total number of training epochs is reduced to \(1/m\), so that the total number of training iterations is kept exactly equal to that of standard training. The result is a computational cost essentially identical to standard training, while the model is implicitly subjected to \(m\)-step PGD adversarial training.
As one final small touch, when a new minibatch arrives, the perturbation produced by the previous minibatch is not reset to zero but is reused as a warm-start. This is a device that lets the perturbation continue to evolve, however loosely, across consecutive minibatches.
Effect of Minibatch Replay on Generalization
Since training on the same minibatch consecutively distorts the original ordering of the training data, it could harm generalization. Concerns such as catastrophic forgetting are particularly natural here.
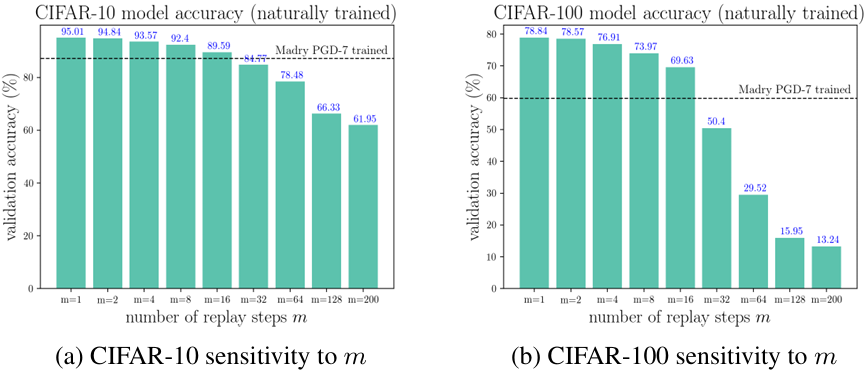
The figure above shows a controlled experiment where, instead of running Free training, only pure natural training is run while varying \(m\). \(m=1\) is identical to standard training, and as \(m\) becomes very large the validation accuracy drops sharply. But for small \(m\) (roughly the $m \le 10$ regime), the drop in accuracy is surprisingly small. For reference, the natural accuracy attained by a 7-PGD adversarially trained model (87.25% on CIFAR-10, 59.87% on CIFAR-100) is already matched by pure natural training with \(m=16\) or so. In other words, the generalization loss incurred by a small \(m\) is a perfectly acceptable cost compared to the robustness gained by adversarial training.
Experiments on CIFAR-10 and CIFAR-100
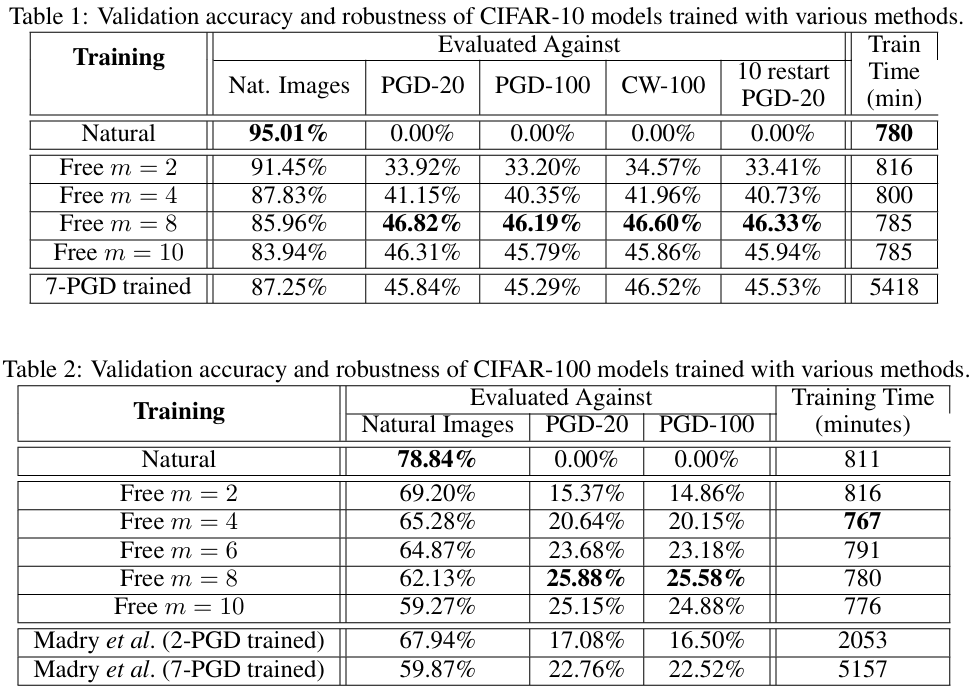
On CIFAR-10, the authors use Wide-ResNet 32-10 to compare Free-\(m\) training and 7-PGD adversarial training head to head. The results are quite striking. The Free \(m=8\) model maintains roughly 46% robust accuracy against PGD-20, PGD-100, and CW-100 attacks alike, which is essentially the same level as Madry’s 7-PGD-trained model (45–46%). However, while 7-PGD training takes about 5,400 minutes, Free training takes only about 780 minutes — almost exactly 7× faster.
The CIFAR-100 results are even more interesting. The Free \(m=8\) model achieves 25.88% robust accuracy under PGD-20, outperforming the 7-PGD-trained model (22.76%) that costs roughly 7× more to train. Not only can the natural-versus-robust accuracy trade-off be obtained at far lower cost, but in some settings the existing approach is in fact surpassed outright.
Examining the Robustness of Free Adversarial Training
So far this might sound like “there is simply a cheap alternative,” but a doubt remains. What if Free training is not actually defending against attacks but is merely twisting the gradients so that PGD attacks fail to operate properly? In other words, the possibility that this is a fake robustness relying on gradient masking has to be considered.
The authors verify this with two diagnostics.
Interpretable Adversarial Examples

The figure above shows adversarial examples produced by a BIM attack with a fairly large allowed perturbation of \(\epsilon = 30\). The top row is the original images, the middle row is the attack images crafted against the 7-PGD-trained model, and the bottom row is the attack images crafted against the Free \(m=8\)-trained model.
As Tsipras et al. first reported, the adversarial examples crafted against properly adversarially trained models are not mere noise but actually take on the genuine visual features of the target class. For example, attack images forced to be classified as a “horse” really do exhibit elements like the contour of a horse and fur-like textures. The same pattern appears for the Free-trained model, and the attack images from the two training schemes are qualitatively almost indistinguishable. This is indirect evidence that Free training learns internally a representation similar to that of PGD training.
Flat Loss Landscape
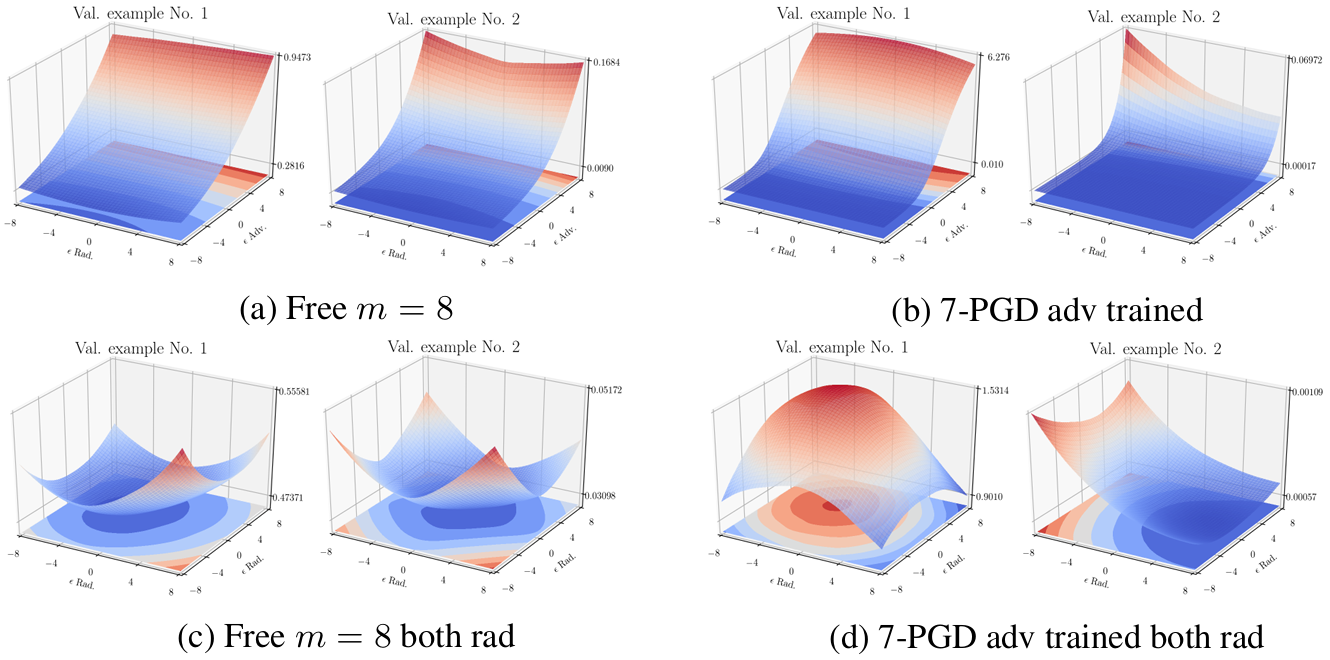
The second diagnostic looks directly at the loss landscape itself. The figure above plots the loss in a neighborhood of CIFAR-10 validation images along two cross-sections; the top two plots \((a), (b)\) are along an adversarial direction and a random direction, and the bottom two plots \((c), (d)\) are along two random directions.
If the model were operating via gradient masking, one would expect a strange shape in which the loss is flat along the adversarial direction but changes a lot along random directions. In both the Free-trained model \((a)\) and the 7-PGD-trained model \((b)\), however, the adversarial direction does in fact correspond to the direction of greatest change in loss, and the landscape itself is smooth and flat for both models. The interpretation is that Free training’s robustness is not the result of hiding gradients to dodge attacks, but is genuinely the result of broadly flattening the loss landscape.
Extension to ImageNet
Another major contribution of this paper is making ImageNet adversarial training feasible on realistic lab-scale hardware. Previous ImageNet adversarial training studies required mobilizing 53 P100s or 128 V100s. Free training, by contrast, can train a robust ResNet-50 model in about 2 days on a single workstation with 4 P100 GPUs.
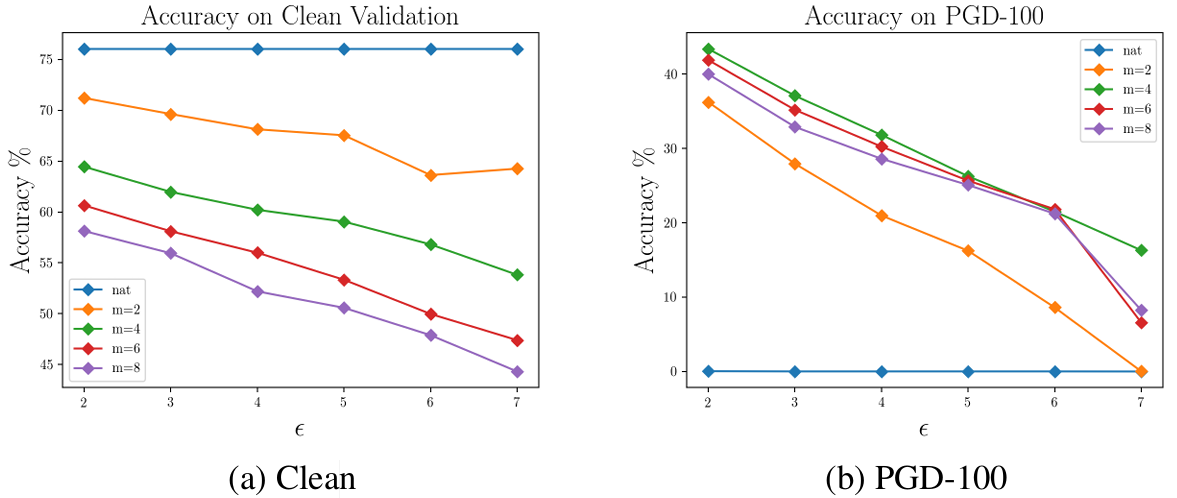
The figure above shows natural accuracy and robust accuracy under PGD-100 attack measured while jointly varying the training-time perturbation budget \(\epsilon\) and the minibatch replay count \(m\). With \(\epsilon = 2\), the Free \(m=4\) model maintains 43.4% robust accuracy under PGD-100 — at the time of publication, the first level of robustness on ImageNet ever achieved against non-targeted attacks.
A trend in which robustness becomes drastically harder to obtain as \(\epsilon\) grows is observed, but this is not a limitation specific to Free training; it is an ImageNet-specific difficulty also reported uniformly in earlier studies. Even so, what is clear is that Free training has pulled robust ImageNet training down from being the exclusive privilege of a few institutions to a project that an ordinary lab can attempt.
Conclusion
The contribution of this paper is conceptually simple, but its practical impact is considerable. From a single observation — “the backward pass for the model update already computes the input gradient as well” — it opens up a path that essentially makes PGD adversarial training, which used to cost \(K+1\) times as much, free of charge.
Combined with two small devices, minibatch replay and warm-starting the perturbation, the result is not a brittle 1-step FGSM-trained model but a model with robustness rivaling multi-step PGD training.
The experimental results are also impressive. On CIFAR-10 and CIFAR-100, results comparable to or even surpassing PGD training are obtained at 7× lower cost, and above all ImageNet adversarial training is brought down to a single workstation. At the same time, the hallmarks of genuine adversarial training — interpretable gradients and a flat loss landscape — are inherited as well.
In the end, the message of this paper is clear. Adversarial training is no longer the exclusive preserve of labs equipped with massive GPU clusters; with reasonable computing resources, robust models that are actually usable in practice can be trained. This is a powerful contribution that opens up the research topic of robust learning to a much broader community of researchers.